Using a fraction of the GPU compute, Meta's CM3Leon achieves images with complex combinations of objects, and hard-to-render things like hands and text, and at a level that achieves a new state of the art on the benchmark FID score.
For the past several years, the world has been wowed by artificial intelligence programs that generate images when you type a phrase, programs such as Stable Diffusion and DALL*E that will output images in any style you want and that can be subtly varied by using different prompted phrases.
Typically, those programs have relied on manipulating example images by performing a process of compression on the example images, and then de-compressing them to recover the original, whereby they learn the rules of image creation, a process referred to as diffusion.
Also: Generative AI: Just don't call it an 'artist' say scholars in Science magazine
Work by Meta introduced this past week suggests something far simpler: an image can be treated as merely a set of codes like words, and can be handled much the way ChatGPT manipulates lines of text.
It might be the case that language is all you need in AI.
The result is a program that can handle complex subjects with multiple elements ("A teddy bear wearing a motorcycle helmet and cape is riding a motorcycle in Rio de Janeiro with Dois Irmãos in the background.") It can render difficult objects such as hands and text, stuff that tends to end up distorted in many image-generation programs. It can perform other tasks, like describing in detail a given image, or altering a given image with precision. And it can be done with a fraction of the computing power usually needed.
In the paper "Scaling Autoregressive Multi-Modal Models: Pre-training and Instruction Tuning," by Lilu Yu and colleagues at Facebook AI Research (FAIR), posted on Meta's AI research site, the key insight is to use images as if they were words. Or, rather, text and image function together as continuous sentences using a "codebook" to replace the images with tokens.
"Our approach extends the scope of autoregressive models, demonstrating their potential to compete with and exceed diffusion models in terms of cost-effectiveness and performance," write Yu and team.
Also: This new technology could blow away GPT-4 and everything like it
The idea of a codebook goes back to work from 2021 by Patrick Esser and colleagues at Heidelberg University. They adapted a long-standing kind of neural network, called a convolutional neural network (or CNN), which is expert at handling image files. By training an AI program called a generative adversarial network, or GAN, which can fabricate images, the CNN was made to associate aspects of an image, such as edges, with entries in a codebook."
Those indices can then be predicted the way words in a language model such as ChatGPT predicts the next word. High-resolution images become sequences of index predictions rather than pixel prediction, which is a far less compute-intense operation.
