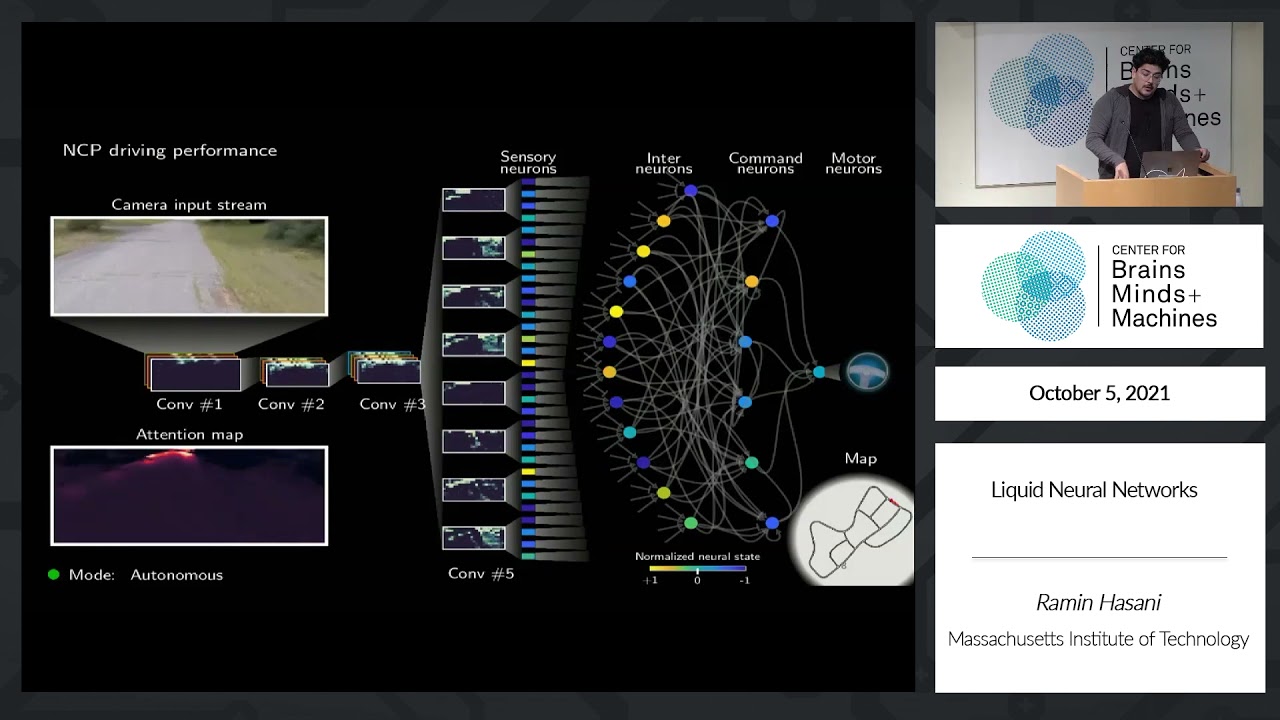
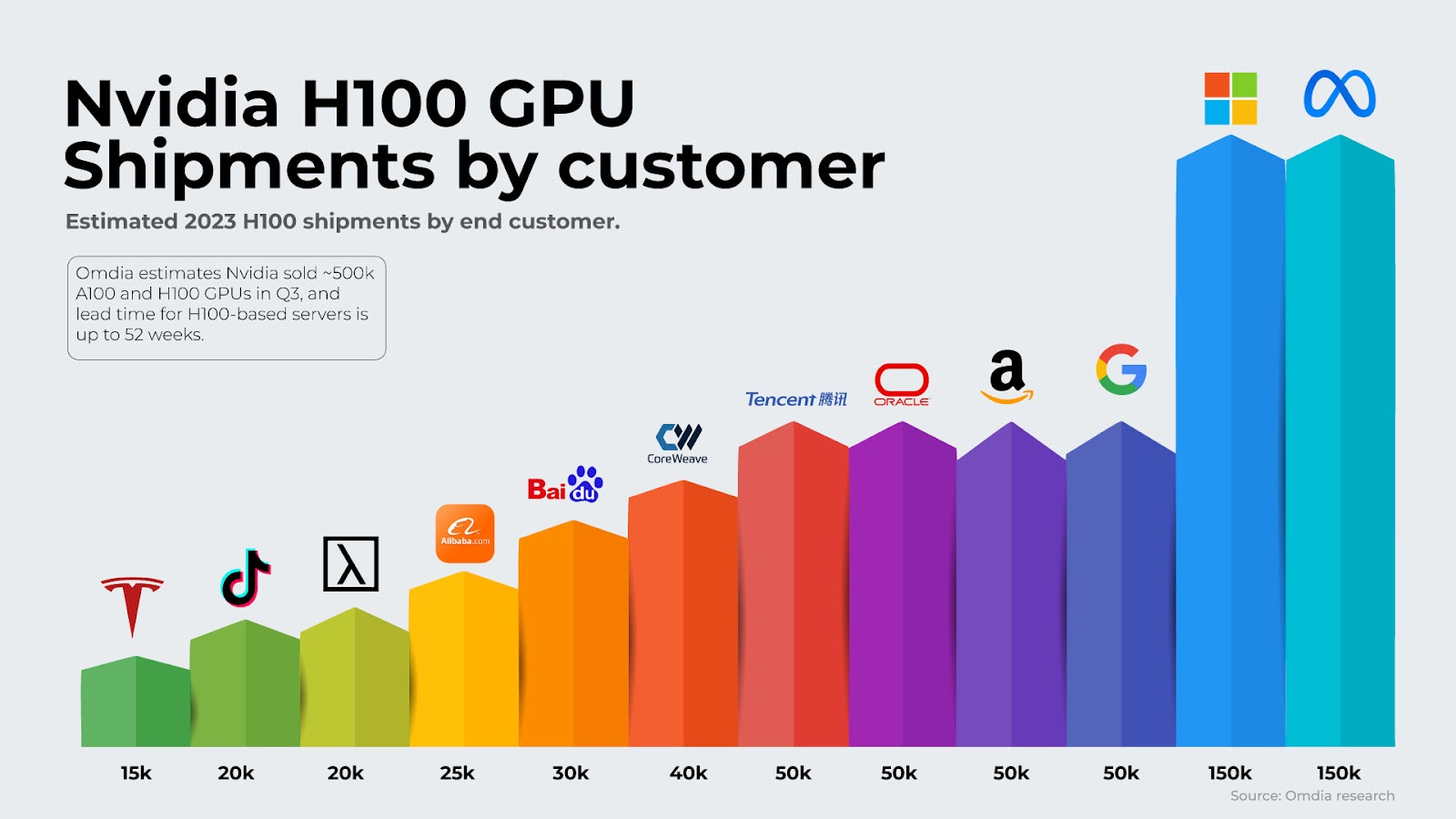
While the world wants more of NVIDIA GPUs, AMD has released MI300X, which is arguably a lot faster than NVIDIA. AMD aims to challenge NVIDIA not only through the hardware side but also plans to corner it on the software side with its open source ROCm, a direct competitor to NVIDIA’s CUDA.
“As important as the hardware is, software is what really drives innovation,” Lisa Su said, talking about the ROCm, which is releasing in the coming week.
At Advancing AI, it was clear that AMD’s focus on software has paved the way for success. Victor Peng, President of AMD, showed how building a strong ecosystem has enabled the company to create a successful open source framework in ROCm.

Peng introduced the latest iteration of its parallel computing framework, ROCm 6, optimised specifically for a comprehensive software stack for AMD Instinct, particularly catering to large language models in generative AI.
Everyone loves open source
“We architectured ROCm to be modular and open source for broad user accessibility and rapid contribution from the open source AI community,” Peng said, adding that it is the software strategy highlighting how CUDA is proprietary and closed source.
Furthermore, ROCm is now also supported on Radeon GPUs, along with Ryzen 1.0 software, for making AI on edge, making it more accessible for AI researchers and developers.
During the presentation, Peng also showed the testimonial of Phillipe Tillet of OpenAI, who wrote, “OpenAI is working with AMD in support of an open ecosystem. We plan to support AMD’s GPUs including MI300 in the standard Triton distribution starting with the upcoming 3.0 release.” Tillet is the creator of Triton.
