Context managers in Python let you work more efficiently with resources—facilitating setup and teardown of resources even if there are errors when working with the resources. In the tutorial on writing efficient Python code, I covered what context managers are and why they’re helpful. And in 3 Interesting Uses of Python's Context Managers, I went over the use of context managers in managing subprocesses, database connections, and more.
In this tutorial, you’ll learn how to create your own custom context managers. We’ll review how context manages work and then look at the different ways you can write your own. Let's get started.
What Are Context Managers in Python?
Context managers in Python are objects that enable the management of resources such as file operations, database connections, or network sockets within a controlled block of code. They ensure that resources are properly initialized before the block of code executes and automatically cleaned up afterward, regardless of whether the code block completes normally or raises an exception.
In general, context managers in Python have the following two special methods: __enter__() and __exit__(). These methods define the behavior of the context manager when entering and exiting a context.
How Do Context Managers Work?
When working with resources in Python, you have to consider setting up the resource, anticipate errors, implement exception handling, and finally free up the resource. To do this, you’ll probably use a try-except-finally block like so:
try: # Setting up the resource # Working with the resource except ErrorType: # Handle exceptions finally: # Free up the resource
Essentially, we try provisioning and working with the resource, except for any errors that may arise during the process, and finally free up the resource. The finally block is always executed regardless of whether the operation succeeds or not. But with context managers and the with statement, you can have reusable try-except-finally blocks.
Now let’s go over how context managers work.
Enter Phase (__enter__() method): When a with statement is encountered, the __enter__() method of the context manager is invoked. This method is responsible for initializing and setting up the resource such as opening a file, establishing a database connection, and the like. The value returned by __enter__() (if any) is made available to the context block after the `as` keyword.
Execute the Block of Code: Once the resource is set up (after __enter__() is executed), the code block associated with the with statement is executed. This is the operation you want to perform on the resource.
Exit Phase (__exit__() method): After the code block completes execution—either normally or due to an exception—the __exit__() method of the context manager is called. The __exit__() method handles cleanup tasks, such as closing the resources. If an exception occurs within the code block, information about the exception (type, value, traceback) is passed to __exit__() for error handling.
To sum up:
Context managers provide a way to manage resources efficiently by ensuring that resources are properly initialized and cleaned up.
We use the with statement to define a context where resources are managed.
The __enter__() method initializes the resource, and the __exit__() method cleans up the resource after the context block completes.
Now that we know how context managers work, let’s proceed to write a custom context manager for handling database connections.
Creating Custom Context Managers in Python
You can write your own context managers in Python using one of the following two methods:
Writing a class with __enter__() and __exit__() methods.
Using the contextlib module which provides the contextmanager decorator to write a context manager using generator functions.
1. Writing a Class with __enter__() and __exit__() Methods
You can define a class that implements the two special methods: __enter__() and __exit__() that control resource setup and teardown respectively. Here we write a ConnectionManager class that establishes a connection to an SQLite database and closes the database connection:
import sqlite3 from typing import Optional # Writing a context manager class class ConnectionManager: def __init__(self, db_name: str): self.db_name = db_name self.conn: Optional[sqlite3.Connection] = None def __enter__(self): self.conn = sqlite3.connect(self.db_name) return self.conn def __exit__(self, exc_type, exc_value, traceback): if self.conn: self.conn.close()
Let’s break down how the ConnectionManager works:
The __enter__() method is called when the execution enters the context of the with statement. It is responsible for setting up the context, in this case, connecting to a database. It returns the resource that needs to be managed: the database connection. Note that we’ve used the Optional type from the typing module for the connection object conn. We use Optional when the value can be one of two types: here a valid connection object or None.
The __exit__() method: It's called when the execution leaves the context of the with statement. It handles the cleanup action of closing the connection. The parameters exc_type, exc_value, and traceback are for handling exceptions within the `with` block. These can be used to determine whether the context was exited due to an exception.
Now let’s use the ConnectionManager in the with statement. We do the following:
Try to connect to the database
Create a cursor to run queries
Create a table and insert records
Query the database table and retrieve the results of the query
db_name = "library.db" # Using ConnectionManager context manager directly with ConnectionManager(db_name) as conn: cursor = conn.cursor() # Create a books table if it doesn't exist cursor.execute(""" CREATE TABLE IF NOT EXISTS books ( id INTEGER PRIMARY KEY, title TEXT, author TEXT, publication_year INTEGER ) """) # Insert sample book records books_data = [ ("The Great Gatsby", "F. Scott Fitzgerald", 1925), ("To Kill a Mockingbird", "Harper Lee", 1960), ("1984", "George Orwell", 1949), ("Pride and Prejudice", "Jane Austen", 1813) ] cursor.executemany("INSERT INTO books (title, author, publication_year) VALUES (?, ?, ?)", books_data) conn.commit() # Retrieve and print all book records cursor.execute("SELECT * FROM books") records = cursor.fetchall() print("Library Catalog:") for record in records: book_id, title, author, publication_year = record print(f"Book ID: {book_id}, Title: {title}, Author: {author}, Year: {publication_year}") cursor.close()
Running the above code should give you the following output:
Output >>> Library Catalog: Book ID: 1, Title: The Great Gatsby, Author: F. Scott Fitzgerald, Year: 1925 Book ID: 2, Title: To Kill a Mockingbird, Author: Harper Lee, Year: 1960 Book ID: 3, Title: 1984, Author: George Orwell, Year: 1949 Book ID: 4, Title: Pride and Prejudice, Author: Jane Austen, Year: 1813
2. Using the @contextmanager Decorator From contextlib
The contextlib module provides the @contextmanager decorator which can be used to define a generator function as a context manager. Here's how we do it for the database connection example:
# Writing a generator function with the `@contextmanager` decorator import sqlite3 from contextlib import contextmanager @contextmanager def database_connection(db_name: str): conn = sqlite3.connect(db_name) try: yield conn # Provide the connection to the 'with' block finally: conn.close() # Close the connection upon exiting the 'with' block
Here’s how the database_connection function works:
The database_connection function first establishes a connection which the yield statement then provisions the connection to the block of code in the with statement block. Note that because yield itself is not immune to exceptions, we wrap it in a try block.
The finally block ensures that the connection is always closed, whether an exception was raised or not, ensuring there are no resource leaks.
Like we did previously, let’s use this in a with statement:
db_name = "library.db" # Using database_connection context manager directly with database_connection(db_name) as conn: cursor = conn.cursor() # Insert a set of book records more_books_data = [ ("The Catcher in the Rye", "J.D. Salinger", 1951), ("To the Lighthouse", "Virginia Woolf", 1927), ("Dune", "Frank Herbert", 1965), ("Slaughterhouse-Five", "Kurt Vonnegut", 1969) ] cursor.executemany("INSERT INTO books (title, author, publication_year) VALUES (?, ?, ?)", more_books_data) conn.commit() # Retrieve and print all book records cursor.execute("SELECT * FROM books") records = cursor.fetchall() print("Updated Library Catalog:") for record in records: book_id, title, author, publication_year = record print(f"Book ID: {book_id}, Title: {title}, Author: {author}, Year: {publication_year}") cursor.close()
We connect to the database, insert some more records, query the db, and fetch the results of the query. Here’s the output:
Output >>> Updated Library Catalog: Book ID: 1, Title: The Great Gatsby, Author: F. Scott Fitzgerald, Year: 1925 Book ID: 2, Title: To Kill a Mockingbird, Author: Harper Lee, Year: 1960 Book ID: 3, Title: 1984, Author: George Orwell, Year: 1949 Book ID: 4, Title: Pride and Prejudice, Author: Jane Austen, Year: 1813 Book ID: 5, Title: The Catcher in the Rye, Author: J.D. Salinger, Year: 1951 Book ID: 6, Title: To the Lighthouse, Author: Virginia Woolf, Year: 1927 Book ID: 7, Title: Dune, Author: Frank Herbert, Year: 1965 Book ID: 8, Title: Slaughterhouse-Five, Author: Kurt Vonnegut, Year: 1969
Note that we open and close the cursor object. So you can also use the cursor object in a with statement. I suggest trying that as a quick exercise!
Wrapping Up
And that’s a wrap. I hope you learned how to create your own custom context managers. We looked at two approaches: using a class with __enter__() and __exit()__ methods and using a generator function decorated with the @contextmanager decorator.
It’s quite easy to see that you get the following advantages when using a context manager:
Setup and teardown of resources are automatically managed, minimizing resource leaks.
The code is cleaner and easier to maintain.
Cleaner exception handling when working with resources.
As always, you can find the code on GitHub. Keep coding!
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.
More On This Topic
3 Interesting Uses of Python's Context Managers
Context, Consistency, And Collaboration Are Essential For Data…
Sentiment Analysis API vs Custom Text Classification: Which one to choose?
Introducing OpenChat: The Free & Simple Platform for Building…
Tailor ChatGPT to Fit Your Needs with Custom Instructions
Qualities Hiring Managers Are Looking For in Data Scientists
With the National Institute of Standards and Technology (NIST) set to publish the first Post Quantum Cryptography (PQC) Standards in a few weeks, attention is shifting to how to put the new quantum-resistant algorithms into practice. Indeed, the number of companies with practices to help others implement PQC is mushrooming and contains familiar (IBM, Deloitte, et al.) and unfamiliar names (QuSecure, SandboxAQ, etc.).
The Migration to Post-Quantum Cryptography project, being run out of NIST’s National Cybersecurity Center of Excellence (NCCoE), is running at full-tilt and includes on the order of 40 commercial participants.
