Alexa’s ability to produce animal sounds through the Wild Planet skill recently helped save a 13-year old girl and her 15-month old niece from monkey attack in Basti, Uttar Pradesh. By asking “Alexa, kutte ki awaz nikalo”, the girl was able to scare away the monkeys.
“The option to access a number of useful kid-friendly experiences with simple voice commands makes Alexa a great addition for a family with young kids. Parents often tell us how Alexa has become a companion in their parenting journeys,” says Dilip R.S., Director and Country Manager for Alexa, Amazon India.
From listening to Indian folktales to playing animal sounds, Indian households with young kids who use Alexa at home are two times more engaged than other users. Parents of young kids take Alexa’s help in managing their day-to-day parenting tasks and keeping their kids engaged by asking Alexa for rhymes, stories, games, GK-related questions, and more.
Users enjoy the ease and convenience of giving simple voice commands to Alexa in Hindi, English, and Hinglish – making the AI a great aid for parents and companion for kids.
“While it is a great learning and entertainment tool for kids, Alexa can help parents manage their day-to-day tasks better. Whether it is controlling smart home appliances with voice while juggling numerous tasks or asking for a bedtime story as part of their child’s daily routine, Alexa’s right there to help them,” Dilip adds.
Today, families across India are asking Alexa for information, games, quizzes, music, managing day-to-day tasks, stories, and much more. In fact, weekends are family time with Alexa – last year there was a 15% increase in requests to Alexa over the weekends in requests for music with many of them being for kids’ music.
The top five, most popular songs for kids on Alexa are: Baby Shark, Lakdi Ki Kathi, Johnny Johnny Yes Papa, Wheels on the Bus, and Twinkle Twinkle Little Star. Indian folktales, like Akbar Birbal, Tenali Raman, and Panchatantra stories, see high interest from customers, especially in Hindi. In 2023, customers asked for these stories on an average of 34 times every hour.
The post Alexa Saves Young Girl from Monkey Attack, Aims to Aid Older Adults Too appeared first on Analytics India Magazine.
Hewlett Packard Enterprise (HPE) has announced that its “Made in India” servers are now being deployed at large scale to meet the increasing demands of Indian customers, ahead of schedule.
The servers, designed to support a variety of applications and workloads, are produced at VVDN’s cutting-edge facility in Manesar, Haryana. This follows HPE’s “Make in India” plan unveiled in July 2023, in partnership with Indian manufacturer VVDN Technologies.
The collaboration aims to manufacture approximately $1 billion worth of servers in the first five years of production.
VVDN’s state-of-the-art manufacturing facility was set up quickly and is now fully operational. Both companies prioritised automation, quality, and control of operations during the eight-month setup period. These servers enable Indian businesses to optimise IT infrastructure and gain a competitive edge in today’s digital age.
Som Satsangi, SVP and managing director of HPE India, credited the government and the Ministry of Electronics & Information Technology (MeitY) for introducing the Production Linked Incentive (PLI) program. He stated, “Their vision has encouraged OEMs like us to establish a manufacturing footprint in India.” He emphasised HPE’s commitment to innovation, local talent, and India’s economic growth.
Printed Circuit Board Assembly (PCBA) through surface mounted technology is one of the most complex aspects of server manufacturing, and HPE’s PCBA capability in India significantly enhances the value of its servers.
VVDN CEO Puneet Agarwal praised the partnership as a step toward India’s ambition of becoming a global manufacturing powerhouse. “Together, we are establishing advanced manufacturing capabilities in India that reflect our commitment to local expertise and an Aatmanirbhar Bharat,” he said.
HPE’s plan to manufacture servers in India aligns with its broader goal of supply chain diversification and resiliency. The company is also exploring ways to deepen localization by leveraging VVDN’s backward integration capability and expanding its portfolio of products made in India.
The post HPE Unveils ‘Made in India’ Servers Ahead of Schedule appeared first on Analytics India Magazine.
Lightstorm, a major provider of connectivity infrastructure and services, has entered into a Memorandum of Understanding (MoU) with the Indian Institute of Technology, Madras, to launch an “Employment Skilling Initiative.”
This collaboration seeks to bridge the skill gap among underprivileged students and support underserved youth, women, and job seekers from tier 2 & 3 cities.
Lightstorm, in partnership with IIT Madras’ Technology Innovation Hub, will offer comprehensive placement assistance for students in Arts, Science, and Commerce degrees. High achievers may also secure internships, furthering their professional development.
Dr. Mangala Sunder Krishnan, Professor Emeritus at IIT Madras, emphasised the importance of quality education and growth opportunities for all backgrounds. “We firmly believe that every individual, regardless of their background, deserves access to quality education and opportunities for personal and professional growth.” He praised Lightstorm’s initiative to provide necessary tech skills to underprivileged students, facilitating inclusive economic development.
According to a 2023 survey, over 75% of industry leaders see a need for more practical knowledge among recent graduates. Another industry report revealed that only 45% of Indian graduates applying for jobs are employable and prepared to meet changing industry demands, highlighting the necessity for specialised technology skills.
Amajit Gupta, Group CEO and Managing Director of Lightstorm, expressed excitement about the partnership: “This is a significant step towards closing the skill gap among underprivileged students and providing them with meaningful employment opportunities. We aim to empower individuals from diverse backgrounds and drive inclusive economic growth.”
