
Image by Author
Data science involves extracting value and insights from large volumes of data to drive business decisions. It also involves building predictive models using historical data. Databases facilitate effective storage, management, retrieval, and analysis of such large volumes of data.
So, as a data scientist, you should understand the fundamentals of databases. Because they enable the storage and management of large and complex datasets, allowing for efficient data exploration, modeling, and deriving insights. Let’s explore this in greater detail in this article.
We’ll start by discussing the essential database skills for data science, including SQL for data retrieval, database design, optimization, and much more. We’ll then go over the main database types, their advantages, and use cases.
Essential Database Skills for Data Science
Database skills are essential for data scientists, as they provide the foundation for effective data management, analysis, and interpretation.
Here's a breakdown of the key database skills that data scientists should understand:
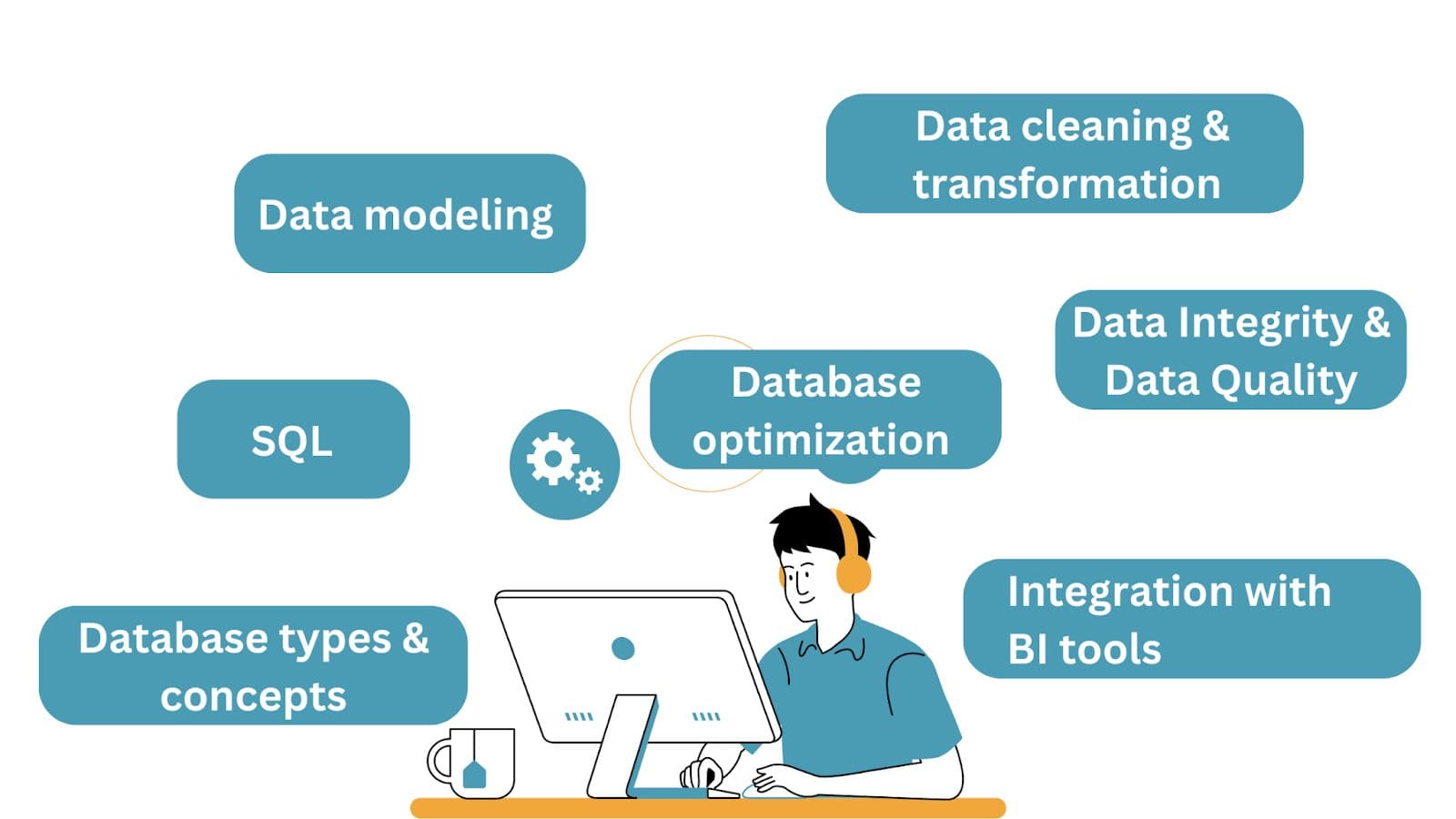
Image by Author
Though we’ve tried to categorize the database concepts and skills into different buckets, they go together. And you’d often need to know or learn them along the way when working on projects.
