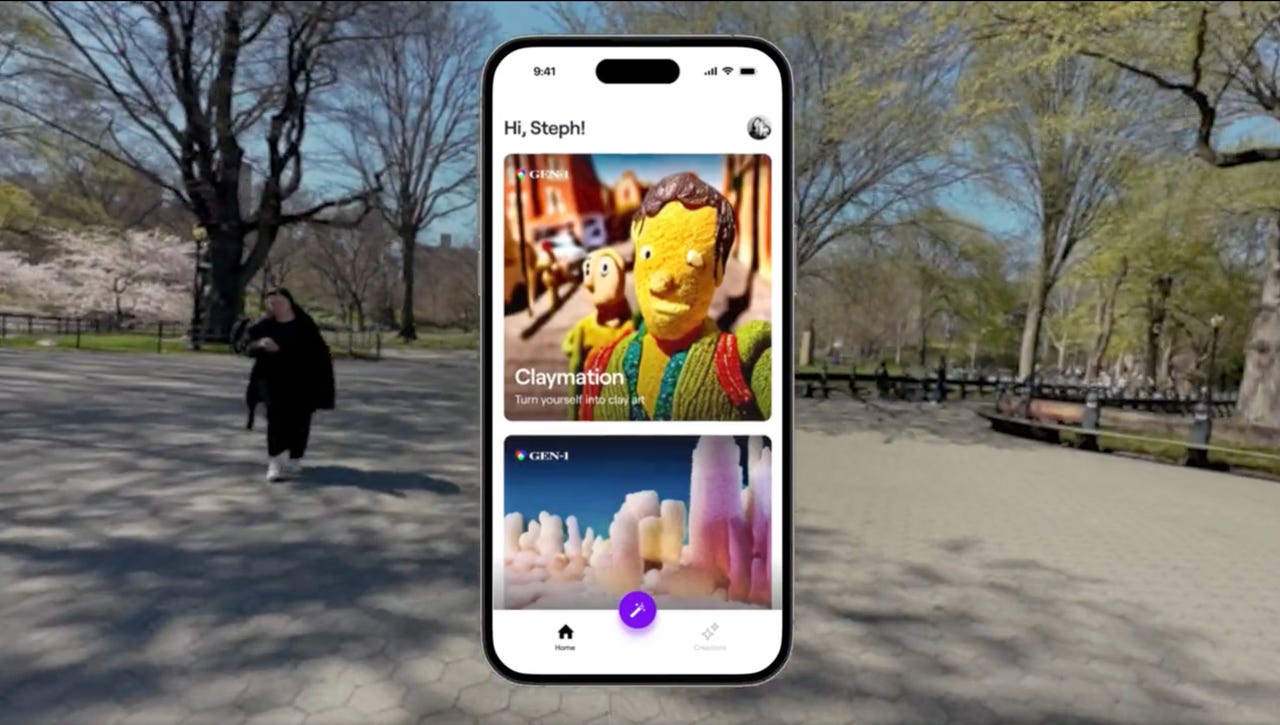
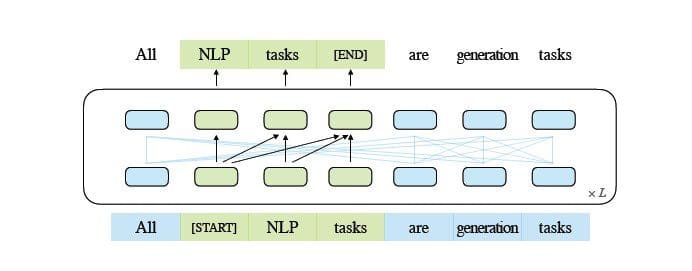
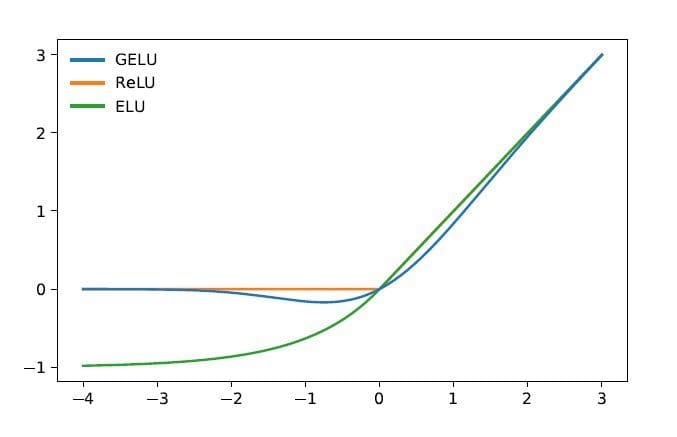
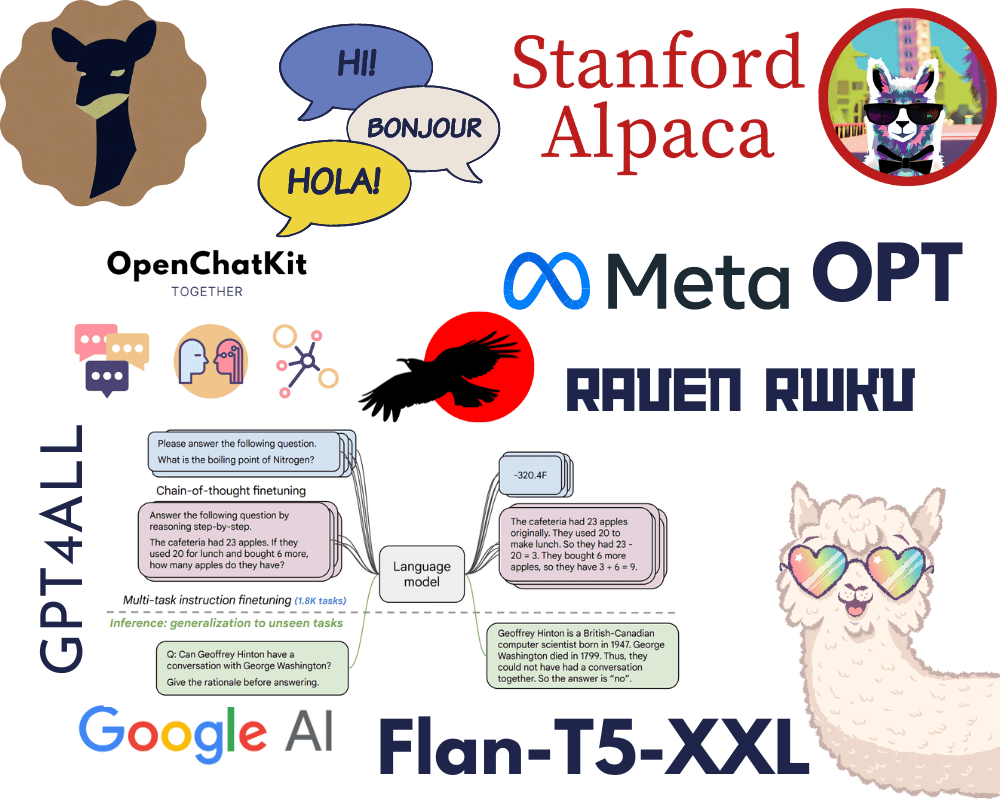
