This week in AI: The generative AI boom drives demand for custom chips Kyle Wiggers Devin Coldewey 7 hours 
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week in AI, D-Matrix, an AI chip startup, raised $110 million to commercialize what it’s characterizing as a “first-of-its-kind” inference compute platform. D-Matrix claims that its tech enables inference — that is, running AI models — at a lower cost of ownership than GPU-based alternatives.
“D-Matrix is the company that will make generative AI commercially viable,” said Playground Global partner Sasha Ostojic, a D-Matrix backer.
Whether D-Matrix delivers on that promise is an open question. But the enthusiasm for it and startups like it — see NeuReality, Tenstorrent, etc. — shows growing awareness among the tech industry players of the severity of the AI hardware shortage. As generative AI adoption accelerates, the suppliers of the chips that run these models, like Nvidia, are struggling to keep pace with demand.
Recently, Microsoft warned shareholders of potential Azure AI service disruptions if it can’t get enough AI chips — specifically GPUs — for its datacenters. Nvidia’s best AI chips are reportedly sold out until 2024, thanks partly to sky-high demand from overseas tech giants including Baidu, ByteDance, Tencent and Alibaba.
It’s no wonder that Microsoft, Amazon and Meta, among others, are investing in developing in-house next-gen chips for AI inferencing. But for the companies without the resources to pursue that drastic course of action, hardware from startups like D-Matrix might be the next best thing.
In the most optimistic scenario, D-Matrix and its kin will act as an equalizing force, leveling the playing field for startups in the generative AI — and broader AI, for that matter — space. A recent analysis by AI research firm SemiAnalysis reveals how the AI industry’s reliance on GPUs is dividing the tech world into “GPU rich” and “GPU poor,” the former group being populated by incumbents like Google OpenAI and the latter group comprising mostly European startups and government-backed supercomputers like France’s Jules Verne.
Inequity plagues the AI industry, from the annotators who label the data used to train generative AI models to the harmful biases that often emerge in those trained models. Hardware threatens to become another example. That’s not to suggest all hopes are riding on startups like D-Matrix — new AI techniques and architectures could help address the imbalance, too. But cheaper, commercially available AI inferencing chips promise to be an important piece of the puzzle.
Here are some other AI stories of note from the past few days:
- Imbue raises $200M: Imbue, the AI research lab formerly known as Generally Intelligent, has raised $200 million in a Series B funding round that values the company at over $1 billion. Imbue launched out of stealth last October with an ambitious goal: to research the fundamentals of human intelligence that machines currently lack. The new tranche will be put toward the startup’s efforts to achieve that.
- eBay generates listings from photos: eBay is rolling out a new AI tool for marketplace sellers that can generate a product listing from a single photo. It’s potentially a major time saver. But as some users have discovered, eBay’s generative AI tools so far have tended to underwhelm in the quality department.
- Anthropic launches a paid plan: Anthropic, the AI startup co-founded by ex-OpenAI employees, has announced the launch of its first consumer-facing premium subscription plan, Claude Pro, for Claude 2 — Anthropic’s AI-powered, text-analyzing chatbot.
- OpenAI launches a dev conference: OpenAI will host a developer conference — its first ever — on November 6, the company announced this week. At the one-day OpenAI DevDay event, which will feature a keynote address and breakout sessions led by members of OpenAI’s technical staff, OpenAI said in a blog post that it’ll preview “new tools and exchange ideas” — but left the rest to the imagination.
- Zoom rebrands AI tools — and intros new ones: To stay competitive in the crowded market for videoconferencing, Zoom is updating and rebranding several of its AI-powered features, including the generative AI assistant formerly known as Zoom IQ.
- Are AI models doomed to hallucinate?: Large language models like OpenAI’s ChatGPT all suffer from the same problem: they make stuff up. But will that always be the case? We ask experts for their two cents.
- Prosecutors combat AI child exploitation: The attorneys general in all 50 U.S. states, plus four territories, signed onto a letter calling for Congress to take action against AI-enabled child sexual abuse material. Generative AI is generally benign in the child pornography department. But in the worst cases, as the attorneys general point out, it can be leveraged to facilitate abuse.
- Artisse generates photos of you: A new tool, Artisse, allows users to generate AI photos of themselves by first uploading a series of selfies. That’s not incredibly novel; other tools do this. But Artisee claims to improve on the current crop of AI photo apps by offering a broader range of both input and output capability and more realism in the resulting photos, even if set in fantastical realms.
More machine learnings

Image Credits: UZH / Leonard Bauersfeld
In first place, literally, we have this AI-driven high-speed drone, which managed to beat the human world champions at the sport, in which the pilots guide their drones at speeds of up to 100 km/h through a series of gates. An AI model was trained in a simulator, which “helped avoid destroying multiple drones in the early stages of learning,” and performed all its calculations in real time, achieving the best lap by half a second. Humans still respond better to changing conditions like light and course switcheroos, but it may only be a matter of time before the AI catches up to them there, too.
Machine learning models are advancing in other, unexpected modalities as well: Osmo, which aims to “give computers a sense of smell,” published a paper in Science showing that scent can in fact reliably be quantified and mapped. “RGB is a three-dimensional map of all colors…We view our discovery of the Principal Odor Map (POM) as the olfactory version of RGB.” The model successfully predicted the characteristics of scents it hadn’t encountered before, bearing out POM’s validity. The company’s first market looks to be streamlining fragrance synthesis. This paper actually made the rounds as a preprint last year but now it’s in Science, which means it actually counts.