In a collaborative effort with three emerging AI startups – Databricks, Essential AI, and Lamini – AMD showcased how these companies leverage the AMD Instinct M1300X accelerators and the open ROCm 6 software stack to deliver differentiated AI solutions for enterprise customers. All three of the startups have been using ROCm along with MI250X and boasting about its performance on various instances.

Ion Stoica, co-founder of Databricks; Ashish Vaswani, co-founder of Essential AI; and Sharon Zhou, co-founder of Lamini, discussed how they have been leveraging AMD hardware and software all this while, and proving that the open nature of the technology has been helping them fully own the technology.
“ROCm runs out of the box from day one,” Stoica said, highlighting it was very easy to integrate it within Databricks stack after the acquisition of MosaicML, with just a little optimisation. He further added that Databricks is using MI250X for almost all its software workflows, and are eagerly waiting for MI300X.
ROCm Vs CUDA: Apple to Apple Comparison
“We have reached beyond CUDA,” said Zhou. Lamini has previously highlighted in their blog how they have found its moat with AMD, and how ROCm is production-ready. The whole mission of Lamini was to help build small language models within enterprises easily accessible and easy to use, and AMD with ROCm has been helping them.
AMD continues its strategic investments in software with companies such as Mipsology and Nod.AI, which have helped the company improve on its software part of AI massively.
Many of the open source tools such as PyTorch are already ready to be used with ROCm on MI300X, which makes it easily accessible for most of the developers. The features of this CUDA alternative include support for new data types, advanced graph and kernel optimisations, optimised libraries, and state-of-the-art attention algorithms.