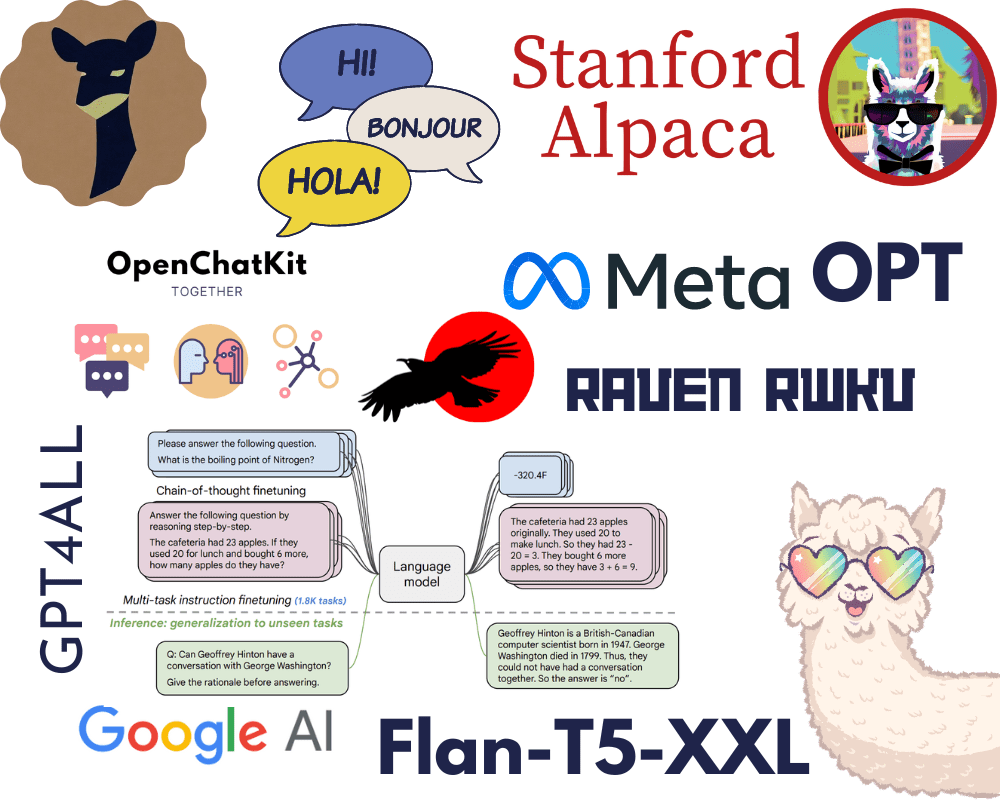
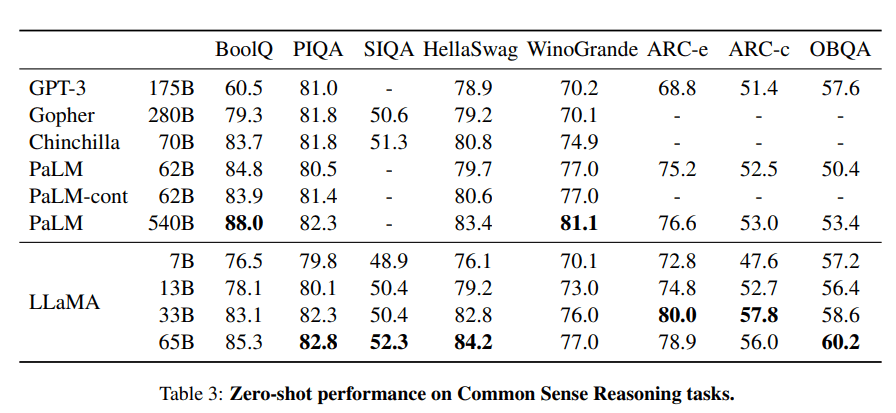
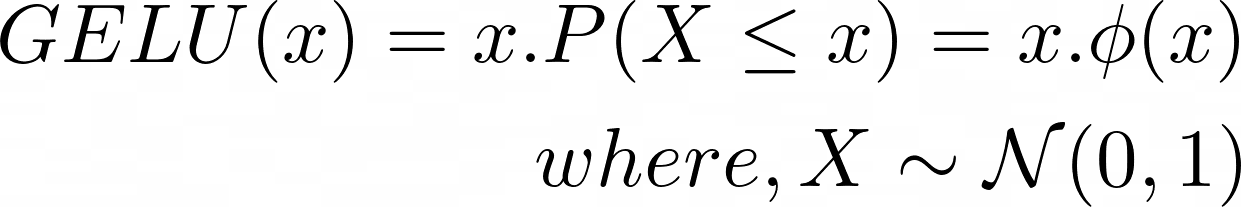Image by Author
Times are changing. If you want to be a data scientist in 2023, there are several new skills you should add to your roster, as well as the slew of existing skills you should have already mastered.
