Image from Midjourney
As a data scientist, I’m always looking for ways to maximize efficiency and drive business value with data.
So when ChatGPT released one of its most powerful features yet?—?the Code Interpreter plugin, I simply had to try and incorporate it into my workflows.
What is ChatGPT Code Interpreter?
If you haven’t already heard about Code Interpreter, this is a new feature that allows you to upload code, run programs, and analyze data within the ChatGPT interface.
For the past year, every time I’ve had to debug code or analyze a document, I’d have to copy my work and paste it into ChatGPT to get a response.
This proved to be time-consuming and the ChatGPT interface has a character limit, which restricted my ability to analyze data and execute machine learning workflows.
The Code Interpreter solves all these issues by allowing you to upload your own datasets onto the ChatGPT interface.
And although it’s called the “Code Interpreter,” this feature isn’t limited to programmers?—?the plugin can help you analyze text files, summarize PDF documents, build data visualizations, and even crop images according to your desired ratio.
How Can You Access Code Interpreter?
Before we get into its applications, let’s quickly go through how you can start using the Code Interpreter plugin.
To access this plugin, you need to have a paid subscription to ChatGPT Plus, which is currently at $20 a month.
Unfortunately, Code Interpreter hasn’t been made available to users who aren’t subscribed to ChatGPT Plus.
Once you have a paid subscription, simply navigate to ChatGPT and click on the three dots at the bottom-left of the interface.
Then, select Settings:
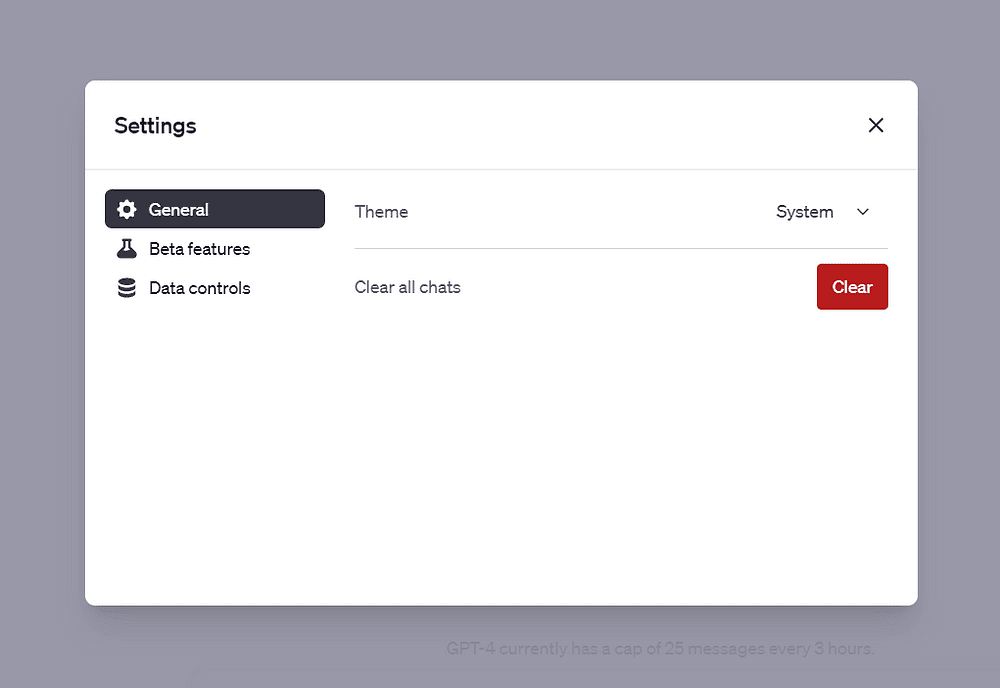
Image by Author
Click on “Beta features” and enable the slider that says Code Interpreter:
Image by Author
Finally, click on “New Chat”, select the “GPT-4” option, and select “Code Interpreter” on the drop-down that appears:
You will see a screen that looks like this, with a “+” symbol near the text box:

Image by Author
Great! You have now successfully enabled ChatGPT Code Interpreter.
