A purpose-built medical Large Language Model (LLM) developed by Jivi, an Indian healthcare AI startup co-founded by former BharatPe Chief Product Officer Ankur Jain and GV Sanjay Reddy, Chairman, Reddy Ventures, has ranked number 1 on the Open Medical LLM Leaderboard.
Jivi’s LLM, Jivi MedX, has beaten established LLMs, including OpenAI’s GPT-4 and Google’s Med-PaLM 2 with an average score of 91.65 across the leaderboard’s nine benchmark categories.
Hosted by leading AI platform Hugging Face, the University of Edinburgh, and Open Life Science AI, the leaderboard ranks medical-specific LLMs based on their performance in answering medical questions from exams and research.
The evaluation covers medical exams such as Indian medical entrance exams (AIIMS and NEET), US Medical License Exams (USMLE), and detailed assessments in clinical knowledge, medical genetics, and professional medicine, among others.
“Jivi is revolutionizing primary healthcare through generative AI, making top-quality care accessible 24/7 at a fraction of the cost. Our mission at Jivi is to harness artificial intelligence to enhance patient care. Our platform accelerates diagnostics and ensures higher accuracy, enabling timely and precise treatment for all,” said Ankur Jain, Co-founder and CEO, JIVI.
Jivi currently operates with a lean, 20-member team of physicians, surgeons, AI engineers, and data scientists. It is developing technology to transform accessibility, affordability, and quality of healthcare globally.
Jivi uses its large proprietary medical dataset consisting of millions of medical research papers, journals, clinical notes, and other sources to train its Jivi MedX LLM. This dataset is among the largest in the world. Jivi MedX was trained using an instruction fine-tuning algorithm called Odds Ratio Preference Optimisation (ORPO).
The post Jivi’s Medical LLM Beats OpenAI at the Open Medical LLM Leaderboard appeared first on AIM.
AI technologies are no longer a luxury for early adopters; they have become a requirement for executives who want to be at the forefront of their fields. These game-changing instruments are now smoothly incorporated into numerous well-known platforms, giving them superpowers that were previously exclusive to science fiction.
But can AI help us become more human at work, alter culture, and put strategies into action? AI deployment for organisational effectiveness will be the next phase for organisations.
Executive educator and coach Marshall Goldsmith is creating an AI-powered virtual avatar of himself as a one-of-a-kind endeavour to share his skills and preserve his legacy for years. MarshallBoT, an AI-powered virtual business coach is based on the GPT-3.5 from OpenAI
Speaking at AIM’s Media House Data Engineering Summit 2024, Goldsmith said, “This is a legacy project for me – I’m 74 years old, so this is a way of being present, even when physically I’m no longer around”.
But why a chatbot? “It can answer questions far better than me,” the 75-year-old says.
Known as one of the world’s leading business thinkers, Marshall Goldsmith has a large following of experts in the business world who are eager to learn from him. To better reach these people, Goldsmith is collaborating with Fractal to develop MarshallBoT. “I have been mentoring leaders for the past 47 years. I’ve been the coach of people like the president of the World Bank, head of Mayo Clinic and five CEOs of the year in the United States,” Goldsmith said.
Chatbots: The Future Of Coaching
MarshallBoT’s most recent version makes use of generative AI technology known as a large language model (LLM). Natural talks are made possible by LLMs’ contextual understanding, which also shows generalisation skills and lessens the need for rules. The speech component of MarshallBoT makes use of generative AI technologies to accurately mimic Marshall’s voice.
“I’ve authored or edited 52 books. In addition, I’ll be sharing insights from some of my friends, who include at least 25 of the top 50 business thinkers in the world. So I try to give everything away. It’s going to be available to everybody in the world. You can use it anytime, anyplace”, he said.
Integrating AI into Leadership Development
AI integration into leadership development is not just theoretical, but also practical, with specialised tools and platforms paving the way for creative training solutions. There is a great opportunity for AI-driven solutions because of this disconnect between traditional methods and the changing requirements of leadership roles.
Many programming tools are having a variety of effects. Platforms such as Centrical, for instance, employ AI to personalise learning sessions by modifying information to suit the preferences and pace of individual leaders. Butterfly.ai, for example, provides executives with real-time statistics and feedback. Mursion provides a virtual environment where leaders can interact in intricate, real-world scenarios with AI-driven avatars.
AI technologies will play a more important role in leadership development as they advance, posing both opportunities and problems. AI will probably become even more ingrained in leadership development programmes and decision-making procedures in the future.
AI is expected to play a bigger part in leadership development in the future, offering even more individualised and efficient training approaches but also posing new ethical and governance concerns.
The post Time To Harness The Power of AI Chatbots For Leadership Mastery appeared first on AIM.
