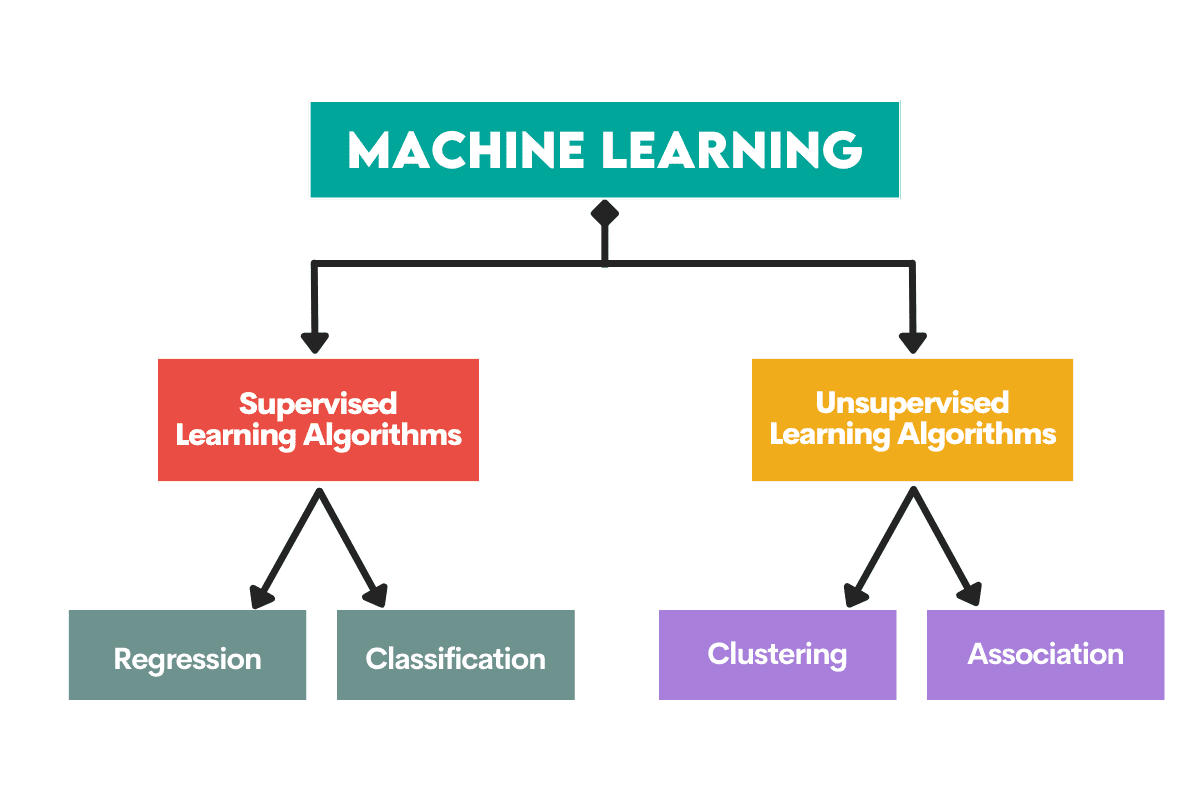
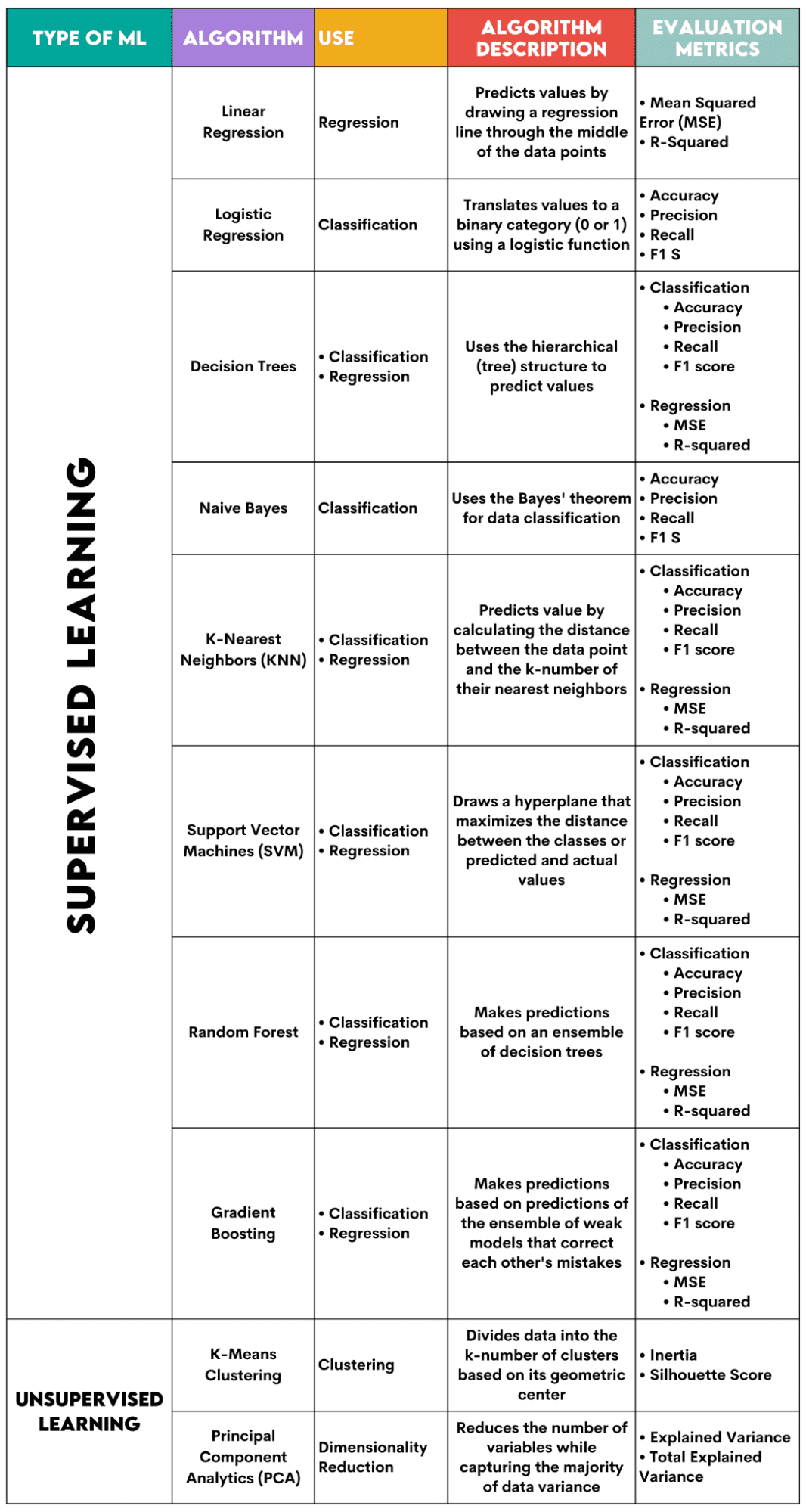
Hailo lands $120 million to keep battling Nvidia as most AI chip startups struggle Kyle Wiggers 9 hours 
The funding climate for AI chip startups, once as sunny as a mid-July day, is beginning to cloud over as Nvidia asserts its dominance.
