

The burning question among enterprises right now is, ‘How much does it cost to use an LLM?’
Presently, there is a plethora of options available to choose from. While OpenAI’s models are highly rated, we have observed that open-source models like Llama 2, Falcon 180-B, and Mistral 7B are catching up to GPT-4 in terms of performance, and are gaining traction.
Many industry leaders are advocating for domain-specific LLMs. At this juncture, it becomes crucial for CXOs to decide which option they should choose. However, selecting the optimal LLM amidst this vast array of open-source and proprietary models demands meticulous evaluation, considering the balance between cost and performance.
“When it comes to selecting an LLM, there is no right or wrong answer. It depends on the use cases. But at the same time, it is important to understand the factors that play a role in deciding the pricing.” said Abhishiek Choudhary co-founder and CTO at TrueFoundry at Cypher 2023, India’s biggest AI conference.
What are the Factors
The size of the LLM is the most significant factor impacting its cost. Larger models with more parameters require more computational resources to train and deploy, leading to higher costs. It cost OpenAI over $100 million to train GPT-4.
The context length, which determines the amount of information the LLM can consider, also affects pricing. Longer context lengths allow for more comprehensive understanding and generation of text, but they also increase computational demands and costs. For example, the cost for using the GPT-4 8K context model API is $0.03 per 1,000 tokens for input and $0.06 per 1,000 tokens for output. While for the 32K context model, the cost is $0.06 per 1,000 tokens for input and $0.12 per 1,000 tokens for output.
To make it easy for enterprises to decide, Choudhary showed three usecases – namely on basis of tokens, RAG (retrieval augmented generation) and fine tuning – through which one can get a ballpark estimate of how much a particular model costs – particularly in the context of Summarizing Wikipedia to Half its Size
Basis of Tokens
For example, Wikipedia has 6 million articles, and each article is around 750 words.
750 words equals to 1000 tokens because three fourths of a word is equal to one token, so in total it translates to 6 billion tokens. When we reduce the size of Wikipedia by half, we will be left with 3 billion tokens as output.
The cost variations for summarisation among different models reveal significant differences in pricing structures. GPT-4 with 32K context length demands a higher investment at $720,000, while its 8K counterpart costs $360,000. GPT-3.5 Turbo is a more budget-friendly option at $15,000, and Llama 2 offers competitive pricing at $14,000. However, the cheapest among all of these alternatives is Falcon 180 B whose cost comes out to be $ 5119.

If you are wondering how we arrived at this cost, below is the math for GPT-4 (8K Context length)
Cost of Summarisation
= (Cost for Input Tokens) + (Cost of Output Tokens)
= (Total Input Tokens * Cost per input token) + (Total Output Tokens + Cost per output Token)
= ( 6 Billion * 0.03 / 1000 ) + ( 3 Billion * 0.06 / 1000 )
= 180,000 + 180,000
= $ 360,000
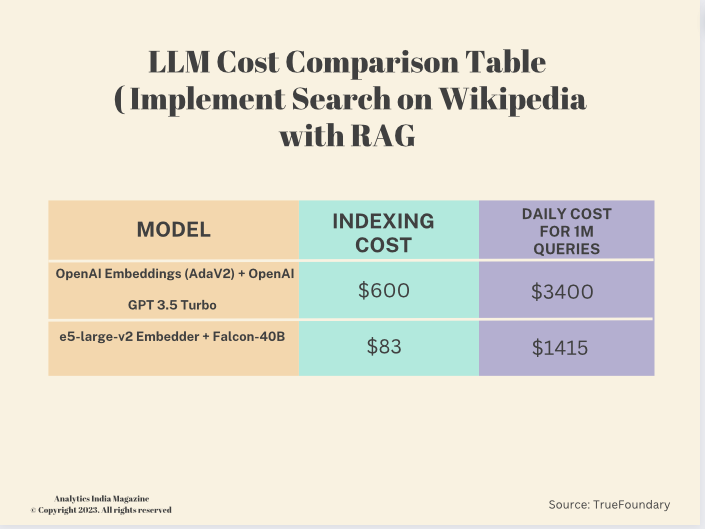
Basis of RAG
RAG is particularly useful when you have a large corpus of data and want to efficiently retrieve relevant information before generating a response. It combines retrieval models, which can quickly identify relevant passages, with generative models for more context-aware responses. This can be beneficial in scenarios where quick access to relevant information is crucial.
This is sometimes referred to as indexing.
The indexing cost for OpenAI Embeddings (AdaV2) + OpenAI GPT 3.5 Turbo is $600. While the daily cost for 1 million queries is $3400. On the other hand, the indexing cost for e5-large-v2 Embedder + Falcon-40B is $83 and the daily cost for 1 million queries is $1415.
Here the company has used T4 GPU and are considering the spot price on AWS which is 0.15$ / hour.
Below is the math for OpenAI Embeddings (AdaV2) + OpenAI GPT 3.5 Turbo
Indexing Cost (One Time)
= (Total Number of Tokens / 1000) * Cost per 1k token
= $ (6 Billion / 1000 ) * 0.0001
= $600
Daily Cost ( 1 Million queries)
Cost for one query
= (Avg input tokens) * (cost of input/token) + (Avg output tokens) * (cost of output / token)
= $ (2000) * (0.0015 / 1000) + (200) * (0.002 / 1000
= $ 0.003 + 0.0004
= $ 0.0034
Total Cost = $ 0.0034 * 1,000,000 = $ 3400
Basis of fine-tuning
The fine-tuning cost for OpenAI Curie 13B is $27,000 and daily cost for 1 million queries $ 26,400. On the other hand, the fine-tuning cost for LLaMa-v2-7b is $1365 and inference cost for 1 million queries is $470. This calculation is based on the use of A100 40GB GPU at a spot price on AWS (8x GPU) which is $9.83/hour.

Below is the math for fine-tuned OpenAI Curie 13 B
Daily Cost ( 1 Million queries)
Cost for one query
= (Avg input tokens) * (cost of input/token) + (Avg output tokens) * (cost of output / token)
= $ (2000) * (0.012 / 1000) + (200) * (0.012 / 1000)
= $ 0.024 + 0.0024
= $ 0.0264
Total Cost = $ 0.0264 * 1,000,000
= $ 26,400
Fine Tuning Cost (One Time)
Cost of Training
= ( Total tokens ) * (Cost Per Token)
= (9 Billion) * (0.003 / 1000)
= $ 27,000
In Conclusion
While OpenAI was the first one to come up with foundational models, it is noticed that their models are very costly to use. “Open AI makes the cost of serving any fine-tuned model 10x. If your GPT costs x, a fine-tuned model will cost you 10x” said Choudhary. As compared to OpenAI’s models, choosing open source models like Llama 2 or Falcon 40B will be much more cost effective.
The post The Cost of Using LLMs for Enterprise appeared first on Analytics India Magazine.