Gleen’s tech-savvy chatbot for Discord and Slack attracts Solana founder in oversubscribed round Rita Liao 12 hours 
There’s no shortage of chatbot services trying to earn a place in the myriad channels on Discord and Slack. California-based Gleen, founded by Microsoft and LinkedIn veterans, is offering its enterprise-grade chatbot to the most demanding segment of the market — technical communities, like a blockchain infrastructure channel on Discord, and it has raised some fresh funding to work on the product.
The narrow focus is a good start as it pushes Gleen to solve the most urgent issue in large language models today: hallucination. Hallucination, which happens when artificial intelligence makes up false information but answers with confidence, is especially high-stakes for discussions that involve esoteric topics, as a false but assertive answer could easily mislead participants.
“If someone says the price of Uniswap [the token of the namesake decentralized crypto exchange] is going to go up to $200, then it can be a massive manipulation of the market,” Ashu Dubey, co-founder and CEO of Gleen, told TechCrunch in an interview. “We decided that we were going to fix this particular problem of hallucination before we could actually be a serious player, so we fixed it.”
Gleen’s vision attracted investors from both the established software world and the nascent crypto sphere in its $4.9 million oversubscribed funding round. Institutional investors include Slow Ventures, 6th Man Ventures, South Park Commons, Spartan Group and CoinShares. Among its list of angels are Anatoly Yakovenko, co-founder of the popular blockchain network Solana; Mike Derezin, former COO of blockchain data provider Chainlink; Will Papper, co-founder of decentralized investing protocol Syndicate; and ISM Angels.
When asked about competition, Dubey argued that many chatbots on the market are mere “wrappers” of ChatGPT and other large language models, so the responses they give are likely the same as those from calling the OpenAI API.
That approach doesn’t solve hallucinations. Instead, Gleen created its own proprietary machine learning layer that sources from enterprise knowledge, which can then cross-check LLM responses to avoid hallucination. LLM is less than 20% of its tech stack; the rest of the work goes to how Gleen stores the data and its proprietary system retrieves data to generate the most accurate answer based on domain knowledge.
Once Gleen’s system is confident that it has an answer, it sends it to various LLMs, be it OpenAI, Anthropic or a fine-tuned Llama, to generate a response. All in all, Gleen’s model has been trained on 100,000 pairs of questions and answers.
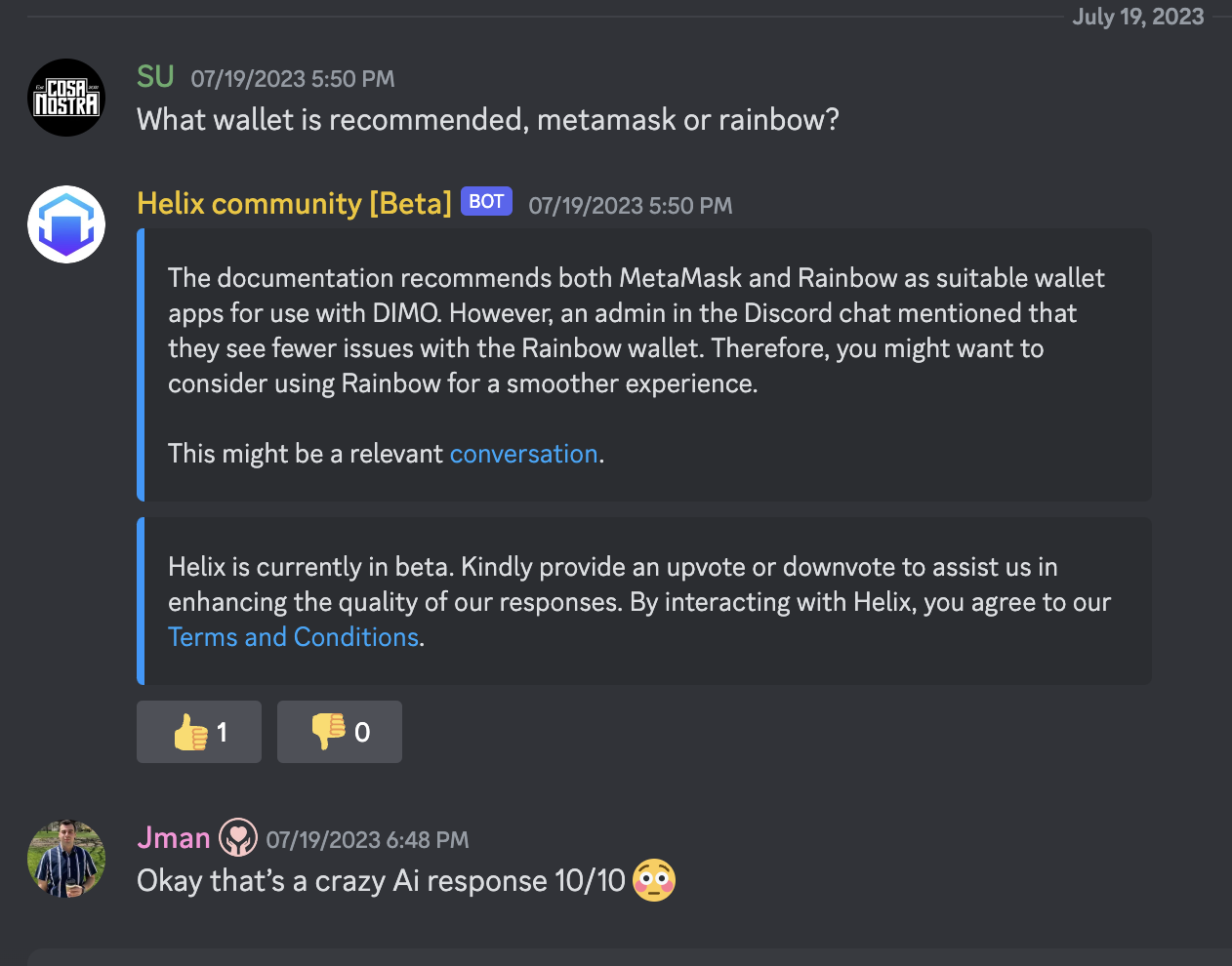
Gleen’s chatbot interacting with users on Discord. Image: Gleen
“Search is our own proprietary algorithm, and that’s where our secret sauce is,” the founder said. “The communities and companies, where the subject matter is highly technical or the quality of the answer matters a lot, is where we get the best traction because those companies or communities appreciate what a good response versus a bad response means.”