CM3Leon's input is a string of tokens, where images are reduced to just another token in text form, a reference to a codebook entry.
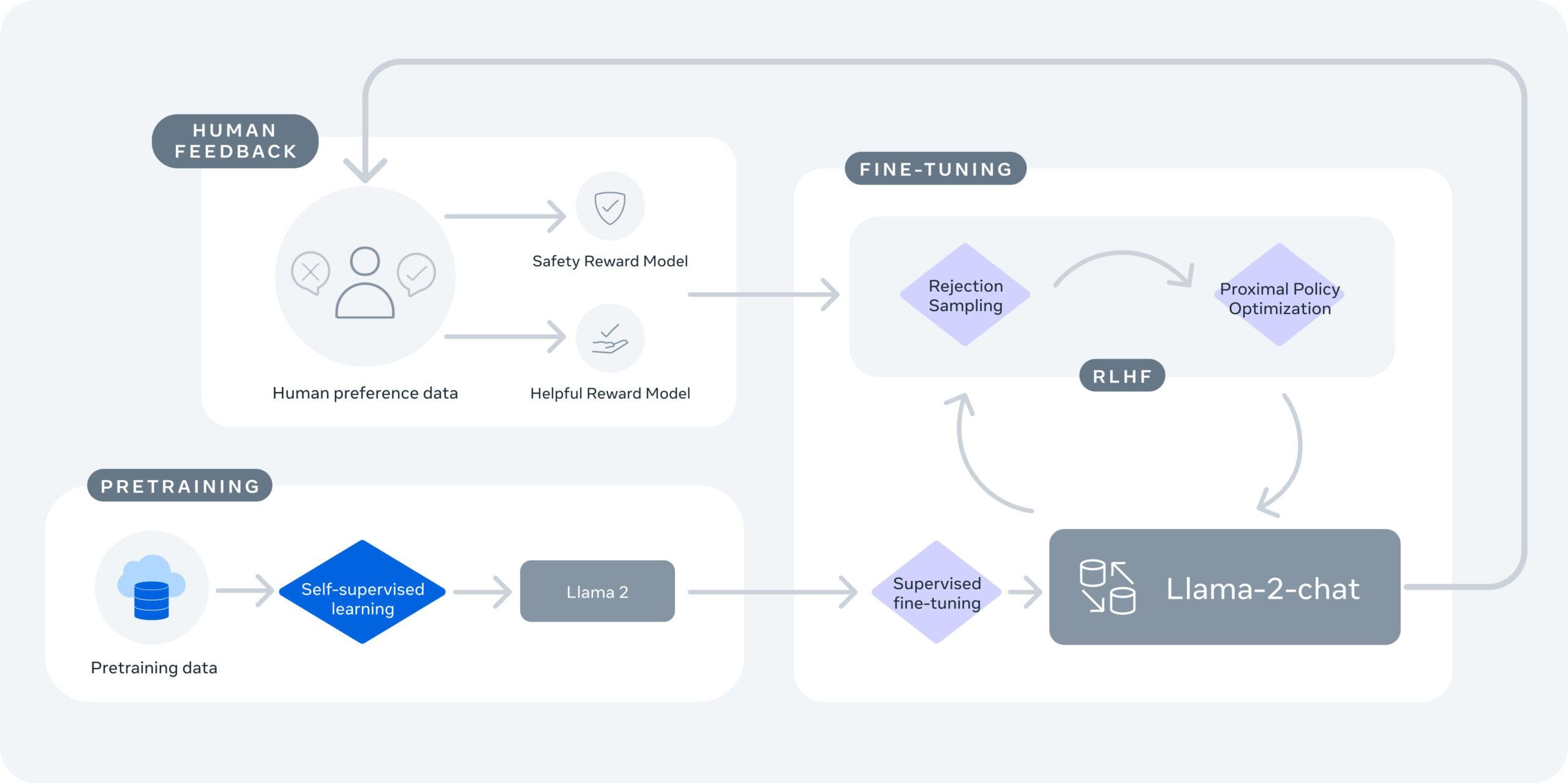
Using the codebook approach, Meta's Yu and colleagues assembled what's called CM3Leon, pronounced "chameleon," a neural net that is a large language model able to handle an image codebook.
CM3Leon builds on a prior program that was introduced last year by FAIR — CM3, for "Causally-Masked Multimodal Modeling." It's like ChatGPT in that it is a "Transformer"-style program, trained to predict the next element in a sequence — a "decoder-only transformer architecture" — but it combines that with "masking" parts of what's typed, similar to Google's BERT program, so that it can also gain context from what might come later in a sentence.
CM3Leon builds on CM3 by adding to it what's called retrieval. Retrieval, which is becoming increasingly important in large language models, means the program can "phone home," if you will, to reach into a database of documents and retrieve what may be relevant as the output of the program. It's a way to have access to memory so that the neural net's weights, or parameters, don't have to bear the burden of carrying all the information necessary to make predictions.
Also: Microsoft, TikTok give generative AI a sort of memory
According to Yu and team, their database is a vector "data bank" that can be searched for both image and text documents: "We split the multi-modal document into a text part and an image part, encode them separately using off-the-shelf frozen CLIP text and image encoders, and then average the two as a vector representation of the document."
In a novel twist, the researchers use as the training dataset not internet images but a collection of 7 million licensed images from Shutterstock, the stock photography company. "As a result, we can avoid concerns related to image ownership and attribution, without sacrificing performance."
The Shutterstock images retrieved from the database are used in the pre-training stage of CM3Leon to develop the capabilities of the program. It's the same way ChatGPT and other large language models are pre-trained. But, an extra stage then takes place whereby the input and output of the pre-trained CM3Leon are both fed back into the model to further refine it, an approach called "supervised fine-tuning," or SFT.
Also: The best AI art generators: DALL-E 2 and other fun alternatives to try
The result of all this is a program that achieves the state of the art for a variety of text-image tasks. Their primary test is Microsoft COCO Captions, a dataset published in 2015 by Xinlie Chen of Carnegie Mellon University and colleagues. A program is judged by how well it replicates images in the dataset, according to what's called an FID score, a resemblance measure that was introduced in 2018 by Martin Heusel and colleagues at Johannes Kepler University Linz in Austria.