In this article, I will show you five ways in which you can use Code Interpreter to automate data science workflows.
1. Data Summarization
As a data scientist, I spend a lot of time just trying to understand the different variables present in the dataset.
Code Interpreter does a great job at breaking down each data point for you.
Here’s how you can get the model to help you summarize data:
Let’s use the Titanic Survival Prediction dataset on Kaggle for this example. I am going to be using the “train.csv” file.
Download the dataset and navigate to Code Interpreter:
Image by Author
Click on the “+” symbol and upload the file you want to summarize.
Then, ask ChatGPT to explain all the variables in this file in simple terms:
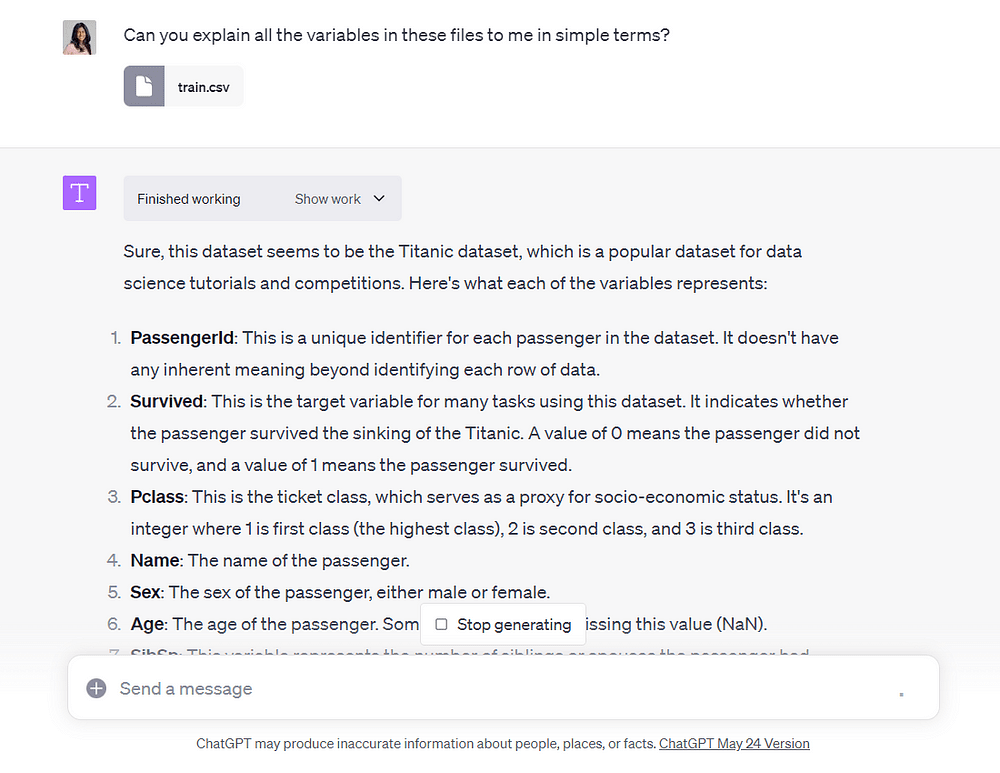
Image by Author
Voila!
Code Interpreter provided us with simple explanations of each variable in the dataset.
2. Exploratory Data Analysis
Now that we have an understanding of the different variables in the dataset, let’s ask Code Interpreter to go one step further and perform some EDA.