Perplexity is a popular AI tool that grounds its responses in reliable sources from the web. Now, the AI search engine has launched a new feature that leverages its web-sourcing capabilities to generate entire articles from a simple prompt.
On Thursday, Perplexity unveiled its new Pages feature, which lets you generate a first draft of articles and reports for any topic that matches the expertise level of your audience.
All you have to do is ask a question and designate whether your audience comprises "anyone, beginners, or experts." Perplexity then searches the web in real time to pull the most relevant and recent information to generate a first draft.
Also: The best AI search engines of 2024: Google, Perplexity, and more
Once that first draft is generated, you can verify the information and approve the sources. If you disapprove of a source, you can remove it, and the section referencing that source will also be removed.
When you're done tweaking the sources, you can customize the Page's formatting, add images, and publish the final result. Perplexity says Pages could be useful for content creators, educators, students, small businesses, hobbyists, researchers, and more. I tried the feature myself to see how it works.
Also: How to use ChatGPT to build your resume
If you have read my other articles on AI tools, such as my roundups on AI search engines or AI image generators, you will know my default test typically involves Yorkshire Terriers. Consequently, I prompted Perplexity to create a page about "Yorkshire Terriers: Why are they the best pets?" and made the audience "anyone."
In under a minute, Perplexity created an entire page with all the elements an article or webpage would need, including a headline, an introduction, three subsections, and footnotes next to every sentence, as seen in the screenshot below.
I could customize every element on the page, including a section's position, text, photos, subheadlines, tone, and more. I could also drop in external media, which could be useful if you are a student or an educator and want to add class materials. I decided to try adding a new section titled "Yorkies' Playfulness" to see if Perplexity would automatically generate the content for me — and it did.
I then placed the section on Yorkies' medical conditions at the bottom, swapping it for the newly created section about Yorkies' playful, energetic nature, in order to start the article with a more positive tone. Once I was done, I published the page, which you can view here.
Testing the feature eased my concerns about editorial integrity. The tool clarified that a human author did not write the content. Instead, the byline reads "curated by" the user who prompted Perplexity to create the Page.
Published Pages lead you back to Perplexity's website, making it obvious that the AI tool created the content. Yes, bad actors who want to plagiarize could still copy and paste the content, but this is still better than most AI chatbots that have no preventions.
Also: OpenAI is training GPT-4's successor. Here are 3 big upgrades to expect from GPT-5
The published version of the Page includes footnotes with sources, making it a helpful resource that can be shared easily with others. I can see how educators and students could use the tool to generate study guides or classroom materials.
The new feature is rolling out to users now. To access it, sign in, go to your Library tab, and click on "Create a Page." You can also chat with Perplexity as you would normally, and convert that thread into a Page by clicking on the "convert to Page button" in the upper right-hand corner.
Recently, Microsoft owned LinkedIn removed a post where Ola co-founder and CEO Bhavish Aggarwal criticised the use of gender-neutral pronouns like they/them, calling it a “pronoun illness” and expressing hope that it wouldn’t spread to India.
Believing that India should avoid blindly following “Western trends”, he moved his workload from Microsoft Azure to its in-house cloud Krutrim AI and advocated for developing an independent tech ecosystem to avoid control by Western big tech monopolies. We reached out to Ola for comments on its diversity initiatives but the team did not respond.
Aggarwal’s post touched a nerve, throwing light on the ongoing struggle between traditional norms and the evolving understanding of gender identity. His comments were seen by many as dismissive of the importance of pronouns in acknowledging and respecting individuals’ gender identities for fostering better workplace inclusivity.
This incident is not isolated but part of a larger, global conversation about inclusivity and respect in the workplace. This brings us to the important question: Are preferred pronouns still a strong taboo in Indian corporate environments?
Rainbow Washing or Honest Intentions?
We are just one day away from the start of June, which is globally recognised as Pride Month. During this period, corporations ramp up their initiatives, often in vibrant and colourful ways.
Many companies will go to great lengths to display rainbow-themed logos and messages of support for the LGBTQIA+ community. However, once the month ends, things typically return to normal. Ola is an example of a company that quickly celebrated Pride Month last June. However, one year later, the situation appears to have changed significantly.
While these efforts are generally well-intentioned, for many, they amount to little more than marketing tactics.
“I am very sceptical (of such initiatives). A lot of tech companies, even those with diversity initiatives, limit these efforts to certain seasons. Diversity initiatives are often seasonal, which is why leaders or even entry-level employees may find pronouns or diversity initiatives not impactful and long-lasting,” Sujoy Das told AIM. Das stands at the intersection of being a gay man with a disability and is an active leader in the DE&I space.