Every time it onboards a new user, Gleen needs to learn its domain knowledge by gleaning data from its knowledge base, forums, Slack or Discord discussions. The ability to abstract from that information is one of the sta0rtup’s strengths, according to Dubey, as it “[doesn’t] need very clean documentation.”
Gleen got its start by providing its Discord chatbot to a web3 customer, though now it generates more revenues from non-crypto users. Run by a team of eight employees, Gleen is now serving more than 10 customers who pay by the number of conversations generated for the bot.
“Customer support is easily a $10 billion market,” said Dubey. Gleen is moving into the medium-sized enterprise market, and its distant goal is to “solve customer service for everyone, from mom-and-pop stores to very large corporations.” The early user base is highly technical, but it wants to be “industry agnostic” in the future, which then will be a real test of its AI system’s adaptability.
Going forward, Gleen plans to spend its fresh funding on building, driving sales and marketing. A big part of its go-to-market strategy will be educating users on issues around hallucination, security and compliance in the field of generative AI, according to Dubey.
“Though we will have a sales force, inbound will continue to be our biggest channel. That’s also very defensible going forward,” he said.
Gleen’s direction is shaped not just by the fast-evolving AI technologies it leverages but also the type of its customers, that is, companies dealing with cutting-edge, changing technologies like itself. The unpredictability nature of these variables presents one of the startup’s biggest challenges.
“As a CEO, you’re investing in a particular technology or taking a product to the