In its own words, “The project will engage industry in demonstrating use of automated discovery tools to identify all instances of public-key algorithm use in an example network infrastructure’s computer and communications hardware, operating systems, application programs, communications protocols, key infrastructures, and access control mechanisms. The algorithm employed and its purpose would be identified for each affected infrastructure component.”
Dustin Moody, NIST
Getting to that goal remains a WIP that started with NIST’s PQC program in 2016. NIST scientist Dustin Moody leads the PQC project and talked with HPCwire about the need to take post quantum cryptography seriously now, not later.
“The United States government is mandating their agencies to it, but industry as well as going to need to be doing this migration. The migration is not going to be easy [and] it’s not going to be pain free,” said Moody, whose Ph.D. specialized in elliptic curves, a commonly used base for encryption. “Very often, you’re going to need to use sophisticated tools that are being developed to assist with that. Also talk to your vendors, your CIOs, your CEOs to make sure they’re aware and that they’re planning for budgets to do this. Just because a quantum computer [able to decrypt] isn’t going to be built for, who knows, maybe 15 years, they may think I can just put this off, but understanding that threat is coming sooner than than you realize is important.”
Estimates vary wildly around the size of the threat but perhaps 20 billion devices will need to be updated with PQC safeguarding. NIST has held four rounds of submissions and the first set of standards will encompass algorithms selected the first three. These are the main weapons against quantum decryption attack. The next round seeks to provide alternatives and, in some instances, somewhat less burdensome computational characteristics.
The discussion with Moody was wide-ranging, if perhaps a little dry. He covers PQC strategy and progress and the need to monitor the constant flow of new quantum algorithms. Shor’s algorithm is the famous threat but others are percolating. He notes that many submitted algorithms broke down under testing but says not to make much of that as that’s the nature of the standards development process. He talks about pursuing cryptoagility and offers a few broad tips on preparation.
Moody also touched on geopolitcal rivalries amid what has been a generally collaborative international effort.
“There are some exceptions like China never trusting the United States. They’re developing their own PQC standards. They’re actually very, very similar to the algorithms [we’re using] but they were selected internally. Russia has been doing their own thing, they don’t really communicate with the rest of the world very much. I don’t have a lot of information on what they’re doing. China, even though they are doing their own standards, did have researchers participate in the process; they hosted one of the workshops in the field a few years back. So the community is small enough that people are very good at working together, even if sometimes the country will develop their own standards,” said Moody.
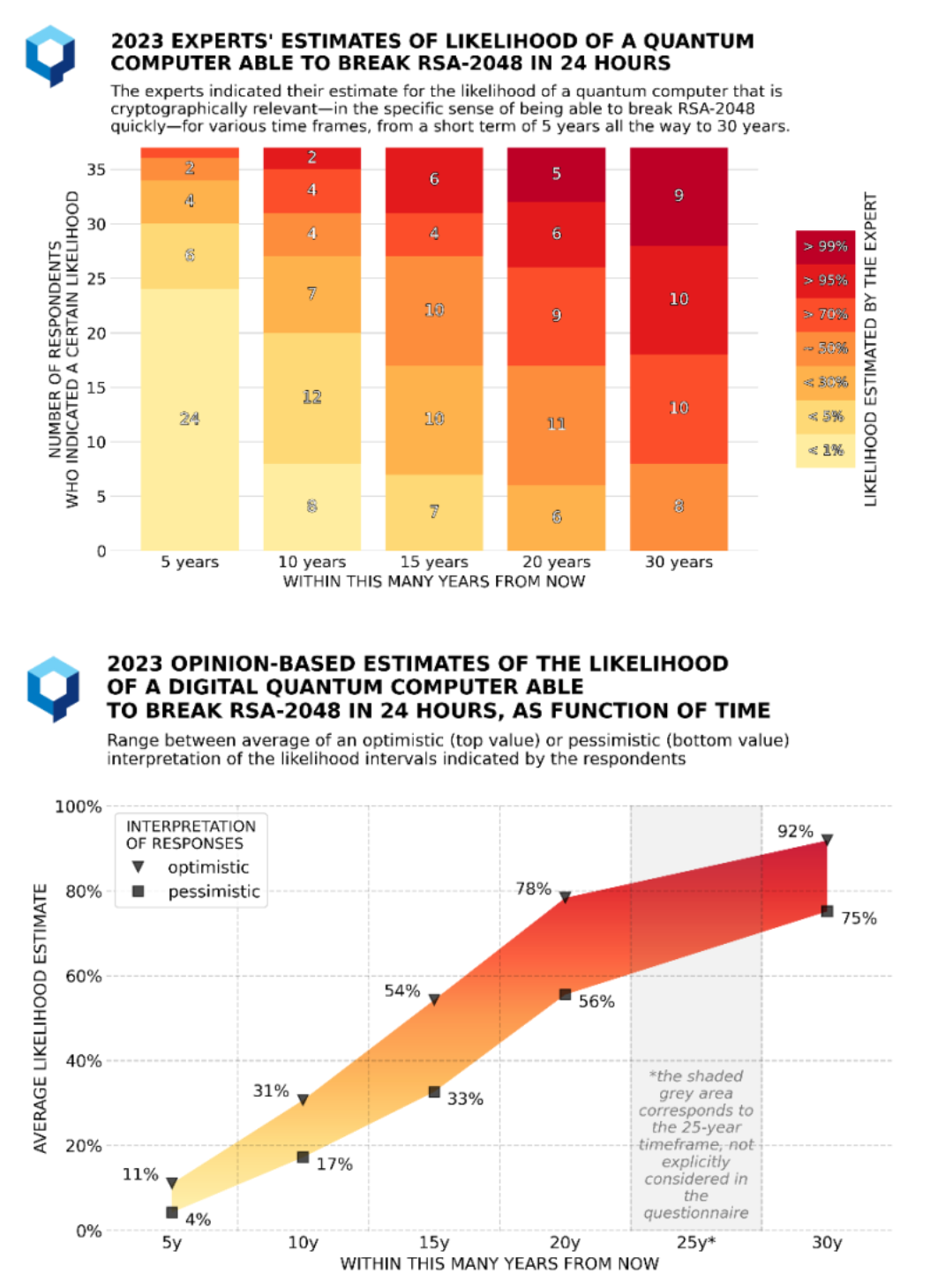
How soon quantum computers will actually be able to decrypt current RSA codes is far from clear, but early confidence that would be many decades has diminished. If you’re looking for a good primer on the PQS threat, he recommended the Quantum Treat Timeline Report released in December by the Global Risk Institute (GRI) as one (figures from its study below).
HPCwire: Let’s talk a little bit about the threat. How big is it and when do we need to worry
Dustin Moody: Well, cryptographers have known for a few decades that if we are able to build a big enough quantum computer, it will threaten all of the public key crypto systems that which we use today. So it’s a it’s a serious threat. We don’t know when a quantum computer would be built that’s large enough to attack current levels of security. There’s been estimates of 10 to 15 years, but you know, nobody knows for certain. We have seen progress in companies building quantum computers — systems from IBM and Google, for example, are getting larger and larger. So this is definitely a threat to take seriously, especially because you can’t just wait until the quantum computer is built and then say now we’ll worry about the problem. We need to solve this 10 to 15 years in advance to protect your information for a long time. There’s a threat of harvest-now-decrypt-later that helps you understand that.
HPCwire: Marco Pistoia, who leads quantum research for JPMorgan Chase, said he’d seen a study suggesting as few as 1300 or so logical qubits might be able to break conventional RSA code, although it would take six months to do so. That was a year ago. It does seem like our ability to execute Shor’s algorithm on these systems is improving, not just the brute force, but our cleverness in getting the algorithm to run.
Dustin Moody: Yep, that’s true. And it’ll take a lot of logical qubits. So we’re not there yet. But yeah, progress has been made. You have to solve the problem solved and migrate to new solutions before we ever get to that point,
HPCwire: We tend to focus on Shor’s algorithm because it’s a direct threat to the current encryption techniques. Are there others in the wings that we should be worried about?
Dustin Moody: There’s a large number of quantum algorithms that we are aware of, Shor being one of them, Grover’s being another one that has an impact on cryptography. But there’s plenty of other quantum algorithms that do interesting things. So whenever anyone is designing the crypto system, they have to take a look at all those and see if they look like they could attack the system in any way? There’s kind of a list of I don’t know, maybe around 15 or so that potentially people have to kind of look at him and figure out, do I need to worry about these.
HPCwire: Does NIST have that list someplace?
Dustin Moody: There was a guy at NIST who kept up such a list. I think he’s at Microsoft, now. It’s been a little while, but he maintained something called the Quantum Algorithms Zoo.
HPCwire: Let’s get back to the NIST effort to develop quantum-resistant algorithms. As I understand it, the process began being around 2016 has gone through this iterative process where you invite submissions of potential quantum resistant algorithms from the community, then test them and come up with some selections; there have been three rounds completed and in the process of becoming standards, with an ongoing fourth round. Walk me through the project and progress.
Dustin Moody: So these kinds of cryptographic competitions have been done in the past to select some of the algorithms that we use today. [So far] a widely used block cypher was selected through a competition. More recently a hash function. Back in 2016, we decided to do one of these [competitions] for new post quantum algorithms that we needed standards for. We let the community know about that. They’re all excited and we got 82 submissions of which 69 met kind of the requirements that we’d set out to be involved. Then we had a process that over six or seven years [during which] we evaluated them going through a period of rounds. In each round, we went further down to the most promising to advance the tons of work going on in there, both internally at NIST, and by the cryptographic community, doing research and benchmarks and experiments and everything.