This sporadic approach dilutes the effectiveness of such initiatives and fails to reach the wider audience it aims to support. Pronouns, gender inclusivity, and intersectionality are crucial topics that need ongoing attention and commitment, not just seasonal acknowledgement. The resistance to change is often rooted in traditional views and a lack of understanding.
Read more: The Struggles and Triumphs of Trans Inclusion in Indian Tech
The Importance of Pronouns
Some argue that the emphasis on pronouns is a Western import, but this perspective is increasingly seen as outdated. The concept of fluid gender identities is not new to Indian culture. The binary concept of gender, often considered a Western imposition, overlooks this rich history.
“The binary concept of masculine and feminine was also a Western adoption,” explained AnitaB.org MD Shreya Krishnan in an interaction with AIM. The world is changing, and language must evolve to acknowledge these identities.
Using the correct pronouns is a simple yet powerful way to show respect and acknowledgement.
“People who identify as queer are an integral part of our society. Making them feel inclusive is basic human respect,” Omega Healthcare HR vice president Lalitha M Shetty told AIM.
In India, the conversation around pronouns is further complicated by cultural and historical contexts. Traditionally, many Indian languages, such as Bengali, have always had gender-neutral pronouns. However, this linguistic neutrality does not automatically translate to a more inclusive culture.
“There are a lot of cultural nuances around discrimination that need to be unlearned and relearned. This is not a cultural debate; it’s fundamentally about gender identity and what they choose. Pronouns are like names — how you want your name to be pronounced is how you want to be addressed,” Krishnan added.
To include trans and non-binary employees, it is crucial to use their preferred pronouns. Typically, people use binary pronouns (he/him, she/her) without much thought. However, these don’t cover the needs of non-binary and gender non-conforming individuals. They may prefer gender-neutral pronouns like they/them.
“As leaders, we should be aware and conscious of what we are saying before we speak,” emphasised Krishnan. “They must set an example, creating environments where all employees feel seen and respected. This is not just about compliance but about fostering a truly inclusive workplace.”
So considering inclusive language practices as a “Western import” can challenge traditional norms. However, framing these practices as part of a broader commitment to global diversity and inclusion standards can enhance India’s reputation on the international stage.
Is there a Solution?
To address these issues, we must move beyond seasonal efforts and make diversity awareness a regular, integral part of the corporate culture like conducting sensitisation workshops and creating a continuous dialogue about inclusivity.
Das suggested that for those targeted by such biases, it is essential to acknowledge the reality of these prejudices.
“Biases are beyond our control, and we should not try to control them because they are at a societal level. It is like living with a non-inclusive neighbour. It’s important to talk to people you trust and build a safe ecosystem around you,” commented Das, talking about the sheer resilience the queer community is already known for.
Corporate leaders have a make-or-break role to play in normalising this culture.
“Embracing inclusive language aligns with global best practices and demonstrates a proactive approach to creating a respectful and equitable workplace
“Using correct pronouns is a fundamental aspect of acknowledging and respecting individual identities. Dismissing this practice undermines efforts to create an inclusive workplace, and can perpetuate stigma and discrimination against transgender and non-binary individuals,” Shetty told AIM.
By fostering regular awareness and inclusivity, we can create a more accepting environment for everyone in the tech industry. This involves not only implementing policies but also ensuring they are deeply embedded in the company’s culture and daily practices. Only then can we hope to see a meaningful and lasting change in the tech ecosystem.
Read more: Going Beyond Pride Month in Corporate Culture
The post Breaking the Taboo Around Pronouns in Indian Tech appeared first on AIM.
Since OpenAI/GPT launched in November 2022, many things have happened. Competitors and new applications are born every month, some raising considerable funding. Search is becoming hot again, this time powered by RAG and LLMs rather than PageRank. It remains to be seen who will achieve profitability on a large scale. Costs are dramatically decreasing, and protagonists are fighting to deliver better quality with faster training speed and easier fine-tuning. While small or specialized LLMs start to emerge, the general trend is towards more GPU, more weights, more tokens. Sometimes based on questionable input, such as Reddit, in an attempt to gather more rather than better sources. But these days, not all LLMs use transformers, and energy-efficient implementations are gaining popularity, with an attempt to lower GPU usage, and thus costs. Yet all but one still rely on Blackbox neural networks.
Great evaluation metrics remain elusive and will remain so probably forever: in the end, LLMs, just like clustering, are part of unsupervised learning. Two users looking at a non-trivial dataset will never agree on what the “true” underlying cluster structure is. Because “true” is meaningless in this context. The same applies to LLMs. With some exceptions: when used for predictive analytics, that is, supervised learning, it is possible to tell which LLM is best in absolute terms (to some extent; it also depends on the dataset).
