Thanks to their capabilities, text-to-image diffusion models have become immensely popular in the artistic community. However, current models, including state-of-the-art frameworks, often struggle to maintain control over the visual concepts and attributes in the generated images, leading to unsatisfactory outputs. Most models rely solely on text prompts, which poses challenges in modulating continuous attributes like the intensity of weather, sharpness of shadows, facial expressions, or age of a person precisely. This makes it difficult for end-users to adjust images to meet their specific needs. Furthermore, although these generative frameworks produce high-quality and realistic images, they are prone to distortions like warped faces or missing fingers.
To overcome these limitations, developers have proposed the use of interpretable Concept Sliders. These sliders promise greater control for end-users over visual attributes, enhancing image generation and editing within diffusion models. Concept Sliders in diffusion models work by identifying a parameter direction corresponding to an individual concept while minimizing interference with other attributes. The framework creates these sliders using sample images or a set of prompts, thus establishing directions for both textual and visual concepts.

Ultimately, the use of Concept Sliders in text to image diffusion models can result in image generation with minimal degree of interference, and enhanced control over the final output while also increasing the perceived realism without altering the content of the images, and thus generating realistic images. In this article, we will be discussing the concept of using Concept Sliders in text to image frameworks in greater depth, and analyze how its use can result in superior quality AI generated images.
An Introduction to Concept Sliders
As previously mentioned, current text-to-image diffusion frameworks often struggle to control visual concepts and attributes in generated images, leading to unsatisfactory results. Moreover, many of these models find it challenging to modulate continuous attributes, further contributing to unsatisfactory outputs. Concept Sliders may help mitigate these issues, empowering content creators and end-users with enhanced control over the image generation process and addressing challenges faced by current frameworks.
Most current text-to-image diffusion models rely on direct text prompt modification to control image attributes. While this approach allows image generation, it is not optimal as changing the prompt can drastically alter the image's structure. Another approach used by these frameworks involves Post-hoc techniques, which invert the diffusion process and modify cross-attentions to edit visual concepts. However, Post-hoc techniques have limitations, supporting only a limited number of simultaneous edits and requiring individual interference passes for each new concept. Additionally, they can introduce conceptual entanglement if not engineered carefully.
In contrast, Concept Sliders offer a more efficient solution for image generation. These lightweight, easy-to-use adaptors can be applied to pre-trained models, enhancing control and precision over desired concepts in a single interference pass with minimal entanglement. Concept Sliders also enable the editing of visual concepts not covered by textual descriptions, a feature distinguishing them from text-prompt-based editing methods. While image-based customization methods can effectively add tokens for image-based concepts, they are difficult to implement for editing images. Concept Sliders, on the other hand, allow end-users to provide a small number of paired images defining a desired concept. The sliders then generalize this concept and automatically apply it to other images, aiming to enhance realism and fix distortions such as in hands.
Concept Sliders strive to learn from and address issues common to four generative AI and diffusion framework concepts: Image Editing, Guidance-based Methods, Model Editing, and Semantic Directions.
Image Editing
Current AI frameworks either focus on using a conditional input to guide the image structure, or they manipulate cross-attentions of source image with its target prompt to enable single image editing in text to image diffusion frameworks. Resultantly, these approaches can be implemented only on single images and they also require latent basis optimization for every image as a result of evolving geometric structure over timesteps across prompts.
Guidance-based Methods
The use of classifier-free guidance based methods have indicated their ability to enhance the quality of the generated images, and boost text-image alignment. By incorporating guidance terms during interference, the method improves the limited compositionality inherited by the diffusion frameworks, and they can be used to guide through unsafe concepts in diffusion frameworks.
Model Editing
The use of Concept Sliders can also be seen as a model editing technique that employs a low-rank adaptor to output a single semantic attribute that makes room for continuous control that aligns with the attribute. Fine-tuning-based customization methods are then used to personalize the framework to add new concepts. Furthermore, the Custom Diffusion technique proposes a way to finetune cross-attention layers to incorporate new visual concepts into pre-trained diffusion models. Conversely, the Textual Diffusion technique proposes to optimize an embedding vector to activate model capabilities and introduce textual concepts into the framework.
Semantic Direction in GANs
Manipulation of semantic attributes is one of the key attributes of Generative Adversarial Networks with the latent space trajectories found to be aligned in a self-supervised manner. In diffusion frameworks, these latent space trajectories exist in the middle layers of the U-Net architecture, and the principal direction of latent spaces in diffusion frameworks captures global semantics. Concept Sliders train low-rank subspaces corresponding to special attributes directly, and obtains precise and localized editing directions by using text or image pairs to optimize global directions.
Concept Sliders : Architecture, and Working
Diffusion Models and LoRA or Low Rank Adaptors
Diffusion models are essentially a subclass of generative AI frameworks that operate on the principle of synthesizing data by reversing a diffusion process. The forward diffusion process initially adds noise to the data, thus the transition from an organized state to a complete Gaussian noise state. The primary aim of diffusion models is to reverse the diffusion process by gradually denoising the image, and sampling a random Gaussian noise to generate an image. In real world applications, the primary objective of Diffusion frameworks is to predict the true noise when the complete Gaussian noise is fed as input with additional inputs like conditioning and timestep.
The LoRA or Low Rank Adaptors technique decomposes weight updates during fine-tuning to enable efficient adaption of large pre-trained frameworks on downstream tasks. The LoRA technique decomposes weight updates for a pre-trained model layer with respect to both the input and the output dimensions, and constrains the update to a low-dimensional subspace.
Concept Sliders
The primary aim of Concept Sliders is to serve as an approach to fine-tune LoRA adaptors on a diffusion framework to facilitate a greater degree of control over concept-targeted images, and the same is demonstrated in the following image.

