OpenAI has formally launched o3-pro, the newest and most superior mannequin in its o-series lineup. Earlier iterations of this mannequin household have constantly delivered sturdy outcomes throughout customary AI benchmarks — particularly in math, programming, and scientific duties — and o3-pro builds on these strengths.
The discharge notes for OpenAI’s o3-pro learn, partly: “Like o1-pro, o3-pro is a model of our most clever mannequin, o3, designed to suppose longer and supply probably the most dependable responses. Because the launch of o1-pro, customers have favored this mannequin for domains resembling math, science, and coding—areas the place o3-pro continues to excel, as proven in tutorial evaluations.”
The o3-pro mannequin is at the moment accessible for Professional and Staff customers in ChatGPT and in its API, with availability for Edu and Enterprise accounts anticipated subsequent week, following a rollout schedule just like earlier fashions.
Comparative evaluations
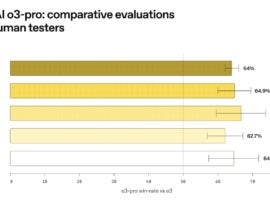
Previous to publishing benchmark information, OpenAI gave human testers the chance to check out o3-pro and examine it in opposition to the outcomes of o3. The vast majority of these human testers most popular o3-pro over o3 in key areas, together with:
- All queries (64%)
- Scientific evaluation (64.9%)
- Private writing (66.7%)
- Laptop programming (62.7%)
- Knowledge evaluation (64.3%)
Move@1 accuracy and effectivity benchmarks
Steadily used to measure the effectivity of recent AI fashions, a move@1 benchmark highlights the mannequin’s potential to generate an correct response on the primary try. Unsurprisingly, the o3-pro outperforms the o3 and the o1-pro on numerous benchmarks.
| Aggressive arithmetic (AIME 2024) | PhD-level science (GPQA Diamond) | Aggressive coding (Codeforces) | |
|---|---|---|---|
| o3-pro | 93% | 84% | 2748 |
| o3 | 90% | 81% | 2517 |
| o1-pro | 86% | 79% | 1707 |
4/4 reliability benchmarks
The staff at OpenAI subjected their AI fashions to a sequence of 4/4 reliability benchmarks. In these evaluations, an AI mannequin can solely achieve success if it gives an accurate response in 4 out of 4 makes an attempt. Any failed makes an attempt end in an automated failure of the 4/4 reliability benchmarks.
| Aggressive arithmetic (AIME 2024) | PhD-level science (GPQA Diamond) | Aggressive coding (Codeforces) | |
|---|---|---|---|
| o3-pro | 90% | 76% | 2301 |
| o3 | 80% | 67% | 2011 |
| o1-pro | 80% | 74% | 1423 |
Limitations of o3-pro
The constraints of o3-pro to think about embody:
- On the time of this writing, non permanent chats in o3-pro are at the moment disabled whereas the OpenAI staff addresses a technical subject.
- o3-pro doesn’t assist picture technology. Customers who want picture technology performance are urged to make use of GPT-4o, OpenAI o3, or OpenAI o4-mini.
- o3-pro doesn’t assist OpenAI’s Canvas interface. It’s unclear if assist shall be added at a later date.>
Weighing the professionals and cons of o3-pro
Though OpenAI admits that o3-pro performs slower than o1-pro in some cases, it’s a results of the extra options within the newest model. As TechnologyAdvice Managing Editor Corey Noles writes in his person information on TechRepublic sister website The Neuron, “o3‑Professional isn’t your on a regular basis chat buddy—it’s the brainiac you summon when accuracy trumps pace.”
With the power to go looking the web in actual time, carry out advanced information evaluation, present reasoning based mostly on visible prompts, and extra, o3-pro is the clear winner in the case of total performance.
Learn our protection of superintelligence predictions by OpenAI CEO Sam Altman.