According to a recent report, U.S. chip firms raised just $881 million from January 2023 to September 2023 — down from $1.79 billion in the first three quarters of 2022. AI chip company Mythic ran out of cash in 2022 and was nearly forced to halt operations, while Graphcore, a once-well-capitalized rival, now faces mounting losses.
But one startup appears to have found success in the ultra-competitive — and increasingly crowded — AI chip space.
Hailo, co-founded in 2017 by Orr Danon and Avi Baum, previously CTO for wireless connectivity at the microprocessor outfit Texas Instruments, designs specialized chips to run AI workloads on edge devices. Hailo’s chips execute AI tasks with lower memory usage and power consumption than a typical processor, making them a strong candidate for compact, offline and battery-powered devices such as cars, smart cameras and robotics.
“I co-founded Hailo with the mission to make high-performance AI available at scale outside the realm of data centers,” Danon told TechCrunch. “Our processors are used for tasks such as object detection, semantic segmentation and so on, as well as for AI-powered image and video enhancement. More recently, they’ve been used to run large language models (LLMs) on edge devices including personal computers, infotainment electronic control units and more.”
Many AI chip startups have yet to land one major contract, let alone dozens or hundreds. But Hailo has over 300 customers today, Danon claims, in industries such as automotive, security, retail, industrial automation, medical devices and defense.
In a bet on Hailo’s future prospects, a cohort of financial backers including Israeli businessman Alfred Akirov, automotive importer Delek Motors and the VC platform OurCrowd invested $120 million in Hailo this week, an extension to the company’s Series C. Danon said that the new capital will “enable Hailo to leverage all opportunities in the pipeline” while “setting the stage for long-term growth.”
“We’re strategically positioned to bring AI to edge devices in ways that will significantly expand the reach and impact of this remarkable new technology,” Danon said.
Now, you might be wondering, does a startup like Hailo really stand a chance against chip giants like Nvidia, and to a lesser extent Arm, Intel and AMD? One expert, Christos Kozyrakis, Stanford professor of electrical engineering and computer science, thinks so — he believes accelerator chips like Hailo’s will become “absolutely necessary” as AI proliferates.

“The energy efficiency gap between CPUs and accelerators is too large to ignore,” Kozyrakis told TechCrunch. “You use the accelerators for efficiency with key tasks (e.g., AI) and have a processor or two on the side for programmability.”
Kozyrakis does see longevity presenting a challenge to Hailo’s leadership — for example, if the AI model architectures its chips are designed to run efficiently fall out of vogue. Software support, too, could be an issue, Kozyrakis says, if a critical mass of developers aren’t willing to learn to use the tooling built around Hailo’s chips.
“Most of the challenges where it concerns custom chips are in the software ecosystem,” Kozyrakis said. “This is where Nvidia, for instance, has a huge advantage over other companies in AI, as they’ve been investing in software for their architectures for 15-plus years.”
But, with $340 million in the bank and a workforce numbering around 250, Danon’s feeling confident about Hailo’s path forward — at least in the short term. He sees the startup’s technology addressing many of the challenges companies encounter with cloud-based AI inference, particularly latency, cost and scalability.
“Traditional AI models rely on cloud-based infrastructure, often suffering from latency issues and other challenges,” Danon said. “They’re incapable of real-time insights and alerts, and their dependency on networks jeopardizes reliability and integration with the cloud, which poses data privacy concerns. Hailo is addressing these challenges by offering solutions that operate independently of the cloud, thus making them able to handle much higher amounts of AI processing.”
Curious for Danon’s perspective, I asked about generative AI and its heavy dependence on the cloud and remote data centers. Surely, Hailo sees the current top-down, cloud-centric model (e.g OpenAI’s modus operandi) is an existential threat?
Danon said that, on the contrary, generative AI is driving new demand for Hailo’s hardware.
“In recent years, we’ve seen a surge in demand for edge AI applications in most industries ranging from airport security to food packaging,” he said. “The new surge in generative AI is further boosting this demand, as we’re seeing requests to process LLMs locally by customers not only in the compute and automotive industries, but also in industrial automation, security and others.”
How about that.