From big to simple LLMs, back to big ones
The first LLMs were very big, monolithic systems. Now you see many simple LLMs to deal with specialized content or applications, such as corporate corpus. The benefit is faster training, easier fine-tuning, and reduced risk of hallucinations. But the trend could change, moving back to big LLMs. For instance, my xLLM architecture consists of small, specialized sub-LLMs, each one focusing on a top category. If you bundle 2000 of them together, you cover the entire human knowledge. The whole system, sometimes called mixture of experts, is managed with an LLM router.
LLM routers
The word multi-agent system is sometimes used instead, although not with the exact same meaning. An LLM router is a top layer above the sub-LLMs, that guides the user to the correct sub-LLMs relevant to his prompt. It can be explicit to the user (asking him which sub-LLM to choose), or transparent (automatically performed), or semi-transparent. For instance, a user looking for “gradient descent” using the statistical science sub-LLM, may find very little: the relevant information is in the calculus sub-LLM. The LLM router should take care of this problem.
Evaluation, faster fine-tuning and self-tuning
Fine-tuning an LLM on part of the system, rather than the whole, can speed up the process tremendously. With xLLM, you can fine-tune hyperparameters locally on a sub-LLM (fast), or across all sub-LLMs at once (slow). Hyperparameters can be local or global. In the case of xLLM, they are intuitive, as the system is based on explainable AI. In standard LLMs, LoRA, an abbreviation for Low-Rank Adaptation, achieves a similar goal.
Self-tuning works as follows: collect the favorite hyperparameters chosen by the users and build a default hyperparameter set based on these choices. It also allows the user to work with customized hyperparameters, with two users getting different answers to the same prompt. Make this process even easier by returning a relevancy score to each item listed in the answer (URLs, related concepts, definitions, references, examples, and so on).
Regarding evaluation, I proceed as follows. Reconstruct the taxonomy attached to the corpus: for each web page, assign a category, and compare it to the real category embedded in the corpus. I worked with Wolfram, Wikipedia, and corporate corpus: all have a very similar structure with taxonomy and related items; this structure can be retrieved while crawling.
Finally, whenever possible, use the evaluation metric as your loss function in the underlying gradient descent algorithm — typically a deep neural network. Loss functions currently in use are poor proxies to model quality, so why not use the evaluation metric instead? This is hard to do because you need a loss function that can be updated with atomic changes such as weight update or neuron activation, billions of times during training. My workaround is to start with a rough approximation of the evaluation metric and refine it over time until it converges to the desired metric. The result is an adaptive loss function. It also prevents you from getting stuck in a local minimum.
Search, clustering and predictions
At the beginning, LLM for search was looked down. Now that this is what most corporate clients are looking for, and since it can do a far better job than Google search or all search boxes found on company websites, it starts to get a lot of attention. Great search on your website leads to more sales. Besides search, there are plenty of other applications: code generation, clustering, and predictive analytics based on text only.
Knowledge graphs and other improvements
There is a lot of talk about long-range context and knowledge graphs, built as a top layer to add more context to LLMs. In my xLLM, the knowledge graph is actually the bottom layer and retrieved from the corpus while browsing. If none is found or if quality is poor, I import one from an external source, calling it augmented knowledge graph. I also built some from scratch using synonyms, indexes, glossaries, and books. It may consist of a taxonomy and related concepts. In any case, it brings the long-range context missing in the first LLM implementations.
I also introduced longer tokens consisting of multiple tokens, such as “data~science”. I call them multi-tokens. Meta also uses them. Finally, I use contextual tokens, denoted as (say) “data^science”. It means that the two words “data” and “science” are found in a same paragraph, but not adjacent to each other. Special care is needed to avoid an explosion in the number of tokens. In addition to the corpus itself, I leverage user prompts as augmented data to enrich the input data. The most frequent embeddings are stored in a cache for faster retrieval in the backend tables. Then, variable-length embeddings further increase the speed. While vector and graph databases are popular to store embeddings, in my case I use nested hashes, that is, an hash (or key-value database) where the value is an hash itself. It is very efficient to handle sparsity.
Cosine distance and dot product, to compare embeddings, is receiving increased criticism. There are alternative metrics, such as pointwise mutual information (PMI).
Local, secure, enterprise versions
There is more and more interest in local, secure implementations to serve corporate clients. Afterall, that’s where the money is. For these clients, hallucinations are a liability. Low latency, easy fine-tuning, and explainable parameters are other important criteria for them. Thus, their interest in my open source xLLM that solves all these problems.
Reference
I illustrate all the concepts discussed here in my new book “State of the Art in GenAI & LLMs — Creative Projects, with Solutions”, available here. For a high-level presentation, see my PowerPoint presentation here on Google drive (easy to view), or on GitHub, here. Both the book and the presentation focus on xLLM.