The ‘Employment Enablement Program through Skill Development’ offers a well-designed curriculum that includes Networking Essentials, ITIL Fundamentals, and Soft Skill Training, among other key topics. Taught by a mix of academic and industry experts, the program combines classroom instruction with practical learning experiences for maximum skill retention and applicability.
Lightstorm’s commitment to corporate social responsibility includes ambitious goals for 2024, focusing on successful program implementation with partner organisations.
Lightstorm builds hyperscale networking infrastructure in South Asia, Southeast Asia, and the Middle East, driving growth and innovation in the digital economy. The company has established a resilient fibre network, SmartNet, in various regional countries.
The post IIT Madras Partners with Lightstorm for Skill Development in Tier 2 & 3 Cities appeared first on Analytics India Magazine.
One of the godfathers of AI, Geoffrey Hinton, recently altered his estimation of when superintelligence could come into being.
“I think it’s fairly clear that maybe in the next 20 years, I’d say with a probability of 0.5, it will get smarter than us and probably in the next hundred years, it will be much smarter than us,” Hinton said during the Romanes Lecture he gave recently on whether digital intelligence will replace biological intelligence.
Hinton had famously changed his estimation early last year, believing AI will become smarter than humans, shortly before he resigned from Google.
While Hinton initially changed his conservative estimate of 30-50 years to a more dire 5-20 years, it seems this has changed slightly over the months due to the accelerated AI advancements.
Hinton isn’t the only industry stalwart to predict when superintelligence will become a thing.
From Elon Musk’s optimistic, yet unlikely prediction of a year to Yann LeCun’s vague estimate of “years, if not decades”, to Jensen Huang’s straightforward and popular estimation of five years, it seems that AI superseding human intelligence will forever be around the corner.
No, AI is not going to take over just yet
Both Hinton and fellow AI godfather LeCun give ample reasons why superintelligence is not likely anytime soon. Hinton acknowledged that these things are hard to predict since the technology is new.
I now predict 5 to 20 years but without much confidence. We live in very uncertain times. It's possible that I am totally wrong about digital intelligence overtaking us. Nobody really knows which is why we should worry now.
— Geoffrey Hinton (@geoffreyhinton) May 3, 2023
Ever the optimist, Hinton said, “My conclusion, which I don’t really like, is that digital computation requires a lot of energy, and so it would never evolve. We have to evolve using the quirks of the hardware to be very low-energy.
But once you’ve got it, it’s very easy for agents to share – GPT4 has thousands of times more knowledge in about 2% of the weights, so that’s quite depressing. Biological computation is great for evolving because it requires very little energy, but my conclusion is that digital computation is just better.”
However, while Hinton is understandably cautious, LeCun has been much more standoffish to the idea that AI regulation is needed just in case the human race gets taken over.
LeCun has repeatedly stated that the move towards superintelligence is decades away, with no specific breakthrough defining when we will definitively see a shift. And this might be the reason that superintelligence will always be at least one step away from where we think it is.
In not being able to pinpoint an exact moment where superintelligence comes into existence, the ability to actually predict it becomes moot.
Maybe predictions aren’t really the way to go about it, considering every new breakthrough seems to fast forward the timeline, followed by ultimately pushing it back, thanks to the new challenges they subsequently pose.
How far are we, really?
The general consensus is that we are nowhere near where we need to be for superintelligence to come into being. The leap of AI as it is now to where it needs to be has several breakthroughs in between for it to rival the intelligence of a human mind.
The godfathers and other relatives of AI seem to agree on one thing. The level of computational power needed for a potential superintelligence is extraordinary, so that could be one starting point on what to look for.
Hinton said that the reason for this was that AI might already be almost on par with the human brain, at least in the way it works, rather than its intelligence.
“I thought making our models more like the brain would make them better. I thought the brain was a whole lot better than the AI we had… I suddenly came to believe that maybe the digital models we’ve got now are already very close to or as good as brains, and will get to be much better than brains,” Hinton said.
He explained that the ability to run the same neural net on different computers or pieces of hardware far outweigh the learning ability of biological computation, with digital computation having the scope for becoming smarter much faster.
However, as mentioned before, biological computation needs much less energy.
Unless this gap is closed, super intelligence isn’t really something that is within grasp. However, while many believe that quantum computation is the means to this end, LeCun seems to believe that quantum computation is just as much of a pipe dream as superintelligence.
With China recently announcing the development of the Taichi chiplet (advertised as capable of running an AGI model!), it’s only a matter of time to see if this theory will hold up.
The post Superintelligence Timeline Now Shrinks to 20 Years appeared first on Analytics India Magazine.
Making an open-source LLM as powerful as the closed ones like GPT-4 and Claude 3 Opus definitely requires a lot of magic. WizardLM has always been up to that task since it decided to make a model on top of Meta’s Llama 2. And now, it has done that using Mistral’s Mixtral of Experts model.
Undoubtedly, it is all part of the Microsoft partnership.
Introducing WizardLM-2, an open-source SOTA language model that offers improved performance in complex chat, multilingual, reasoning, and agent tasks. The model includes three advanced versions: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
The WizardLM-2 8x22B excels in intricate tasks, WizardLM-2 70B offers top-tier reasoning, and WizardLM-2 7B is the fastest while matching the performance of models 10 times its size.