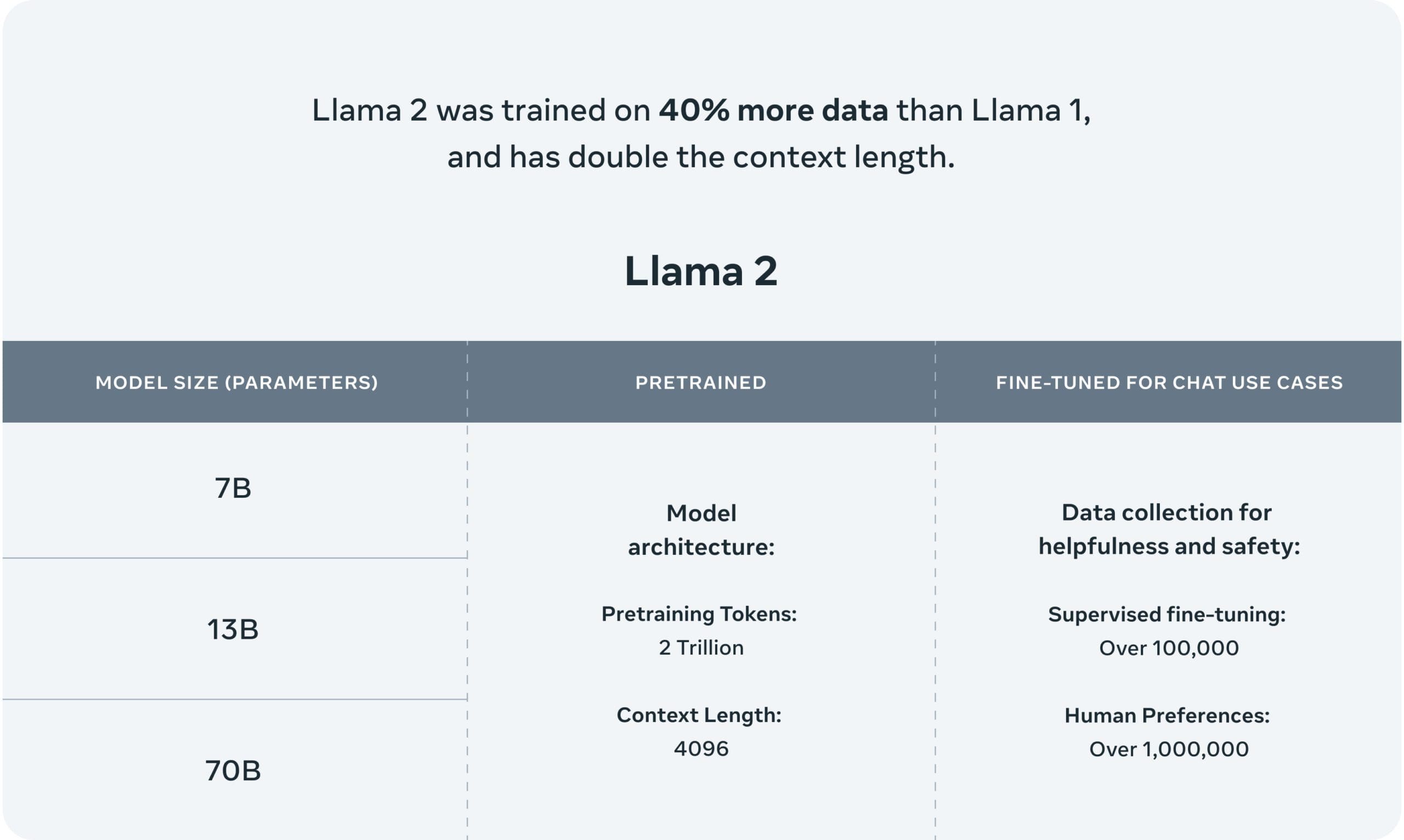
Write Yu and team: "The CM3Leon-7B model sets a new state-of-the-art FID score of 4.88, while only using a fraction of the training data and compute of other models such as PARTI." The "7B" part refers to the CM3Leon program having 7 billion neural parameters, a common measure of the scale of the program.
A table shows how the CM3Leon model gets a better FID score (lower is better) with far less training data, and with fewer parameters than other models, which is the same as saying less compute intensity:
One chart shows how the CM3Leon reaches that superior FID score using fewer training hours on Nvidia A100 GPUs:
What's the big picture? CM3Leon, using a single prompted phrase, can not only generate images but can also identify objects in a given image, or generate captions from a given image, or do any number of other things juggling text and image. It's clear that the wildly popular practice of typing stuff into a prompt is becoming a new paradigm. The same gesture of typing can be broadly employed for many tasks with lots of "modalities," meaning, different kinds of data — image, sound, audio, etc.
Also: This new AI tool transforms your doodles into high-quality images
As the authors conclude, "Our results support the value of autoregressive models for a broad range of text and image tasks, encouraging further exploration for this approach."