Why such an extensive set of skills? Part of the problem is job scope creep. Nobody knows what a data scientist is, or what one should do, least of all your future employer. So anything that has data gets stuck in the data science category for you to deal with.
You’re expected to know how to clean, transform, statistically analyze, visualize, communicate, and predict data. Not only that but new technology (or technology that has recently reached the mainstream) could also be added to your job responsibilities.
In this article, I’ll break down the top 19 skills you need to know in 2023 to be a data scientist.
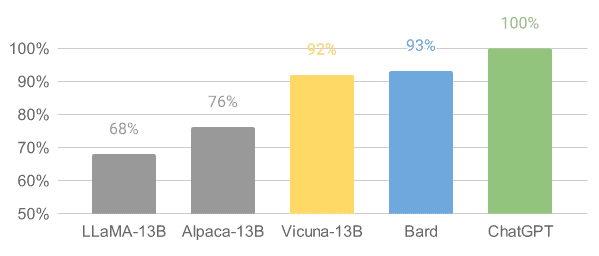
Here’s an overview of the ten most important.
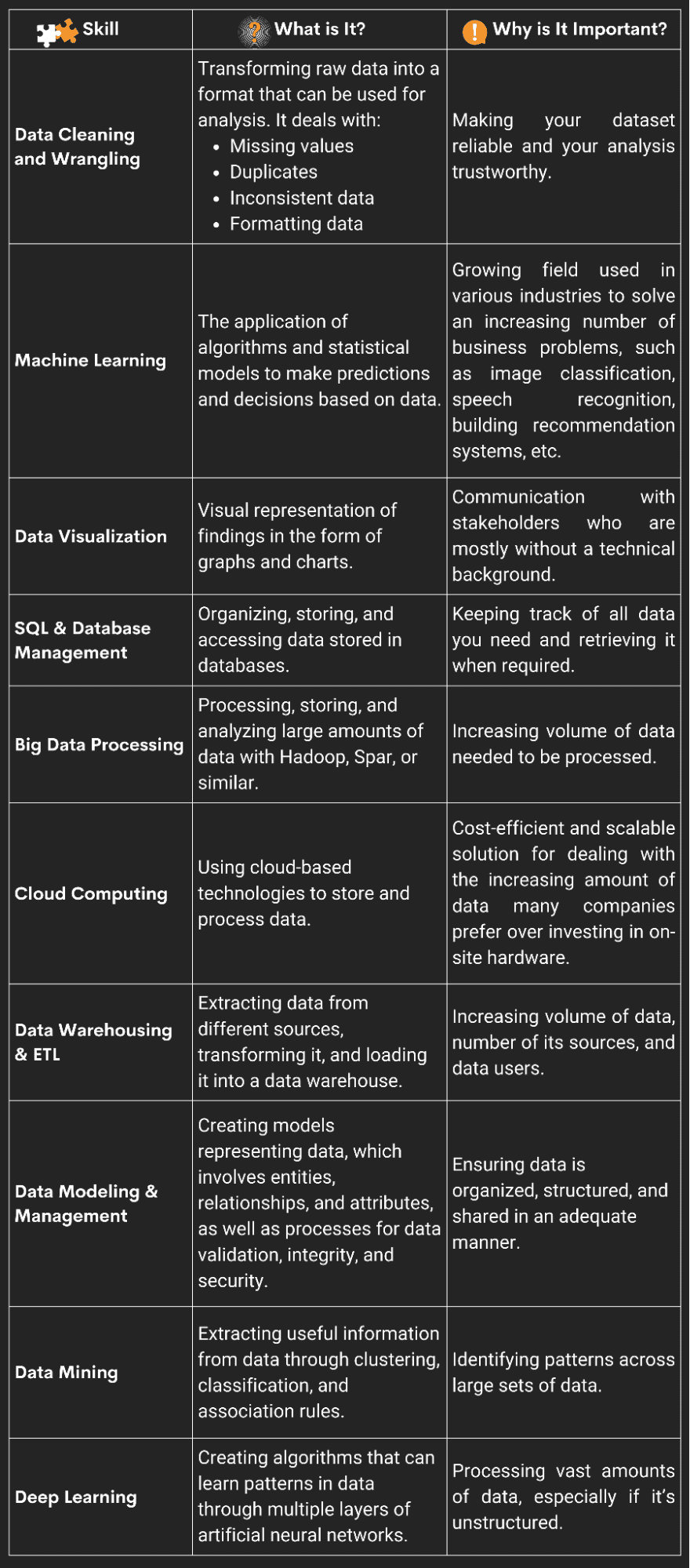
Image by Author
These skills will help you land a job, crush an interview, stay ahead of the curve, and negotiate for that promotion. In each section, I’ll briefly summarize what each skill is, why it matters, and offer a few places to learn these skills.
1. Data Cleaning and Wrangling
While it’s not 80% of a data scientist’s job, data cleaning and wrangling are still one of the most important skills a data scientist can master in 2023.
What is Data Cleaning and Wrangling?
Data cleaning and wrangling are the processes of transforming raw data into a format that can be used for analysis. This involves handling missing values, removing duplicates, dealing with inconsistent data, and formatting the data in a way that makes it ready for analysis.
Cleaning the data usually refers to getting rid of bad/inaccurate values, filling in any blanks, finding duplicates, and otherwise making sure your data set is as spotless and reliably accurate as can be expected. Wrangling it (or munging it, massaging it, or any other weird verb like that) means getting it into an analyzable shape. You convert it or map it into another, easier-to-look-at-format.
Why Does it Matter in Becoming a Data Scientist in 2023?