The third round had seven finalists and eight alternate concluded in July of 2022, where we announced items that we would be standardizing as a result, that included one encryption algorithm and three signature algorithms. We did also keep a few encryption algorithms on into a fourth round for further study. They weren’t quite ready to be selected for standardization. That fourth round is still ongoing and will probably end as this fall, and we’ll pick one or two of those to also standardize. We’ll have two or three encryption [methods] and three signatures as well.
HPCwire: It sounds like a relatively smooth process?
Dustin Moody: That process got a lot of attention from the community. A lot of the algorithms ended up being broken, some late in the process — that’s kind of the nature of how this thing works. That’s where we are now. We’re just about done writing the standards for the first ones that we selected, our expected date is publishing them this summer. The fourth round will end this fall, and then we’ll write standards for those that will take another year or two.
We also have ongoing work to select a few more digital signature algorithms as well. The reason for that is so many of the algorithms we selected are based on what are called lattices; they’re the most promising family, [with] good performance, good security. And for signatures, we had two based on lattices, and then one not based on lattices. The one that wasn’t based on lattices — it’s called SPHINCS+ — turns out to be bigger and slower. So if applications needed to use it, it might not be ideal for them. We wanted to have a backup not based on lattices that could get used easily. That’s what this ongoing digital signature process is about [and] we’re encouraging researchers to try and design new solutions that are not based on lattices that are better performing.
HPCwire: When NIST assesses these algorithms, it must look to see how many computational resources are required to run them?
Dustin Moody: There’s specific evaluation criteria that we look at. Number one is security. Number two is performance. And number three is this laundry list of everything else. But we work internally at NIST, we have a team of experts and try to work with cryptography and industry experts around the world who are independently doing it. But sometimes we’re doing joint research with them in the field.
Security has a wide number of ways to look at it. There’s the theoretical security, where you’re trying to create security proofs where you’re trying to say, ‘if you can break my crypto system, then you can break this hard mathematical problem.’ And we can give a proof for that and because that hard mathematical problem has been studied, that gives us a little bit more confidence. Then it gets complicated because we’re used to doing this with classical computers and looking at how they can attack things. But now we have to look at how can quantum computers attack things and they don’t yet exist. We don’t know their performance. capabilities. So we have to extrapolate and do the best that we can. But it’s all thrown into the mix.
Typically, you don’t end up needing supercomputers. You’re able to analyze how long would the attacks take, how many resources they take, if you were to fully tried to break the security parameters at current levels. The parameters are chosen so that it’s [practically] infeasible to do so. You can figure out, if I were to break this, it would take, you know, 100 years, so there’s no use in actually trying to do that unless you kind of find a breakthrough to find a different way. (See descriptive list of NIST strengths categories at end of article)
HPCwire: Do you test on today’s NISQ (near-term intermediate scale quantum) computers?
Dustin Moody: They’re too small right now to really have any impact in looking at how will a larger quantum computer fare against concrete parameters chosen at high enough security levels. So it’s more theoretical, when you’re figuring out how much resources it would take.
HPCwire: So summarizing a little bit, you think in the fall you’ll finish this last fourth round. Those would all be candidates for standards, which then anyone could use for incorporation into encryption schemes that would be quantum computer resistant.
Dustin Moody: That’s correct. The main ones that we expect to use were already selected in our first batch. So those are kind of the primary ones, most people will use those. But we need to have some backups in case you know, someone comes up with a new breakthrough.
HPCwire: When you select them do you deliberately have a range in terms of computational requirements, knowing that not everyone is going to have supercomputers at their doorstep. Many organizations may need to use more modest resources when running these encryption codes. So people could pick and choose a little bit based on the computational requirements.
Dustin Moody: Yes, there’s a range of security categories from one to five. Category Five has the highest security, but performance is impacted. So there’s a trade off. We include parameters for categories one, three, a five so people can choose the one that’s best suited for their needs.
HPCwire: Can you talk a little bit about the Migration to PQC project, which is also I believe in NIST initiative to develop a variety of tools for implementingPQC What’s your involvement? How is that going?
Dustin Moody: That project is being run by NIST’s National Cybersecurity Center of Excellence (NCCoE). I’m not one of the managers but I attend all the meetings and I’m there to support what goes on. They’ve collaborated with…I think the list is up 40 or 50 industry partners and the list is on their website. It’s a really strong collaboration. A lot of these companies on their own would typically be competing with each but here, they’re all working for the common good of making the migration as smooth as possible, getting experience developing tools that people are going to need to do cryptographic inventories. That’s kind of one of the first steps that an organization is going to need to do. Trying to make sure everything will be interoperable. What lessons can we learn as we. Some people are further along than others and how can we share that information best? It’s really good to have weekly calls, [and] we hold events from time to time. Mostly these industry collaborators are driving it and talking with each other and we just kind of organize them together and help them to keep moving.
HPCwire: Is there any effort to build best practices in this area? Something that that NIST and these collaborators from industry and academia and DOE and DOD could all provide? It would be perhaps have the NIST stamp of authority on best practices for implementing quantum resistant cryptography.
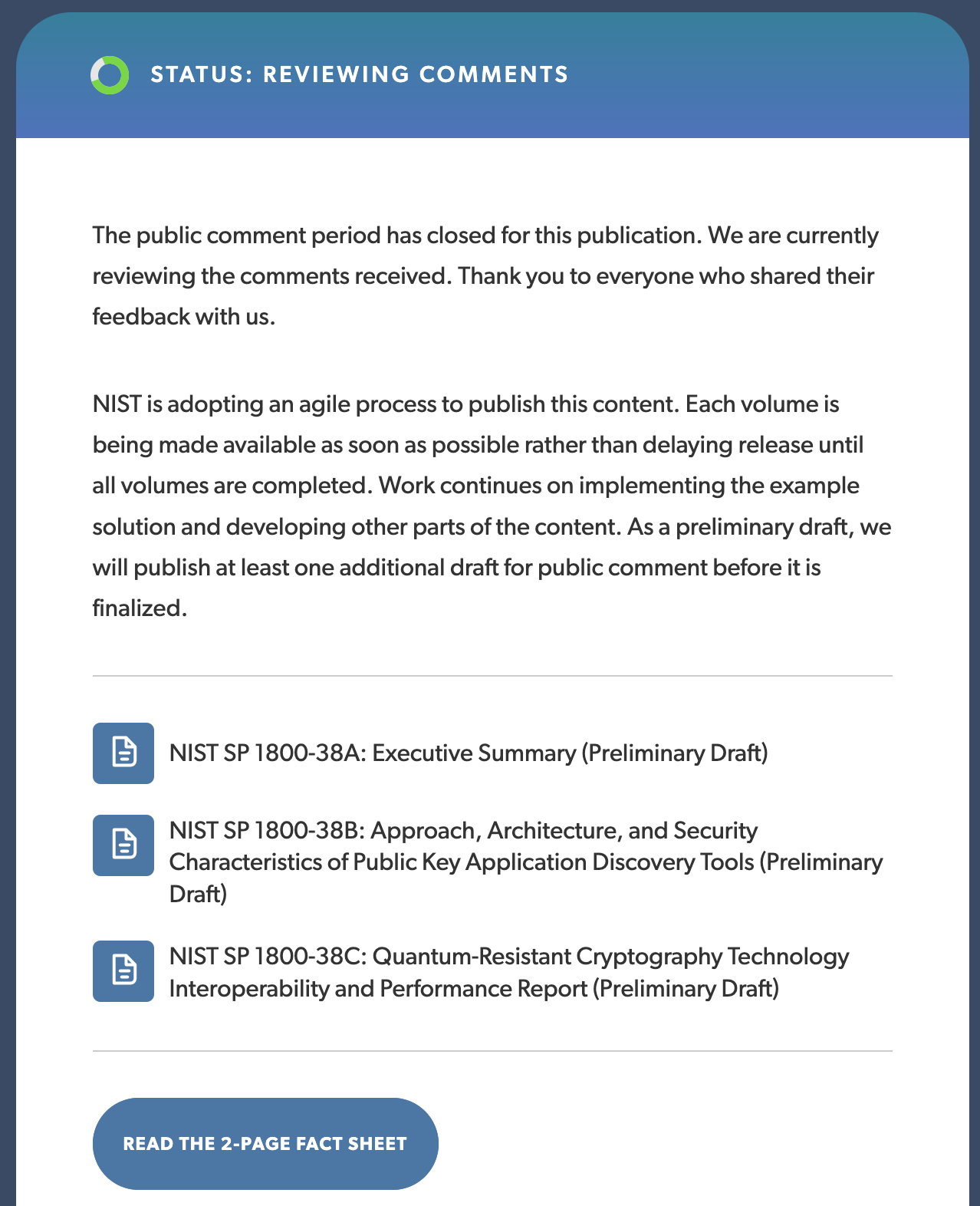
Dustin Moody: Well, the standards that my team is writing, and those are written by NIST and those are the algorithms that people will implement. Then they’ll also then get tested and validated by some of our labs at NIST. The migration project is producing documents, in a series (NIST SP 1800-38A, NIST SP 1800-38B, NIST SP 1800-38C) and those are updated from time to time, where they’re sharing what they’ve learned and putting best practice in this. They are NIST documents, written jointly with the NIST team and with these collaborators to share what they’ve got so far.
