The GPT4 model has been THE groundbreaking model so far, available to the general public either for free or through their commercial portal (for public beta use). It has worked wonders in igniting new project ideas and use-cases for many entrepreneurs but the secrecy about the number of parameters and the model was killing all enthusiasts who were betting on the first 1 trillion parameter model to 100 trillion parameter claims!
The cat is out of the bag
Well, the cat is out of the bag (Sort of). On June 20th, George Hotz, founder of self-driving startup Comma.ai leaked that GPT-4 isn’t a single monolithic dense model (like GPT-3 and GPT-3.5) but a mixture of 8 x 220-billion-parameter models.
Later that day, Soumith Chintala, co-founder of PyTorch at Meta, reaffirmed the leak.
Just the day before, Mikhail Parakhin, Microsoft Bing AI lead, had also hinted at this.
GPT 4: Not a Monolith
What do all the tweets mean? The GPT-4 is not a single large model but a union/ensemble of 8 smaller models sharing the expertise. Each of these models is rumored to be 220 Billion parameters.

The methodology is called a mixture of experts' model paradigms (linked below). It's a well-known methodology also called as hydra of model. It reminds me of Indian mythology I will go with Ravana.
Please take it with a grain of salt that it is not official news but significantly high-ranking members in the AI community have spoken/hinted towards it. Microsoft is yet to confirm any of these.
What is a Mixture of Experts paradigm?
Now that we have spoken about the mixture of experts, let's take a little bit of a dive into what that thing is. The Mixture of Experts is an ensemble learning technique developed specifically for neural networks. It differs a bit from the general ensemble technique from the conventional machine learning modeling (that form is a generalized form). So you can consider that the Mixture of Experts in LLMs is a special case for ensemble methods.
In short, in this method, a task is divided into subtasks, and experts for each subtask are used to solve the models. It is a way to divide and conquer approach while creating decision trees. One could also consider it as meta-learning on top of the expert models for each separate task.
A smaller and better model can be trained for each sub-task or problem type. A meta-model learns to use which model is better at predicting a particular task. Meta learner/model acts as a traffic cop. The sub-tasks may or may not overlap, which means that a combination of the outputs can be merged together to come up with the final output.
For the concept-descriptions from MOE to Pooling, all credits to the great blog by Jason Brownlee (https://machinelearningmastery.com/mixture-of-experts/). If you like what you read below, please please subscribe to Jason’s blog and buy a book or two to support his amazing work!
Mixture of experts, MoE or ME for short, is an ensemble learning technique that implements the idea of training experts on subtasks of a predictive modeling problem.
In the neural network community, several researchers have examined the decomposition methodology. […] Mixture–of–Experts (ME) methodology that decomposes the input space, such that each expert examines a different part of the space. […] A gating network is responsible for combining the various experts.
— Page 73, Pattern Classification Using Ensemble Methods, 2010.
There are four elements to the approach, they are:
- Division of a task into subtasks.
- Develop an expert for each subtask.
- Use a gating model to decide which expert to use.
- Pool predictions and gating model output to make a prediction.
The figure below, taken from Page 94 of the 2012 book “Ensemble Methods,” provides a helpful overview of the architectural elements of the method.
How Do 8 Smaller Models in GPT4 Work?
The secret “Model of Experts” is out, let's understand why GPT4 is so good!
ithinkbot.com
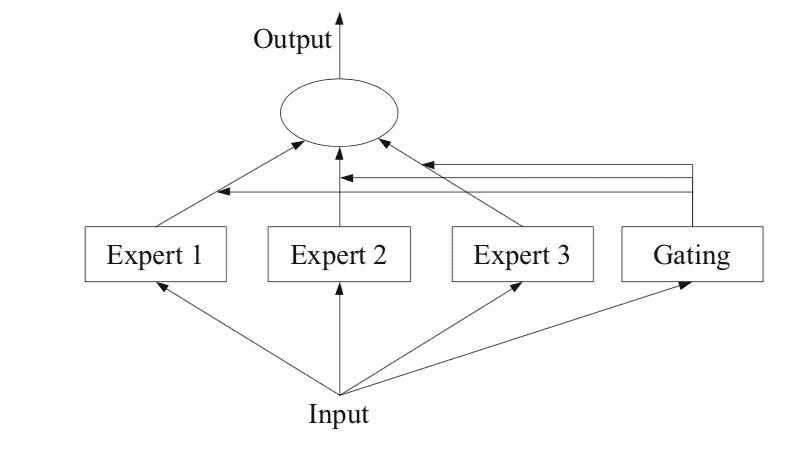
Example of a Mixture of Experts Model with Expert Members and a Gating Network
Taken from: Ensemble Methods
Subtasks
The first step is to divide the predictive modeling problem into subtasks. This often involves using domain knowledge. For example, an image could be divided into separate elements such as background, foreground, objects, colors, lines, and so on.