market. But what if the underlying technology completely changes one year from now? You have to restart from scratch,” Dubey said.
“If we are halfway or 25% into research, we just keep an eye out on what’s best out there, so we are not married to the technology. We are married to the customer problem. We want to solve the customer support problem for these new companies that are coming up in the best possible way.”
Discord updates its bot with ChatGPT-like features, rolls out AI-generated conversation summaries and more

















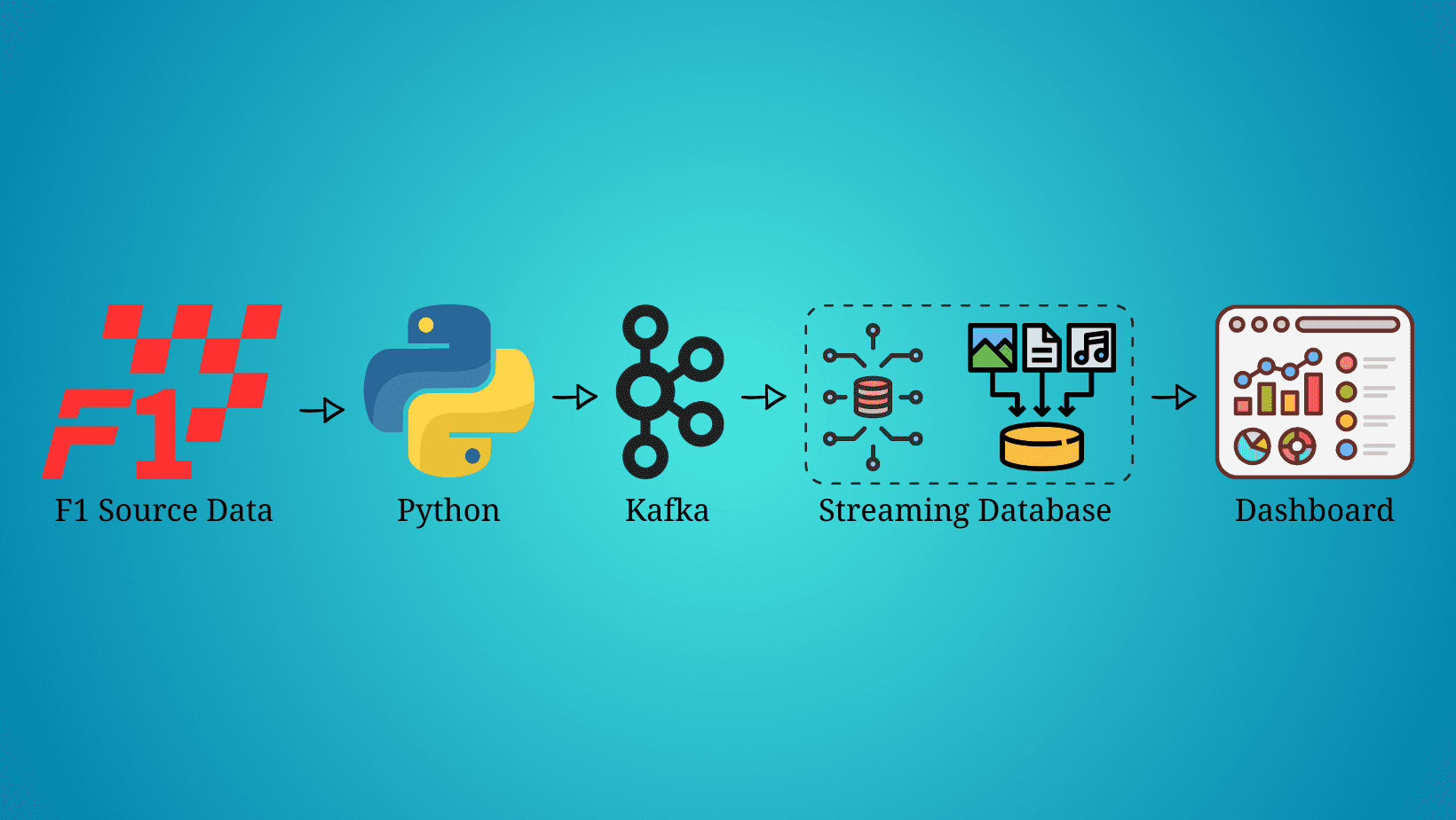
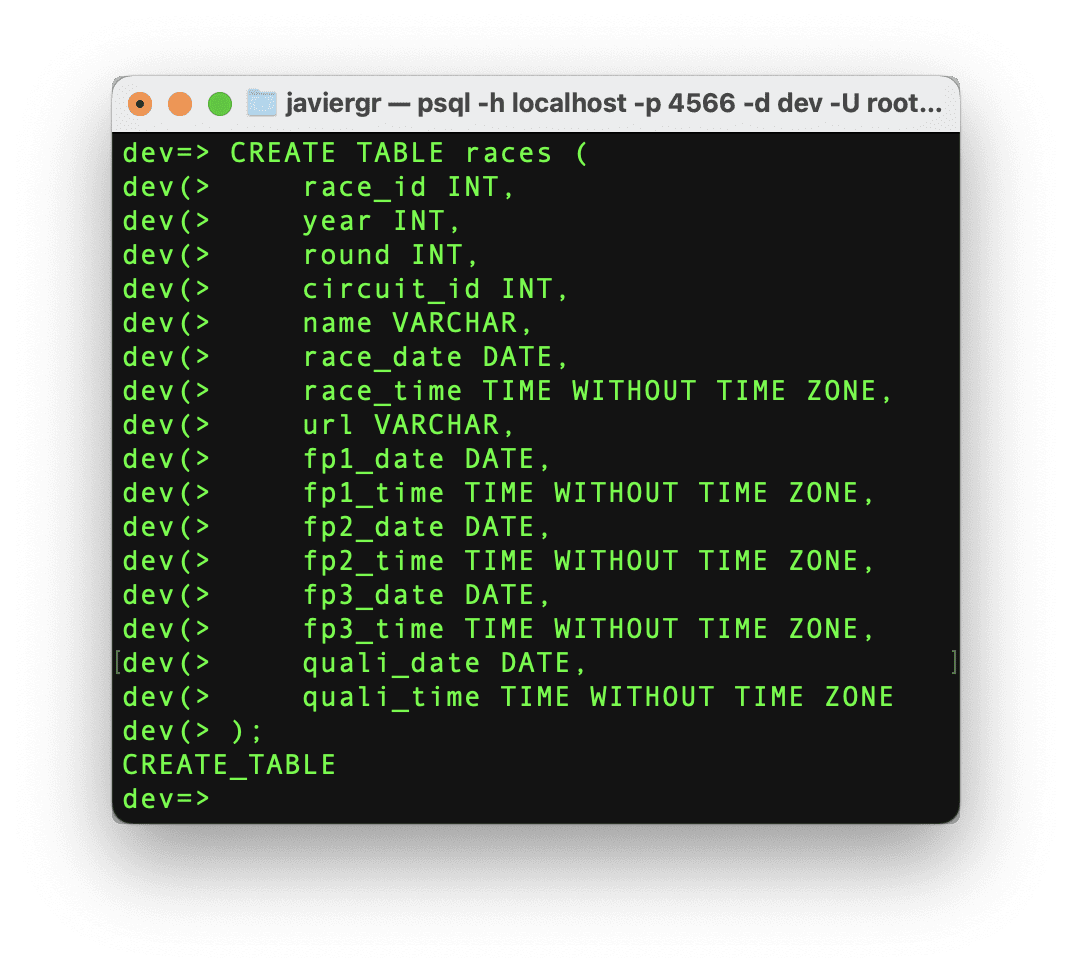
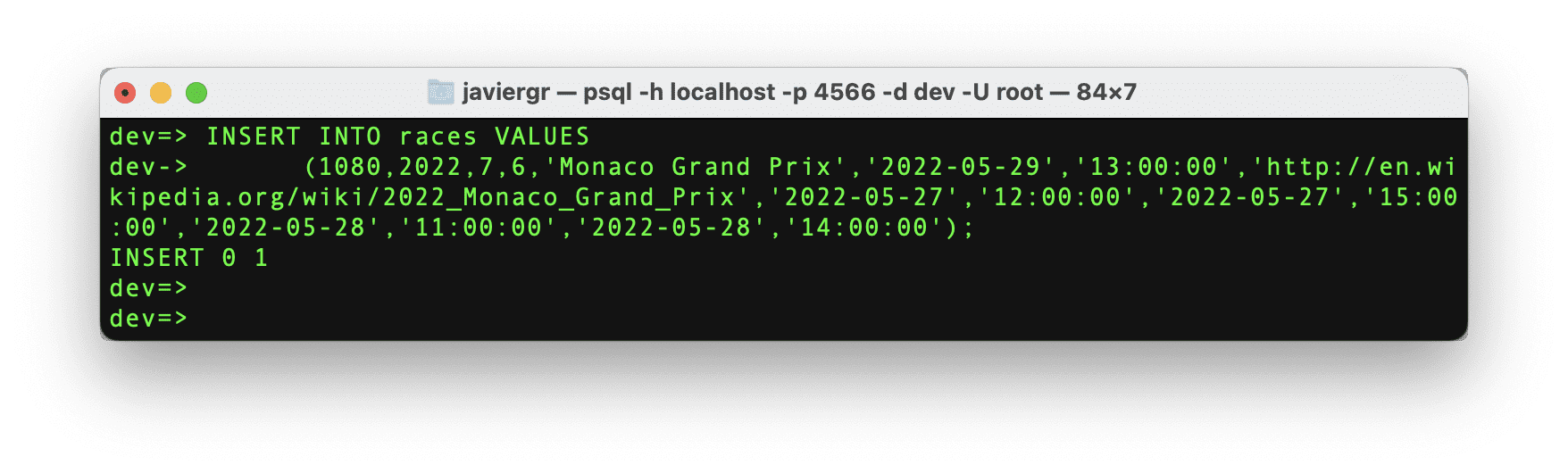
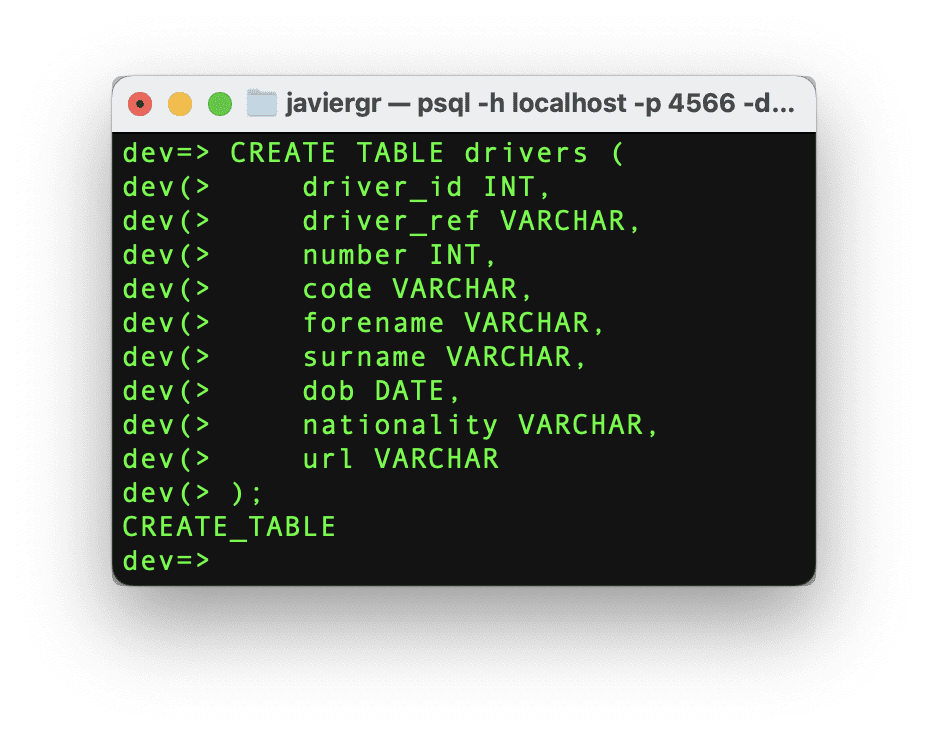
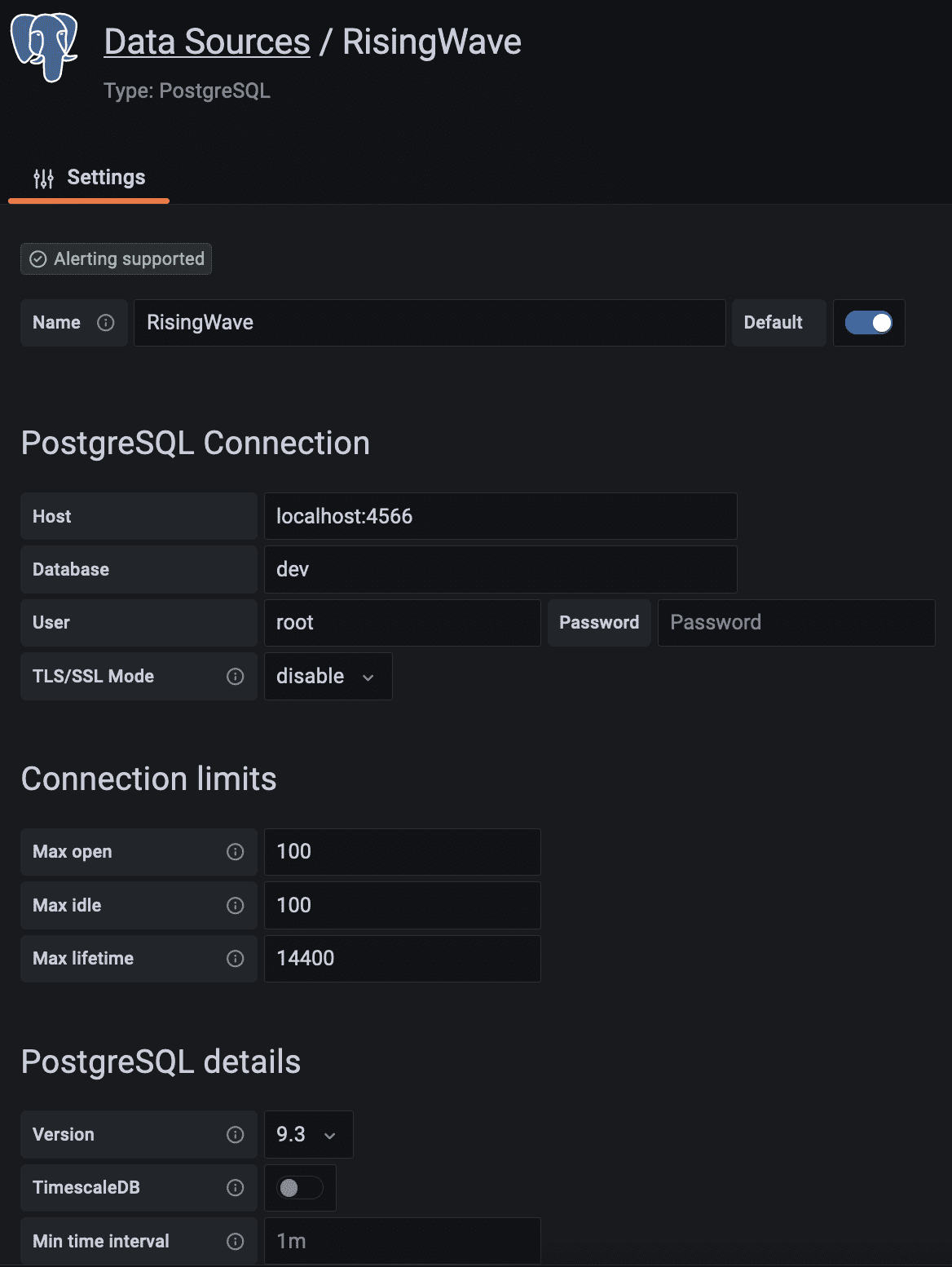
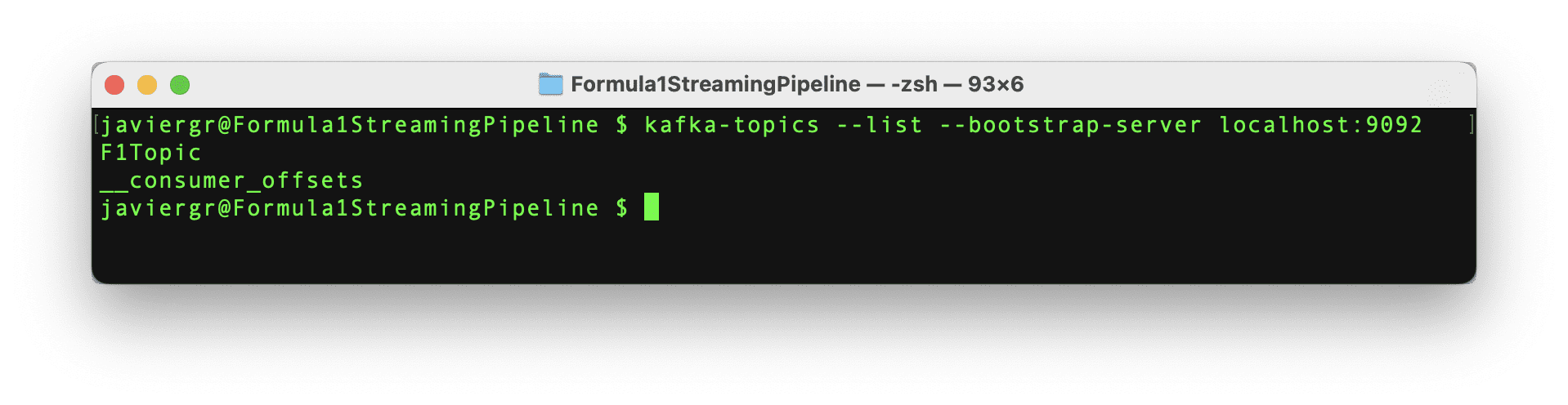 Setting up the Streaming Database RisingWave
Setting up the Streaming Database RisingWave 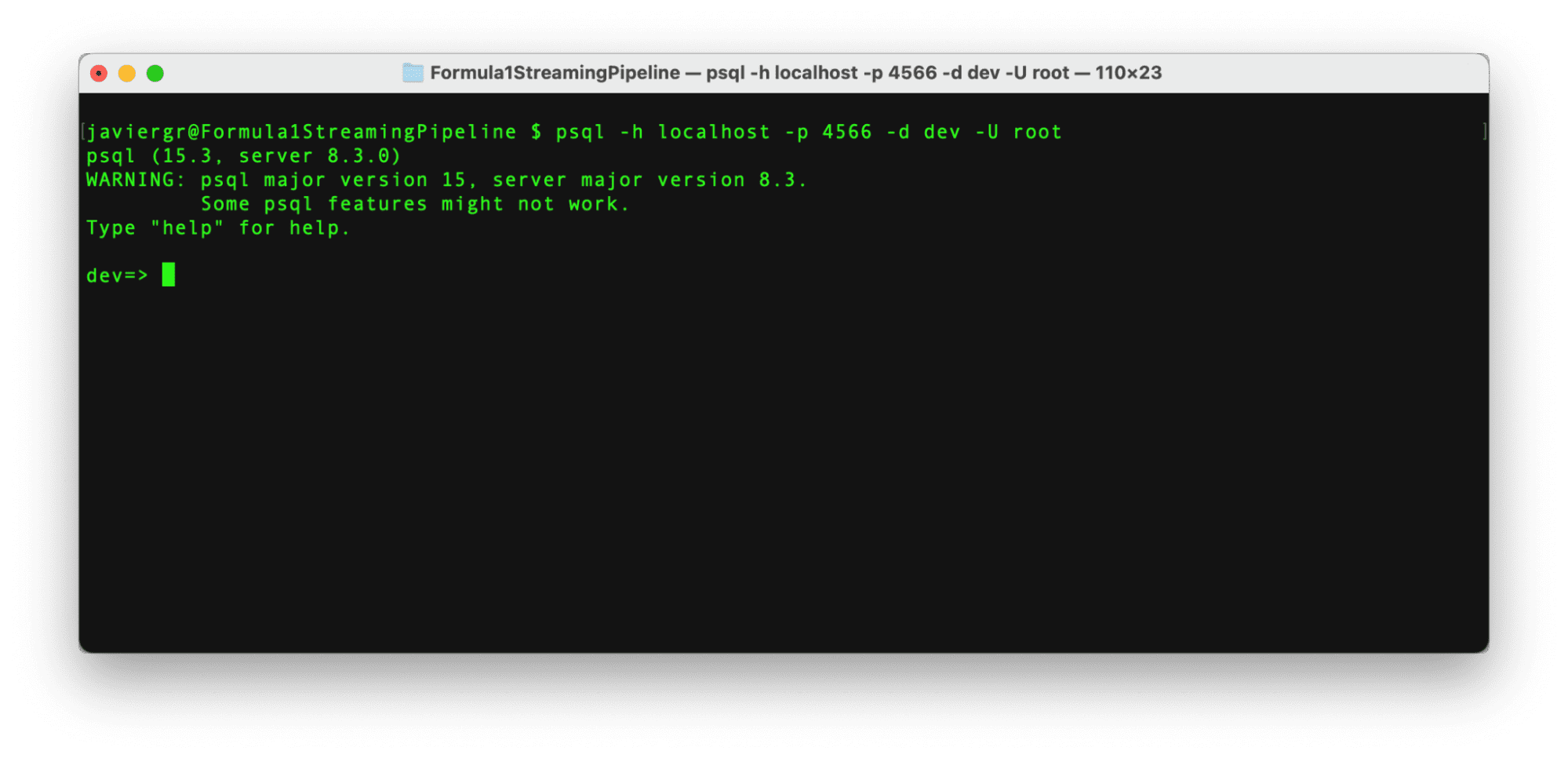
