Cisco Live 2024 is proving to be a phenomenal event in Las Vegas. Apart from boasting Elton John as the star performer, the company has announced a billion-dollar AI investment fund, which CEO Chuck Robbins claims is not just another fund.
“Everybody yawns when you hear about a billion dollars in AI these days — ‘Oh, another billion dollars’,” said Robbins. He emphasised that Cisco’s strategy was quite different from others who are currently pouring billions of dollars into the industry.
Cisco Investments has unveiled a $1 billion AI investment fund to bolster the startup ecosystem and further advancements with GenAI and LLMs. Additionally, the company revealed its financial support for Cohere, Mistral AI, and Scale AI, all of which have achieved billion-dollar valuations through their continuous fundraising efforts.
These three startups are among over 20 acquisitions and investments Cisco has made in AI in recent years. The $1 billion Global AI Investment Fund aims to further expand these efforts. So far, the fund has already allocated nearly $200 million.
Moreover, the company is also fuelling competition against OpenAI by investing in startups such as Mistral and Cohere. Cisco’s support for Cohere is part of a $450 million funding round that includes contributions from NVIDIA, Salesforce Ventures, and PSP Investments. This fusion of capital brings Cohere’s valuation to $5 billion.
The Agnostic Play of AI
Much like other tech giants, Cisco has made numerous AI acquisitions and investments over the past several years while also integrating generative AI across its product portfolio. Notably, in March, Cisco completed a $28 billion acquisition of the observability platform Splunk.
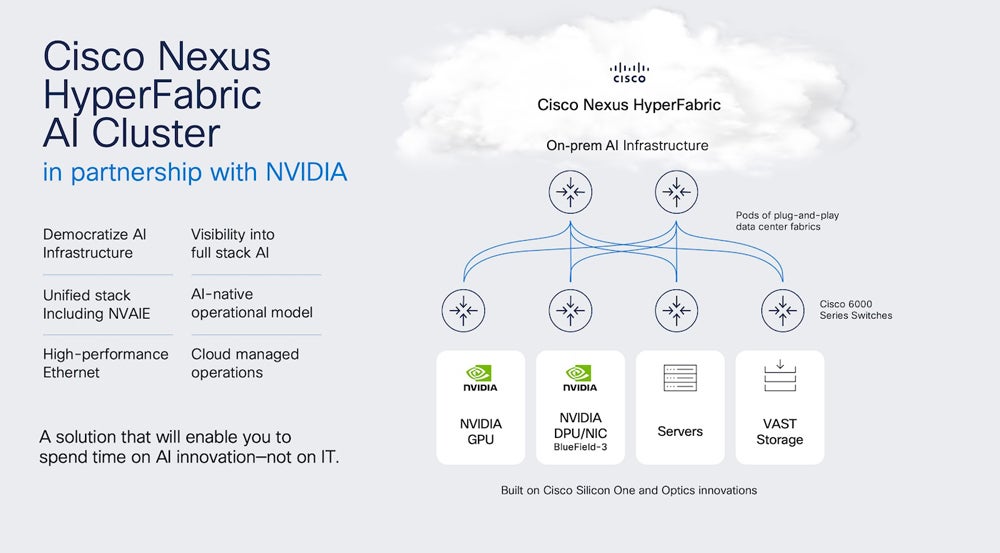
Apart from these investments, NVIDIA is collaborating with Cisco to enable enterprise generative AI infrastructure and ensure optimal performance of these models. Cisco’s new Nexus HyperFabric AI cluster solution, created in partnership with NVIDIA, offers a pathway for enterprises to operationalise generative AI using NVIDIA’s hardware.
The Cisco HyperFabric solution is an enterprise-ready, end-to-end infrastructure solution designed to scale generative AI workloads. This sounds eerily similar to the approach that Databricks and Snowflake are taking for providing infrastructure for LLM training and deployment.
According to Cisco corporate development SVP Derek Idemoto, the company considers several factors before making investments. The first question they ask is, “Does it address the real and evolving needs of our diverse customer base?”
“Put simply, we connect and protect the AI era. Only Cisco brings together extensive experience with AI-scale infrastructure and domain expertise in building AI across networking, security, and observability,” said Idemoto.
For Cisco, AI Has Always Been Big Because It Has Always Been a Data Company
Robbins said in the keynote that AI is moving at an unprecedented pace and generative AI is “coming on the scene very quickly.” Comparing it with the cloud boom, Robbins said, “I think AI is going to be that on steroids.”
Over the past few years, Cisco has actively integrated AI into its products. Webex initially spearheaded this effort by introducing features such as background noise removal, live transcripts, and meeting insights.
Since then, AI has significantly enhanced Cisco’s security offerings, highlighted by the launch of Hypershield around the RSA Conference 2024. Additionally, Cisco has rolled out AI assistants to help administrators better manage infrastructure.
Moreover, Cisco has also announced its partnership with Tech Mahindra in delivering next-generation firewall (NGFW) modernisation for customers and its workforce. Just recently, Lenovo also collaborated with Cisco to jointly design and engineer integrated products focused on networking, purpose-built AI infrastructure, and generative AI solutions.
Despite having a comprehensive AI strategy that spans its entire portfolio, the integration remains incomplete. By combining its network, observability, and security telemetry with Splunk data, Cisco could leverage a broader dataset to power its AI projects. Data has been one of the biggest parts of Cisco, and now, with NVIDIA and others, the company is going to bet big on generative AI with its unique data.
Earlier this year, Robbins appointed Mark Patterson as the company’s chief strategy officer, tasked with shaping Cisco’s overarching AI narrative. While it is unrealistic to expect Patterson to have all the answers immediately, we can anticipate valuable insights into the company’s future direction.
This strategic focus on AI is crucial for Cisco, as it will be integral to its customers’ AI journeys.
The post “Oh, Another Billion Dollars,” Chuck Robbins Says Cisco’s AI Strategy is Different appeared first on AIM.