Ask any data scientist what they do, and one of the first things they mention will be data cleaning and wrangling. Data never comes into your hands in a nice, clean, analyzable shape, so it’s super important to know how to get it tidy.
The ability to clean and wrangle data ensures that your analysis results are trustworthy, and helps to avoid incorrect conclusions being drawn.
Where Can You Learn This Key Skill?
There are plenty of great options to learn data cleaning and wrangling. Harvard offers a course on EdX. You can also practice on your own by cleaning and wrangling free, raw datasets like the Common Crawl, web crawl data composed of over 50 billion web pages (here), or Brazil’s weather data (here).
2. Machine Learning
No, it’s not just a buzzword! Machine learning is a very important skill for any future data scientist to know.
What is Machine Learning?
Machine learning is the application of algorithms and statistical models to make predictions and decisions based on data.
It’s a subfield of artificial intelligence that enables computers to improve their performance on a specific task by learning from data, without being explicitly programmed. It helps with automation. You’ll find it in any industry.
Why Does It Matter in Becoming a Data Scientist in 2023?
You need to know about machine learning in 2023 because it’s a rapidly growing field that has become a crucial tool for solving complex problems and making predictions in various industries.
Machine learning algorithms can be used to classify images, recognize speech, do natural language processing, and create recommendation systems. You’ll be hard-pressed to find an industry that doesn’t do (or doesn’t want to) do those ML-assisted tasks.
Being proficient in machine learning allows a data scientist to extract valuable insights from large and complex data sets, and to develop predictive models that can drive better business decisions.