… ME works in a divide-and-conquer strategy where a complex task is broken up into several simpler and smaller subtasks, and individual learners (called experts) are trained for different subtasks.
— Page 94, Ensemble Methods, 2012.
For those problems where the division of the task into subtasks is not obvious, a simpler and more generic approach could be used. For example, one could imagine an approach that divides the input feature space by groups of columns or separates examples in the feature space based on distance measures, inliers, and outliers for a standard distribution, and much more.
… in ME, a key problem is how to find the natural division of the task and then derive the overall solution from sub-solutions.
— Page 94, Ensemble Methods, 2012.
Expert Models
Next, an expert is designed for each subtask.
The mixture of experts approach was initially developed and explored within the field of artificial neural networks, so traditionally, experts themselves are neural network models used to predict a numerical value in the case of regression or a class label in the case of classification.
It should be clear that we can “plug in” any model for the expert. For example, we can use neural networks to represent both the gating functions and the experts. The result is known as a mixture density network.
— Page 344, Machine Learning: A Probabilistic Perspective, 2012.
Experts each receive the same input pattern (row) and make a prediction.
Gating Model
A model is used to interpret the predictions made by each expert and to aid in deciding which expert to trust for a given input. This is called the gating model, or the gating network, given that it is traditionally a neural network model.
The gating network takes as input the input pattern that was provided to the expert models and outputs the contribution that each expert should have in making a prediction for the input.
… the weights determined by the gating network are dynamically assigned based on the given input, as the MoE effectively learns which portion of the feature space is learned by each ensemble member
— Page 16, Ensemble Machine Learning, 2012.
The gating network is key to the approach and effectively, the model learns to choose the type subtask for a given input and, in turn, the expert to trust to make a strong prediction.
Mixture-of-experts can also be seen as a classifier selection algorithm, where individual classifiers are trained to become experts in some portion of the feature space.
— Page 16, Ensemble Machine Learning, 2012.
When neural network models are used, the gating network and the experts are trained together such that the gating network learns when to trust each expert to make a prediction. This training procedure was traditionally implemented using expectation maximization (EM). The gating network might have a softmax output that gives a probability-like confidence score for each expert.
In general, the training procedure tries to achieve two goals: for given experts, to find the optimal gating function; for a given gating function, to train the experts on the distribution specified by the gating function.
— Page 95, Ensemble Methods, 2012.
Pooling Method
Finally, the mixture of expert models must make a prediction, and this is achieved using a pooling or aggregation mechanism. This might be as simple as selecting the expert with the largest output or confidence provided by the gating network.
Alternatively, a weighted sum prediction could be made that explicitly combines the predictions made by each expert and the confidence estimated by the gating network. You might imagine other approaches to making effective use of the predictions and gating network output.
The pooling/combining system may then choose a single classifier with the highest weight, or calculate a weighted sum of the classifier outputs for each class, and pick the class that receives the highest weighted sum.
— Page 16, Ensemble Machine Learning, 2012.
Switch Routing
We should also briefly discuss the switch routing approach differs from the MoE paper. I am bringing it up as it seems like Microsoft has used a switch routing than a Model of Experts to save some computational complexity, but I am happy to be proven wrong. When there are more than one expert's models, they may have a non-trivial gradient for the routing function (which model to use when). This decision boundary is controlled by the switch layer.
The benefits of the switch layer are threefold.
- Routing computation is reduced if the token is being routed only to a single expert model
- The batch size (expert capacity) can be at least halved since a single token goes to a single model
- The routing implementation is simplified and communications are reduced.