When conditioned on target concepts, Concept Sliders learn low-rank parameter directions to either increase or decrease the expression of specific attributes. For a model and its target concept, the primary goal of Concept Sliders is to obtain an enhanced model that modifies the likelihood of enhancing and suppressing attributes for an image when conditioned on the target concept to increase the likelihood of enhancing attributes, and decrease the likelihood of suppressing attributes. Using reparameterization and Tweedie’s formula, the framework introduces a time-varying noise process, and expresses each score as a denoising prediction. Furthermore, the disentanglement objective finetunes the modules in Concept Sliders while keeping the pre-trained weights constant, and the scaling factor introduced during the LoRA formulation is modified during interference. The scaling factor also facilitates adjusting the strengths of the edit, and makes the edits stronger without retraining the framework as demonstrated in the following image.

Editing methods used earlier by frameworks facilitated stronger edits by retraining the framework with increased guidance. However, scaling the scaling factor during interference produces the same editing results without increasing the retraining cost, and time.
Learning Visual Concepts
Concept Sliders are designed in a way to control visual concepts that text prompts are not able to define well, and these sliders leverage small datasets that are either paired before or after to train on these concepts. The contrast between the image pairs allows sliders to learn the visual concepts. Furthermore, the Concept Sliders’ training process optimizes the LoRA component implemented in both the forward and reverse directions. As a result, the LoRA component aligns with the direction that causes the visual effects in both the directions.
Concept Sliders : Implementation Results
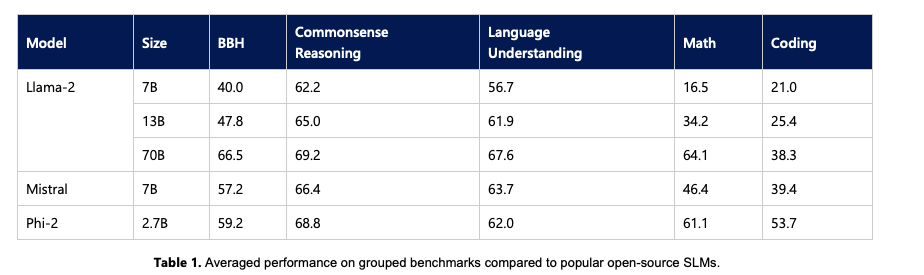
To analyze the gain in performance, developers have evaluated the use of Concept Sliders primarily on the Stable Diffusion XL, a high-resolution 1024-pixel framework with additional experiments conducted on the Stable Diffusion v1.4 framework with the models being trained for 500 epochs each.
Textual Concept Sliders
To evaluate the performance of textual Concept Sliders, it is validated on a set of 30 text-based concepts, and the method is compared against two baseline that make use of a standard text prompt for a fixed number of timesteps, and then starts composition by adding prompts to steer the image. As it can be seen in the following figure, the use of Concept Sliders results in constantly higher CLIP score, and a constant reduction in the LPIPS score when compared to the original framework without Concept Sliders.