HPCwire: What can the potential user community do to be involved? I realize the project is quite mature, it’s been around for a while, and you’ve got lots of people who who’ve been involved already. Are we at the stage where the main participants are working with each other and NIST in developing these algorithms, and it’s now a matter of sort of monitoring the tools that come out.
Dustin Moody: I would say every organization should be becoming educated on understanding the quantum threat, knowing what’s going on with standardization, knowing that you’re going to need to migrate, and what that’s going to involve your organization. It’s not going to be easy and pain free. So planning ahead, and all that. If they want to join that that collaboration (Migration to PQC), people are still joining from time to time and it is still open if they have something that they’ve got to share. But for most organizations or groups, it’s going to be just trying to create your plan preparing for the migration. We want you to wait till the final standards are published, so you’re not implementing the something that’s 99% the final standard, we want you to wait until that’s there, but you can prepare now.
HPCwire: When will they be final?
Dustin Moody: Of the four that we selected, three of them. We put out draft standards a year ago, got public feedback, and have been revising since. The final versions are going to be published this summer. We don’t have an exact date, but it will, it’ll be this summer.
HPCwire: At that point, will a variety of requirements will come around using these algorithms, for example in the U.S. government and perhaps in industry requiring compliance?
Dustin Moody: Technically NIST isn’t a regulatory agency. So yes, US government can. I think the OMB says that all agencies need to use our standards. So the federal government has to use the standards that we use for cryptography, but we know that a wider audience industry in the United States and globally tends to use the algorithms that we standardized as well.
HPCwire: We’re in a world in which geopolitical tensions are real. Are we worried about rivals from China or Russia, or other competing nations not sharing their advances? Or is the cryptoanalyst community small enough that those kinds of things are not likely to happen because the people know each other?
Dustin Moody: There is a real geopolitical threat in terms of who gets the quantum computer quickest. If China develops that and they’re able to break into our cryptography, that’s a that’s a real threat. In terms of designing the algorithms and making the standards, it’s been a very cooperative effort internationally. Industry benefits when a lot of people are using the same algorithms all over the world. And we’ve seen other countries in global standards organizations say they’re going to use the algorithms that were involved in our process.
There are some exceptions like China never trusting the United States. They’re developing their own PQC standards. They’re actually very, very similar to the algorithms [we’re using] but they were selected internally. Russia has been doing their own thing, they don’t really communicate with the rest of the world very much. I don’t have a lot of information on what they’re doing. China, even though they are doing their own standards, did have researchers participate in the process; they hosted one of the workshops in the field a few years back. So the community is small enough that people are very good at working together, even if sometimes the country will develop their own standards.
HPCwire: How did you get involved in cryptography? What drew you into this field?
Dustin Moody: Well, I love math and the math I was studying has some applications in cryptography, specifically, something called elliptic curves, and there’s crypto systems we use today that are based on the curve, which is this beautiful mathematical object that probably no one ever thought they would be of any use in the in the real world. But it turns out they are for cryptography. So that’s kind of my hook into cryptography.
I ended up at NIST because NIST has elliptic curve cryptography standards. I didn’t know anything about post quantum cryptography. Around 2014, my boss said, we’re going to put you in this project dealing with post quantum cryptography and I was like, ‘What’s this? I’ve no idea what this is.’ Within a couple of years, it kind of really took off and grew and has become this high priority for the United States government. It’s been a kind of a fun journey to be on.
HPCwire: Will the PQC project just continue or will it wrap up at some point?
Dustin Moody: We’ll continue for a number of years. We still have the fourth round to finish. We’re still doing this additional digital signature process, which will take several more years. But then again, every everything we do in the future needs to protect against quantum computers. So these initial standards will get published, they’ll be done at some point, but all future cryptography standards will have to take the quantum threat into account. So it’s kind of built in that we have to keep going for the future.
HPCwire: When you talk to the vendor community, they all say, “Encryption has been implemented in such a haphazard way across systems that it’s everywhere, and that in simply finding where it exists in all those things is difficult.” The real goal, they argue, should be to move to a more modular predictable approach. Is there a way NIST can influence that? Or the selection of the algorithms can influence that?
Dustin Moody: Yes, and no. It’s very tricky. That idea you’re talking about, sometimes the word cryptoagility gets thrown out there in that direction. A lot of people are talking about, okay, we’re going to need to migrate these algorithms, this is an opportunity to redesign systems and protocols, maybe we can do it a little bit more intelligently than we did in the past. At the same time, it’s difficult to do that, because you’ve got so many interconnected pieces doing so many things. So it’s tricky to do, but we are encouraging people and having lots of conversations like with the migration and PQC project. We’re encouraging people to think about this, to redesign systems and protocols when you’re designing your applications. Knowing I need to transition to these algorithms, maybe I can redesign my system so that if I need to upgrade again, at some point, it’ll be much easier to do. I can keep track of where my cryptography is, what happens when I’m using it, what information and protecting. I hope that we’ll get some benefit out of this migration, but it’s, it’s certainly going to be very difficult, complicated and painful as well.
HPCwire: Do you have an off the top of your head checklist sort of five things you should be thinking about now to prepare for post quantum cryptography?
Dustin Moody: I’d say number one, just know that the migration is coming. The United States government is mandating their agencies to it, but industry as well as going to need to be doing this migration. The migration is not going to be easy, it’s not going to be pain free. You should be educating yourself as to what PQC is, the whole quantum threat, and starting to figure out, where are you using cryptography, what information is protected with cryptography. As you noted, that’s not as easy as it should be. “Very often, you’re going to need to use sophisticated tools that are being developed to assist with that. Also talk to your vendors, your CIOs, your CEOs to make sure they’re aware and that they’re planning for budgets to do this. Just because a quantum computer [able to decrypt] isn’t going to be built for, who knows, maybe 15 years, they may think I can just put this off, but understanding that threat is coming sooner than than you realize is important.”
HPCwire: Thank you for your time!
Strength Categories from NIST
In accordance with the second and third goals above (Submission Requirements and Evaluation Criteria for the Post-Quantum Cryptography Standardization Process), NIST will base its classification on the range of security strengths offered by the existing NIST standards in symmetric cryptography, which NIST expects to offer significant resistance to quantum cryptanalysis. In particular, NIST will define a separate category for each of the following security requirements (listed in order of increasing strength2 ):
1) Any attack that breaks the relevant security definition must require computational resources comparable to or greater than those required for key search on a block cipher with a 128-bit key (e.g. AES-128)
2) Any attack that breaks the relevant security definition must require computational resources comparable to or greater than those required for collision search on a 256-bit hash function (e.g. SHA-256/ SHA3-256)
3) Any attack that breaks the relevant security definition must require computational resources comparable to or greater than those required for key search on a block cipher with a 192-bit key (e.g. AES-192)
4) Any attack that breaks the relevant security definition must require computational resources comparable to or greater than those required for collision search on a 384-bit hash function (e.g. SHA-384/ SHA3-384)
5) Any attack that breaks the relevant security definition must require computational resources comparable to or greater than those required for key search on a block cipher with a 256-bit key (e.g. AES-256)
At its annual user conference Snowflake Summit 2024, the company today announced Polaris Catalog, a vendor-neutral, open catalog implementation for Apache Iceberg. It’s an open standard of choice for implementing data lakehouses, data lakes, and other modern architectures.
Snowflake plans to open-source Polaris Catalog in the next 90 days to provide enterprises and the entire Iceberg community with new levels of choice, flexibility, and control over their data, with full enterprise security and Apache Iceberg interoperability with Amazon Web Services (AWS), Confluent, Dremio, Google Cloud, Microsoft Azure, Salesforce, and more.
Apache Iceberg emerged from incubation to a top-level Apache Software Foundation project in May 2020, and has since surged in popularity to become a leading open-source data table format.
With Polaris Catalog, users now gain a single, centralised place for any engine to find and access an organisation’s Iceberg tables with full, open interoperability.
Polaris Catalog relies on Iceberg’s open-source REST protocol, which provides an open standard for users to access and retrieve data from any engine that supports the Iceberg Rest API, including Apache Flink, Apache Spark, Dremio, Python, Trino, and more.
“Organisations want open storage and interoperable query engines without lock-in. Now, with the support of industry leaders, we are further simplifying how any organisation can easily access their data across diverse systems with increased flexibility and control,” said Christian Kleinerman, EVP of product, Snowflake.
Moreover, Snowflake revealed that organisations can get started running Polaris Catalog hosted in Snowflake’s AI Data Cloud within minutes (Snowflake-hosted in public preview soon), or self-host it in their own infrastructure using containers such as Docker or Kubernetes.
Since Polaris Catalog’s backend implementation will be open source, organisations can freely swap the hosting infrastructure while eliminating vendor lock-in.
To ensure Polaris Catalog can meet the evolving needs of the wider community and landscape, Snowflake is collaborating with the Iceberg ecosystem to drive the project forward. Interestingly, a part of what makes Apache Iceberg so powerful is its vibrant community of diverse adopters, contributors, and commercial offerings.
The post Snowflake Unveils Polaris Catalog, a Vendor-Neutral, Open Catalog Implementation for Apache Iceberg appeared first on AIM.
We all know that Generative AI is on the tip of everybody's tongue. Companies are looking into new ways to integrate it into the business. Some companies are looking into building their own tools. Machine learning engineers are looking into ways to transition as prompt engineers. Everybody wants a piece of the cake.