Now let's go over each of the above.
1. Database Types and Concepts
As a data scientist, you should have a good understanding of different types of databases, such as relational and NoSQL databases, and their respective use cases.
2. SQL (Structured Query Language) for Data Retrieval
Proficiency in SQL achieved through practice is a must for any role in the data space. You should be able to write and optimize SQL queries to retrieve, filter, aggregate, and join data from databases.
It’s also helpful to understand query execution plans and be able to identify and resolve performance bottlenecks.
3. Data Modeling and Database Design
Going beyond querying database tables, you should understand the basics of data modeling and database design, including entity-relationship (ER) diagrams, schema design, and data validation constraints.
You should be also able to design database schemas that support efficient querying and data storage for analytical purposes.
4. Data Cleaning and Transformation
As a data scientist, you’ll have to preprocess and transform raw data into a suitable format for analysis. Databases can support data cleaning, transformation, and integration tasks.
So you should know how to extract data from various sources, transform it into a suitable format, and load it into databases for analysis. Familiarity with ETL tools, scripting languages (Python, R), and data transformation techniques is important.
5. Database Optimization
You should be aware of techniques to optimize database performance, such as creating indexes, denormalization, and using caching mechanisms.
To optimize database performance, indexes are used to speed up data retrieval. Proper indexing improves query response times by allowing the database engine to quickly locate the required data.
6. Data Integrity and Quality Checks
Data integrity is maintained through constraints that define rules for data entry. Constraints such as unique, not null, and check constraints ensure the accuracy and reliability of the data.
Transactions are used to ensure data consistency, guaranteeing that multiple operations are treated as a single, atomic unit.
7. Integration with Tools and Languages
Databases can integrate with popular analytics and visualization tools, allowing data scientists to analyze and present their findings effectively. So you should know how to connect to and interact with databases using programming languages like Python, and perform data analysis.
Familiarity with tools like Python's pandas, R, and visualization libraries is necessary too.
In summary: Understanding various database types, SQL, data modeling, ETL processes, performance optimization, data integrity, and integration with programming languages are key components of a data scientist's skill set.
In the remainder of this introductory guide, we’ll focus on fundamental database concepts and types.
Image by Author Fundamentals of Relational Databases
Relational databases are a type of database management system (DBMS) that organize and store data in a structured manner using tables with rows and columns. Popular RDBMS include PostgreSQL, MySQL, Microsoft SQL Server, and Oracle.
Let's dive into some key relational database concepts using examples.
Relational Database Tables
In a relational database, each table represents a specific entity, and the relationships between tables are established using keys.
To understand how data is organized in relational database tables, it’s helpful to start with entities and attributes.
You’ll often want to store data about objects: students, customers, orders, products, and the like. These objects are entities and they have attributes.
Let’s take the example of a simple entity—a "Student" object with three attributes: FirstName, LastName, and Grade. When storing the data The entity becomes the database table, and the attributes the column names or fields. And each row is an instance of an entity.