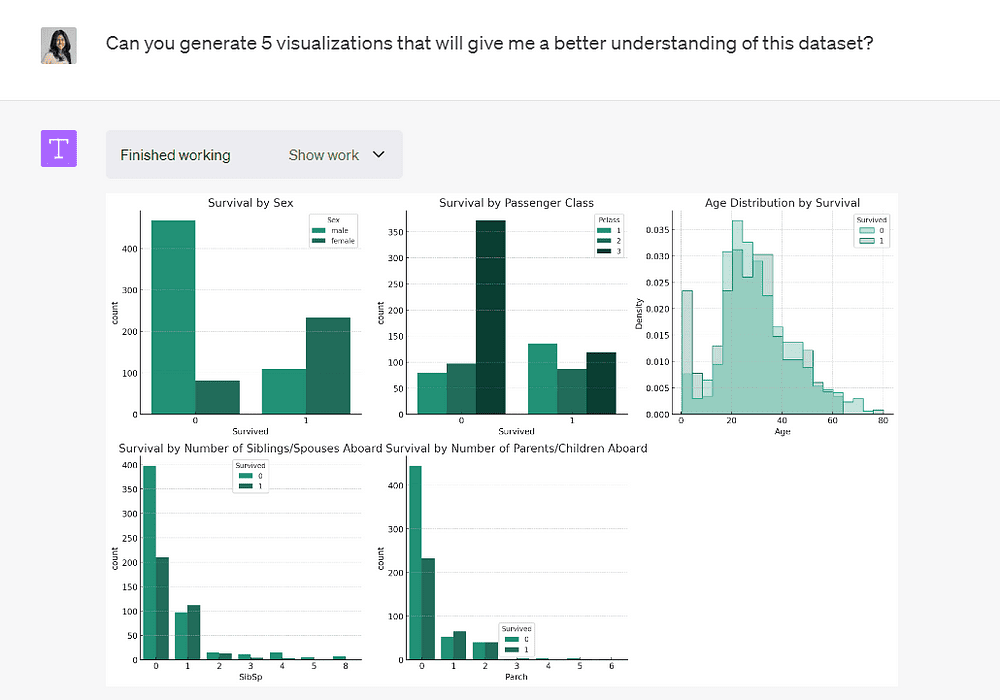
Image by Author
The model has generated 5 plots that allow us to better understand the different variables in this dataset.
If you click on the “Show work” drop-down, you will notice that Code Interpreter has written and run Python code to help us achieve the end result:
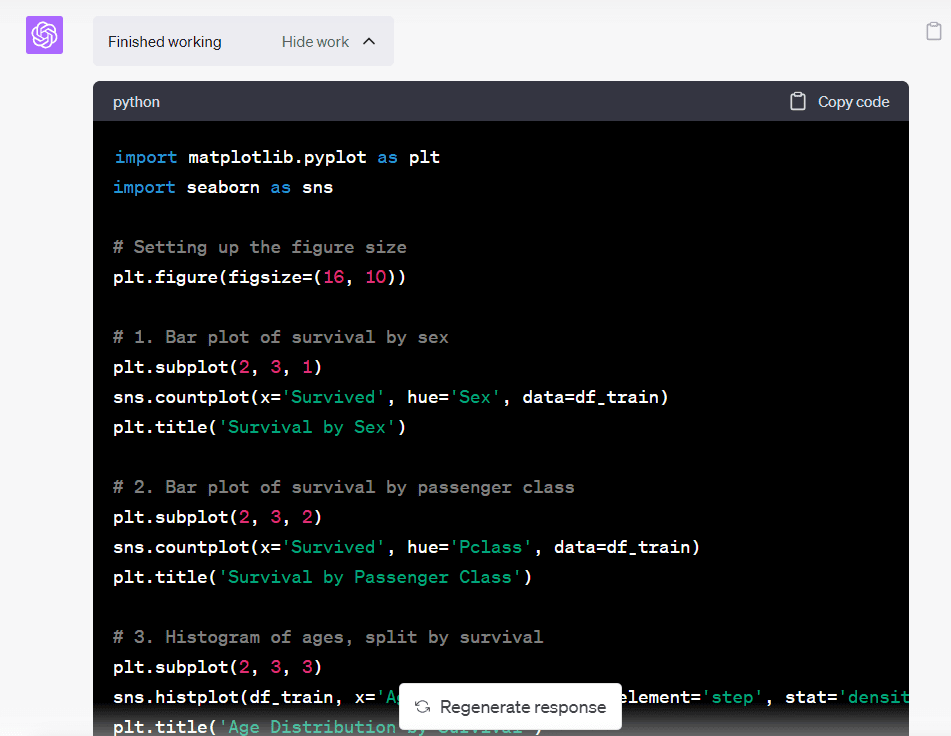
Image by Author
You can always copy-paste this code into your own Jupyter Notebook if you’d like to perform further analysis.