The generative AI market will continue to grow and become more popular. One of the major aspects a lot of people are looking at is how they get into the $45 billion market.
The foundation of mastering generative AI is all about prompt engineering. And as the market grows, the market of prompt engineers will also grow.
Prompt engineering is the best practice for designing inputs for generative AI tools that aim to produce optimal outputs. Companies want these optimal outputs so need the best in the game to do it!
Prompt engineers are in high demand and are making a great career out of it: AI Prompt Engineers are Making $300k/y
What Skills Does a Prompt Engineer Need?
The main hard skills a prompt engineer needs is technical proficiency in:
Artificial Intelligence
Machine Learning Models
Natural Language Processing
GPT (Generative Pre-trained Transformer)
Along with these hard skills, they will also need soft skills in linguistic acuity:
Language
Grammar
Syntax
Semantics
How Can I Become A Prompt Engineer?
As this is a general blog post, some of you may already be in the tech space as a machine learning engineer whereas some of you may be just starting out. Therefore, I will create a roadmap to help you become a prompt engineer from start to finish.
Machine Learning
Link: Machine Learning Specialization
Firstly, you will need a good understanding of machine learning. Stanford offers this course and DeepLearning.AI is specific for people who want to break into AI by mastering the fundamental concepts of machine learning whilst also being able to develop practical machine learning skills through a 3-course program.
Natural Language Processing
Link: Natural Language Processing (NLP) Specialization
Once you have a good foundational understanding of machine learning models, you now want to understand the beauty of language and how it is processed in computers. Taking on what you have learned from the machine learning specialization, you will learn how to master cutting-edge NLP techniques through four hands-on courses.
Generative AI and LLMs
Link: Generative AI with Large Language Models
Now it is time to combine the two. Take your knowledge of machine learning models and natural language processing and fuse it together to understand large language models. You will gain foundational knowledge, practical skills, and a functional understanding of how generative AI works whilst also creating value with cutting-edge technology with guidance from AWS experts.
Generative AI and Transformers
Link: Generative AI Language Modeling with Transformers
Imperative to your career to becoming a prompt engineer is learning about transformers. Transformers help machines to understand, interpret, and generate human language. In this course, you will be able to explain the concept of attention mechanisms in transformers and also be able to describe language modelling with the decoder-based GPT and encoder-based BERT. You will then move on to implementing positional encoding, masking, attention mechanism, document classification, and creating LLMs like GPT and BERT.
Prompt Engineering
Link: ChatGPT Prompt Engineering for Developers
And when you have all this knowledge under your belt, you want to learn prompt engineering. The last aim of your career transition is to understand and build intuition around best practices for prompt engineering. There are a lot of resources out there to help you perfect it. In this case, this is where your soft skills will come into play and your ability to understand language and also understand tools such as ChatGPT and how they interpret language.
Prompt Engineer Salary
Depending on the company, location, and years of experience, your salary for any job will vary.
If we’re looking at Prompt Engineers in the UK, London, entry-level prompt engineers start between £30,000 – £40,000. As you start to gain a few more years of experience, you can expect to earn £40,000 – £50,000. At senior levels, prompt engineering salaries range from £50,000 – £70,000.
With that being said, in the States, some Prompt engineers are making $350,000 a year at some of the leading companies.
If you want to make bank and are eager to pursue a career in prompt engineering. Have a look into more niche skills within prompt engineering such as multimodal prompt engineering, prompt security, and prompt testing automation.
Wrapping it Up
If you’re looking into prompt engineering, now is the time to execute the transition. The generative AI market will only continue to grow and need people to meet those high demands.
Nisha Arya is a data scientist, freelance technical writer, and an editor and community manager for KDnuggets. She is particularly interested in providing data science career advice or tutorials and theory-based knowledge around data science. Nisha covers a wide range of topics and wishes to explore the different ways artificial intelligence can benefit the longevity of human life. A keen learner, Nisha seeks to broaden her tech knowledge and writing skills, while helping guide others.
More On This Topic
Data Scientist Breakdown: Skills, Certifications, and Salary
Data Scientist vs Data Engineer Salary
2021 Data Engineer Salary Report Shares Insights on a Swiftly…
5 Machine Learning Skills Every Machine Learning Engineer Should…
Here’s Why You Need Python Skills as a Machine Learning Engineer
KDnuggets News, December 14: 3 Free Machine Learning Courses for…
Rapid advancements in technology and manufacturing processes have accelerated productivity and efficiency gains in the manufacturing sector. The integration of technologies such as artificial intelligence (AI) and internet of things (IoT) with traditional operational technologies (OT) continues to transform and optimize how we manufacture products of ever-increasing complexity globally.
This increased interconnectivity and digitization have introduced new threat vectors into traditionally closed systems. These vectors, introduced into a landscape of ever-evolving threat actors, are posing significant risks in the manufacturing sector – both to individuals and to society.
New Threats to Old Systems
New geopolitical risks, global market competitiveness, intricate cybercrime syndicates, and the growing ease of crafting and launching sophisticated cyberattacks are driving a shift in mindset from merely advanced manufacturing to secure advanced manufacturing (AM). Clearly, the wide range of attacks illustrates the threats faced by manufacturing in particular.
Supply chain attacks: Product and manufacturing complexity and growing supplier inter-connectivity have had a multiplicative effect on the number of vulnerabilities faced by modern supply chains. Exploiting these vulnerabilities can lead to production delays, quality issues, and compromise a manufacturer’s infrastructure.
Industrial Control System (ICS) attacks: Advanced manufacturing systems enable remote access and control, reducing workforce requirements and reducing processing time. However, malicious control of such systems can disrupt production and endanger worker safety.
Ransomware attacks: Ransomware attacks continue to rise globally and are increasingly targeted at the manufacturing sector, leading to increased financial losses along with the cost of recovery.
Data breaches: Data such as a manufacturer’s Intellectual Property (IP), customer data and other confidential information continues to be a prime target for malicious entities. Unauthorized access and transfer of such data severely impacts an organization’s reputation.
Traditional Methods, Applied in a New Way
How does one tackle these new threats? Having robust cybersecurity measures becomes imperative in safeguarding critical systems and sensitive data against these multifaceted threats. Not surprisingly, tried-and-tested cybersecurity practices are most effective, yet are best implemented through innovative methods and technologies.
Integrating and synergizing the cybersecurity organization: Businesses should create and implement a cybersecurity strategy covering the entire enterprise, facilitating application to both IT and OT environments in a consistent manner. This entails aligning people, process and technology to support common cybersecurity goals and priorities based on a regularly updated risk management strategy.
Control access: Organizations must enforce robust identity and access controls across all environments, including on-premise, off-premise, IT (information technology), operational technology (OT), industrial internet of things (IIoT), IoT and cloud. They should maintain consistent controls and processes for managing identities and access across the business.
System hardening and patch management: Timely patching of products and systems is essential in addressing vulnerable systems. This includes hardening of systems before they are introduced into the environment, as well as ensuring regular testing and application of vendor-published patches.
Network segmentation: Segregation and isolation of systems and environments based on business criticality makes it harder for malicious actors to access critical systems, even as it simplifies isolation of infected or compromised systems from the rest of the enterprise.
Security monitoring and incident response: Security monitoring should be performed cohesively so that security events from across different environments are effectively triaged and investigated. This forms a comprehensive view of the attack vector and all affected systems across the enterprise.
Cybersecurity awareness: While most businesses have cybersecurity awareness and learning programs for employees, few extend these to manufacturing facilities, deeming them irrelevant or low risk. However, the convergence of IT and OT systems has now elevated the risk in these traditionally isolated environments; hence, employees at these locations should be trained accordingly.
Supply chain security: An effective vendor risk management process enables security and resilience of supply chains. This should be prioritized based on risk and tested periodically to affirm accurate monitoring and reporting across the ecosystem.
EY GDS – Leading the Charge in Industry 4.0
With the role of cybersecurity professionals becoming more critical, cybersecurity, strategy, risk, compliance, and resilience teams stand at the forefront of protecting organizational assets and maintaining business continuity. As a global leader in assurance, tax, transaction, and advisory services, EY GDS has emerged as a frontrunner in cybersecurity solutions for Industry 4.0. The organization is driving cutting-edge technologies such as AI-based threat detection, blockchain for security, and advanced analytics to protect against cyber threats.
With certifications and up-skilling programs offered to employees to keep them abreast of industry standards and technologies, EY GDS plays a key role in maintaining the integrity and security of industrial systems and data across the globe, protecting businesses and consumers alike. The organization is building inclusive teams to bring in diverse perspectives in tackling cybersecurity challenges. It offers opportunities globally to work with international clients and on cross-border projects, helping shape global cybersecurity strategies. There are ample opportunities to work on innovative projects that address some of the most pressing cybersecurity challenges in Industry 4.0.
EY GDS has facilitated networking opportunities with industry experts and mentors from the global EY network, allowing for professional growth and knowledge exchange. By aligning employer branding and career development strategies with Industry 4.0 imperatives, the organization offers the best opportunities in cybersecurity, enabling a resilient and innovative workforce that can meet the evolving challenges of the digital landscape.
The Road Ahead …
As with addressing any cybersecurity threats, executive leadership buy-in is essential to set priorities for business, and collaboration across the enterprise will be critical to effectively achieve these priorities.
Industry 4.0 continues to drive innovation and transform manufacturing business across the globe. It is for businesses to decide how secure these transformations are, with clear visibility of the risks and a well-defined strategy to address them. How well businesses can do it will determine their level of success and resilience in this new competitive manufacturing landscape.