The model weights for WizardLM-2 8x22B and WizardLM-2 7B were available on Hugging Face, which were then pulled down due to an premature release. “It’s been a while since we released a model months ago; we’re unfamiliar with the new release process now. We accidentally missed an item required in the model release process – toxicity testing,” explained the WizardLM account on X.
We are sorry for that. It’s been a while since we’ve released a model months ago, so we’re unfamiliar with the new release process now: We accidentally missed an item required in the model release process – toxicity testing. We are currently completing this test quickly… https://t.co/1YG3e35Uvj pic.twitter.com/nyPCX2owA2
— WizardLM (@WizardLM_AI) April 16, 2024
Too powerful to be out in the open
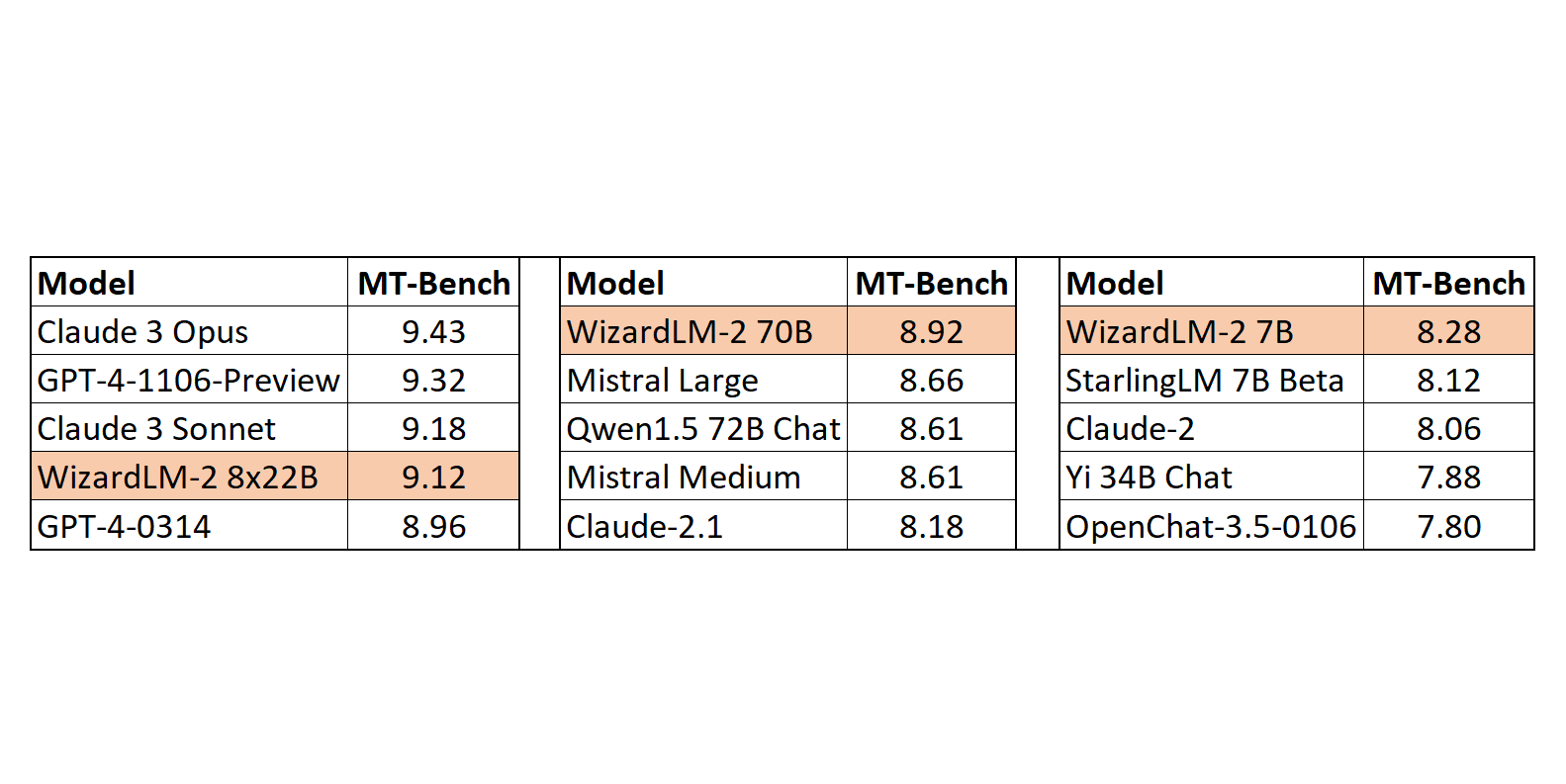
WizardLM-2 8x22B, the most advanced release falls just short of GPT-4-1106-preview and reaches top tier performance compared to other models of the same size. Moreover, the 7B model even achieves a good performance when compared to existing 10 times larger models such as Qwen1.5 14B model.
The model was also trained on synthetic data generated by AI models, as WizardLM explains, “Natural world’s human data becomes increasingly exhausted through LLM training, we believe that the data carefully created by AI and the model step-by-step supervised by AI will be the sole path towards more powerful AI.”