Where Can You Learn This Key Skill?
We’ve got a repository of over thirty machine-learning projects on ScrataScratch to show this skill off on your resume. TensorFlow also has a set of great free resources to learn machine learning.
3. Data Visualization 
Image by Author
This skill is pretty self-explanatory. When you analyze numbers, key stakeholders will want to understand your findings with pretty graphs and charts.
What is Data Visualization?
Data visualization is the creation of charts, graphs, and other graphics to help make data easier to understand. You take the numbers you’ve just cleaned, wrangled, or predicted and you put them into some kind of visual format, either to communicate trends with others or to make trends easier to spot.
Why Does it Matter in Becoming a Data Scientist in 2023?
In 2023, being able to visualize data is crucial for a data scientist. It's like having a secret superpower for uncovering hidden patterns and trends in the data that might not be obvious at first glance. And the best part? You get to share your findings with others in a way that's both engaging and memorable. As a data scientist, you’ll work with groups of all different experience levels, but a picture is much more easily understood than a row of numbers.
So, if you want to be a data scientist who can effectively communicate your insights and discoveries, it's important to master the art of data visualization.
Where Can You Learn This Key Skill?
Here’s a list of free places to learn data viz.
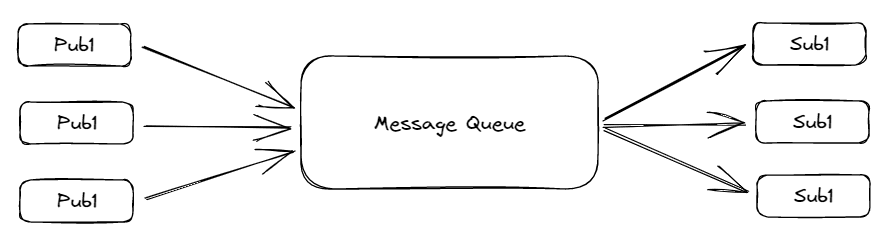
4. SQL & Database Management
SQL is a Structured Query Language. Data scientists use SQL to work with SQL databases as well as manage databases and perform data storage tasks.
What is SQL and Database Management?
SQL is a very popular language that lets you access and manipulate structured data. It goes hand in hand with database management, which is commonly done in SQL. Database management is basically how you can organize, store, and fetch data from a place. SQL databases are one of the top backend technologies to learn in 2023, so it’s not just for data science.
Why Does It Matter in Becoming a Data Scientist in 2023?
As a data scientist, you have to keep track of all the data, make sure it's organized, and retrieve it when someone needs it. That’s what SQL and database management let you do.
Where Can You Learn This Key Skill?
Coursera has a ton of great, well-priced database management/admin courses you can try. You can also get a sneak preview of some SQL interview questions here, which can be useful for testing your knowledge.
5. Big Data Processing
Big data is a buzzword, yes, but it’s also a real concept — Oracle defines it as “data that contains greater variety, arriving in increasing volumes and with more velocity,” or data with the three V’s.
What is Big Data Processing?
Big data processing is the ability to process, store, and analyze large amounts of data using technologies like Hadoop and Spark.
Why Does It Matter in Becoming a Data Scientist in 2023?
In 2023, the ability to process big data is critical for data scientists. The volume of data being generated continues to grow at an exponential rate, and being able to handle and analyze this data effectively is essential for making informed decisions and gaining valuable insights. Data scientists who have a deep understanding of big data processing techniques will be able to work with large data sets with ease and make the most out of the information they contain.
Also, thanks to its buzz-wordiness, it never hurts to whack “big data” on your resume.
Where Can You Learn it?
I love Simplilearn’s YouTube tutorial series on this concept.
6. Cloud Computing 
Image by Author
It’s funny – as more products and services move into the cloud, cloud computing becomes a job requirement for pretty much every techy job, whether it’s DevOps or a data scientist.