The views reflected in this article are the views of the author and do not necessarily reflect the views of the global EY organization or its member firms.
The post Smart Industry, Smart Approach: Cybersecurity Imperatives in Industry 4.0 appeared first on AIM.
Nvidia CEO Jensen Huang surprised the audience at his keynote on Sunday for the Computex event by teasing the next chip architecture from his company, "Rubin."
Nvidia CEO Jensen Huang disclosed in his keynote Sunday evening, at the Computex annual trade show in, Taipei, Taiwan, that the successor to the company's "Blackwell" GPU and CPU family will be called "Rubin" named for US astronomer Vera Rubin, and will be made available in the first half of 2026.
The announcement reinforces Huang's pledge for Nvidia to be on a one-year cadence of releasing new chip architectures.
Before clicking the slide to show the Rubin line, Huang quipped to his audience, "This is the very first time this next click has been made, and I'm not sure yet whether I'm going to regret this or not."
Huang shows off the roadmap from prior generation, "Hopper," through the newest, "Blackwell," to Rubin.
"All of these chips are in full development, a 100% of them, and the rhythm is one year, at the limits of technology, all 100% architecturally compatible," said Huang, "and all of the richness of software on top of it."
The surprise unveiling of Rubin comes hot on the heels of the formal announcement of Blackwell by Huang at the GTC conference in March.
According to a research note from Wall Street brokerage Jefferies & Co., citing news site Wccftech, the Rubin chips, including a GPU chip family, and a CPU chip named Vera, will move from using the current fastest computer DRAM memory, "HBM3e," to using the next generation, "HBM 4." The GPU chips will be designated as "R100" GPUs.
The chips will be fabricated by Taiwan Semiconductor Manufacturing in a 3-nanometer process technology, said Jefferies analysts, and will commence production in the fourth quarter of 2025.
The Rubin uses what's called a "4x reticle design," the analysts note, which means that it takes up more of the surface area of a 12-inch silicon wafer than does the Blackwell, which is only 3.3x. The "reticle" is the area of a wafer that a typical photolithography system can address with one pass when laying down the circuits of a chip.
Huang also disclosed a forthcoming successor to the Blackwell GPU, Blackwell Ultra. The Rubin architecture, said Huang, will also have its "Ultra" version, following in 2027.
Check out all the Computex news from Nvidia on the company's news site or this round-up blog post on the event from the company.
Ola Chief Bhavish Aggarwal recently met with Arm CEO Rene Haas in Taiwan after migrating Ola’s workload from Microsoft Azure and AWS to its own homegrown cloud platform, Krutrim.
“Wonderful meeting Rene Haa, Arm CEO in Taiwan. Lots of exciting things in store to enable AI compute for India!” Aggarwal posted on X.
Wonderful meeting @renehaas237 Arm CEO in Taiwan. Lots of exciting things in store to enable AI compute for India! pic.twitter.com/IGwEDoy4UK
— Bhavish Aggarwal (@bhash) June 3, 2024
Krutrim, India’s first AI unicorn, recently launched Krutrim AI Cloud, its own cloud platform for enterprises, researchers, and developers. Recently, Aggarwal said the world’s largest talent density for semiconductors outside the US’ Bay Area is in Bengaluru.
“But nobody is working on an Indian chip. The problem is not the talent. My peer set of entrepreneurs haven’t given them a platform,” Aggarwal said. “We’ve to make that platform…to build a full stack compute in India,” he added.
Krutrim Cloud provides access to state-of-the-art AI computing infrastructure, Krutrim’s foundational models, and other open-source models such as Meta’s Llama 3 and Mistral. This platform will enable developers to run and build LLMs at a fraction of the costs currently offered by other cloud service providers.
With this development, Ola Krutrim will compete with Microsoft Azure, Google Cloud, and Amazon Web Services. These platforms have all experienced robust revenue growth in recent quarters,driven by increasing demand from businesses and enterprises of varying sizes.
The company has also announced Model-as-a-Service (MaaS) and GPU-as-a-Service offerings, allowing access to its foundational models and AI compute infrastructure.
British chip designer Arm Holdings anticipates that 100 billion Arm devices worldwide will be AI-ready by the end of next year, according to Haas, who made the announcement on Monday at the Computex forum in Taipei.
Moreover, the company aims to gain more than 50% of the Windows PC market in five years as Microsoft and its hardware partners prepare to launch a new batch of computers based on the British firm’s technology.
In India, HCLTech recently partnered with Arm To build custom silicon chips for AI workloads.
The post Ola Chief Bhavish Aggarwal Meets Arm CEO in Taiwan to Build AI Chips appeared first on AIM.
GPT-4o is a new and the top of the line AI model by OpenAI. It is a multimodal AI model, meaning it integrates text, audio, and vision into a single model, offers faster response times, improved reasoning, and better performance in non-English languages. Compared to GPT-4 Turbo, it is 50% cheaper and twice as fast.
In this blog, we will learn 5 ways to access the GPT-4o model for free, experience the multimod ability, and improve reasoning.
Note: The platforms mentioned in this blog provide limited access to the model, meaning you can ask 5-10 queries per day. It is free but limited.
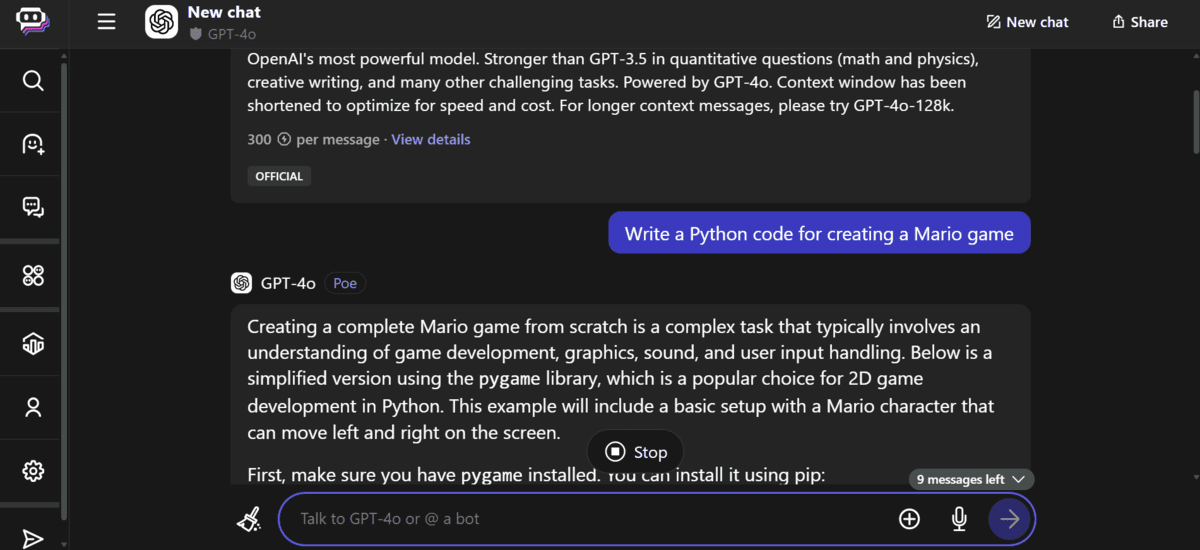
1. Poe
Poe is my favorite chatbot application. It always provides free access to the latest models. You can access both open-source and closed-source AI models. Poe is by far the most generous platform in providing free access to the latest paid AI models.
To access the GPT-4o model:
Create a new chat.
Click on the “More” button above the text input box.
Search for “GPT-4o” and select the model.
Start asking questions.
Every day, you get to ask 10 questions using this model.
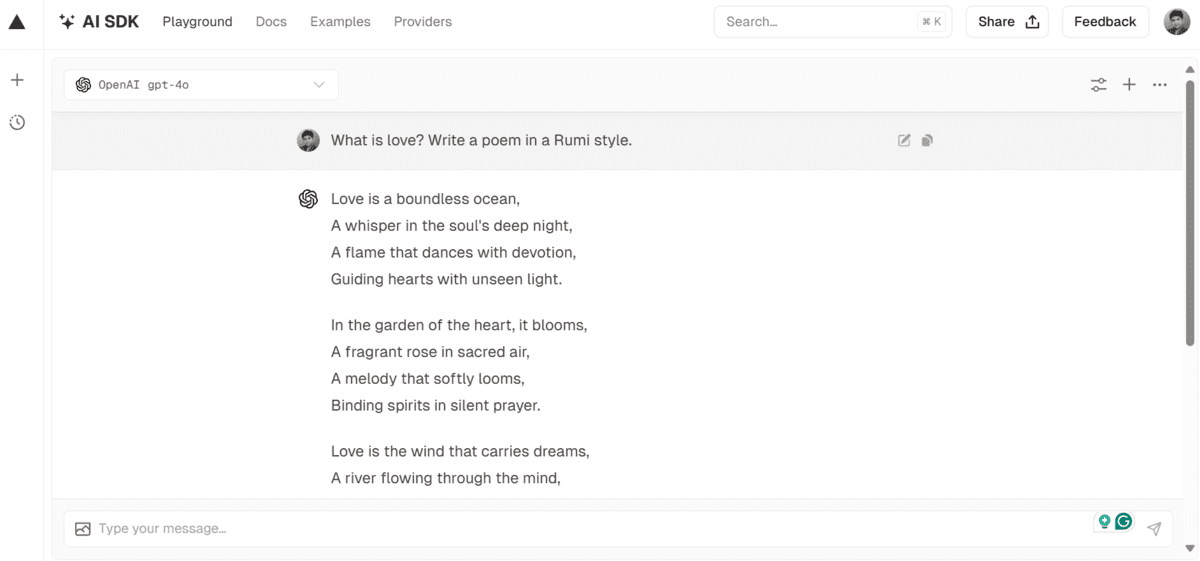
2. Vercel AI Playground
Vercel AI Playground is another favorite platform that offers free access to both open-source and closed-source models. It also lets you combine multiple models at the same time. It is fast and lets you switch models.