The Mixture of Experts and multilingual model has a total parameter size of 141 billion. It comes with an Apache 2.0 license, the same as the one offered with Llama 2, making it highly competitive. This comes just when Meta is about to release Llama 3 this week.
When compared on MT-Bench, the metric which is directly correlated with HumanEval on the chatbot arena, the 8x22B model achieved 9.12 rating, which ranks it on the fourth position on the chart, lagging just behind Claude 2 Sonnet with a rating of 9.18.
On the other hand, the model tops the chart when compared to all the other open source models on the same benchmark. In simple terms, this model offers the capabilities of a GPT-4 level model which can run on a single laptop.
The internet wants uncensored models
Microsoft has been a blessing for WizardLM models. As mentioned in the training details, the models were trained on data generated by GPT-4, which apart from being better for training AI models, are also cheaper to access when compared to human data.
On the other hand, Microsoft’s compliance for creating “censored” models has also been a hindrance for WizardLM.
LOLWUT! Wizard LM Is Forced To Pull Down Their Model Because The Censors Hadn’t Blessed It! Apparently, Wizard LM had to pull its models from HuggingFace because they hadn’t completed “toxicity testing” of their models!! So they have to go do that before releasing it again!…
— Bindu Reddy (@bindureddy) April 16, 2024
Since the initial uncensored version was pulled down by Microsoft, users on X have been asking for the release of both the versions on Hugging Face, saying developers can decide for themselves which one to use. However, this does not comply with Microsoft’s policy.
“Considering these models are released by ‘Microsoft AI’, I doubt they do anything against the ToS of ‘OpenAI,’ said a user on HackerNews.
The battle of spells
While Llama 3 is almost here, there are other models as well on the horizon that are competing closely with the Dumbledore of LLMs. Google has Gemma. Microsoft also has Phi-2 and Orca. Meanwhile, Amazon remains tightlipped about making smaller models and relying on open-source models.
Microsoft’s bet on WizardLM is definitely its test with open source models while it builds larger and stronger models with OpenAI. Let’s wait and watch where the model lands on the Open LLM Leaderboard when it is launched again.
The post The Dumbledore of LLMs appeared first on Analytics India Magazine.
PyTorch has announced the alpha release of torchtune, a new library designed to simplify the fine-tuning of large language models (LLMs) using PyTorch.
Click here to check out the GitHub repository.
The library is built on PyTorch’s core principles, offering modular building blocks and customisable training recipes for fine-tuning popular LLMs on various GPUs, including consumer-grade and professional ones.
The library provides a comprehensive fine-tuning workflow, from downloading and preparing datasets and model checkpoints to customising training with composable building blocks, logging progress, quantizing models post-tuning, evaluating fine-tuned models, running local inference for testing, and ensuring compatibility with popular production inference systems.
Torchtune aims to address the increasing demand for fine-tuning LLMs by offering flexibility and control. Users can easily add customisations and optimizations to adapt models to specific use cases, including memory-efficient recipes that work on machines with single 24GB gaming GPUs.
The design of torchtune focuses on easy extensibility, democratising fine-tuning for users of varying expertise, and interoperability with the open-source LLM ecosystem.
The library integrates with popular tools such as Hugging Face Hub, PyTorch FSDP, Weights & Biases, EleutherAI’s LM Evaluation Harness, ExecuTorch, and torchao for various purposes like model and dataset access, distributed training, logging, evaluation, inference, and quantisation.
torchtune currently supports Llama 2, Mistral, and Gemma 7B models and plans to expand with additional models, features, and fine-tuning techniques in the coming weeks including 70 billion parameters and Mixture of Experts models.
The post PyTorch Releases torchtune for Easily Fine-Tuning LLMs appeared first on Analytics India Magazine.
Bangaluru-based agritech startup Cropin Technology today announced the launch of ‘akṣara’, the sector’s first purpose-built open-source (Apache 2.0 License and with no restrictions) Micro Language Model (µ-LM) for climate-smart agriculture.
Built on Mistral’s foundational model, the micro language model is designed to address the problems faced by the underserved farming communities in the Global South by removing barriers to knowledge and empowering anyone in the agriculture ecosystem to build frugal and scalable AI solutions for the sector.
Cropin aims to empower agricultural stakeholders, developers, and researchers to tackle global challenges like food security, climate change, resource conservation – water and soil, regenerative agriculture practices amongst others by providing access to contextual, factual, and actionable information.
Out of the world’s 600 million farms, five out of six are small, covering less than two hectares each. Despite operating on only about 12 percent of agricultural land, these small farms produce roughly 35 percent of the world’s food.
The goal is to enable AI investments to have a significant impact and to make AI accessible to everyone in the ecosystem, including academia, development agencies, governments, and agricultural enterprises, to empower farmers worldwide, beginning with the smallholders in the global south.
Krishna Kumar, founder & CEO, Cropin said in an era where Large Language Models are reshaping jobs, businesses, and customer interactions, the spotlight is now on industry-specific models trained on niche and comprehensive domain data as the ‘next big thing.’
These models can potentially transform agriculture, paving the way for a new era of tech-driven farming in a sector that has traditionally seen limited technological advancement. Domain-specific AI models for agriculture are expected to attract significant investments, offering a practical and economically viable approach to food systems transformation.
