
Inference speed is a hot topic right now as companies rush to fine-tune and build their own AI models. Conversations around test-time compute are also heating up with models like OpenAI’s o1 showcasing ‘thinking’ and reasoning skills post-prompt, relying on an infrastructure-powered computation even after training.
This is why companies like Groq, Sambanova, and Cerebras Systems have gained traction building their own hardware and providing unparalleled performance in inference, competing with the likes of NVIDIA and AMD.
However, Simplismart, a Bengaluru-based startup led by former Oracle and Google engineers, has emerged as a leader in creating high-performance AI deployment tools. It competes in inference speed on the software side, not focusing on the hardware.
Simplismart’s inference engine optimises performance for all model deployments. For instance, its software-level optimisations enabled Llama 3.1 8B to achieve a throughput of over 343 tokens per second, which is the fastest, while ignoring hardware companies like Groq, Cerebras, and SambaNova. The platform also supports models like Whisper V3, Mistral 7B, Melo TTS, and SDXL.
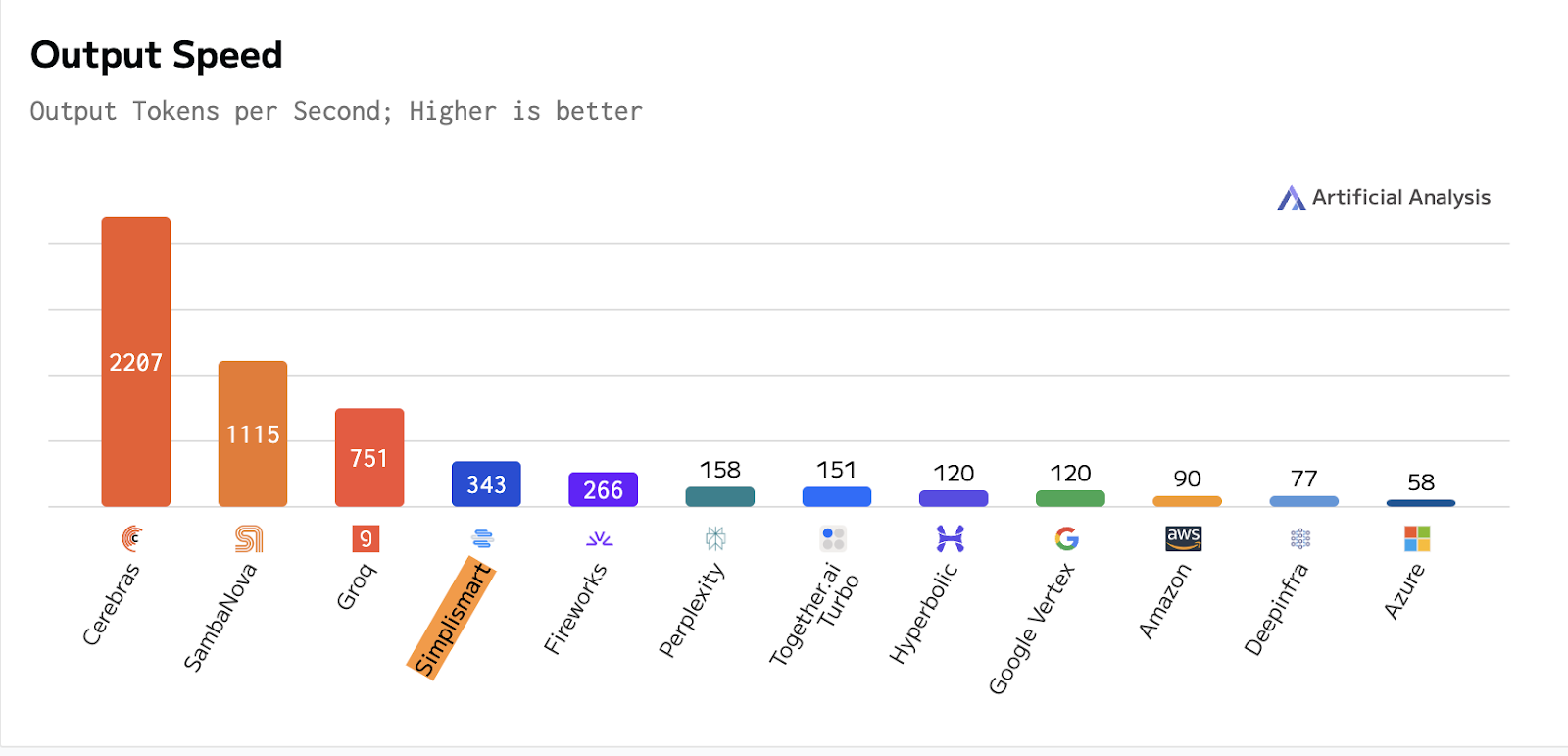

Unlike Groq and others, which rely on hardware or cloud-based solutions, Simplismart’s innovation lies in its MLOps platform, designed for on-premises enterprise deployments and flexible across different models and cloud platforms. Speaking with AIM, Amritanshu Jain, the co-founder and CEO, quickly clarified that Simplismart isn’t looking to enter the hardware race.