The most intriguing part of using Vercel AI playground is that it has no limitations. You can ask questions as many times as possible without hitting the daily quota.
You can start using the GPT-4o model by creating a new chat box, clicking on the model at the top left, and scrolling down to select it. It is that simple.
Read the 5 Free AI Playgrounds For You to Try in 2024 blog to learn about other AI playgrounds.
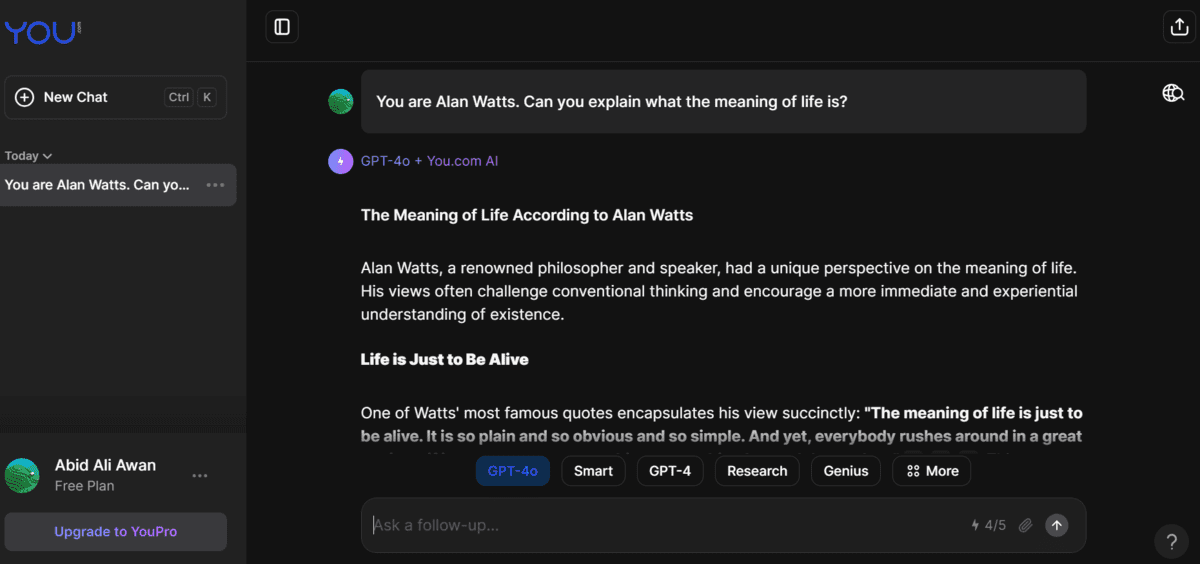
3. You.com
You.com is an AI search engine that combines the power of AI models like GPT-4o with web search to provide the latest and most relevant answers.
You.com offers access to all of the top-performing large language models like GPT-4-turbo, Claude 3 Opus, Gemini 1.5 Pro, Llama 3, Command R+, and more. All you have to do is to click on the “More” button and select the “GPT-4o” model.
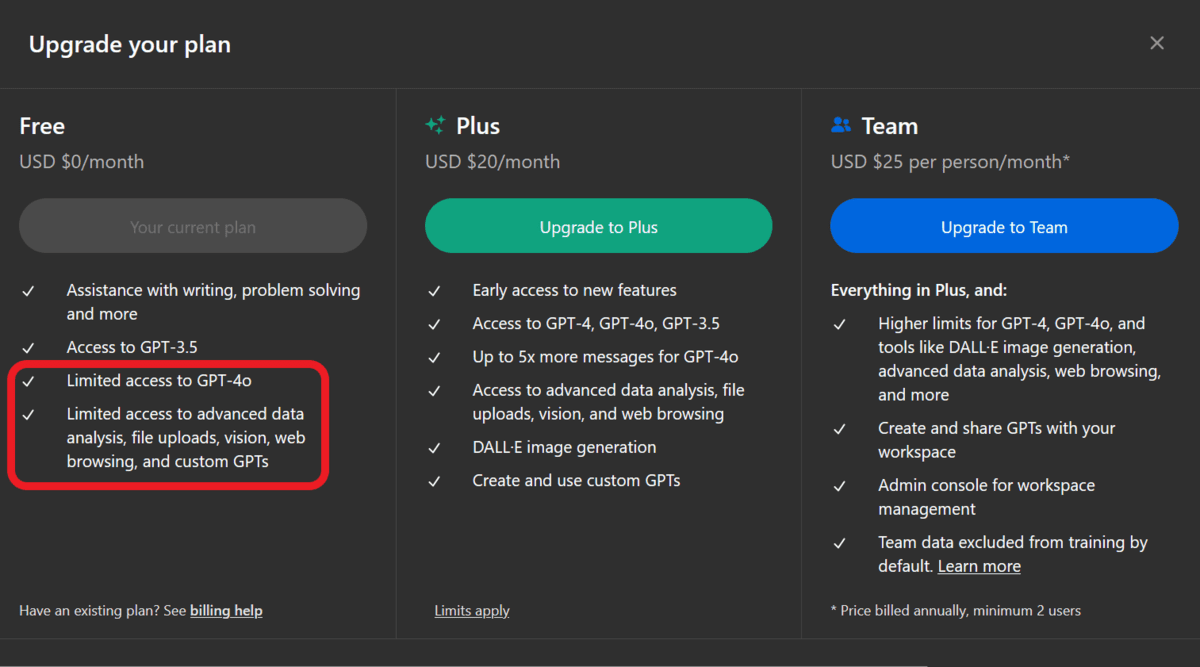
4. ChatGPT
ChatGPT has announced with the launch of GPT-4o, that it will offer access to the GPT-4o model and advanced tools for all users. As a free user, you can use the GPT-4o model a few times, and then it will automatically switch to the GPT-3.5-turbo model.
The best way to access GPT-4o is to upload the file or image and ask questions about it. It cannot use GPT-3.5 to understand image data, so this might be a cheat code to using GPT-4o all the time.
5. LMSYS Direct Chat
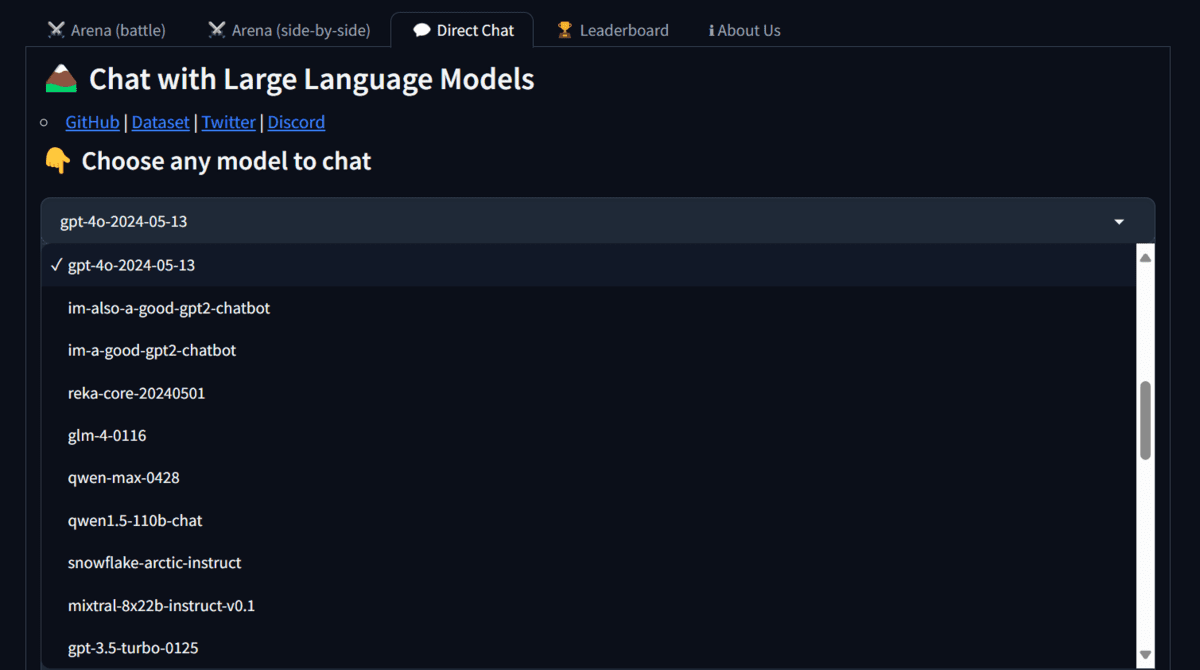
LMSYS Direct Chat is an AI playground that lets you use all kinds of open and closed-source models. To access a particular model, go to the Direct Chat tab, click on the model drop-down button, and select the “gpt-4o-2024-05-13” model.
Access to the model is limited, and sometimes, you might need to get a chance to use it. So, that is why I am keeping it at the 5th spot due to the unpredictability of the model availability.