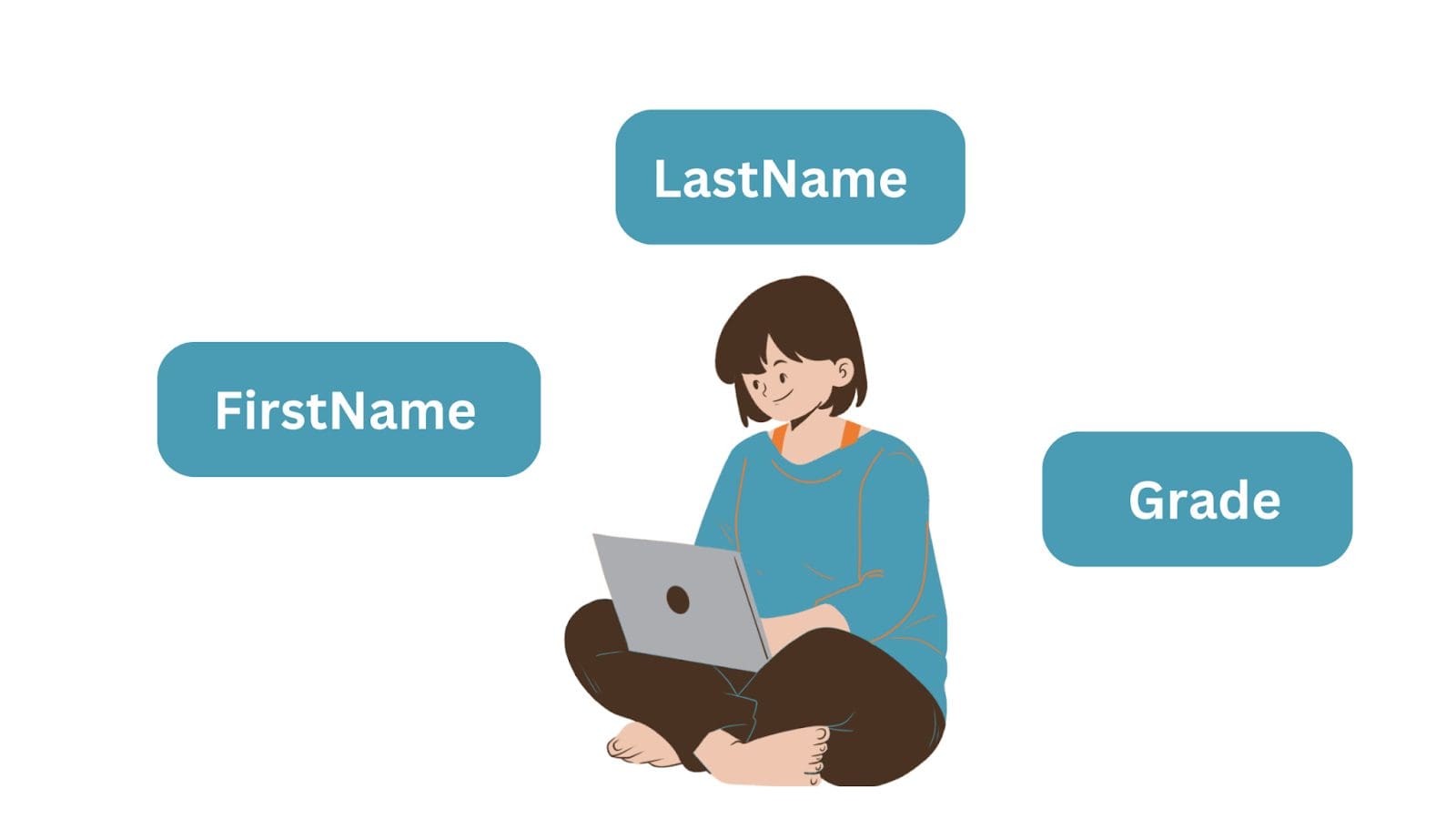
Image by Author
Tables in a relational database consists of rows and columns:
- The rows are also known as records or tuples, and
- The columns are referred to as attributes or fields.
Here's an example of a simple "Students" table:
| StudentID | FirstName | LastName | Grade |
| 1 | Jane | Smith | A+ |
| 2 | Emily | Brown | A |
| 3 | Jake | Williams | B+ |
In this example, each row represents a student, and each column represents a piece of information about the student.