The post Cropin Launches Micro Language Model for Climate Smart Agriculture appeared first on Analytics India Magazine.
Intel and others commit to building open generative AI tools for the enterprise Kyle Wiggers 8 hours
Can generative AI designed for the enterprise (for example, AI that autocompletes reports, spreadsheet formulas and so on) ever be interoperable? Along with a coterie of organizations including Cloudera and Intel, the Linux Foundation — the nonprofit organization that supports and maintains a growing number of open source efforts — aims to find out.
The Linux Foundation on Tuesday announced the launch of the Open Platform for Enterprise AI (OPEA), a project to foster the development of open, multi-provider and composable (i.e. modular) generative AI systems. Under the purview of the Linux Foundation’s LFAI and Data org, which focuses on AI- and data-related platform initiatives, OPEA’s goal will be to pave the way for the release of “hardened,” “scalable” generative AI systems that “harness the best open source innovation from across the ecosystem,” LFAI and Data’s executive director, Ibrahim Haddad, said in a press release.
“OPEA will unlock new possibilities in AI by creating a detailed, composable framework that stands at the forefront of technology stacks,” Haddad said. “This initiative is a testament to our mission to drive open source innovation and collaboration within the AI and data communities under a neutral and open governance model.”
In addition to Cloudera and Intel, OPEA — one of the Linux Foundation’s Sandbox Projects, an incubator program of sorts — counts among its members enterprise heavyweights like Intel, IBM-owned Red Hat, Hugging Face, Domino Data Lab, MariaDB and VMWare.
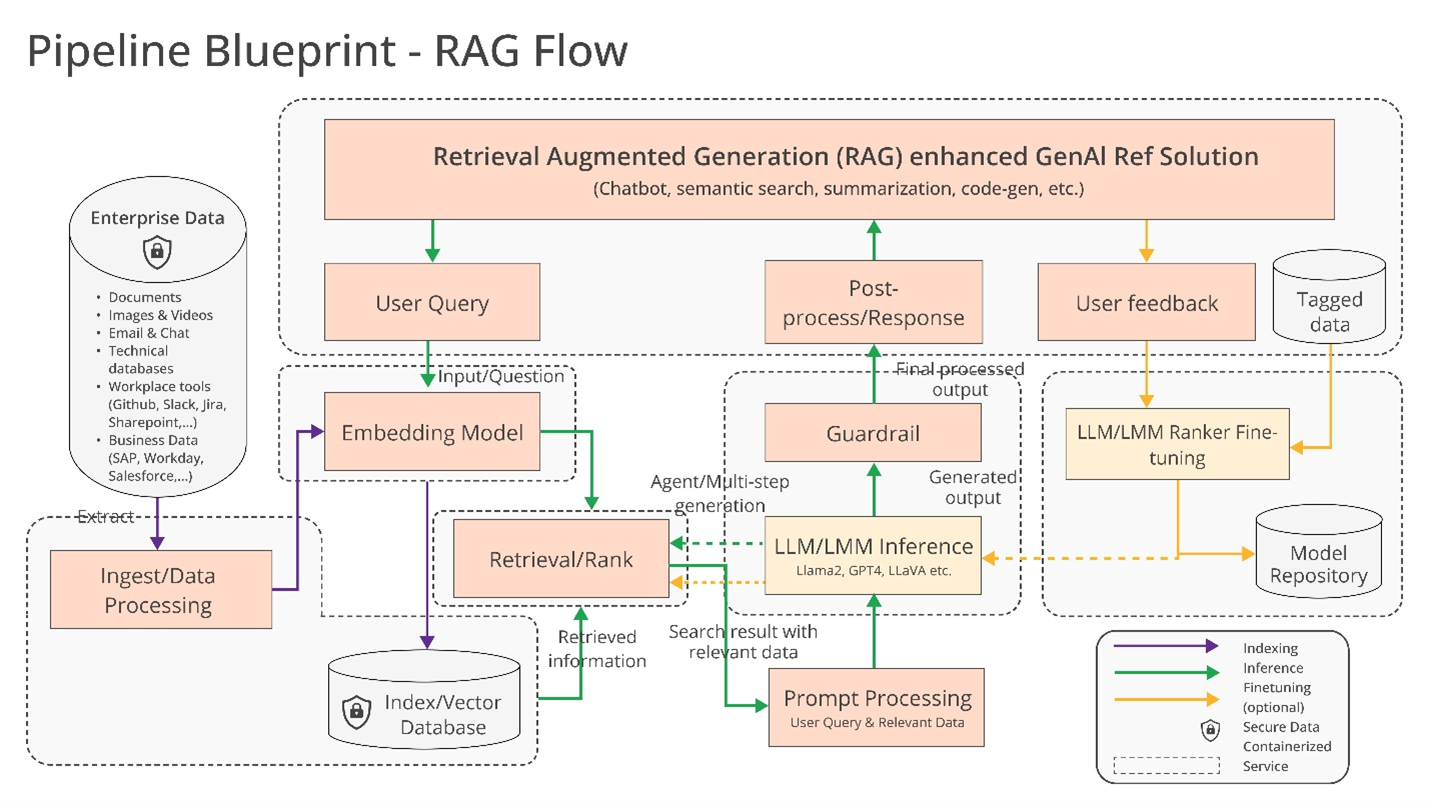
So what might they build together exactly? Haddad hints at a few possibilities, such as “optimized” support for AI toolchains and compilers, which enable AI workloads to run across different hardware components, as well as “heterogeneous” pipelines for retrieval-augmented generation (RAG).