Author
Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
Generative AI has proven to be an impressive tool for industries in generating insights from a large volume of data. Parmjeet Virdi Director Data Analytics at Publicis Sapient, reveals while speaking at AIM Media House’s Data Engineering Summit (DES) 2024 that Publicis Sapient has been leveraging generative AI to derive insights from customers data and helping them make better business decisions.
To make her point, Virdi referred to an incident of an analyst reviewing a lengthy report by Harvard Business Review. She said an analyst overlooked crucial details in a lengthy report, missing the competitor’s expansion strategy.
However,AI, unlike humans, connected scattered information, revealing the competitor’s plan to penetrate a low-cost market by leveraging specific product manufacturing and later market expansion, enhancing analytical insight.
The initial disruption caused by the internet paved the way for subsequent technological advancements, including the evolution of web, mobile, IoT, and connected systems. So when these technologies are evolving, at the same time, the customers are also evolving,” Virdi said.
Along with Aashima Kumar, senior manager, data analytics at Publicis Sapient, discusses how Publicis Sapient has harnessed the power of generative AI, Machine Learning models, and advanced Data Analytics techniques to unearth hidden patterns, trends, correlations, and influential features within extensive data repositories.
Deriving insights from data
Moreover, Kumar pointed out that Publicis Sapient built a solution for a large automobile company that helped them drive sales by better understanding customer data.
“So when any potential customer comes to their website or mobile app, they see a very fancy-looking configurator that gives the customer the option of selecting the model, grade, color, engine, upholstery, and accessories, plus all the subscriptions for the connected cars.
“Now that so much of data coming out of configurator and talking about this data, it actually has the power for us to understand the needs of the customer, at the same time provide back to the business a way that they can understand what kind of combinations are more profitable for them and in more demand. “We utilised conjoint analysis and Monte Carlo Markov analysis to identify coefficients for customer choices, generating insights visualised through a utility dashboard,” Kumar said.
This internal tool aided product planning and experience teams by revealing utility scores, indicating component attractiveness and profitability trade-offs, and enhancing decision-making across multiple business levels, including product combinations and profitability assessment.
Leveraging generative AI
Marriot, one of the world’s largest hotel brands, had a traditional search engine, Kumar pointed out. Marriott’s traditional search process needs users to input destinations, dates, and preferences, among other things. However, this method leaves much to be desired in aiding decision-making, offering limited assistance.
“We transitioned their traditional search to a generative AI-powered search, enabling users to input specific needs in natural language rather than filters. The generative AI model then extracted these queries into attributes and identified relevant accommodations.
“We scaled it to the next level to make it a conversational AI. Using the same power that we were able to engage with Gen AI, we made sure that it’s not just giving you the options of what you’re looking for. But why can’t we recommend you more options and then you make the choices that you want,” Kumar said.
The post Unleashing Intelligence: Leveraging AI to derive Insights at Scale appeared first on AIM.
I've been playing with artificial intelligence (AI) since Lisp was the state-of-the-art (that is to say, a while). Lately, like everyone else, I've been looking at AI a lot more closely. While it's nifty, I'm not that impressed — but not because OpenAI ripped off Scarlett Johansson or Google's AI Overviews recommend I use glue to help cheese stick to my pizza. It's that even when I tell the chatbot of the day to summarize an Otter.ai transcription of a meeting, it gets things wrong.
Also: How to avoid AI Overviews in Google Search: Three easy ways
That's why I treat the results of my AI queries very, very cautiously. That said, I've finally found an AI chatbot whose work I can easily double-check to make sure it's in the ballpark of being right: Perplexity.
That may not sound like much, but it's a critical feature. Because AI chatbots are trained on information scraped from the web, they are all capable of hallucinating or spouting errant nonsense. For instance, Google pulled the glue-in-pizza-sauce suggestion from a sarcastic Reddit post.
Perplexity also hallucinates, but it values data from trustworthy sources. Here's what it can do, and why it's become my favorite AI chatbot.
Overall, Perplexity AI is my pick over other chatbots because it's excellent at detailed research, but it can also translate from one language to another, write document summaries, and answer both simple and complex questions. Plus, you can use it to create poems, code, email messages, and articles.
It doesn't do everything, though. Unlike other chatbots, such as Microsoft Copilot or ChatGPT with DALL-E 3, Perplexity does not include free AI image creation functionality. You can subscribe to Perplexity Pro — $20 per month or $200 per year — for basic AI-image creation tools, but they're not equal to the best AI image generators.
That said, if you need reliable, in-depth answers to your queries, it's my top choice. It may not get all the press that Google, Meta, Microsoft, or OpenAI have, but the results speak for themselves.
“Everyone uses data in the form of analytics dashboards, storage or transfer, but how do you look at data as a product? How can you benefit from it? How do you monetise it?” asked PayU data and ML engineering director Praveen Singh, during AIM’s Data Engineering Summit (DES) 2024.