What is Cloud Computing?
Cloud computing is the use of cloud-based technologies and platforms like AWS, Azure, or Google Cloud to store and process data. It’s kind of like having a virtual storage room that you can access from anywhere at any time. Instead of storing data and computing resources on local machines or servers, cloud computing allows organizations – and data scientists – to access these resources through the internet.
Why Does It Matter in Becoming a Data Scientist in 2023?
As I keep highlighting, the amount of data you’re expected to work with as a data scientist is growing. More companies will be sticking it in the cloud rather than dealing with it on-prem. It's becoming increasingly important to have the ability to store and process this data in a scalable and efficient manner.
Cloud computing provides an effective solution for this, allowing data scientists to access vast amounts of computing resources and data storage without needing pricy hardware and infrastructure.
Where Can You Learn It?
The good news is because companies own various clouds, many of them have a vested interest in teaching you about it for free, so you learn to use theirs. Google, Microsoft, and Amazon all have great cloud computing resources.
7. Data Warehousing & ETL
“Wait, didn’t we just cover databases? What’s a data warehouse?” I hear you ask.
I get you. Sometimes it feels like the most critical data science skill is keeping all the acronyms and jargon straight.
What Are Data Warehousing and ETL?
First, let’s differentiate data warehouses from databases.
Warehouses store current and historical data for multiple systems, while databases store current data needed to power a project. A database stores the current data required to power an application whereas a data warehouse stores current and historical data for one or more systems in a predefined and fixed schema to analyze the data.
In short, you’d use a data warehouse for data for lots of different projects together, whereas a database mostly stores one single project’s data.
ETL is a process that involves data warehousing, short for extract, transform, and load. An ETL tool will extract data from any data source systems you want, transform it in the staging area (usually cleaning, manipulating, or “munging” it), and then load it into a data warehouse.
Why Does It Matter in Becoming a Data Scientist in 2023?
I feel like I’ve repeated this point in every skill, but data is growing. Companies are hungry for it, and they’ll expect you to manage it. Knowing how to manage data in buildable pipelines is critical.
Where Can You Learn It?
I recommend learning how to do a proper ETL with a specific language, like SQL or Python. Datacamp has got a good one with Python. Microsoft runs a more intermediate-level tutorial to go through a SQL option.
8. Data Modeling & Management
Every data scientist is a model specialist. I’m not talking about Giselle Bundchen. I mean creating a model of how data is stored and organized in a system.
What is Data Modeling And Management?
Data modeling and management is the process of creating mathematical models to represent data, as well as the management of data to maintain its quality, accuracy, and usefulness.
This involves defining data entities, relationships, and attributes, as well as implementing processes for data validation, integrity, and security.
In simpler terms, data modeling basically means you’re creating a blueprint for how data is organized and connected in your employer’s systems. You can think of it like drafting a blueprint of a house. Just like a blueprint shows the different rooms and how they're connected, data modeling shows how different pieces of information are related and connected to each other.
This helps ensure that data is stored and used in a consistent and effective way.
Why Does It Matter in Becoming a Data Scientist in 2023?
As a data scientist, you’ll be responsible for making sure data is organized and structured in an accessible way. Data modeling and management help you work with data, share it, make sure it’s accurate, and make decisions based on it.
Where Can You Learn It?
Microsoft has a good intro on their blog, just half an hour long and highly rated. It’s a good place to start.
9. Data Mining 
Image byt Author
Many data science terms have just been robbed from other professions, like modeling and mining. Let’s get into what it means and why it matters.
What is Data Mining?
Data mining is the process of extracting useful information from data through techniques like clustering, classification, and association rules. You’re sifting through the veritable flood of data to find useful golden nuggets. (Maybe data panning would have been a better name for this skill!)
Why Does It Matter in Becoming a Data Scientist in 2023?
