Image by Author
Earning a certification not only validates your skills but also boosts your self-confidence. Moreover, it signals that you are job-ready for a specific role.
For a beginner, it is highly recommended that after finishing a data science boot camp and working on portfolio projects, it is time to get certified. While DataCamp provides end-to-end career development tools that make certification accessible, many people attempting the exams still fail.
In this blog, I will share my experience of taking the certification exam, the certification process, and how any data science beginner or expert can earn certification in less than two days.
What is a Data Scientist Professional Certificate?
Finding qualified data science talent is tough these days. Companies need data experts like you, but there aren't enough folks with the right skills. Earning a certification from DataCamp is a great way to stand out. It shows employers that your skills are job-ready so you can land that dream role.
Currently, you can get certified for as:
- Data Analyst Associate
- Data Analyst Professional
- Data Scientist Associate
- Data Scientist Professional
- Data Engineer Associate

Image from DataCamp
The Associate certification is ideal for those just starting out and meets entry-level job expectations. The Professional certification, on the other hand, is the next step up and aligns with the skill level expected for roles requiring 2+ years of experience.
In this blog, we will be covering the Professional Data Scientist Certification process.

Image from DataCamp
There is a high demand for data scientists, with thousands of well-paid job openings in the US alone. However, there is a shortage of qualified data professionals. DataCamp's Data Scientist certification can help you get these jobs faster.
Certification Process
The certification process evaluates proficiency across core data science competencies, including exploratory data analysis, data management, statistical modeling, and experimental design. Candidates must demonstrate expert-level fluency in Python or R programming, SQL, communicating analytical insights, and applying these skills to common data science procedures and workflows. The timed and practical certification exams rigorously assess one's readiness to meet the demands of data science roles at the highest level.
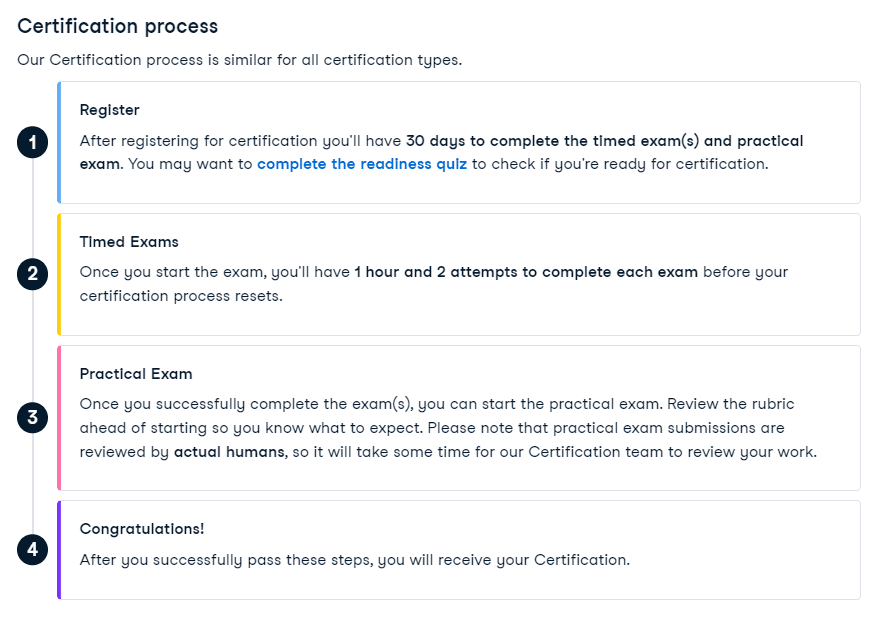
Image from DataCamp certification
What to expect on the timed exams
To earn the Data Scientist Professional Certificate, you must pass two timed exams — DS101 and DS201 — to advance through the practical exam stages.
DS101
The DS101 exam is a 45-minute R or Python assessment of exploratory analysis and statistical experimentation skills including calculating metrics, creating visualizations to demonstrate data characteristics and feature relationships, describing statistical concepts for testing and experimentation, applying sampling methods, and implementing statistical tests.
DS201
The 60-minute DS201 exam evaluates data management in SQL, data cleaning and preparation in Python or R, modeling skills, model evaluation, unsupervised learning, and programming best practices including version control and package building.
What to expect on the practical exam
The practical exam evaluates data visualization and communication skills by having you review a business problem, select and create visualizations, and present a summary of findings; it requires recording and submitting a presentation demonstrating the ability to effectively visualize, frame, convey, and summarize data stories to diverse audiences including business leaders. You can find more information on how DataCamp grades the Data Scientist. To learn about how DataCamp evaluates the data scientist practical exam, you can refer to the rubric for more details.
Tips and Trick for Timed Exam
1. Take Assessment Tests
Before registering for the professional certification exam, I recommend taking as many practice assessment tests as possible. These assessments provide scores and solutions for incorrect answers. Practicing with the timed assessment tests will help you become familiar with the exam format and better manage your time. Going through the practice tests is also an opportunity to learn new concepts and sharpen your skills, setting you up for success on the actual certification exam.
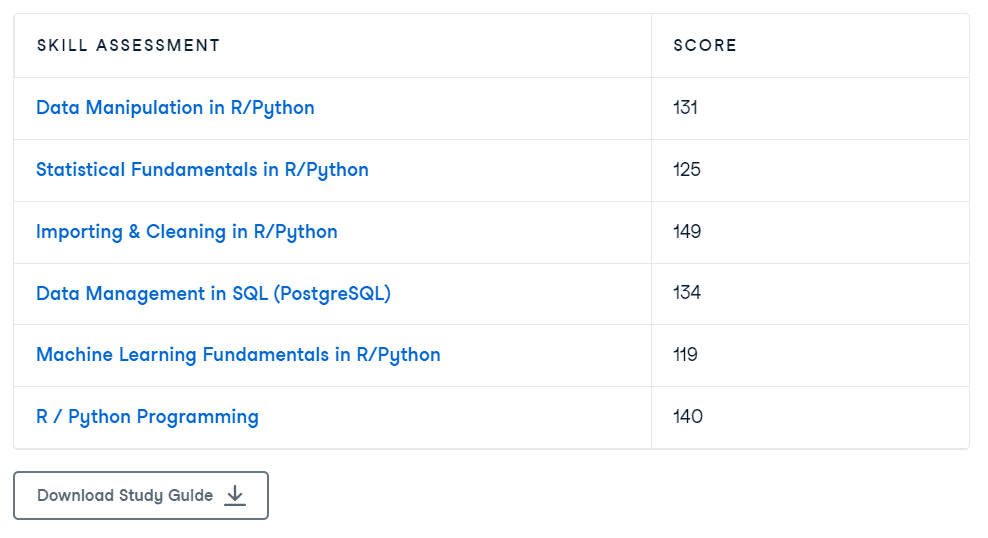
Skill assessment tests
2. Review the Study Guide
Download the Data Scientist Certification Study Guide Data Scientist Certification Study Guide and thoroughly review each objective you must meet for the competencies assessed. The guide provides helpful links to relevant practice assessments for each competency.
3. Take a Short Course
I found statistical tests and SQL data management to be my weaker areas. To address this, I took a few small courses and revisited the forgotten concepts. I highly recommend taking courses to review these concepts, especially if you don't use these tools or concepts in your day-to-day work life.
4. Trust the Process
DataCamp certification offers a wide range of resources, such as assessment tests, study guides, courses, and demos. If you do not pass the certification on your first attempt, you are allowed to retake it once. However, if you do not pass on your second attempt, it is recommended that you wait for two months and work on your weaknesses. You will receive a comprehensive performance report to help you improve.
Tips and Trick for Practical Exam
1. Complete Two End-to-End Data Science Projects
Complete one regression and one classification project using datasets from Kaggle. For each project, work through the data science pipeline including exploratory data analysis, data cleaning, visualizations, feature engineering, model selection, training, and evaluation. Following the full process from start to finish for both a regression and classification problem will help ensure you are on track and build the skills needed to achieve your certification goal. You can also give a try to a clustering project.
2. Take a Sample Practical Exam
Read the project description for the sample exam and ensure that you understand what the head of data expects from you. You will learn a lot by reviewing the sample exam description, solution notebook, and video recording of the presentation.