This is particularly interesting, considering how issues due to poor datasets have become increasingly prevalent, for example, Google’s use of Reddit API leading to some strange responses.
Singh spoke about data as a product, or DaaP for short. “According to IBM, data as a product is an approach in data management and analytics, where datasets are treated as standalone products designed, built and maintained with the end user in mind,” he explained.
Basically looking at data not just as a tool for analytics, but looking at the datasets that come from these platforms as a product in and of itself.
“Traditional data management focuses on storage, retrieval, and getting value from the data, with its own lifecycle and infrastructure.
“Whereas if you see data as a product, the benefit is that you could also ensure the overall lifecycle including the data quality, accessibility and usability, leading to better decision making and overall strategic advantage,” he said.
In this regard, Singh explained several ways to refine datasets, improving both accessibility and interpretability. This, he said, would help make datasets more reliable for the consumer.
This is where AI and machine learning come in. “At each stage of the DaaP foundation, the idea at the next level is to apply GenAI and LLMs so that you can get improvements at each stage,” he said.
This means that GenAI can be applied to the data at the search, discovery and analytics stage. Further, Singh said that the aim for software management and data analytics should always be to move towards the DaaP methodology. This, he emphasised, can help provide a more holistic product as well as more benefits for the end user.
Some of the important aspects he mentioned for DaaP was that the data should be of good quality, in terms of being complete up-to-date, and reliable. Another important aspect is the usability of the data, meaning that the data should be accessible, understandable and usable by the intended stakeholders.
“If the source’s data quality is not fit or standardised, I will never be able to rely upon the overall metrics that I’m presenting,” he said.
The post Why is Data as a Product (DaaP) a Vital Pivot for Businesses? appeared first on AIM.
A little over two weeks ago, OpenAI announced it would supercharge the free version of ChatGPT, giving users access to features previously limited to ChatGPT Plus subscribers at no cost. The company said it would be rolling out the upgrade to users in the coming weeks, and the wait is finally over.
On Wednesday, OpenAI shared in an X post that all free ChatGPT users can now access the features announced at the Spring Updates event, including web browsing, vision, data analysis, file uploads, and GPTs.
The browse feature allows ChatGPT to pull answers from the web, which means you can ask questions on current events, expect that the information in ChatGPT's answers is up-to-date, and even use the provided links to verify the accuracy of the response.
Also: ChatGPT vs. ChatGPT Plus: Is a paid subscription still worth it?
Browse turns on automatically when you ask for a prompt that requires access to the web. For example, using my free ChatGPT account, I asked, "What is the weather today in NYC?" As you can see below, ChatGPT browsed the web to generate an answer.
Vision lets you share images with the chatbot and get more advanced insights. For example, OpenAI shared that you would be able to "take a picture of a menu in a different language and talk to GPT-4o to translate it, learn about the food's history and significance, and get recommendations."
As the name implies, the data analysis feature means free users can now use ChatGPT to get insights, create interactive charts, and visualize data, all features previously reserved for ChatGPT Plus subscribers. With file uploads, you can upload spreadsheets, documents, presentations, research papers, PDFs, and more, and use ChatGPT to analyze, interpret, transform, and extract information from them.
Lastly, free users can now access GPTs via the GPT store, meaning you can try chatbots customized to suit a specific purpose or task. For example, AllTrails GPT can help you find trails for your next outdoor adventure, and the Canva GPT can help you design projects.
The addition of all these free features makes ChatGPT Plus — the chatbot's $20 monthly premium subscription option — a bit less enticing. There are still some perks to the subscription, however, which you can read more about here.
In Proofpoint’s 2024 Voice of the CISO report, the cybersecurity company found that CISOs are dealing with people-centric threats more than ever. Plus, cybersecurity budgets often don’t change, and AI can help and hurt CISOs’ efforts.
Regarding the specific threat risks, 41% of the CISOs mostly fear ransomware attacks, followed by malware (38%), email fraud (36%), cloud account compromise (34%), insider threat (30%) and distributed denial of service (30%) attacks.
Biggest threat risks as perceived by CISOs for the next 12 months. Image: Proofpoint
For this report, the research firm Censuswide surveyed 1,600 CISOs from organizations of 1,000 employees or more across different industries in 16 countries.