Imagine it: you’re a data scientist in 2023. You have data coming in from ten thousand different sources. What skill do you use to identify patterns across all these data fountains?
It’s data mining.
Where Can You Learn It?
Data mining is typically covered in courses that cover big data or data analytics since it’s a pretty critical component of those two skills. EdX offers a couple of options to learn data mining.
10. Deep Learning
Deep learning is subtly different from machine learning! Deep learning is a subfield of machine learning.
What is Deep Learning?
Deep learning is a facet of machine learning that focuses on creating algorithms that can learn patterns in data through multiple layers of artificial neural networks. (Artificial neural networks, by the way, are a type of machine learning algorithm modeled to be similar to the structure and function of the human brain.)
Why Does It Matter in Becoming a Data Scientist in 2023?
Artificial intelligence is getting more sophisticated in 2023. It’s not enough to know the basics of AI and ML – you should be familiar with the cutting edge, too, because it won’t be cutting edge tomorrow. Deep learning was novel a few years ago, and now it’s a necessity.
Data scientists will be expected to use deep learning when companies have access to a truly vast amount of data. It’s used for image and video processing, or computer vision applications.
Where can you learn it?
I like Simplilearn’s tutorial as a starting point.
What Other Skills Do You Need to Know to Become a Data Scientist in 2023?
There are plenty of up-and-coming technologies and techniques that are useful to know. These are either even more advanced, like generative adversarial networks, or more soft-skills-based, like data storytelling, or specialized to a field like time series forecasting. I’ll briefly summarize these here:
- Natural Language Processing (NLP): A subfield of AI that handles processing and understanding of human language. Chatbots use this.
- Time Series Analysis & Forecasting: The study of data over time and the use of statistical models to make predictions about future events. You might use this skill to do sales or revenue analysis.
- Experimental Design & A/B Testing: The process of designing and conducting controlled experiments to test hypotheses and make decisions based on data.
- Data Storytelling: The ability to effectively communicate data insights and findings to non-technical stakeholders. More and more stakeholders are taking an interest in the why behind data-based decisions, so this is critical.
- Generative Adversarial Networks (GANs): A type of deep learning architecture where two neural networks are trained to work together to generate new data that resembles a given dataset.
- Transfer Learning: A machine learning technique where a model is pre-trained on one task and is fine-tuned on a related task, improving performance and reducing the amount of training data needed. Smaller companies that are more resource-limited will find this useful.
- Automated Machine Learning (AutoML): A method of automating the process of selecting, training, and deploying machine learning models.
- Hyperparameter Tuning: Another ML subcategory. This is the process of optimizing the performance of a machine learning model by adjusting the parameters that are not learned from the data, such as the learning rate or the number of hidden layers.
- Explainable AI (XAI): A branch of AI focused on creating algorithms and models that are transparent and interpretable, so their decision-making processes can be understood by humans. Again, helping stakeholders understand what’s happening.
If you want to be a data scientist in 2023, these 19 skills are absolutely critical. The really great news is that many of these skills can be self-taught, while others you can pick up while working in a more junior-level role like a data or business analyst.
A few ways to learn:
- Always check YouTube. There are so many free, comprehensive resources. I’ve listed a few here, but there are practically infinite videos out there.
- Platforms like Coursera and EdX often have lecture series
- We’ve got over a thousand real interview questions to practice on, both coding-based and non-coding. We also offer data project examples.
Enjoy the journey of learning these skills to become a data scientist in 2023.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.
More On This Topic
- Modern Data Science Skills: 8 Categories, Core Skills, and Hot Skills
- Top 13 Skills That Every Data Scientist Should Have
- 7 Most Recommended Skills to Learn to be a Data Scientist
- KDnuggets™ News 20:n34, Sep 9: Top Online Data Science Masters…
- 3 Valuable Skills That Have Doubled My Income as a Data Scientist
- 5 Machine Learning Skills Every Machine Learning Engineer Should Know in…