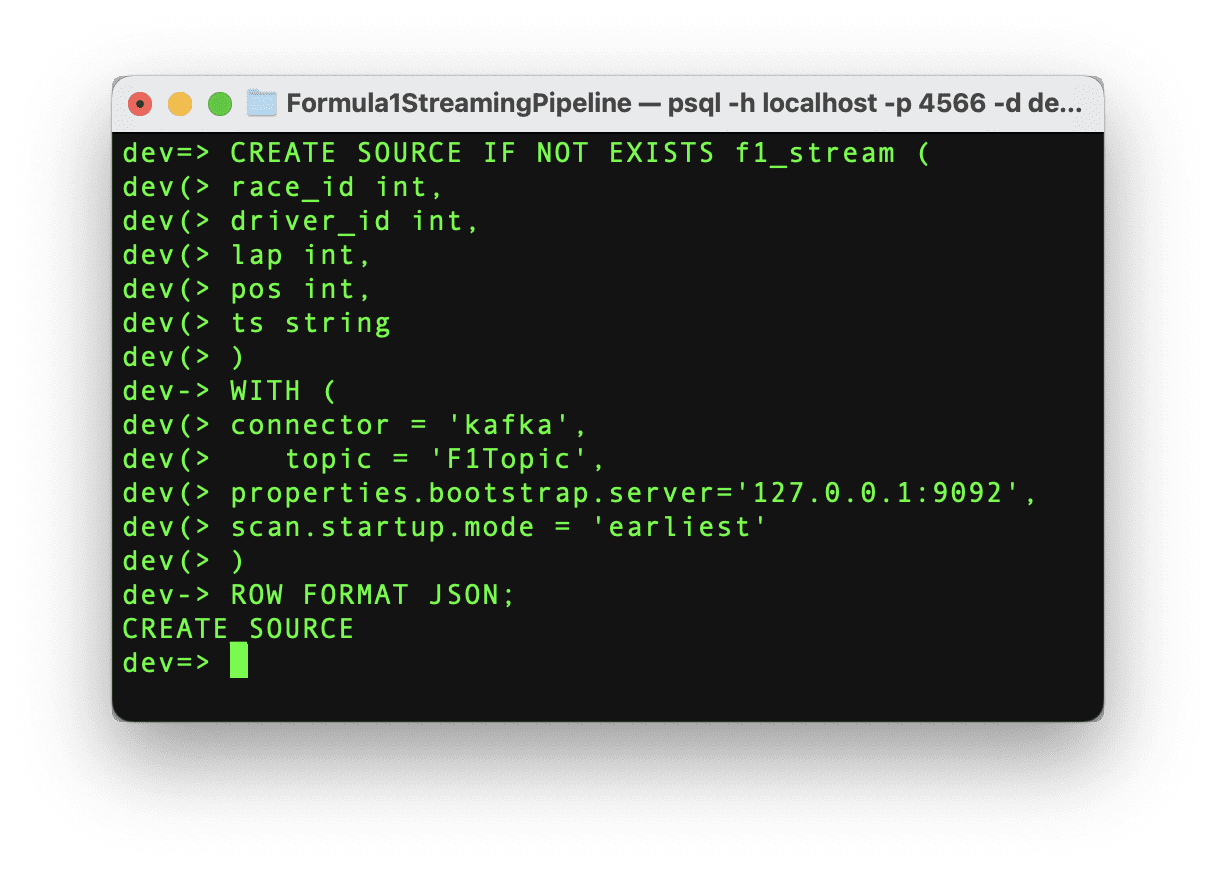
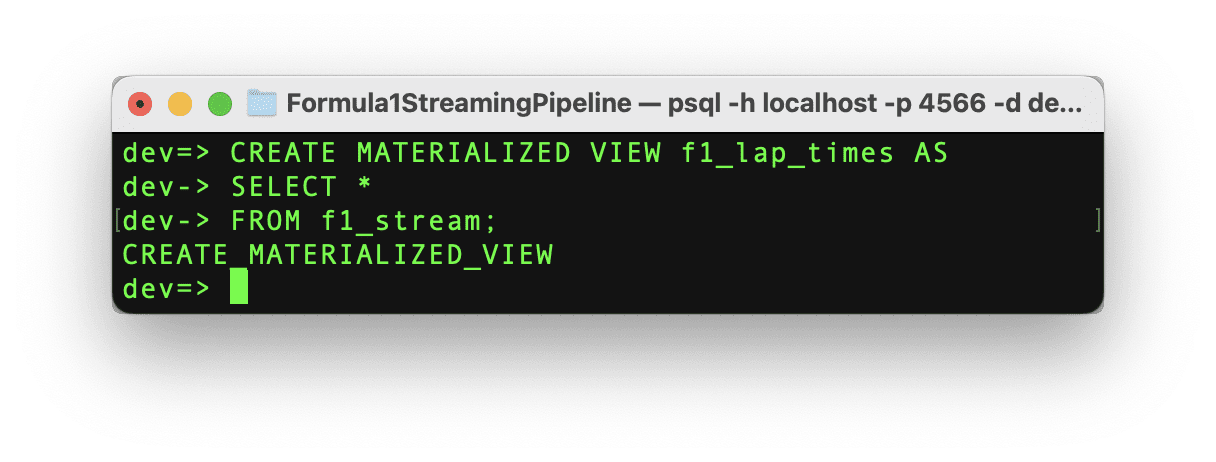
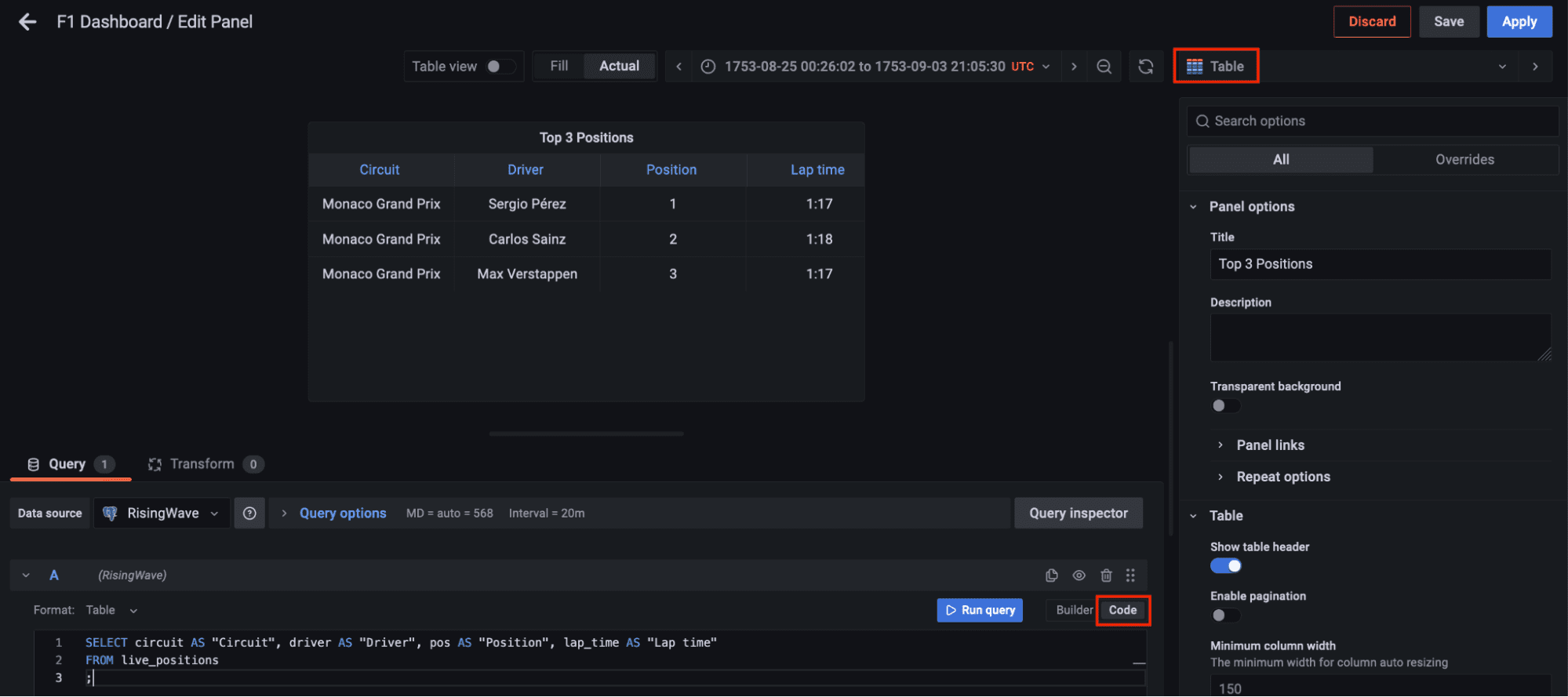
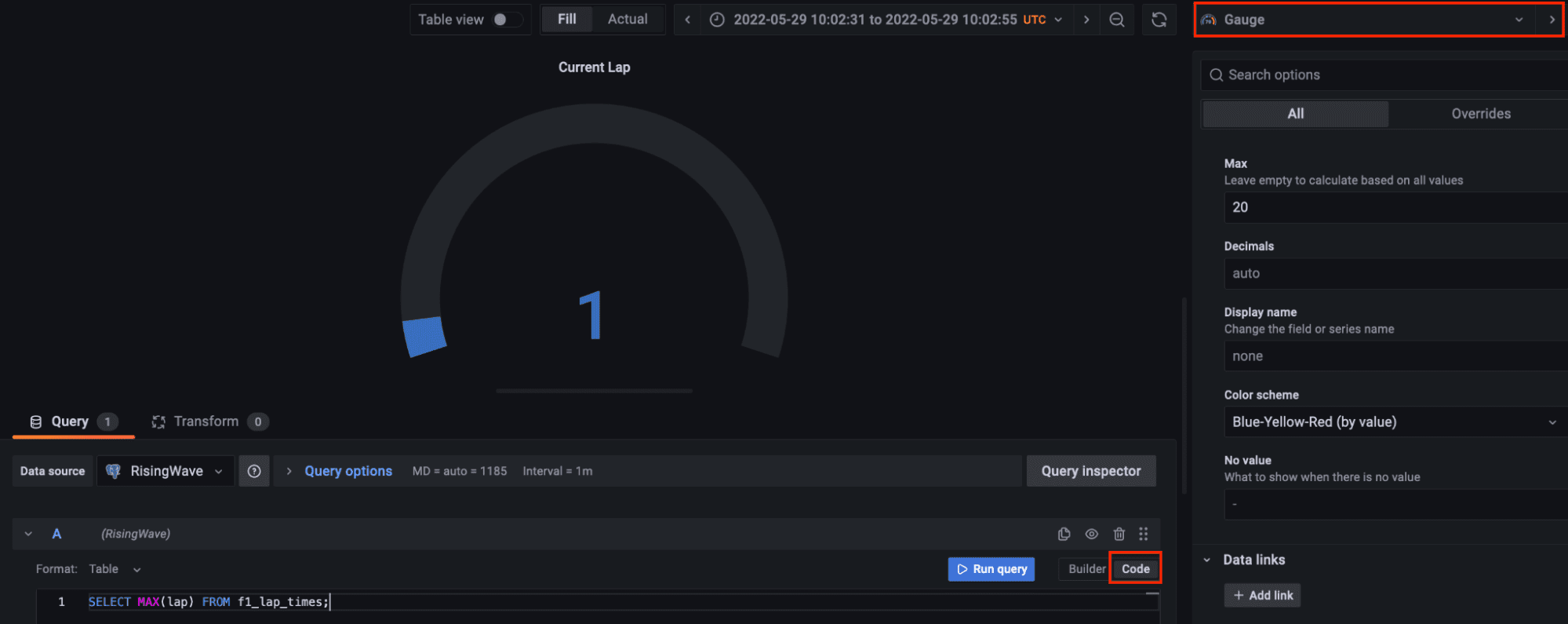
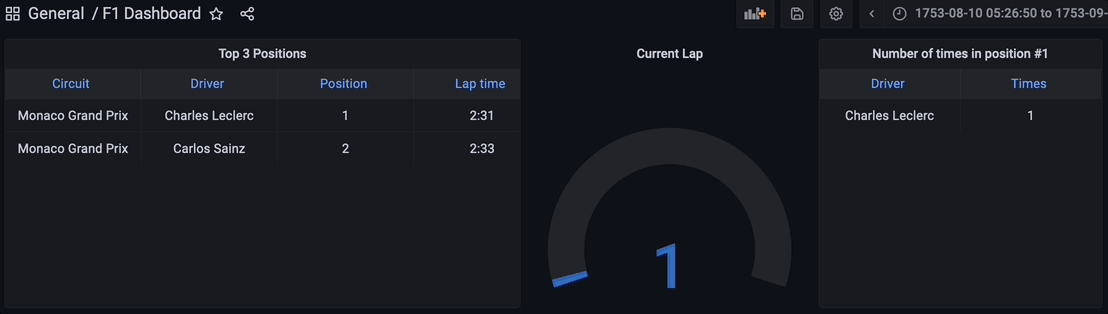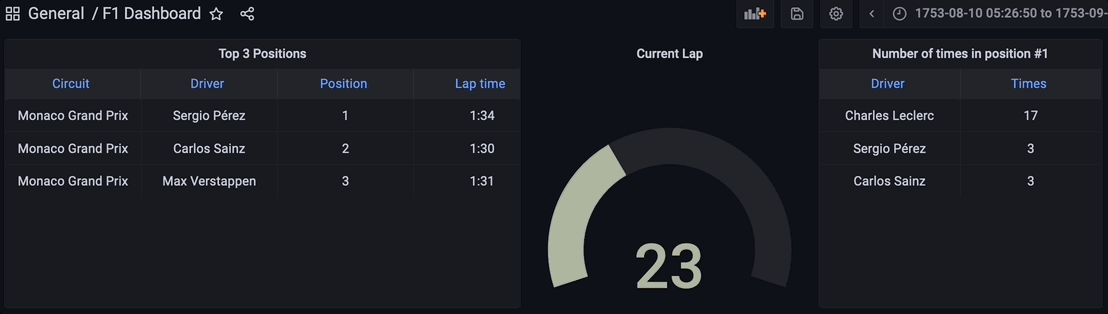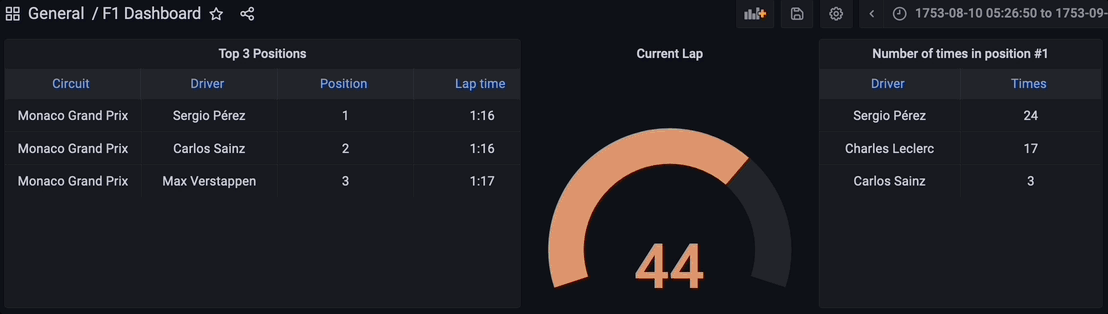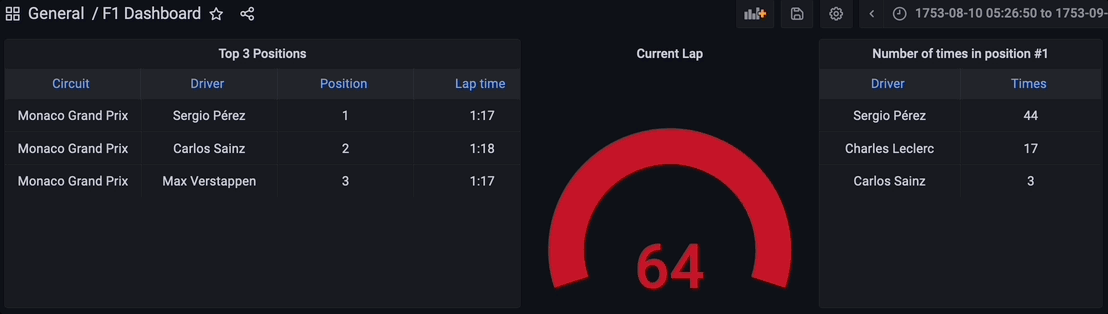
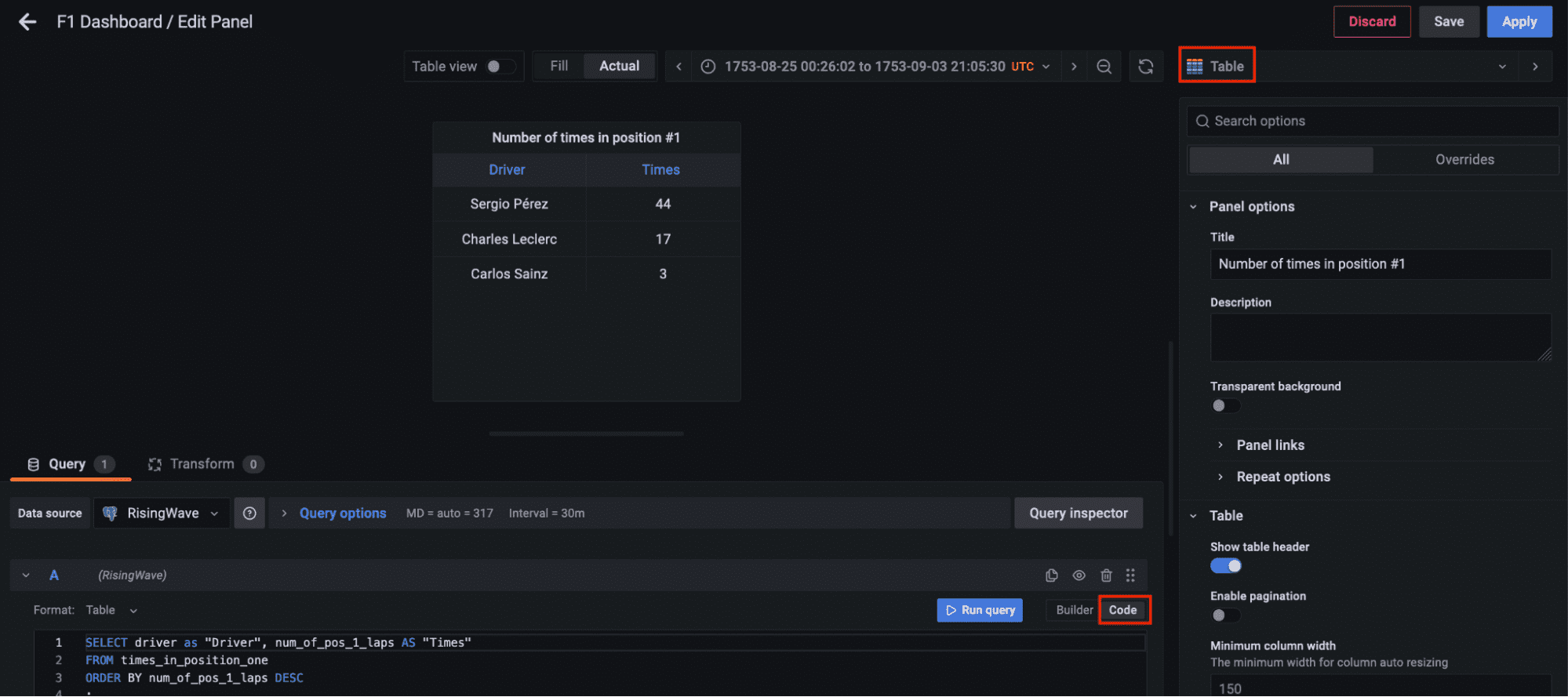 Visualizing the Results
Visualizing the Results