Image by Author
Python is a beginner-friendly and versatile programming language known for its simplicity and readability. Its elegant syntax, however, is not immune to quirks that can surprise even experienced Python developers. And understanding these is essential for writing bug-free code—or pain-free debugging if you will.
This tutorial explores some of these gotchas: mutable defaults, variable scope in loops and comprehensions, tuple assignment, and more. We’ll code simple examples to see why things work the way they do, and also look at how we can avoid these (if we actually can 🙂).
So let’s get started!
1. Mutable Defaults
In Python, mutable defaults are common sharp corners. You’ll run into unexpected behavior anytime you define a function with mutable objects, like lists or dictionaries, as default arguments.
The default value is evaluated only once, when the function is defined, and not each time the function is called. This can lead to unexpected behavior if you mutate the default argument within the function.
Let's take an example:
def add_to_cart(item, cart=[]): cart.append(item) return cart
In this example, add_to_cart is a function that takes an item and appends it to a list cart. The default value of cart is an empty list. Meaning calling the function without an item to add returns an empty cart.
And here are a couple of function calls:
# User 1 adds items to their cart user1_cart = add_to_cart("Apple") print("User 1 Cart:", user1_cart)
Output >>> ['Apple']
This works as expected. But what happens now?
# User 2 adds items to their cart user2_cart = add_to_cart("Cookies") print("User 2 Cart:", user2_cart)
Output >>> ['Apple', 'Cookies'] # User 2 never added apples to their cart!
Because the default argument is a list—a mutable object—it retains its state between function calls. So each time you call add_to_cart, it appends the value to the same list object created during the function definition. In this example, it’s like all users sharing the same cart.
How To Avoid
As a workaround, you can set cart to None and initialize the cart inside the function like so:
def add_to_cart(item, cart=None): if cart is None: cart = [] cart.append(item) return cart
So each user now has a separate cart. 🙂
If you need a refresher on Python functions and function arguments, read Python Function Arguments: A Definitive Guide.
2. Variable Scope in Loops and Comprehensions
Python's scope oddities call for a tutorial of their own. But we’ll look at one such oddity here.
Look at the following snippet:
x = 10 squares = [] for x in range(5): squares.append(x ** 2) print("Squares list:", squares) # x is accessible here and is the last value of the looping var print("x after for loop:", x)
The variable x is set to 10. But x is also the looping variable. But we’d assume that the looping variable’s scope is limited to the for loop block, yes?
Let’s look at the output:
Output >>> Squares list: [0, 1, 4, 9, 16] x after for loop: 4
We see that x is now 4, the final value it takes in the loop, and not the initial value of 10 we set it to.
Now let’s see what happens if we replace the for loop with a comprehension expression:
x = 10 squares = [x ** 2 for x in range(5)] print("Squares list:", squares) # x is 10 here print("x after list comprehension:", x)
Here, x is 10, the value we set it to before the comprehension expression:
Output >>> Squares list: [0, 1, 4, 9, 16] x after list comprehension: 10
How To Avoid
To avoid unexpected behavior: If you’re using loops, ensure that you don’t name the looping variable the same as another variable you’d want to access later.
3. Integer Identity Quirk
In Python, we use the is keyword for checking object identity. Meaning it checks whether two variables reference the same object in memory. And to check for equality, we use the == operator. Yes?
