

OpenAI has shattered the boundaries of AI customisation with the debut of reinforcement fine-tuning (RFT) for its o1 models on the second day of its ‘12 Days of OpenAI’ livestream series. This new breakthrough marks the end of traditional fine-tuning as we know it. With RFT, models don’t just replicate—they reason.
By employing reinforcement learning, OpenAI looks to empower organisations to build expert-level AI for complex tasks in law, healthcare, finance, and beyond. This new approach enables organisations to train models using reinforcement learning to handle domain-specific tasks with minimal data, sometimes as few as 12 examples.
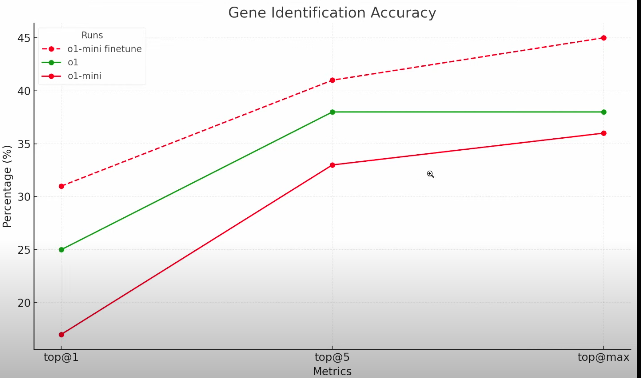
By using reference answers to evaluate and refine model outputs, RFT improves reasoning and accuracy in expert-level tasks. OpenAI demonstrated this technique by fine-tuning the o1-mini model, allowing it to predict genetic diseases more accurately than its previous version.
Redefining Model Fine-Tuning
Unlike traditional fine-tuning, RFT focuses on teaching models to think and reason through problems, as Mark Chen, OpenAI’s head of research, explained: “This is not standard fine-tuning… it leverages reinforcement learning algorithms that took us from advanced high school level to expert PhD level.”
Limitations: the approach is not without limitations. OpenAI engineer John Allard explained that RFT excels in tasks where outcomes are “objectively correct and widely agreed upon,” but may struggle in subjective domains or creative applications where consensus is harder to define.
However, reinforcement fine-tuning (RFT) is generally considered more computationally efficient compared to traditional full fine-tuning. Critics also note that RFT’s performance depends heavily on task design and the quality of the training data.
Interestingly, with RFT, you can achieve significant performance improvements with just a few dozen examples because the model learns from feedback rather than needing to see all possible scenarios.
Early adopters, including Berkeley Lab researchers, have already achieved remarkable results. For example, a fine-tuned o1-mini model outperformed its base version in identifying genetic mutations that cause rare diseases.
OpenAI has opened its RFT alpha program to select organisations. Participating teams will gain access to OpenAI’s infrastructure to train models optimised for their unique needs. “Developers can now leverage the same tools we use internally to build domain-specific expert models,” said Allard.
Justin Reese, a computational biologist, highlighted RFT’s transformative potential in healthcare, particularly for rare diseases affecting millions. “The ability to combine domain expertise with systematic reasoning over biomedical data is game-changing,” he said.
Similarly, OpenAI’s partnership with Thomson Reuters has already demonstrated success in fine-tuning legal models, paving the way for enhanced AI applications in high-stakes fields like law and insurance.
A New Era of AI Customisation
With a public release planned for 2025, OpenAI aims to refine RFT based on feedback from early participants. Beyond its initial applications, OpenAI envisions RFT models advancing fields like mathematics, research, and agent-based decision-making. “This is about creating hyper-specialised tools for humanity’s most complex challenges,” said Chen.
Simply put, this technique transforms OpenAI’s o1 series of models into domain-specific experts, enabling them to reason with unparalleled accuracy and outperform their base versions on complex, high-stakes tasks.
Regular fine-tuning typically involves training a pre-trained model on a new dataset with supervised learning, where the model adjusts its parameters based on the exact outputs or labels provided in the dataset.
On the other hand, RFT uses reinforcement learning where the model learns from feedback on its performance, not just from direct examples.
Instead of learning from fixed labels, the model gets scored based on how well it performs on tasks according to a predefined rubric or grader. This allows the model to explore different solutions and learn from the outcomes, focusing on improving reasoning capabilities.
ChatGPT o1 Pro Feels like Buying a Lambo
On the first day of 12 Days of OpenAI, the company released the full version of o1 and a new $200 ChatGPT Pro model. The ChatGPT Pro plan includes all the features of the Plus plan and access to the additional o1 Pro mode, which is said to use ‘more compute for the best answers to the hardest questions’. Furthermore, the plan is set to offer unlimited access to o1, o1-mini and GPT-4o along with the advanced voice mode.
OpenAI also announced new developer-centric features to the model. These include structured outputs, function calling, developer messages, and API image understanding. OpenAI also said they’re working on bringing API support to the o1 model.
“for extra clarity: o1 is available in our plus tier, for $20/month. with the new pro tier ($200/month), it can think even harder for the hardest problems. most users will be very happy with o1 in the plus tier!,” posted OpenAI chief Sam Altman on X.
Many in the community feel that $200 is too much for a ChatGPT Pro subscription. “Don’t think I need o1 Pro for $200/month. o1 is enough for me. Heck, just GPT-4o is enough for me,” posted a user on X.
“ChatGPT o1 Pro feels like buying a Lambo. Are you in?” posted another user.
Ethan Mollick, associate professor at The Wharton School, who has early access to o1, shared his experience and compared it to Claude Sonnet 3.5 and Gemini. “It can solve some PhD-level problems and has clear applications in science, finance, and other high-value fields. Discovering uses will require real R&D efforts,” he said.
He explained that while o1 outperforms Sonnet in solving specific hard problems that Sonnet struggles with, it doesn’t surpass Sonnet in every area. Sonnet remains stronger in other domains. “o1 is not better as a writer, but it often capable of developing complex plots better than Sonnet because it can plan ahead better,” he said.
A Reddit user shared their experience after spending 8 hours testing OpenAI’s o1 Pro ($200) against Claude Sonnet 3.5 ($20) in real-world applications.
For complex reasoning, o1 Pro was the winner, providing slightly better results but taking 20-30 seconds longer per response. Claude Sonnet 3.5, while faster, achieved 90% accuracy on these tasks. In code generation, Claude Sonnet 3.5 outperformed o1 Pro, producing cleaner, more maintainable code with better documentation, whereas o1 Pro tended to overengineer solutions.
Similarly, Abacus AI chief Bindu Reddy said that Sonnet 3.5 still performs better than o1 in coding, based on manual tests she conducted since OpenAI has not yet released the API.
“Early indications are that Sonnet 3.5 still rules when it comes to coding. We will be able to confirm this result whenever OpenAI chooses to make an API available,” she said.
The post Fine-Tuning is Dead, Long Live Reinforcement Fine-Tuning appeared first on Analytics India Magazine.