
While everyone talks about data protection and building transparent AI models, a less discussed yet critical concern looms large: adversarial machine learning (AML). This emerging field of cybersecurity exposes the vulnerabilities of AI systems, one where even slight manipulation can lead to disastrous consequences, as we have witnessed in several cases over the last few years.
To begin with, AML refers to techniques used to exploit the weaknesses of ML models. Attackers create subtle perturbations in input data, often unnoticeable to humans, to deceive these systems. For example, an AI system designed to classify images might misidentify a stop sign as a speed limit sign after minor alterations. Instances like this can be a significant risk to autonomous vehicles.
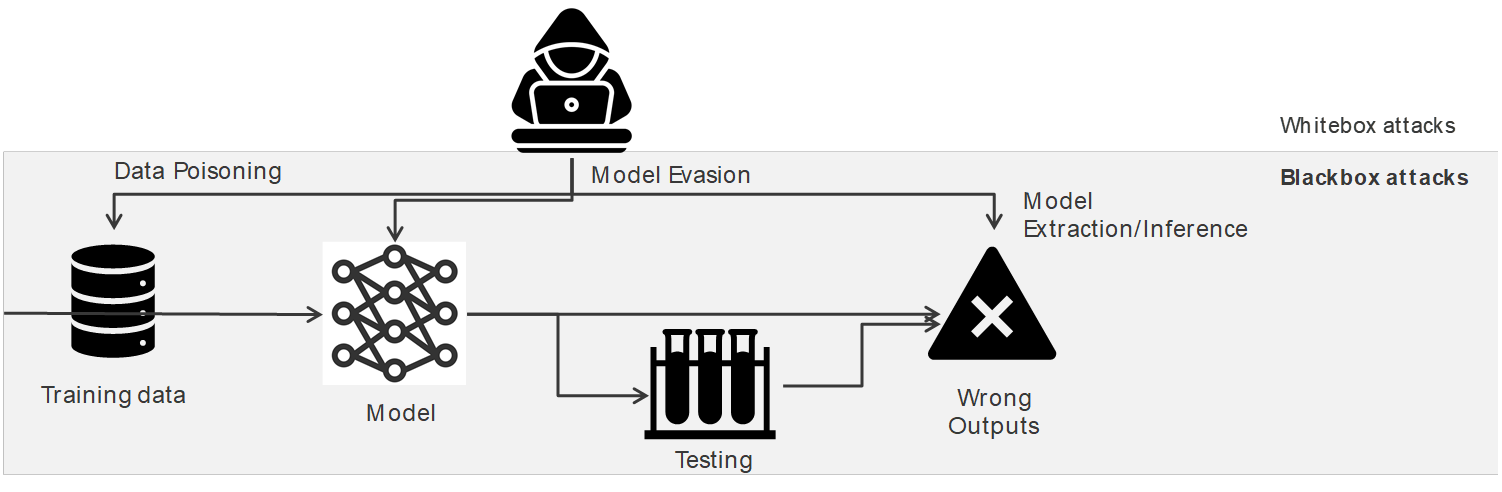
While AI systems can become tools for attackers facilitating sophisticated and automated attacks such as phishing and malware threats, AML is a bit difficult to detect. This is where attackers use AI to disrupt machine learning models through techniques like model poisoning, model theft, and adversarial inputs.
These threats highlight the importance of securing AI systems at every stage of their lifecycle, from data collection to building models to deployment. This can be achieved through data poisoning attacks, where attackers inject malicious data into training datasets, influencing the model’s decisions.
Preparation, Precautions, and Mitigation against AML attacks
There are several mitigation strategies for building secure AI systems, which include avoiding data from untrusted sources, implementing data sanitisation techniques like activation clustering, and using STRong Intentional Perturbation (STRIP) to detect trigger patterns.
However, some attacks include manipulating the model with pre-trained models that can be compromised by Trojan nodes or backdoors. To reduce this, it is better to rely on pre-trained models only from trusted sources and apply fine pruning to remove malicious components.
Here are the mitigation strategies based on the stage of the ML ecosystem:
Data Collection & Preparation stage: At this stage, the security questions that arise are whether the data source is valid and authenticated, whether the data is mislabeled, and whether the data is prepared correctly.