ChatGPT has also provided us with some insight into the dataset based on the visualizations generated:

Image by Author
It’s telling us that females, first-class passengers, and younger passengers had higher survival rates.
These are insights that would take time to derive by hand, especially if you aren’t well-versed with Python and data visualization libraries like Matplotlib.
Code Interpreter generated them in mere seconds, significantly reducing the amount of time consumed to perform EDA.
3. Data Preprocessing
I spend a lot of time cleaning datasets and preparing them for the modelling process.
Let’s ask Code Interpreter to help us preprocess this dataset:
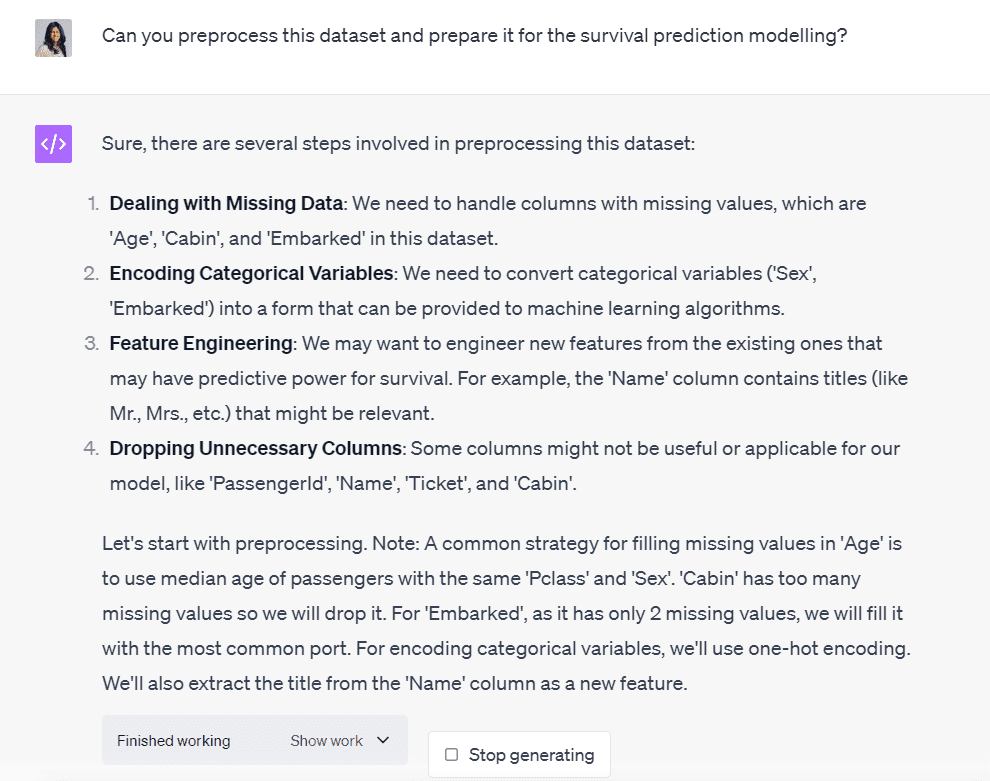
Image by Author
Code Interpreter has outlined all the steps involved in the process of cleaning this dataset.
It’s telling us that we need to handle three columns with missing values, encode two categorical variables, perform some feature engineering, and drop columns that are irrelevant to the modelling process.
It proceeded to create a Python program that did all the preprocessing in mere seconds.