“Companies like Grok and Cerebras may market their hardware as the fastest in inference, but that’s a battle we don’t want to fight. Hardware is a race to the bottom, where companies constantly outdo each other with new chips. Instead, we’re building a universal engine that’s model-agnostic, chip-agnostic, and cloud-agnostic,” Jain said.

The platform offers a declarative language, similar to Terraform, simplifying the process of fine-tuning, deploying, and monitoring AI models at scale. This language allows enterprises to fine-tune, deploy, and monitor models with ease, providing a flexible solution adaptable to both on-premises and cloud-based environments.
Founded by Jain and Devansh Ghatak, this Bangalore-based startup is garnering attention with its claim of having developed the fastest inference engine in the world, outpacing rivals like TogetherAI and FireworksAI.
In October, Simplismart secured $7 million in a Series A funding round led by Accel, with participation from Shastra VC, Titan Capital, and angel investor Akshay Kothari, the co-founder of Notion.
“Our goal isn’t just to be the fastest but to provide enterprises with the autonomy they need to make AI work for them on their terms,” said Jain.
The company’s platform supports NVIDIA GPUs and AMD chips, and can integrate with specialised accelerators if they become publicly available. This adaptability means that Simplismart’s solutions can evolve with industry advancements, making it easier for enterprises to maintain AI performance without being locked into specific hardware vendors or cloud services.
Jain sees companies like Together AI and Fireworks AI as providers of generic AI services, whereas Simplismart aims to provide a more comprehensive solution. “TogetherAI and FireworksAI are essentially brokers of GPUs disguised as generative AI APIs,” Jain remarked. “They provide APIs for inference, but that’s not what enterprises truly need. Businesses want control over their data, SLAs, and privacy, which APIs alone can’t deliver.”
Instead of simply offering API access, Simplismart’s platform allows enterprises to host and manage AI models on their premises, ensuring greater security and control.
Jain pointed out that enterprises, especially those handling sensitive data, are hesitant to use third-party APIs due to data privacy concerns. By offering a Terraform-like language for MLOps orchestration, Simplismart gives businesses the tools to build and manage personalised inference engines that fit their specific needs, offering a level of customisation that APIs can’t match.
The Origin Story: From College Buddies to Co-founders
The partnership between Jain and Ghatak goes back to their college days, where they bonded over a shared interest in machine learning. After graduation, both embarked on careers that solidified their expertise in AI infrastructure. While Jain worked at Capillary Technologies and Oracle Cloud, Ghatak took up jobs at conversational AI firm Avaamo and Google.
The duo’s journey toward Simplismart began when they found themselves frustrated by the redundancy in the industry. “We were roommates in Bangalore, and we often found ourselves writing similar code for different organisations,” Jain recalled. “We realised that if big-tech firms were facing optimisation challenges for inference in natural language models, smaller enterprises would likely struggle even more.”
This insight laid the foundation for Simplismart. Inspired by a hackathon victory, they took the plunge in 2022, leaving their jobs to build a company that could offer enterprises a more efficient way to manage their AI models.
“In the early 2000s, AWS and GCP standardised the process of spinning up servers, while companies like Databricks and Snowflake later simplified data processing. Now, we’re at the cusp of a new inflection point with generative AI, where enterprises need standardised tools for deploying and managing models,” Jain concluded.
The post This Bengaluru Startup Made the Fastest Inference Engine, Beating Together AI and Fireworks AI appeared first on Analytics India Magazine.
{kind=link}