Notably, the performance boost is remarkable, with an approximately 8x increase in overall latency for text generation compared to ROCm 5 running on the MI250.
Peng showcased how MI300X with ROCm 6 is eight times faster than MI250X with ROCm 5, when inference Llama 2 70B.
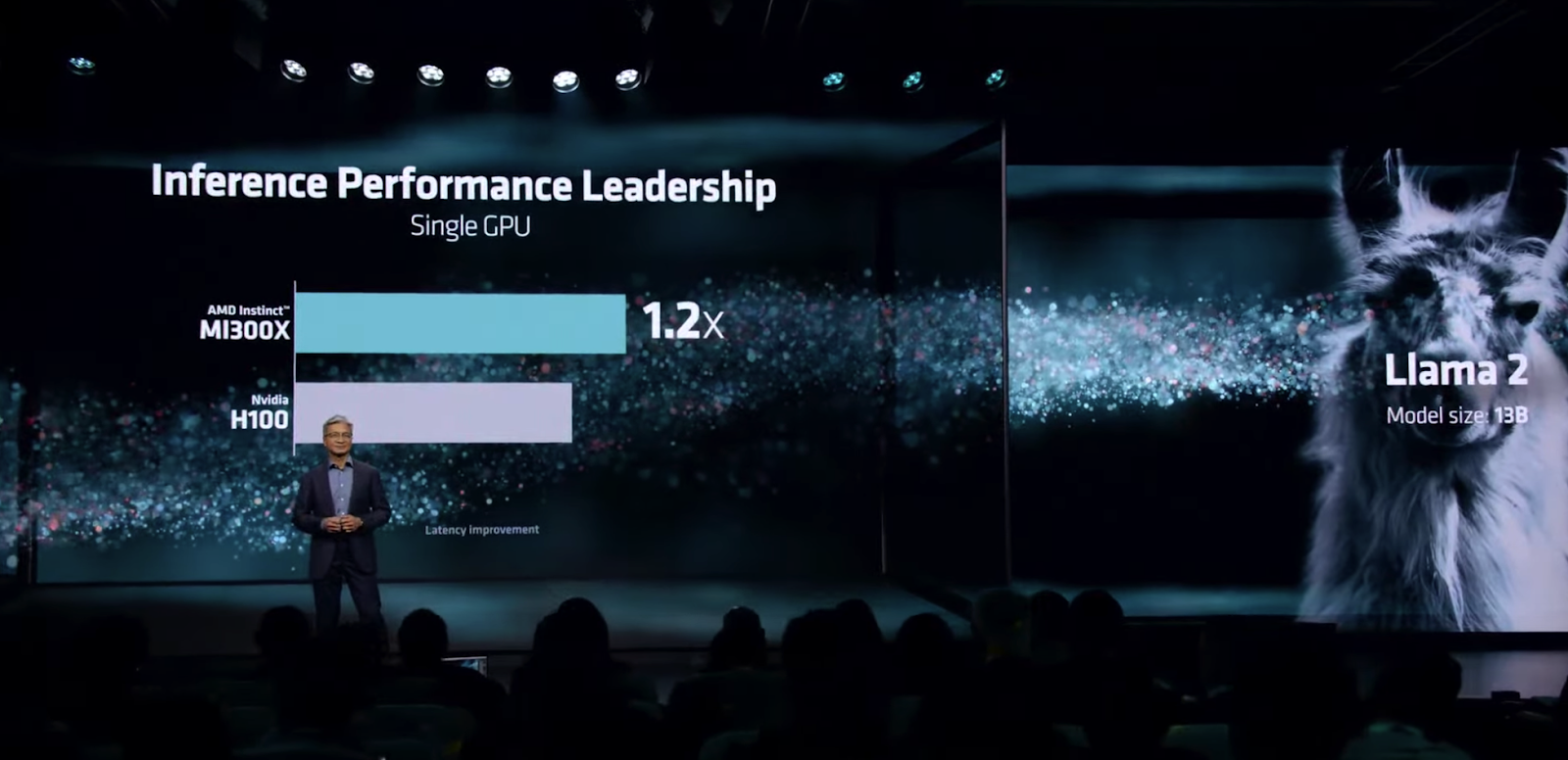
On smaller models such as Llama 2 13B, ROCm with MI300X showcased 1.2 times better performance than NVIDIA coupled with CUDA on a single GPU.
ROCm 6 now supports Dynamic FP16, BF16, and FP8, for higher performance and reducing memory usage. The new release also comes with open-art libraries and supports various key features for generative AI, including FlashAttention, HIPGraph, and vLLM, with 1.3X, 1.4X, and 2.6X speed up respectively.
ROCm 6 and MI300X will drive an inflection point in developer adoption, “I’m confident of that. We are empowering innovators to realise the profound benefits of pervasive AI, faster on AMD,” concluded Peng.
The post AMD’s ROCm is Ready To Challenge NVIDIA’s CUDA appeared first on Analytics India Magazine.