CISOs’ main people-centric security problems
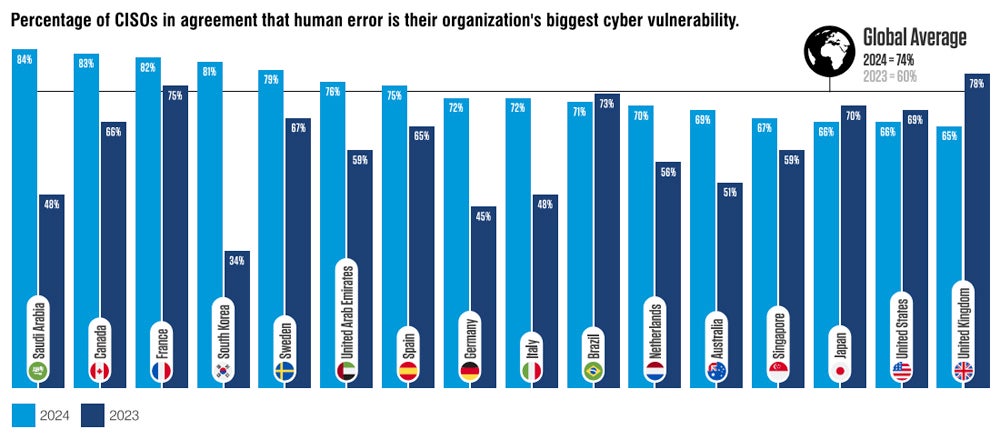
According to the survey, more CISOs than ever believe human error is the biggest vulnerability for their organizations; 74% of the CISOs feel this way, up from 60% in 2023.
Percentage of CISOs by country who consider human error as their organization’s biggest vulnerability. Image: Proofpoint
In addition, 80% of CISOs see human risk as a key cybersecurity concern over the next two years, up from 63% in 2023. This is where AI comes into play, as 87% of CISOs are looking to deploy AI-powered technologies to fight human vulnerability and block human-centric cyber threats.
Concerning threats also include malicious insiders (36%) and compromised insiders (33%).
DOWNLOAD: Security Awareness and Training Policy from TechRepublic Premium
Data loss events and threat mitigation
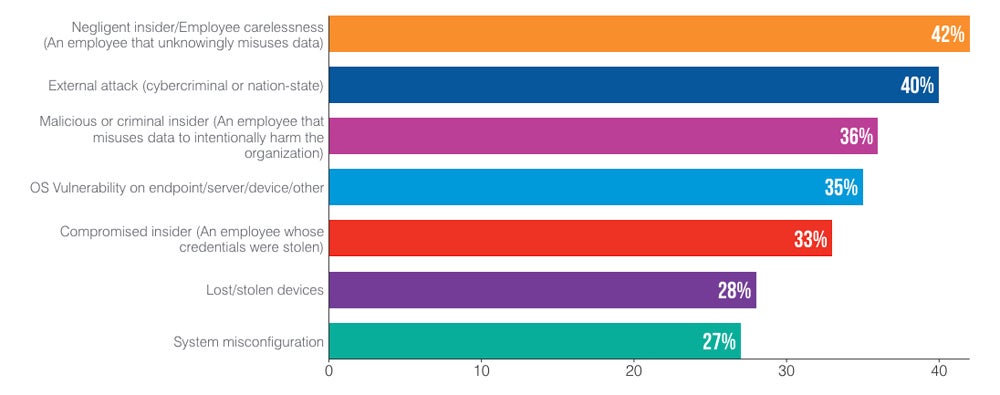
Negligent or careless employees are seen as the biggest cause of data loss events for CISOs (42%) over external attacks (40%). According to the Proofpoint report, 73% of CISOs added their data loss events were caused by employees leaving their organization.
Cause of data loss events, as reported by CISOs who dealt with a material loss of sensitive information in the past 12 months. Image: Proofpoint
The consequences of these data loss events are mostly financial loss (43%), post-attack recovery costs (41%) and loss of critical data (40%).
SEE: CISOs in Australia Urged to Take a Closer Look at Data Breach Risks
To fight the data loss problem, many CISOs educate their employees about computer security best practices (53%), use cloud security solutions (52%), deploy data loss prevention technology (51%), endpoint security (49%), email security (48%) or isolation technology (42%).
This adoption of DLP has surged from 35% to 51% in a year, with the result being 81% of CISOs believing their data is well protected.
An increasing number of cybersecurity threats
Proofpoint stated the attack surface of organizations has never been larger for various reasons, including hybrid work has become a standard, while reliance on cloud technology has grown. Also, employees have become increasingly mobile, often taking data with them when changing jobs.
