![]()
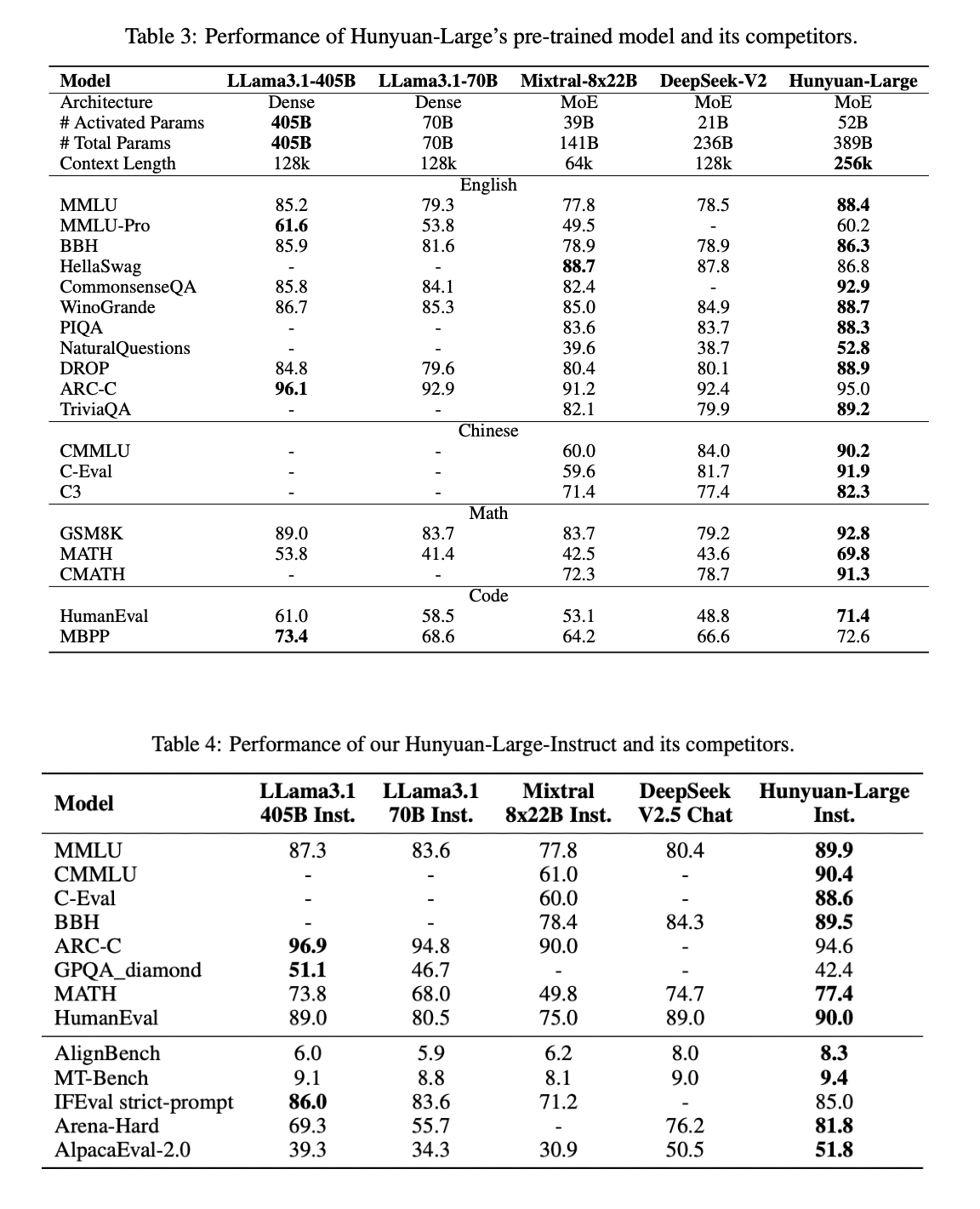
Chinese giant Tencent has just released a large 389 billion parameter open source model called Hunyuan Large – with 52 billion active parameters. The model supports a context length of 256,000 tokens and is one of the largest open-source models in its category. In comparison, both Llama 3.1 70B and 405B models support a 128,000 context length.
If you’re competing in the open-source arena, you’ve got to dethrone the king. Interestingly, the Hunyuan-Large outperforms the Llama3.1 70B model on several benchmarks in English and Chinese. The model’s performance was also comparable with Meta’s flagship Llama 3.1-405B model on tasks involving language understanding, coding, maths and logical reasoning.
Unlike the Llama 3.1 405B, Hunyuan Large isn’t a ‘dense’ model. This means that it doesn’t use all of its parameters for each input. Tencent explores Mixture of Experts (MoE) scaling laws to guide an optimal balance between model size, data volume, and performance. An MoE model activates only a subset of parameters based on its input. This makes it more efficient as it only uses a part of the model’s capacity each time.
Hunyuan Large incorporates several ‘innovative’ techniques to outperform its competition. This includes using 1.5 trillion tokens of higher-quality synthetic data, which is part of the 7 trillion parameters that the model is trained over. The model also incorporates various model structure enhancement techniques to reduce memory usage, increase performance, and balance token usage.
Tencent compared Hunyuan Large against leading open-source models in both pre-and post-training stages. In most results, Hunyuan Large came out on top in comparison with other dense, and MoE models with similar parameter sizes. The authors mentioned, “We also hope that the release of the largest and overall best performing MoE-based Hunyuan-Large could spark more ripple of debate about more promising techniques of LLMs among the community, in turn, to further improve our model from a more practical aspect and contribute to the more helpful AGI in the future.”
Tencent’s latest announcement comes after the news that China has adopted Meta’s open-source models for building a chatbot for military applications. This ensued a debate between Vinod Khosla and Yan LeCun, with the former criticising Meta for providing ease of access to LLMs. LeCun retaliated that China is quite competent with the United States in generative AI, and they wouldn’t entirely depend on Meta’s open-source models to develop any consequential technology. With the release of Hunyuan Large, Yann LeCun may just be right.
Interestingly, Meta has also announced that it is making Llama available to the US government, and any other private organisations working in the interests of national security.
The post Tencent Launches Hunyuan Large, Outperforms Llama 3.1 70B & 405B appeared first on Analytics India Magazine.