Sample practical exam
3. Learn from the Experts
When working on a practical exam, look for similar projects on Kaggle, GitHub, or Medium. It will help you understand the necessary steps and popular tools for performing specific tasks. If you encounter difficulties, conduct a Google search to find a solution.
I do not recommend copying and pasting code from Kaggle or other sources. The reviewers will likely detect plagiarized work and result in exam failure. Additionally, in real work scenarios, managers can easily identify copied.
When reviewing other experts' solutions, thoroughly read the explanation. Doing so will aid in composing the results of experiments, analytical reports, and conclusions.
4. Presentation
I used Canva to create my presentation, but various tools are available to create one. Here is a list of steps you can follow to develop and present your project outcomes:
- Use a maximum of 3 lines per slide to avoid overcrowding.
- Explain results in your own words rather than reading directly from slides.
- Include relevant visualizations and images from your project.
- Avoid technical jargon as the audience is non-technical.
- Limit presentation to 10 slides and 8 minutes maximum.
- Practice your presentation at least 3 times before recording.
- Watch your recorded presentation and re-record if you feel improvements could be made.
What’s Next?
After earning certification, enhance your portfolio and profiles by highlighting your accomplishments. Share your certification on LinkedIn and showcase it on GitHub, Deepnote, DataCamp, DagsHub, and other platforms to strengthen your data science portfolio.
Image from author’s profile
If you are job searching, continue applying on job boards while working on data science projects to showcase your skills. Developing projects demonstrate hands-on experience that will increase your visibility to recruiters and help them better understand your capabilities.
Join the DataCamp certified community and networking groups on Discord and Slack to connect with others in the field. Use these communities to seek mentoring opportunities that can help in your job search. Remember, finding a full-time role should now be your priority, so dedicate sufficient time to the search process.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
More On This Topic
- Start a Career in a Growing Field with Google’s Data Analytics Professional…
- How I 14Xed my salary in 14 years as a data analytics/science professional
- Become a Data Science Professional in Five Steps
- Top 5 NLP Cheat Sheets for Beginners to Professional
- Machine Learning for Cybersecurity Certificate at U. of Chicago
- How to ace A/B Testing Data Science Interviews





 About the author: Alex Woodie
About the author: Alex Woodie