Understanding Keys
Keys are used to uniquely identify rows within a table. The two important types of keys include:
- Primary Key: A primary key uniquely identifies each row in a table. It ensures data integrity and provides a way to reference specific records. In the "Students" table, "StudentID" could be the primary key.
- Foreign Key: A foreign key establishes a relationship between tables. It refers to the primary key of another table and is used to link related data. For example, if we have another table called "Courses," the "StudentID" column in the "Courses" table could be a foreign key referencing the "StudentID" in the "Students" table.
Relationships
Relational databases allow you to establish relationships between tables. Here are the most important and commonly occurring relationships:
- One-to-One Relationship: Under one-to-one relationship, each record in a table is related to one—and only one—record in another table in the database. For example, a "StudentDetails" table with additional information about each student might have a one-to-one relationship with the "Students" table.
- One-to-Many Relationship: One record in the first table is related to multiple records in the second table. For instance, a "Courses" table could have a one-to-many relationship with the "Students" table, where each course is associated with multiple students.
- Many-to-Many Relationship: Multiple records in both tables are related to each other. To represent this, an intermediary table, often called a junction or link table, is used. For example, a "StudentsCourses" table could establish a many-to-many relationship between students and courses.
Normalization
Normalization (often discussed under database optimization techniques) is the process of organizing data in a way that minimizes data redundancy and improves data integrity. It involves breaking down large tables into smaller, related tables. Each table should represent a single entity or concept to avoid duplicating data.
For instance, if we consider the "Students" table and a hypothetical "Addresses" table, normalization might involve creating a separate "Addresses" table with its own primary key and linking it to the "Students" table using a foreign key.
Advantages and Limitations of Relational Databases
Here are some advantages of relational databases:
- Relational databases provide a structured and organized way to store data, making it easy to define relationships between different types of data.
- They support ACID properties (Atomicity, Consistency, Isolation, Durability) for transactions, ensuring that data remains consistent.
On the flip side, they have the following limitations:
- Relational databases have challenges with horizontal scalability, making it challenging to handle massive amounts of data and high traffic loads.
- They also require a rigid schema, making it challenging to accommodate changes in data structure without modifying the schema.
- Relational databases are designed for structured data with well-defined relationships. They may not be well-suited for storing unstructured or semi-structured data like documents, images, and multimedia content.
Exploring NoSQL Databases
NoSQL databases do not store data in tables in the familiar row-column format (so are non-relational). The term "NoSQL" stands for "not only SQL"—indicating that these databases differ from the traditional relational database model.
The key advantages of NoSQL databases are their scalability and flexibility. These databases are designed to handle large volumes of unstructured or semi-structured data and provide more flexible and scalable solutions compared to traditional relational databases.
NoSQL databases encompass a variety of database types that differ in their data models, storage mechanisms, and query languages. Some common categories of NoSQL databases include:
- Key-value stores
- Document databases
- Column-family databases
- Graph databases.
Now, let's go over each of the NoSQL database categories, exploring their characteristics, use cases, and examples, advantages, and limitations.
Key-Value Stores
Key-value stores store data as simple pairs of keys and values. They are optimized for high-speed read and write operations. They are suitable for applications such as caching, session management, and real-time analytics.
These databases, however, have limited querying capabilities beyond key-based retrieval. So they’re not suitable for complex relationships.
Amazon DynamoDB and Redis are popular key-value stores.
Document Databases
Document databases store data in document formats such as JSON and BSON. Each document can have varying structures, allowing for nested and complex data. Their flexible schema allows easy handling of semi-structured data, supporting evolving data models and hierarchical relationships.
These are particularly well-suited for content management, e-commerce platforms, catalogs, user profiles, and applications with changing data structures. Document databases may not be as efficient for complex joins or complex queries involving multiple documents.
MongoDB and Couchbase are popular document databases.
Column-Family Stores (Wide-Column Stores)
Column-family stores, also known as columnar databases or column-oriented databases, are a type of NoSQL database that organizes and stores data in a column-oriented fashion rather than the traditional row-oriented manner of relational databases.