Now, start a Python REPL and run the following code:
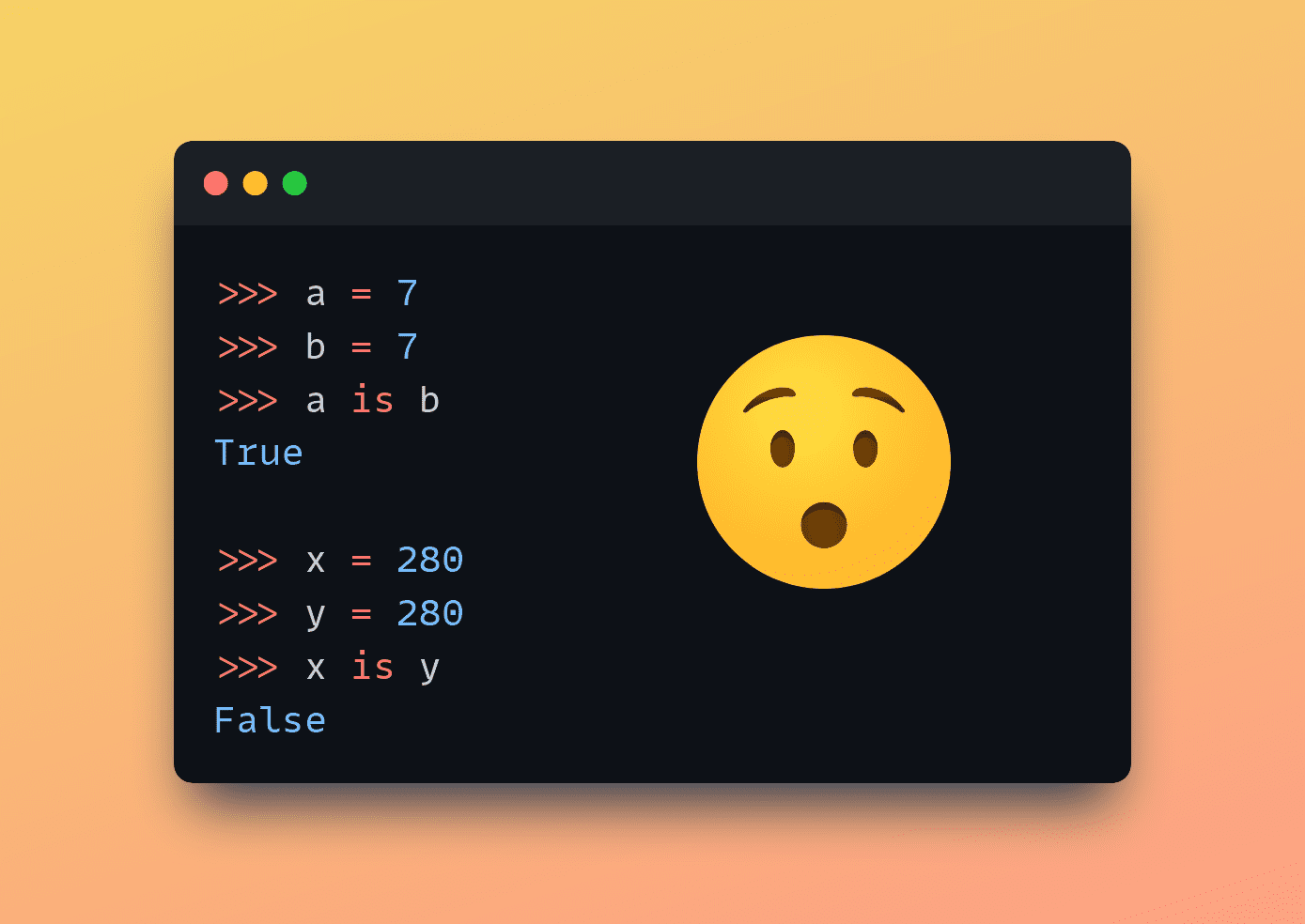
>>> a = 7 >>> b = 7 >>> a == 7 True >>> a is b True
Now run this:
>>> x = 280 >>> y = 280 >>> x == y True >>> x is y False
Wait, why does this happen? Well, this is due to "integer caching" or "interning" in CPython, the standard implementation of Python.
CPython caches integer objects in the range of -5 to 256. Meaning every time you use an integer within this range, Python will use the same object in memory. Therefore, when you compare two integers within this range using the is keyword, the result is True because they refer to the same object in memory.
That’s why a is b returns True. You can also verify this by printing out id(a) and id(b).
However, integers outside this range are not cached. And each occurrence of such integers creates a new object in memory.