Conclusion
You can also try the OpenGPT 4o app created by the open-source community to provide similar functionality as the GPT-4o model. It offers a chatbot, live chat with webcam, voice chat, image generation, and video generation. It is a super app.
In this blog, we have learned 5 simple ways to use the GPT-4o model for free. Not all AI models are equally accurate for every task; therefore, choosing a top-tier model like GPT-4o is often the safest choice.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in technology management and a bachelor's degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
More On This Topic
3 Ways to Access GPT-4 for Free
3 Ways to Access Claude AI for Free
15 Trending MLOps Talks You can Access for Free at ODSC East 2022
How to Access and Use Gemini API for Free
Hone Your Data Skills With Free Access to DataCamp
365 Data Science Offers Free Course Access Until Nov. 20
A common cliche held in the language industry is that translation helps to break the language barrier. Since the late 1950s, researchers have been attempting to understand animal communication. Now, scientists are blending animal wisdom with LamDA’s secrets, embracing GPT-3’s essence.
By studying massive datasets, which can include audio recordings, video footage, and behavioural data, researchers are now using machine learning to create a programme that can interpret these animal communication methods, among other things.
Closer to Reality
The Earth Species Project (ESP) seeks to build on this by utilising AI to address some of the industry’s enduring problems. With projects like mapping out crow vocalisations and creating a benchmark of animal sounds, ESP is establishing the groundwork for further AI research.
The organisation’s first peer-reviewed publication, Scientific Reports, presented a technique that could separate a single voice from a recording of numerous speakers, demonstrating impressive strides being made in the field of animal communication with the help of AI, inspiring the audience with the possibilities.
Scientists refer to the complex task of isolating and understanding individual animal communication signals in a cacophony of sounds as the cocktail-party problem. From there, the organisation started evaluating the information in bloggers to pair behaviours with communication signals.
ESP co-founder Aza Raskin stated, “As human beings, our ability to understand is limited by our ability to perceive. AI does widen the window of what human perception is capable of.”
Easier Said than Done
A common mistake is assuming that animals employ sounds as one form of communication. Visual and tactile stimuli are as equally significant in animal communication as auditory stimuli, highlighting the intricate and fascinating nature of this field, which is sure to pique the interest of the audience.
For example, when beluga whales communicate, specific vocalisation cues show their social systems. Meerkats utilise a complex system of alarm cries in response to predators based on the predator’s proximity and level of risk. Birds also convey danger and other information to their flock members in the sky, such as the status of a mating pair.
These are only a few challenges researchers must address while studying animal communication.
To do this, Raskin and the ESP team are incorporating some of the most popular and consequential innovations of the moment into a suite of tools to actualise their project – generative AI and huge language models. These advanced technologies can understand and generate human-like responses in multiple languages, styles, and contexts using machine learning.
Understanding non-human communication can be significantly aided by the insights provided by models like OpenAI’s GPT-3 and Google’s LaMDA, which are examples of such generative AI tools.
ESP has recently developed the Benchmark for Animal Sounds, or BEANS for short, the first-ever benchmark for animal vocalisations. It established a standard against which to measure the performance of machine learning algorithms on bioacoustics data.
On the basis of self-supervision, it has also created the Animal Vocalisation Encoder, or AVES. This is the first foundational model for animal vocalisations and can be applied to many other applications, including signal detection and categorisation.
The nonprofit is just one of many groups that have recently emerged to translate animal languages. Some organisations, like Project Cetacean Translation Initiative (CETI), are dedicated to attempting to comprehend a specific species — in this case, sperm whales. CETI’s research focuses on deciphering the complex vocalisations of these marine mammals.
DeepSqueak is another machine learning technique developed by University of Washington researchers Kevin Coffey and Russell Marx, capable of decoding rodent chatter. Using raw audio data, DeepSqueak identifies rodent calls, compares them to calls with similar features, and provides behavioural insights, demonstrating the diverse approaches to animal communication research.
ChatGPT for Animals
In 2023, an X user named Cooper claimed that GPT-4 helped save his dog’s life. He ran a diagnosis on his dog using GPT-4, and the LLM helped him narrow down the underlying issue troubling his Border Collie named Sassy.
Though achieving AGI may still be years away, Sassy’s recovery demonstrates the potential practical applications of GPT-4 for animals.
While it is astonishing in and of itself, developing a foundational tool to comprehend all animal communication is challenging. Animal data is hard to obtain and requires specialised research to annotate, in contrast to human data, which is annotated in a simple manner (for humans).
Compared to humans, animals have a far limited range of sounds, even though many of them are capable of having sophisticated, complex communities. This means that the same sound can have multiple meanings depending on the context in which it is used. The only way to determine meaning is to examine the context, which includes the caller’s identity, relationships with others, hierarchy, and past interactions.
Yet, this might be possible within a few years, according to Raskin. “We anticipate being able to produce original animal vocalisations within the next 12 to 36 months. Imagine if we could create a synthetic crow or whale that would seem to them to be communicating with one of their own. The plot twist is that, before we realise what we are saying, we might be able to engage in conservation”, Raskin says.
This “plot twist”, as Raskin calls it, refers to the potential for AI to not only understand animal communication but also to facilitate human-animal communication, opening up new possibilities for conservation and coexistence.
The post Soon, LLMs Can Help Humans Communicate with Animals appeared first on AIM.
When it comes to AI models in different cultures and geographies, it is important for them to be accurate and aware of the context, history, and relevance of the region to serve the communities better. We have seen AI models hallucinate majorly while describing several key aspects of Indian culture in the past.
To ensure that AI models are culturally aware, Vinija Jain, ML leader at Amazon and research fellow at IIT Patna, recently published the paper along with Aman Chadha, Shashank Goswami, and Olena Burda-Lassen, titled ‘How Culturally Aware are Vision-Language Models?’ The paper evaluated the cultural sensitivity of AI in image captioning.
“In terms of the Indian context, we wanted to understand how global models like Gemini and GPT recognise our cultural symbols,” said Jain in an interview with AIM. She collected 1,500 images of different Indian dance forms and foods, and manually captioned them to create the MOSAIC-1.5k dataset, representing India’s rich culture in detail.
While most of this is currently done manually, Jain said that if needed, she would later expand the dataset with synthetic data.
Source: How Culturally Aware are Vision-Language Models?
The idea of this project is deeply rooted in Jain’s Indian origin. “What happened is that I really craved that culture,” Jain, who started living in the USA at a young age, said. “I feel like I’ve missed out on a big part of that. And because of that, I’ve been trying to find that community here.”
Another key introduction from the research was the Cultural Awareness Score (CAS), which measures AI models on how well they capture the cultural context in image captions. Even though the current evaluation is in English, Jain emphasised the importance of assessing model performance across various linguistic and cultural contexts, including Indic languages.
Culturally Aware AI Research
Recently, Guneet Singh Kohli, an AI research scientist at GreyOrange, created the Sanskriti Bench. It aims to develop an Indian cultural benchmark to test the increase in Indic AI models. By crafting a benchmark with the help of native speakers from different regions across India, the initiative aims to take into account the country’s cultural diversity.
Jain has now also started working with Kohli for this initiative. “Sanskriti Bench is actually a phenomenal idea and the way Guneet is leading the project is unbelievable,” she said, when asked about the most interesting project she’s come across in recent times.
Similarly, Jain is building Indic-MMLU, which is focused on understanding Indic languages. “Every major LLM is evaluated on MMLU; therefore we wanted to create one for Indic languages as well,” said Jain, highlighting that it is necessary to evaluate all the newly released Indic LLMs on their generalisation capabilities across various domains such as science, literature, and social sciences.
Hoping to release the benchmark by the end of the next month, Jain said that her motivation to work in the Indic language space was her roots in India. “My journey in AI research is deeply rooted in my desire to connect with and contribute to my cultural heritage,” she said.
AI Research is an Inspiration
Jain enrolled at Stanford while working at her job as her passion grew towards NLP, multimodal, and AI research. She also won the Outstanding Paper Award at ENLP 2023 for ‘Counter Turing Test (CT2): AI-Generated Text Detection is Not as Easy as You May Think – Introducing AI Detectability Index (ADI)’.
Jain is also currently co-advising Sriparna Saha at IIT Patna’s AI lab for Indic medical research. The paper, titled ‘M3: Multimodal, Multilingual, Medical Help Assistant’, will be India’s first multilingual medical VLM. The aim of the research is to eventually assist doctors in patient-doctor communication along with translation and visual assistance during diagnosis.
“They’re doing a lot of tremendous work in Indic medical research and are actually collaborating with doctors to help validate the data to avoid hallucination,” said Jain. IIT Patna has been focusing on AI research in the medical field very intensively. Recently, a team led by Aman Chadha released the MedSumm dataset for LLMs and VLMs for medical research.
Apart from this, Jain is also working on creating an inventory of all the impactful Indic AI research, which would include LLM, datasets, benchmarks, frameworks, and even tokenisers.
“The research from India is not only serving as great research in itself, but also as an inspiration,” said Jain.
“When you see someone else building something for the community, it motivates you to help and contributes as a building block for further developments,” she added, talking about the growing push for AI research in India, while companies such as OpenAI and Google expand their base into the Indic AI space.
The post Meet the AI Researcher Building Culturally Aware Vision Language Models appeared first on AIM.














 pic.twitter.com/IGwEDoy4UK
pic.twitter.com/IGwEDoy4UK