Column-family stores are suitable for analytical workloads that involve running complex queries on large datasets. Aggregations, filtering, and data transformations are often performed more efficiently in column-family databases. They’re helpful for managing large amounts of semi-structured or sparse data.
Apache Cassandra, ScyllaDB, and HBase are some column-family stores.
Graph Databases
Graph databases model data and relationships in nodes and edges, respectively. to represent complex relationships. These databases support efficient handling of complex relationships and powerful graph query languages.
As you can guess, these databases are suitable for social networks, recommendation engines, knowledge graphs, and in general, data with intricate relationships.
Examples of popular graph databases are Neo4j and Amazon Neptune.
There are many NoSQL database types. So how do we decide which one to use? Well. The answer is: it depends.
Each category of NoSQL database offers unique features and benefits, making them suitable for specific use cases. It's important to choose the appropriate NoSQL database by factoring in access patterns, scalability requirements, and performance considerations.
To sum up: NoSQL databases offer advantages in terms of flexibility, scalability, and performance, making them suitable for a wide range of applications, including big data, real-time analytics, and dynamic web applications. However, they come with trade-offs in terms of data consistency.
Advantages and Limitations of NoSQL Databases
The following are some advantages of NoSQL databases:
- NoSQL databases are designed for horizontal scalability, allowing them to handle massive amounts of data and traffic.
- These databases allow for flexible and dynamic schemas. They have flexible data models to accommodate various data types and structures, making them well-suited for unstructured or semi-structured data.
- Many NoSQL databases are designed to operate in distributed and fault-tolerant environments, providing high availability even in the presence of hardware failures or network outages.
- They can handle unstructured or semi-structured data, making them suitable for applications dealing with diverse data types.
Some limitations include:
- NoSQL databases prioritize scalability and performance over strict ACID compliance. This can result in eventual consistency and may not be suitable for applications that require strong data consistency.
- Because NoSQL databases come in various flavors with different APIs and data models, the lack of standardization can make it challenging to switch between databases or integrate them seamlessly.
It's important to note that NoSQL databases are not a one-size-fits-all solution. The choice between a NoSQL and a relational database depends on the specific needs of your application, including data volume, query patterns, and scalability requirements amongst others.
Relational vs. NoSQL Databases
Let’s sum up the differences we’ve discussed thus far:
| Feature | Relational Databases | NoSQL Databases |
| Data Model | Tabular structure (tables) | Diverse data models (documents, key-value pairs, graphs, columns, etc.) |
| Data Consistency | Strong consistency | Eventual consistency |
| Schema | Well-defined schema | Flexible or schema-less |
| Data Relationships | Supports complex relationships | Varies by type (limited or explicit relationships) |
| Query Language | SQL-based queries | Specific query language or APIs |
| Flexibility | Not as flexible for unstructured data | Suited for diverse data types, including |
| Use Cases | Well-structured data, complex transactions | Large-scale, high-throughput, real-time applications |
A Note on Time Series Databases
As a data scientist, you’ll also work with time series data. Time series databases are also non-relational databases, but have a more specific use case.
They need to support storing, managing, and querying timestamped data points—data points that are recorded over time—such as sensor readings and stock prices. They offer specialized features for storing, querying, and analyzing time-based data patterns.
Some examples of time series databases include InfluxDB, QuestDB, and TimescaleDB.
Conclusion
In this guide, we went over relational and NoSQL databases. It’s also worth noting that you can explore a few more databases beyond popular relational and NoSQL types. NewSQL databases such as CockroachDB provide the traditional benefits of SQL databases while providing the scalability and performance of NoSQL databases.
You can also use an in-memory database that stores and manages data primarily in the main memory (RAM) of a computer, as opposed to traditional databases that store data on disk. This approach offers significant performance benefits due to the much faster read and write operations that can be performed in memory compared to disk storage.
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more.
- From Oracle to Databases for AI: The Evolution of Data Storage
- Column-Oriented Databases, Explained
- Document Databases, Explained
- Key-Value Databases, Explained
- NoSQL Databases and Their Use Cases
- Graph Databases, Explained
{kind=link}