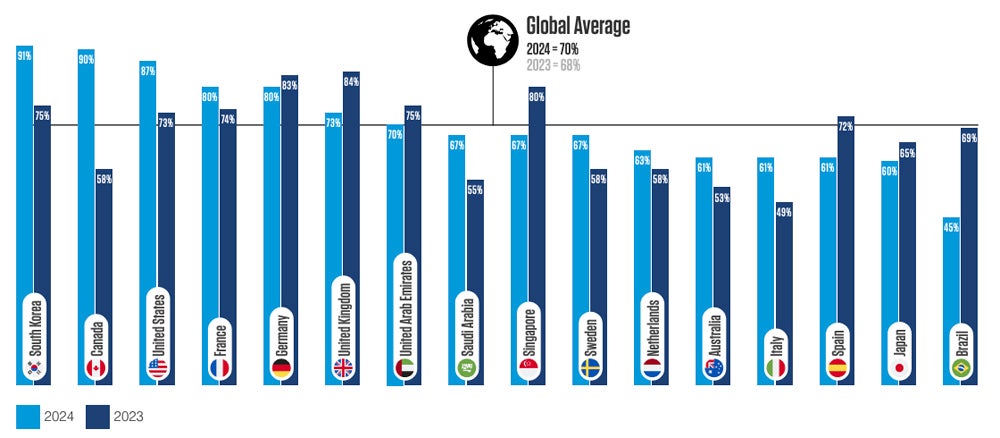
Seventy percent of CISOs feel their organization will probably face a material cyberattack over the next 12 months, with 31% thinking it is very likely. The CISOs from the U.S., Canada and South Korea are the most concerned about experiencing such an attack.
Percentage of CISOs who feel their organization is at risk of a material cyberattack in the next 12 months. Image: Proofpoint
Artificial intelligence helps CISOs but also cybercriminals
As noted earlier, most CISOs surveyed are looking to deploy AI-powered technologies to help them protect their organization, even if they are still at an early stage. Proofpoint wrote, “Even in these early stages, we can already connect the dots between external threats, sensitive content and anomalous behaviors or activity. That’s something that has not been possible at the same speed and scale with human moderation or traditional analysis.”
SEE: Google Cloud’s Nick Godfrey Talks Security, Budget and AI for CISOs
Yet AI also benefits cybercriminals, rendering their attacks easier to scale, and techniques that were only deployed by nation-state threat actors or well-funded cybercriminal groups are now available for lower-skilled attackers. More than half of the CISOs (54%) think AI poses some form of security risk to their organization.
Pressure about cybersecurity budgets
The economy has had an impact on organizations, according to 59% of the surveyed CISOs. Plus, CISOs are pressured to do more or at least the same for less, with security budgets remaining flat at best. Forty-eight percent of the CISOs have been requested to cut staff, delay backfills or reduce spending.
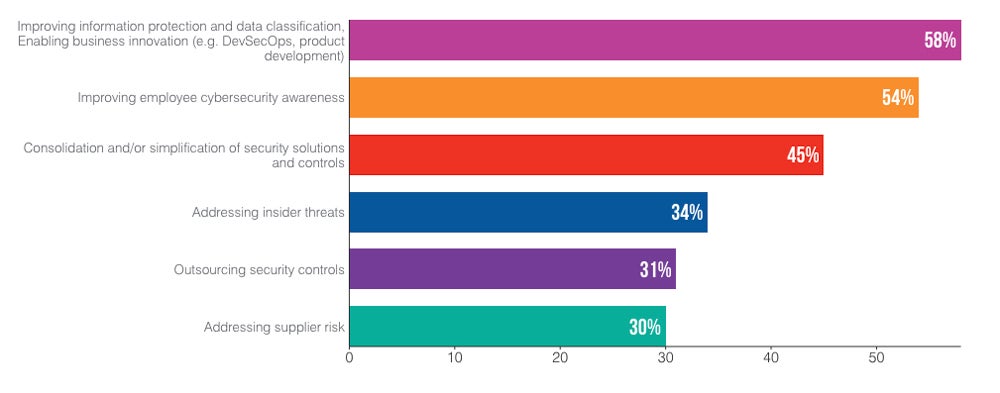
CISOs’ top priority according to their budget is now improving information protection and enabling greater business innovation (58%) slightly ahead of improving employee cybersecurity awareness (54%).
Top priorities for organizations’ IT teams over the next two years. Image: Proofpoint
CISOs’ concerns include burnout and insurance
In addition to the budget-related stress, 66% of CISOs feel expectations on them are unrealistic. This number is continuously increasing (61% for 2023), as they also feel their concerns are unanswered. This all results in low job satisfaction, with 53% of the CISOs experiencing or witnessing burnout in the past year.
Sixty-six percent of CISOs are also concerned with personal, financial and legal liability in their role, fearing a lack of protection in their job. And, 72% of CISOs would not join an organization that would not offer them directors and officers insurance or similar protection in the event of a successful cyberattack.
A bright spot: CISOs’ relationships with board members
Eighty-four percent of CISOs reported they have eye-to-eye contacts with their board members, while only 51% reported such contact in 2022 and 62% in 2023. Those contacts have led to a greater understanding from the board members.
Disclosure: I work for Trend Micro, but the views expressed in this article are mine.