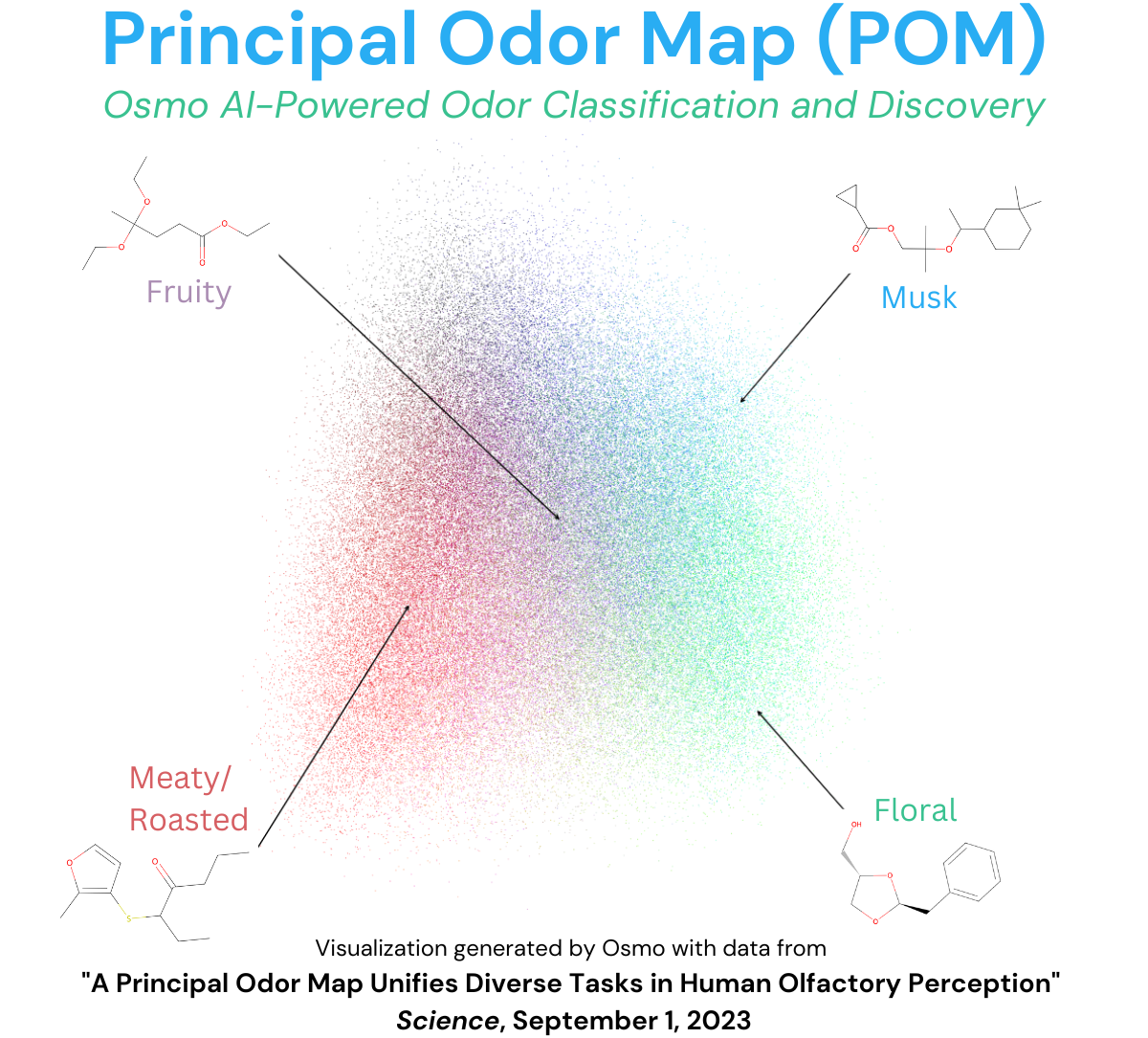
The Principal Odor Map, or as I call it, Smellspace. Image Credits: Osmo
It would not be accurate to say that AI is also good at audition in this other study, but it is fitting that we have another sense in the mix. Biologists at Imperial College London recorded almost 36,000 hours of audio from more than 300 sites across Costa Rica so they could track wildlife there. It would have taken 20 years, or 20 grad students 1 year, to listen to it all, but machine learning models are great at pulling signal out of noise, so they analyzed it in two months. Turns out Costa Rican howlers don’t like it where there’s less than 80% tree cover, and are more sensitive to human presence than those in Mexico.
Microsoft’s AI for Good Research Lab has a couple projects along similar lines, which Juan Lavista Ferres gets into in this post. And here, in Spanish. Basically it’s the same problem of too much data and not enough time or people to look at it. With specially trained models, however, they can work through hundreds of thousands of motion-triggered photos, satellite images, and other data. By quantifying things like the extent and secondary effects of deforestation, projects like these provide solid empirical backing for conservation efforts and laws.
No roundup is complete without some new medical application, and indeed at Yale they have found that ultrasounds of the heart can be analyzed by a machine learning model to detect severe aortic stenosis, a form of heart disease. Making a diagnosis like this faster and easier can save lives, and even when it’s not 100% confident, it can tip a non-specialist care provider off that maybe a doctor should be consulted.
Last we have a bit of analysis from reporters at ChinaTalk, who put Baidu’s latest LLM, Ernie, through the wringer. It works primarily in Chinese, so it’s all second hand, but the gist is as you might expect from the country’s restrictive regulations around AI. “Spicy” topics like Taiwanese sovereignty are rejected, and it made “moral assertions and even policy proposals” that sometimes reflect the current regime, and at other times are a little odd. It loves Richard Nixon, for instance. But it does what some LLMs seem incapable of doing: just shutting up when it thinks it’s entering dangerous territory. Would that we all had such admirable discretion.


 Conclusion
Conclusion