RAG is becoming increasingly popular in enterprise applications of generative AI, and it’s not difficult to see why. Most generative AI models’ answers and actions are limited to the data on which they’re trained. But with RAG, a model’s knowledge base can be extended to info outside the original training data. RAG models reference this outside info — which can take the form of proprietary company data, a public database or some combination of the two — before generating a response or performing a task.
A diagram explaining RAG models.
Intel offered a few more details in its own press release:
Enterprises are challenged with a do-it-yourself approach [to RAG] because there are no de facto standards across components that allow enterprises to choose and deploy RAG solutions that are open and interoperable and that help them quickly get to market. OPEA intends to address these issues by collaborating with the industry to standardize components, including frameworks, architecture blueprints and reference solutions.
Evaluation will also be a key part of what OPEA tackles.
In its GitHub repository, OPEA proposes a rubric for grading generative AI systems along four axes: performance, features, trustworthiness and “enterprise-grade” readiness. Performance as OPEA defines it pertains to “black-box” benchmarks from real-world use cases. Features is an appraisal of a system’s interoperability, deployment choices and ease of use. Trustworthiness looks at an AI model’s ability to guarantee “robustness” and quality. And enterprise readiness focuses on the requirements to get a system up and running sans major issues.
Rachel Roumeliotis, director of open source strategy at Intel, says that OPEA will work with the open-source community to offer tests based on the rubric, as well as provide assessments and grading of generative AI deployments on request.
OPEA’s other endeavors are a bit up in the air at the moment. But Haddad floated the potential of open model development along the lines of Meta’s expanding Llama family and Databricks’ DBRX. Toward that end, in the OPEA repo, Intel has already contributed reference implementations for an generative-AI-powered chatbot, document summarizer and code generator optimized for its Xeon 6 and Gaudi 2 hardware.
Now, OPEA’s members are very clearly invested (and self-interested, for that matter) in building tooling for enterprise generative AI. Cloudera recently launched partnerships to create what it’s pitching as an “AI ecosystem” in the cloud. Domino offers a suite of apps for building and auditing business-forward generative AI. And VMWare — oriented toward the infrastructure side of enterprise AI — last August rolled out new “private AI” compute products.
The question is whether these vendors will actually work together to build cross-compatible AI tools under OPEA.
There’s an obvious benefit to doing so. Customers will happily draw on multiple vendors depending on their needs, resources and budgets. But history has shown that it’s all too easy to become inclined toward vendor lock-in. Let’s hope that’s not the ultimate outcome here.
