
AI4Bharat has announced the launch of BhasaAnuvaad, a speech translation dataset tailored for Indian languages, boasting coverage across 13 languages and approximately 44,400 hours of audio. This marks the largest publicly accessible speech translation resource of its kind for Indian linguistic diversity.
Click here to check out the GitHub repository.
BhasaAnuvaad aims to address gaps in existing speech translation benchmarks that often lack sufficient resources for Indian languages and struggle with India-specific challenges like code-switching and dialect variations.
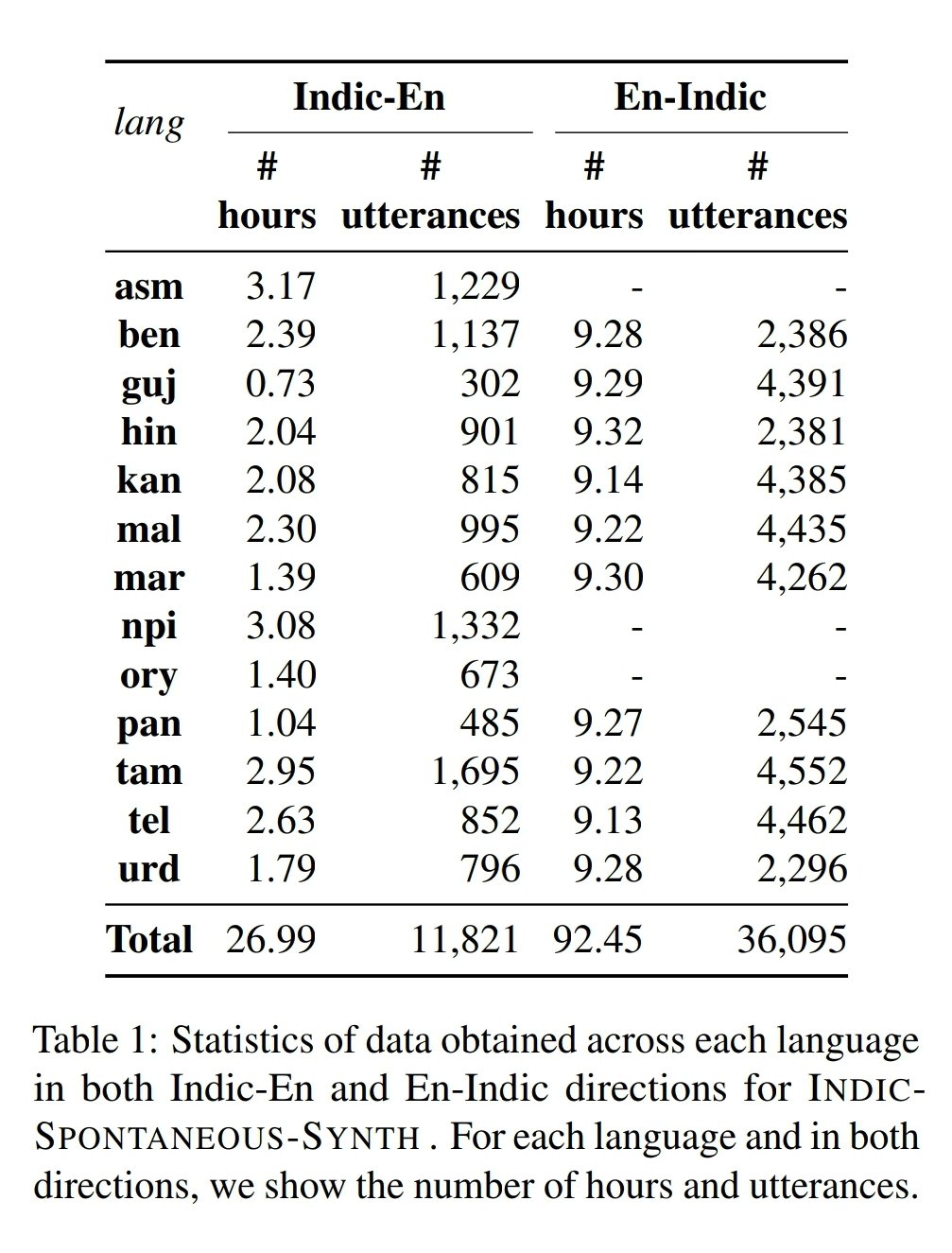
Recognising these needs, AI4Bharat also developed Indic-Spontaneous-Synth, a synthetic evaluation set to highlight how current models, though effective on datasets like FLEURS, tend to underperform in realistic, spontaneous language translation scenarios, underscoring the need for more robust datasets.
The dataset spans a broad spectrum of India’s linguistic landscape, covering Hindi, Bengali, Tamil, Telugu, Malayalam, Kannada, Gujarati, Marathi, Odia, Punjabi, Urdu, Assamese, and Nepali. The data originates from three key sources: existing public resources, large-scale web scraping, and synthetic data generation.
Paper Alert!!
Introducing BhasaAnuvaad, the largest publicly available speech translation dataset for Indian languages, covering 13 languages and ~44,400 hours.
Paper: https://t.co/9Utm50V9LA
Code: https://t.co/EFENAPmB9F
Dataset:https://t.co/VZAz0yQ6pE
1/N pic.twitter.com/x55tISC6eK— AI4Bharat (@ai4bharat) November 13, 2024
AI4Bharat’s roadmap includes a future release of a human-edited version of Indic-Spontaneous-Synth, as well as plans to expand BhasaAnuvaad with more data and to develop a dedicated speech translation model for Indian languages.
Recently, AI4Bharat, in partnership with IBM Research India, introduced MILU (Multi-task Indic Language Understanding Benchmark), an extensive new evaluation benchmark for Indic languages.
This benchmark, developed under The AI Alliance, includes 85,000 multiple-choice questions across 11 Indian languages, covering eight diverse domains and over 40 subjects with an India-centric focus on both general and cultural knowledge.
The post AI4Bharat Introduces BhasaAnuvaad, Speech Translation Dataset of 13 Indian Languages with 44,400 Hours of Data appeared first on Analytics India Magazine.
{kind=link}