

The battle for token speed is intensifying as SambaNova, Cerebras, and Groq push the limits of inference performance. SambaNova recently made headlines by setting a new record for inference on Meta’s Llama 3.1 405B. The platform achieved 132 output tokens per second while running the model in native 16-bit precision.
In an exclusive interview with AIM, SambaNova’s chief architect Sumti Jairath revealed how SambaNova is different from its competitors. Notably, among the three—Groq, Cerebras, and SambaNova—SambaNova is the only platform offering Llama 3.1 405B.
The API inference on SambaNova cloud is powered by its SN40L custom AI chip, which features their Reconfigurable Dataflow Unit architecture. Manufactured on TSMC’s 5 nm process, the SN40L integrates DRAM, HBM3, and SRAM on each chip.
Jairath explained that one of the key differences SambaNova has over Cerebras and Groq is its three levels of memory hierarchy. “If you look at Groq and Cerebras, they only have SRAM. There is no HPM, and there is no high-capacity memory.”
He further explained that running the Llama 70B model on Groq requires nine racks of hardware, with each rack containing eight usable nodes and eight LPUs per node. The challenge, he explained, is having enough SRAM to accommodate 140 gigabytes of memory, which is necessary for the 70 billion parameters.
He added that while Groq and Cerebras handle the 70B model, scaling up would be difficult if the parametres increase. “The reason Cerebras and Groq don’t have Llama 405B yet is that the required capacity would need to grow by another factor of five to ten. The amount of hardware needed becomes impractical,” he said.
Speaking about SambaNova, he explained that they use the same rack for both Llama 70B and 405B models because of their large memory capacity. “We have 24 terabytes of DDR, one terabyte of HBM, and around eight gigabytes of SRAM. This combination allows us to manage up to 12 trillion parameters in a single box,” he said.
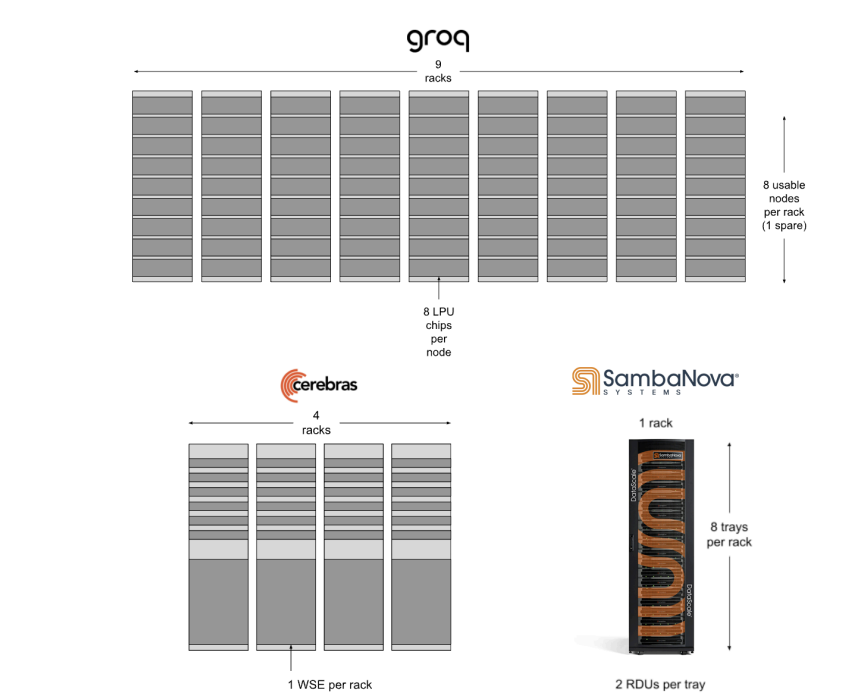
Referring to Cerebras, he explained that they would need four racks of hardware, or wafers. “The reason they haven’t made Llama 405B available is that it would require 12 racks of hardware—12 wafers in total—making it costly for them,” he said.
Would Love to Work With OpenAI
SambaNova Systems recently launched a new demo on Hugging Face, offering a high-speed, open-source alternative to OpenAI’s o1 model. The demo uses Meta’s Llama 3.1 Instruct model and competes directly with OpenAI’s latest release.
Jairath said that the company is willing to collaborate with any open-source model that matches the capabilities of OpenAI’s o1. Interestingly, he added that SambaNova is also willing to partner with OpenAI to run their models.
“If OpenAI is interested in using our hardware and running their models behind their firewall, I see no reason why it wouldn’t deliver better performance,” he said. Jairath also pointed out that OpenAI’s models would likely benefit from SambaNova’s hardware, saying, “They are currently running on GPUs, and their model architectures are well-aligned with what SambaNova offers.”
Better than Traditional GPUs
Raghu Prabhakar, engineer at SambaNova Systems, explained that running a complex operation like a Transformer decoder on a GPU often involves multiple kernel launches, each with its own memory access patterns and synchronisation costs. In contrast, the dataflow architecture allows for the fusion of these operations into a single kernel call, drastically reducing overhead and increasing throughput.
“On GPUs, each operator in a decoder might require multiple trips to high-performance memory (HPM), resulting in significant bandwidth and latency penalties. By grouping all operations into a single unit of execution, we eliminate these inefficiencies and achieve up to 3x to 4x better performance,” said Prabhkar.
Speaking about the SN40L chip, he explained, “The chip features over half a gigabyte of SRAM on a single socket, approximately 64 gigabytes of HPM, and 1.5 terabytes of off-package DDR high-capacity memory. The system delivers 638 teraflops, which is roughly comparable to, though slightly below, the compute power of an air-cooled Hopper H100 for BF16 teraflops.”

The Business Model of SambaNova
Jairath said that SambaNova is a full-stack company. “We handle everything from the chip to the APIs, basically everything in between.” He explained that back in 2020, they started selling chip systems.
“Our box was very much similar to what DGX boxes are from NVIDIA. Anybody can take it and then code and we still sell that. That’s a data scale product that we have,” he said.
Jairath explained that their current business model caters to enterprises that want a ChatGPT-like service but behind their own firewall. “If someone wants the entire stack—chip system, all the APIs, and the model—but behind their firewall, where they can train and run the model without sending data out, that’s the business we are in,” he said.
He said their goal is to offer enterprise AI solutions that allow customers to fine-tune and deploy models in the cloud. The company also provides an option for deploying these models securely behind the customer’s firewall.
Moreover, he explained that in the near future with agentic AI coming in, companies won’t just deploy one model, instead there will be multiple models working together, which different departments within the company will be fine-tuning.
“Enterprises will be running hundreds of these models. When they need to operate these many models, they can’t deploy a separate set of GPUs for each one, as the costs would grow exponentially,” concluded Jairath.
The post SambaNova’s 24TB Memory Powers 12T Parameters, Surpasses Cerebras and Groq in AI Scalability appeared first on AIM.