Meta has introduced MEGALODON, a neural architecture for efficient sequence modelling with unlimited context length. It is designed to address the limitations of the Transformer architecture in handling long sequences, including quadratic computational complexity and limited inductive bias for length generalisation.
Click here to check out the GitHub repository.
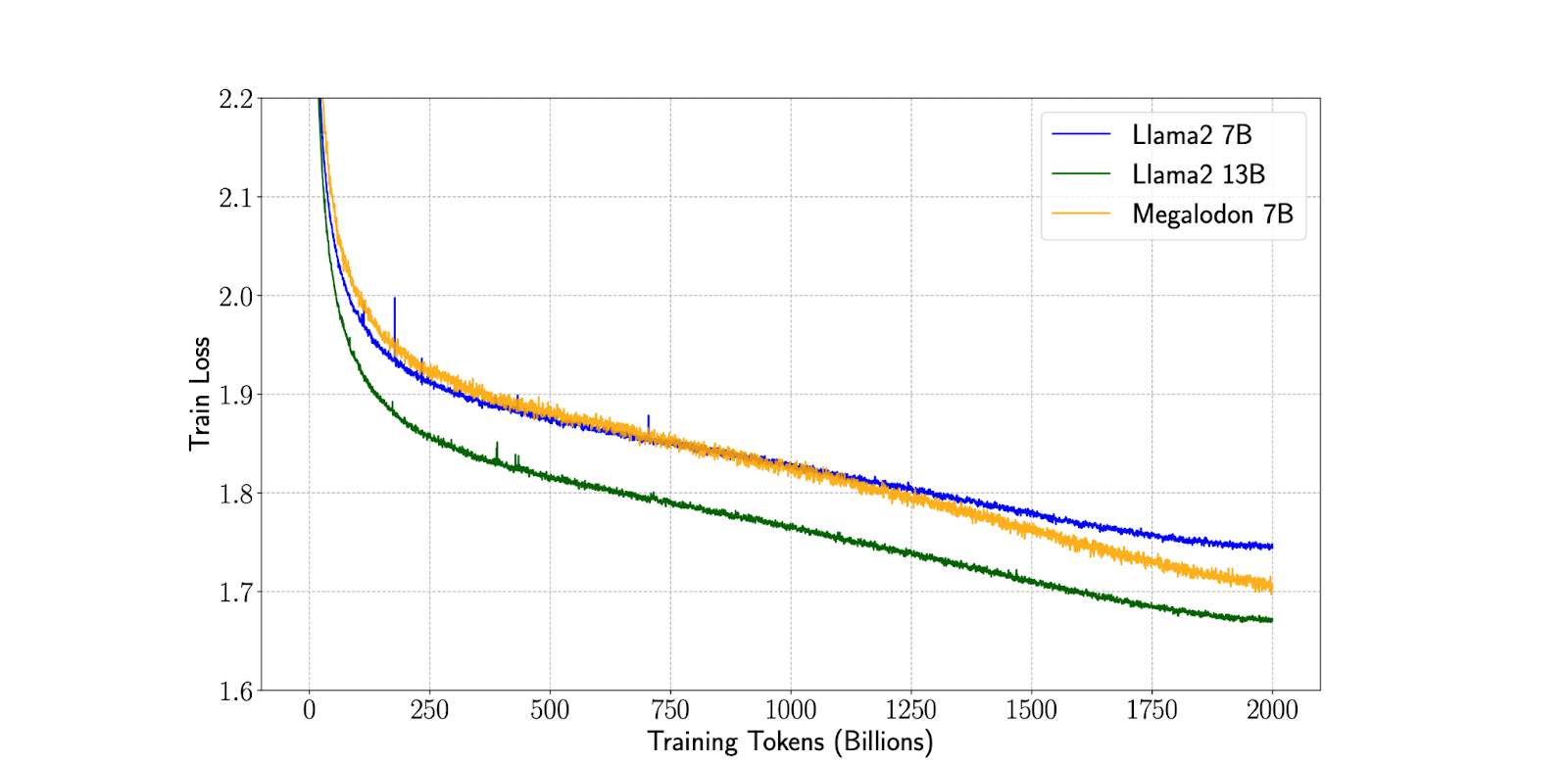
In direct comparisons with Llama 2, MEGALODON demonstrates superior efficiency at a scale of 7 billion parameters and 2 trillion training tokens, with a training loss of 1.70—positioned between LLAMA2-7B (1.75) and LLAMA2-13B (1.67). MEGALODON’s improvements over Transformers are consistent across a range of benchmarks, encompassing different tasks and modalities.
To evaluate MEGALODON’s performance, various experiments were conducted, including large-scale long-context pretraining. The model was scaled up to 7 billion parameters and applied to large-scale language models pretraining on 2 trillion tokens.
MEGALODON introduces key innovations such as the complex exponential moving average (CEMA) component, which extends the multi-dimensional damped EMA to the complex domain, and the timestep normalization layer, which allows normalization along the sequential dimension in autoregressive sequence modeling tasks. Other improvements include normalized attention and pre-norm with two-hop residual configurations.
MEGALODON’s linear computational and memory complexity during training and inference is achieved by chunking input sequences into fixed blocks as in MEGA-chunk. This results in efficient long-context pretraining and better data efficiency. MEGALODON is evaluated across various scales of language modeling and downstream domain-specific tasks, showcasing its ability to model sequences of unlimited length.
MEGALODON’s instruction fine-tuning performance is also notable. Fine-tuning the base model of MEGALODON-7B on proprietary instruction-alignment data yields strong performance on MT-Bench, comparable to LLAMA2-Chat, which employs reinforcement learning from human feedback.
In terms of image classification, MEGALODON exhibits top-1 accuracy improvements over DeiT-B and MEGA on ImageNet-1K. Its performance on auto-regressive language modelling tasks on PG19 surpasses state-of-the-art baselines.
The post Meta Releases MEGALODON, Efficient LLM Pre-Training and Inference on Infinite Context Length appeared first on Analytics India Magazine.
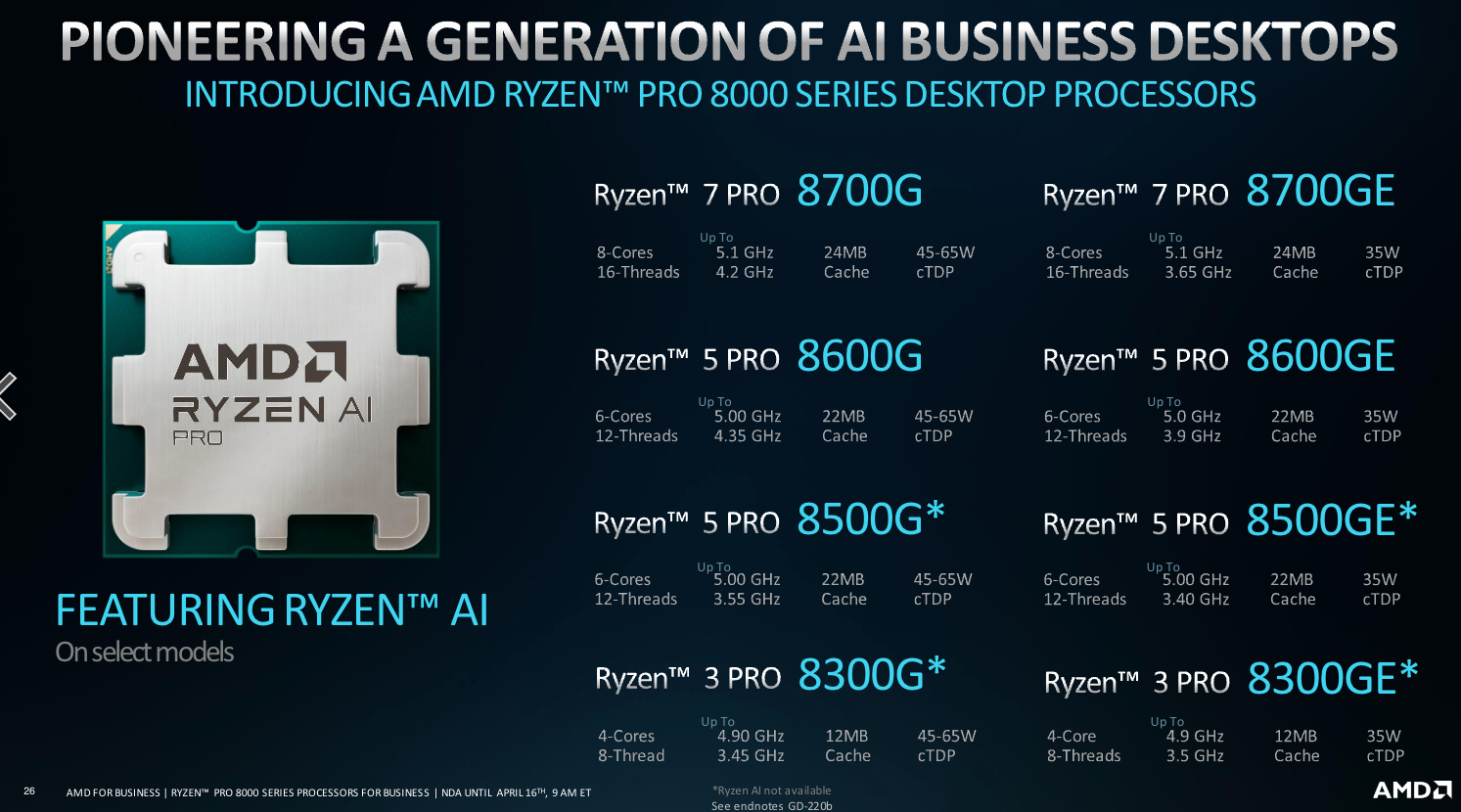
Today, AMD introduced the Ryzen PRO 8000 desktop and Ryzen PRO 8040 mobile processors, the latest high-performance computing-focused iterations of the Ryzen processors for creative work, gaming or speeding up work assignments. Both the desktop and mobile processors are made with the x86 instruction set and run on AMD’s Zen 4 CPU architecture, as did the 8000G desktop processors revealed in January.
