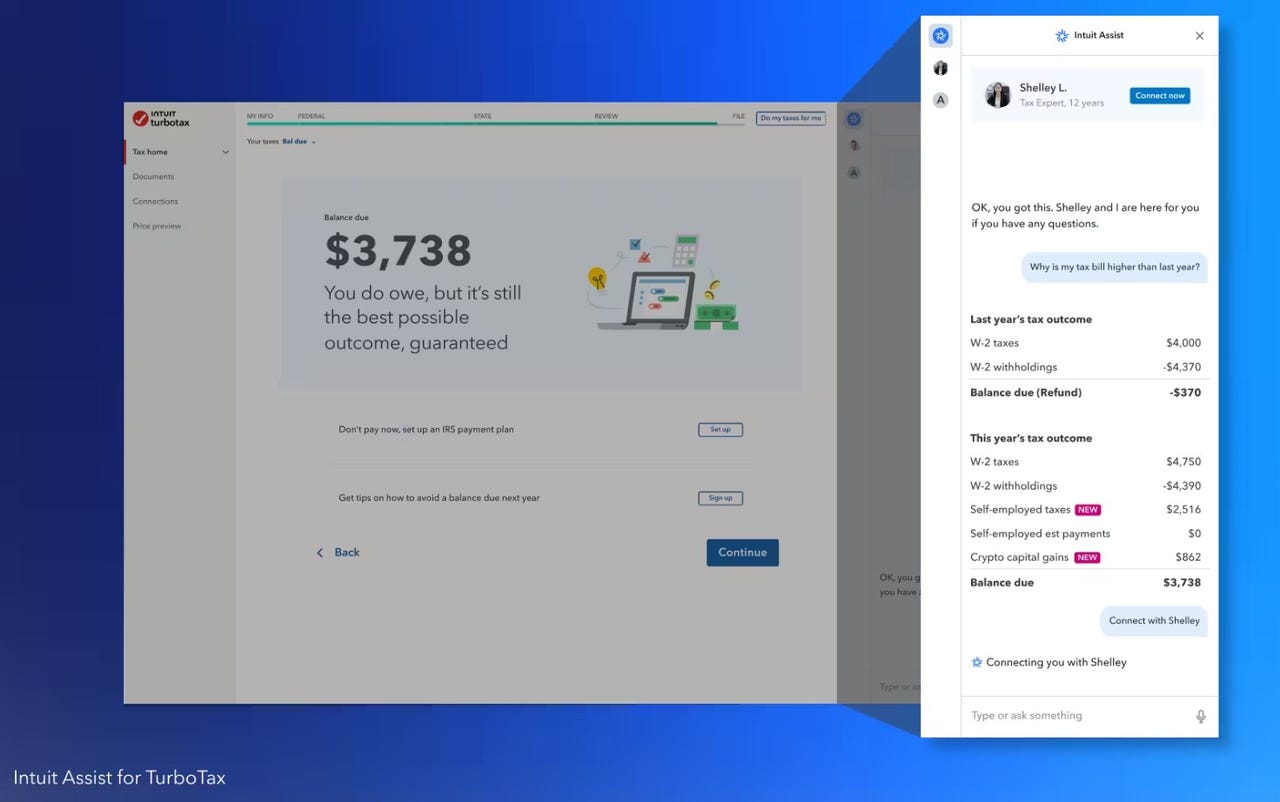
Enfabrica, which builds networking hardware to drive AI workloads, raises $125M Kyle Wiggers 7 hours 
Enfabrica, a company building networking chips designed to handle AI and machine learning workloads, today announced that it raised $125 million in a Series B funding round that values the company at “five times” its Series A post-money valuation, according to co-founder and CEO Rochan Sankar.
Led by Atreides Management with participation from Sutter Hill Ventures, Nvidia, IAG Capital Partners, Liberty Global Ventures, Valor Equity Partners, Infinitum Partners and Alumni Ventures, the new tranche brings Enfabrica’s total raised to $148 million. Sankar says that it’ll be put toward supporting Enfabric’s R&D and operations as well as expanding its engineering, sales and marketing teams.
“It’s notable that Enfabrica raised a round of this magnitude in a highly challenging funding environment for chip startups — and venture-funded deeptech in general — and, in doing so, has set itself apart from many of its chip startup peers in the industry,” Sankar said. “As generative AI and large language models continue to drive the largest infrastructure push in cloud computing across a multitude of industries, solutions like Enfabrica’s have the potential to address a very high demand for networking technologies.”