The overlap of the same token to more than 1 expert model is called as the Capacity factor. Following is a conceptual depiction of how routing with different expert capacity factors works
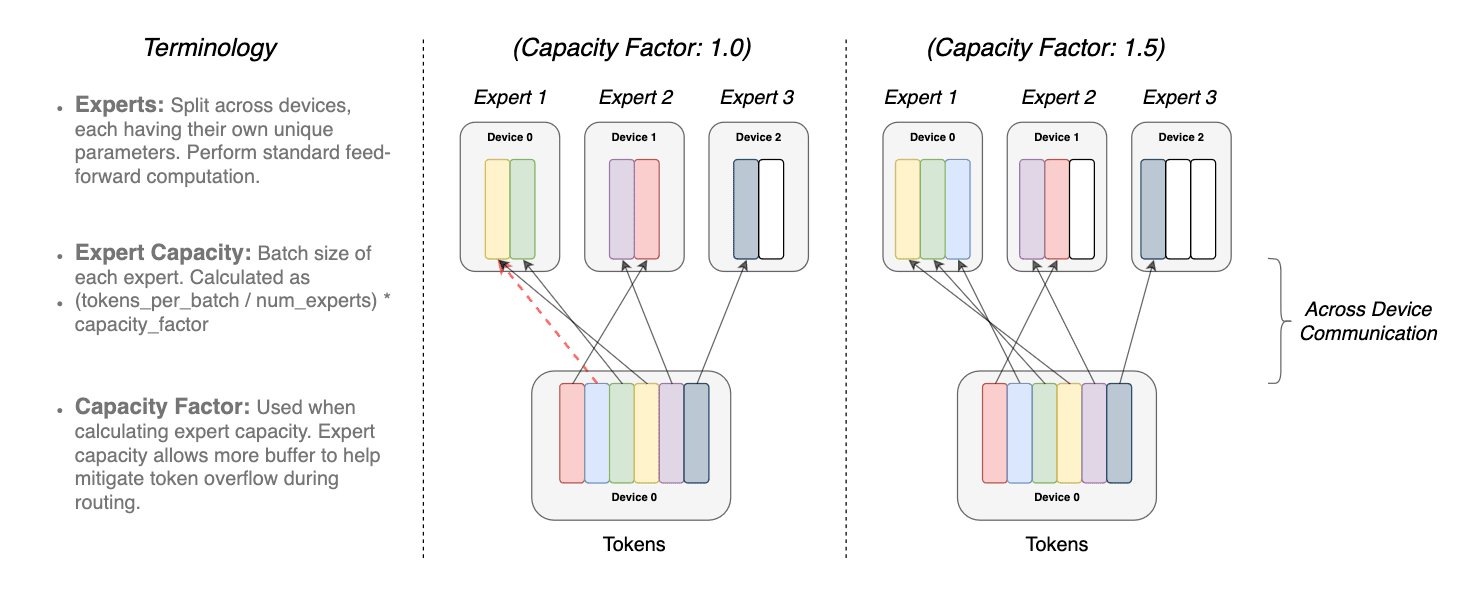 illustration of token routing dynamics. Each expert processes a fixed batch-size
illustration of token routing dynamics. Each expert processes a fixed batch-size
of tokens modulated by the capacity factor. Each token is routed to the expert
with the highest router probability, but each expert has a fixed batch size of
(total tokens/num experts) × capacity factor. If the tokens are unevenly dis-
patched, then certain experts will overflow (denoted by dotted red lines), resulting
in these tokens not being processed by this layer. A larger capacity factor allevi-
ates this overflow issue but also increases computation and communication costs
(depicted by padded white/empty slots). (source https://arxiv.org/pdf/2101.03961.pdf)
When compared with the MoE, findings from the MoE and Switch paper suggest that
- Switch transformers outperform carefully tuned dense models and MoE transformers on a speed-quality basis.
- Switch transformers have a smaller compute futprint than MoE
- Switch transformers perform better at lower capacity factors (1–1.25).

Concluding thoughts
Two caveats, first, that this is all coming from hearsay, and second, my understanding of these concepts is fairly feeble, so I urge readers to take it with a boulder of salt.
But what did Microsoft achieve by keeping this architecture hidden? Well, they created a buzz, and suspense around it. This might have helped them to craft their narratives better. They kept innovation to themselves and avoided others catching up to them sooner. The whole idea was likely a usual Microsoft gameplan of thwarting competition while they invest 10B into a company.
GPT-4 performance is great, but it was not an innovative or breakthrough design. It was an amazingly clever implementation of the methods developed by engineers and researchers topped up by an enterprise/capitalist deployment. OpenAI has neither denied or agreed to these claims (https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed), which makes me think that this architecture for GPT-4 is more than likely the reality (which is great!). Just not cool! We all want to know and learn.
A huge credit goes to Alberto Romero for bringing this news to the surface and investigating it further by reaching out to OpenAI (who did not respond as per the last update. I saw his article on Linkedin but the same has been published on Medium too.
Dr. Mandar Karhade, MD. PhD. Sr. Director of Advanced Analytics and Data Strategy @Avalere Health. Mandar is an experienced Physician Scientist working on the cutting edge implementations of the AI to the Life Sciences and Health Care industry for 10+ years. Mandar is also part of AFDO/RAPS helping to regulate implantations of AI to the Healthcare.
Original. Reposted with permission.
More On This Topic
- GPT-2 vs GPT-3: The OpenAI Showdown
- Meet Gorilla: UC Berkeley and Microsoft’s API-Augmented LLM Outperforms…
- The secret to analysing large, complex datasets quickly and productively?
- HuggingGPT: The Secret Weapon to Solve Complex AI Tasks
- A Deep Dive into GPT Models: Evolution & Performance Comparison
- Can Robots and Humans Combat Extinction Together? Find Out April 17