As it can be seen in the above picture, the use of Concept Sliders facilitate precise editing of the attributes desired during the image generation process while maintaining the overall structure of the image.
Visual Concept Sliders
Text to image diffusion models that make use only of text prompts often find it difficult to maintain a higher degree of control over visual attributes like facial hair, or eye shapes. To ensure better control over granular attributes, Concept Sliders leverage optional text guidance paired with image datasets. As it can be seen in the figure below, Concept Sliders create individual sliders for “eye size” and “eyebrow shape” that capture the desired transformations using the image pairs.

The results can be further refined by providing specific texts so that the direction focuses on that facial region, and creates sliders with stepwise control over the targeted attribute.
Composing Sliders
One of the major advantages of using Concept Sliders is its composability that allows users to combine multiple sliders for an enhanced amount of control rather than focusing on a single concept at a time which can be owed to the low-rank sliders directions used in Concept Sliders. Additionally, since Concept Sliders are lightweight LoRA adaptors, they are easy to share, and they can also be easily overlaid on diffusion models. Users can also adjust multiple knobs simultaneously to steer complex generations by downloading interesting slider sets.

The following image demonstrates the composition capabilities of concept sliders, and multiple sliders are composed progressively in each row from left to right, thus allowing traversal of high-dimensional concept spaces with an enhanced degree of control over the concepts.

Improving Image Quality
Although state of the art text to image diffusion frameworks & large-scale generative models like Stable Diffusion XL model are capable of generating realistic and high-quality images, they often suffer from image distortions like blurry or wrapped objects even though the parameters of these state of the art frameworks are equipped with the latent capability to generate high-quality output with fewer generations. The use of Concept Sliders can result in generating images with fewer distortions by unlocking the true capabilities of these models by identifying low-rank parameter directions.
Fixing Hands
Generating images with realistic-looking hands has always been a hurdle for diffusion frameworks, and the use of Concept Sliders has the directly control the tendency to distort hands. The following image demonstrates the effect of using the “fix hands” Concept Sliders that allows the framework to generate images with more realistically looking hands.

Repair Sliders
The use of Concept Sliders can not only result in generating more realistically looking hands, but they have also shown their potential in improving the overall realism of the images generated by the framework. Concept Sliders also identifies single low-rank parameter direction that enables the shift in images from common distortion issues, and the results are demonstrated in the following image.

Final Thoughts
In this article, we have talked about Concept Sliders, a simple yet scalable new paradigm that enables interpretable control over generated output in diffusion models. The use of Concept Sliders aims to resolve the issues faced by the current text to image diffusion frameworks that find it difficult to maintain the required control over visual concepts and attributes included in the generated image which often leads to unsatisfactory output. Furthermore, a majority of text to image diffusion models find it difficult to modulate continuous attributes in an image that ultimately often leads to unsatisfactory outputs. The use of Concept Sliders might allow text to image diffusion frameworks to mitigate these issues, and empower content creators & end users with an enhanced degree of control over the image generation process, and solve issues faced by current frameworks.