The Ryzen Pro 8000 series will be available April 16 internationally.
AMD Ryzen Pro 8000 for desktop
The Ryzen Pro 8000 series (Figure A) integrates with the Ryzen AI software platform to allow for processing-power-heavy features like video editing during live Teams or Zoom meetings. Plus, it can work with the AMD Pro platform, which provides enhanced security and manageability for corporate IT teams.
The Ryzen Pro 8000 chip was codenamed Hawk Point. Image: AMD
AMD wants to “invest in something that is future-equipped to run all these AI-powered productivity boosts,” Ronak Shah, AMD global commercial product marketing manager, said at a press briefing on April 11.
The Ryzen Pro 8000 with the Ryzen AI engine will be available in a variety of configurations for different business needs (Figure B).
Figure B
Different configurations are available for business laptops. Image: AMD
AMD said its Ryzen AI chip with the Ryzen Pro 8000 series can perform at 16 mobile dedicated NPU TOPS (i.e., TOPS is a measurement of how many mathematical operations a chip can perform in a second, measured in trillions) or 39 total systems TOPS; compared to 11 and 34, respectively, for the Intel Core Ultra.
Large language model performance is a priority for AMD, too. Ryzen AI reduces the time to the first token and the tokens per second — basically, how long it takes for a generative AI to produce content, AMD said.
AMD Pro security and recovery enhancements
Desktops with AMD Pro coming soon in 2024 will have new security and recovery features:
Security from the integrated Microsoft Pluton processor. AMD memory guard, which provides encryption that protects business data if a company laptop is lost or stolen.
SEE: Intel’s Gaudi 3 accelerator could compete with AMD’s AI chips. (TechRepublic)
AMD Ryzen Pro 8040 series processors for laptops
AMD also revealed mobile processors for laptops in the Ryzen Pro 8000 line. The AMD Ryzen Pro 8040 series processors will appear in new and refurbished laptops from HP and Lenovo in 2024.
The silicon underpinning the Ryzen Pro 8040 series is mostly the same as that in the Ryzen Pro 7040 series, Shah said, both of which have up to 8 high performance cores and Zen 4 CPU architecture; however, the Ryzen Pro 8040 series has been optimized for power efficiency (better performance per watt) and better AI performance. That power efficiency means the laptop doesn’t go through its battery charge as fast if the employee using it spends a lot of time on Microsoft Teams, for example.
Competitors
The AMD Ryzen Pro 8000 series desktop processors and Rysen Pro 8040 series mobile processors compete with Intel’s Core and Core Ultra processors.










 We are sorry for that.
We are sorry for that. , so we’re unfamiliar with the new release process now: We accidentally missed an item required in the model release process – toxicity testing.
, so we’re unfamiliar with the new release process now: We accidentally missed an item required in the model release process – toxicity testing.