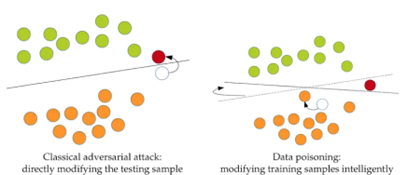
A possible threat at this stage includes a data poisoning attack where a miscreant attacks training data with poison data to influence model decisions on a targeted or intended class.
For mitigation of this, it is advisable to include not using training data from untrusted domains, data sanitisation using the activation clustering method, and STRIP.
Model Building Stage (Pre-Trained Models): At this stage, the security questions that arise are:
- Is the source of the pre-trained model known?
- Is the pre-trained model crafted?
Possible threats at this stage include a pre-trained model using a Trojan Node or latent variable, where the miscreant injects a malicious node into the pre-trained model or embeds AI with backdoor fine-tuning to generate the intended output.
Possible mitigation strategies include not using pre-trained models from untrusted sources, fine-pruning to remove malicious nodes and STRIP.
Model Building Stage (ML Frameworks): At this stage, the security questions that arise are:
- Is the ML framework being used correctly?
- Is the ML framework the latest?
- Are all security patches applied?
Possible threats at this stage include pre-trained models using malicious ML frameworks or malicious layers embedded in the AI as the victims fine-tune the AI with a pre-trained model.
For such cases, a possible mitigation strategy is using the latest version of the ML framework.
Model Deployment Stage: At this stage, the security questions include:
- Is the query access to AI crafted?
- Is AI responding to unnecessary information?
Several possible threats can occur at this stage.
Evasion Attacks: These attacks manipulate input data to bypass detection or classification systems. For example, attackers might design malware that avoids being flagged by an AI-powered security system.
For example, a minuscule difference in the profile of a compliant customer will make the model predict or classify risky customers.
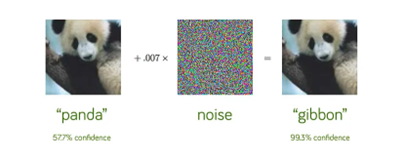
Poisoning Attacks: Attackers can compromise the model’s integrity by injecting malicious data during the training phase. This can result in models that underperform or behave unpredictably.
For example, a good credit lending model can be spoiled by reconstructing small, unnoticeable changes in a few customer features in a training or retraining dataset.
Model Extraction Attacks: In these attacks, miscreants exploit query access to steal the underlying model’s parameters or intellectual property, enabling replication or further attacks.
For example, exploiting a deployed credit model by malicious inputs and creating an alternative but similar credit risk with full control to use for malicious intent.
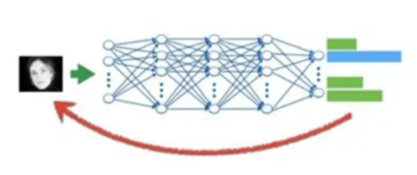
Inference Attacks: By analysing model predictions, attackers can infer sensitive details about the training data, potentially leading to privacy violations. This can include attacks aimed at learning about the attributes of a credit risk and compliant customer.
Real-World Implications of Adversarial Attacks
Adversarial attacks remind us that no AI system is infallible. Security must be embedded at every level of AI development.
Mitigation strategies for all possible attacks include key points that model builders, deployers, and users should keep in mind, which include data augmentation, adversarial training, ensemble method, and defensive distillation.
Robust Training: Introducing adversarial examples during the training phase can help models learn to resist attacks. This process, known as adversarial training, enhances resilience.
Regular Audits: Continuous vulnerability assessments and penetration testing can identify potential weaknesses in AI systems.
Defensive Algorithms: Techniques like defensive distillation and gradient masking can obscure models’ decision-making processes, making them harder to exploit.
Explainable AI: Building interpretable models allows developers to identify and address unexpected behaviours more effectively.
As AI becomes increasingly integrated into our lives, the need to secure it against adversarial threats becomes paramount. By proactively addressing these challenges, we can ensure AI systems remain trustworthy and reliable.
The adversarial threat landscape will continue to evolve, but so must our defences. Organisations must prioritise security as a foundational element of AI development, not an afterthought. Only through vigilance and innovation can we safeguard the transformative potential of AI.
The post Why is No One Talking About Adversarial Machine Learning? appeared first on Analytics India Magazine.
{kind=link}