So when you compare two integers outside the cached range using the is keyword (yes, x and y both set to 280 in our example), the result is False because they are indeed two different objects in memory.
How To Avoid
This behavior shouldn’t be a problem unless you try to use the is for comparing equality of two objects. So always use the == operator to check if any two Python objects have the same value.
4. Tuple Assignment and Mutable Objects
If you’re familiar with built-in data structures in Python, you know that tuples are immutable. So you cannot modify them in place. Data structures like lists and dictionaries, on the other hand, are mutable. Meaning you can change them in place.
But what about tuples that contain one or more mutable objects?
It's helpful to started a Python REPL and run this simple example:
>>> my_tuple = ([1,2],3,4) >>> my_tuple[0].append(3) >>> my_tuple ([1, 2, 3], 3, 4)
Here, the first element of the tuple is a list with two elements. We try appending 3 to the first list and it works fine! Well, did we just modify a tuple in place?
Now let’s try to add two more elements to the list, but this time using the += operator:
>>> my_tuple[0] += [4,5] Traceback (most recent call last): File "", line 1, in TypeError: 'tuple' object does not support item assignment
Yes, you get a TypeError which says the tuple object does not support item assignment. Which is expected. But let’s check the tuple:
>>> my_tuple ([1, 2, 3, 4, 5], 3, 4)
We see that elements 4 and 5 have been added to the list! Did the program just throw an error and succeed at the same time?
Well the += operator internally works by calling the __iadd__() method which performs in-place addition and modifies the list in place. The assignment raises a TypeError exception, but the addition of elements to the end of the list has already succeeded. += is perhaps the sharpest corner!
How To Avoid
To avoid such quirks in your program, try using tuples only for immutable collections. And avoid using mutable objects as tuple elements as much as possible.
5. Shallow Copies of Mutable Objects
Mutability has been a recurring topic in our discussion thus far. So here’s another one to wrap up this tutorial.
Sometimes you may need to create independent copies of lists. But what happens when you create a copy using a syntax similar to list2 = list1 where list1 is the original list?
It’s a shallow copy that gets created. So it only copies the references to the original elements of the list. Modifying elements through the shallow copy will affect both the original list and the shallow copy.
Let's take this example:
original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # Shallow copy of the original list shallow_copy = original_list # Modify the shallow copy shallow_copy[0][0] = 100 # Print both the lists print("Original List:", original_list) print("Shallow Copy:", shallow_copy)
We see that the changes to the shallow copy also affect the original list:
Output >>> Original List: [[100, 2, 3], [4, 5, 6], [7, 8, 9]] Shallow Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
Here, we modify the first element of the first nested list in the shallow copy: shallow_copy[0][0] = 100. But we see that the modification affects both the original list and the shallow copy.
How To Avoid
To avoid this, you can create a deep copy like so:
import copy original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # Deep copy of the original list deep_copy = copy.deepcopy(original_list) # Modify an element of the deep copy deep_copy[0][0] = 100 # Print both lists print("Original List:", original_list) print("Deep Copy:", deep_copy)
Now, any modification to the deep copy leaves the original list unchanged.
Output >>> Original List: [[1, 2, 3], [4, 5, 6], [7, 8, 9]] Deep Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
Wrapping Up
And that’s a wrap! In this tutorial, we've explored several oddities in Python: from the surprising behavior of mutable defaults to the subtleties of shallow copying lists. This is only an introduction to Python’s oddities and is by no means an exhaustive list. You can find all the code examples on GitHub.
As you keep coding for longer in Python—and understand the language better—you’ll perhaps run into many more of these. So, keep coding, keep exploring!
Oh, and let us know in the comments if you’d like to read a sequel to this tutorial.
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.
More On This Topic
- 3 Crucial Challenges in Conversational AI Development and How to Avoid Them
- 10 Most Common Data Quality Issues and How to Fix Them
- KDnuggets News, August 24: Implementing DBSCAN in Python • How to…
- Most Common Data Science Interview Questions and Answers
- Common Data Problems (and Solutions)
- Data Science Programming Languages and When To Use Them