Enfabrica might’ve emerged from stealth in 2023, but it began its journey in 2020. Sankar, formerly the director of engineering at Broadcom, teamed up with Shrijeet Mukherjee, who previously headed up networking platforms and architecture at Google, to build a startup — Enfabrica — to meet what they observed as growth in the AI industry’s appetite for “parallel, accelerated and heterogeneous” infrastructure — in other words, GPUs.
“We reasoned that networking silicon and systems needed to follow a similar paradigm shift to enable this kind of compute infrastructure at massive scale,” Sankar said. “The biggest challenge posed by the current AI revolution is the scaling of AI infrastructure – both in terms of cost of compute and sustainability of compute.”
With Sankar as CEO and Mukherjee as chief development officer, along with a few founding engineers hailing from companies like Cisco, Meta and Intel, Enfabrica began developing an architecture for networking chips that could deliver on the I/O and “memory movement” requirements of parallel workloads, including AI.
Sankar asserts that conventional networking chips, such as switches, struggle to keep up with the data movement needs of modern AI workloads. Some of the AI models being trained today, like Meta’s Llama 2 and GPT-4, ingest massive data sets during the training process — and network switches can end up being a bottleneck, Sankar says.
“A significant portion of the scaling problem and bottleneck for the AI industry lies in the I/O subsystems, memory movement and networking attached to GPU compute,” he said. “There is a massive need to bridge the growing AI workload demand to the overall cost, efficiency, sustainability and ease of scaling the compute clusters on which they run.”
In its quest to develop superior networking hardware, Enfabrica focused on parallelizability.
Enfabrica’s hardware — which it calls the Accelerated Compute Fabric Switch, or ACF-S for short — can deliver up to “multi-terabit-per-second” data movement between GPUs, CPUs and AI accelerator chips in addition to memory and networking devices. Employing “standards-based” interfaces, the hardware can scale to tens of thousands of nodes and cut GPU compute for a large language model (along the lines of Llama 2) by around 50 percent for at the same performance point, Enfabric claims.
“Enfabrica’s ACF-S devices complement GPUs, CPUs and accelerators by providing efficient, high-performance networking, I/O and memory attached within a data center server rack,” Sankar explained. “To that end, the ACF-S is a converged solution that eliminates the need for disparate, traditional server I/O and networking chips such as rack-level networking switches, server network interface controllers and PCIe switches.”

A rendering of Enfabrica’s ACF-S networking hardware.
Sankar also made the case that ACF-S devices can benefit companies handling inferencing — that is, running trained AI models — by allowing them to use the fewest possible number of GPUs, CPUs and other AI accelerators. That’s because — according to Sankar — ACF-S can make more efficient use of existing hardware by moving vast amounts of data very quickly.
“The ACF-S is agnostic to the type and brand of AI processor used for AI computation, as well as to the exact models deployed — allowing for AI infrastructure to be built across many different use cases and to support multiple processor vendors without proprietary lock-in,” he added.
Enfabrica might be well-funded. But it isn’t the only networking chip startup chasing after the AI trend, it’s worth noting.
This summer, Cisco announced a range of hardware — the Silicon One G200 and G202 — to support AI networking workloads. For their parts, both Broadcom and Marvell — incumbents in the enterprise networking space — offer switches that can deliver up to 51.2 terabits per second of bandwidth; Broadcom recently launched the Jericho3-AI high-performance fabric, which can connect to up to 32,000 GPUs.
Sankar wasn’t willing to talk about Enfabrica’s customers, as it’s relatively early days — part of the latest funding tranche will support Enfabrica’s production and go-to-market efforts, he says. Still, Sankar asserts that Enfabrica is sitting in a position of strength given the attention on — and enormous investments being made in — AI infrastructure.
According to the Dell’Oro Group, AI infrastructure investments will raise data center capital expenditures to over $500 billion by 2027. Investment in AI-tailored hardware broadly speaking, meanwhile, is expected to see a compound annual growth rate of 20.5% over the next five years, according to IDC.
“The current cost and power footprint of AI compute, whether on-prem on in the cloud, is — or if not, should be — a top priority for every CIO, C-Suite exec, and IT organization who deploys AI services,” he said. “Despite the economic headwinds that have impaired the tech startup world since late 2022, Enfabrica has advanced its funding, product progress and market potential by virtue of a substantially innovative and disruptive technology to existing networking and server I/O chip solutions [and] the magnitude of the market opportunity and technology paradigm shift that generative AI and accelerated computing has given rise to over the past 18 months.”
Enfabrica, based in Mountain View, has just over 100 employees across North America, Europe and India.






















 Cloud
Cloud