You can click on “Show Work” if you’d like to understand the steps taken by the model to perform the data cleaning:
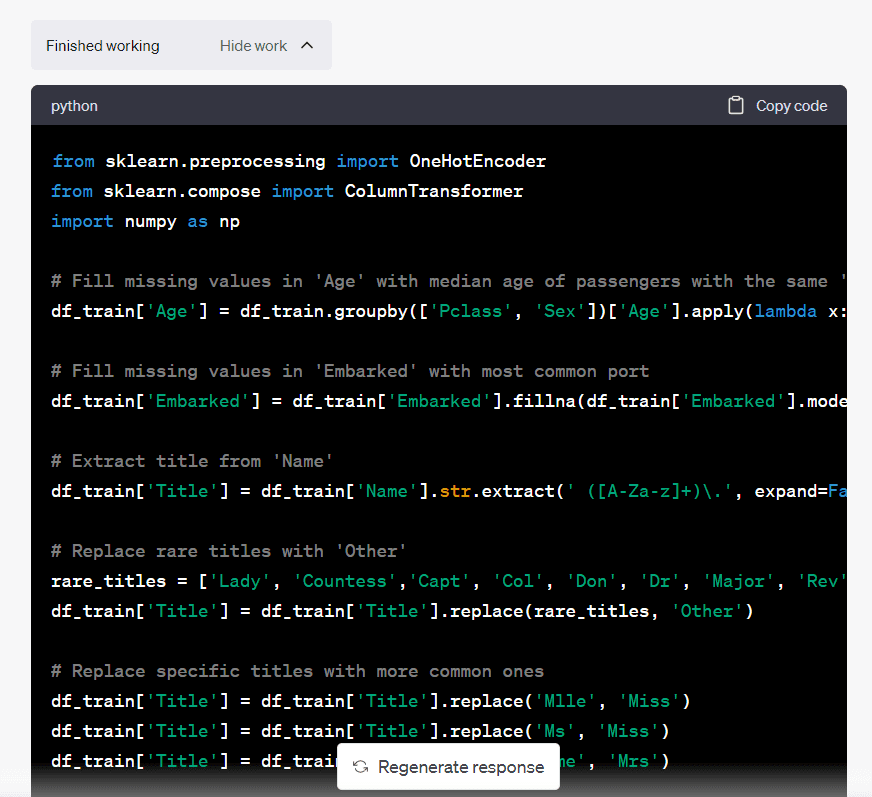
Image by Author
Then, I asked ChatGPT how I could save the output file, and it provided me with a downloadable CSV file:
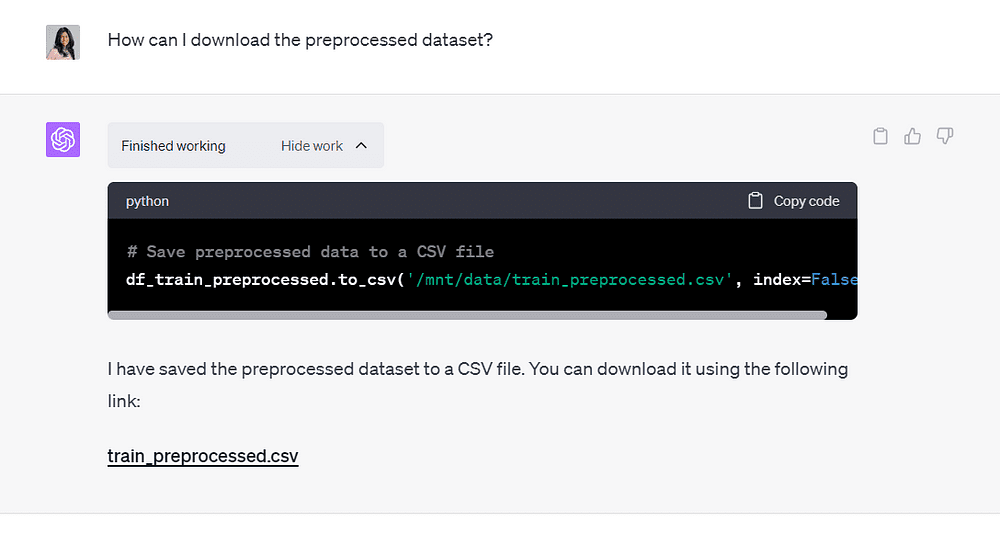
Image by Author
Note that I did not even have to run one line of code throughout this process.
Code Interpreter was able to ingest my file, run code within the interface, and provide me with the output in record time.
4. Building Machine-Learning Models
Finally, I asked Code Interpreter to use the preprocessed file to build a machine-learning model to predict whether a person would survive the Titanic shipwreck:
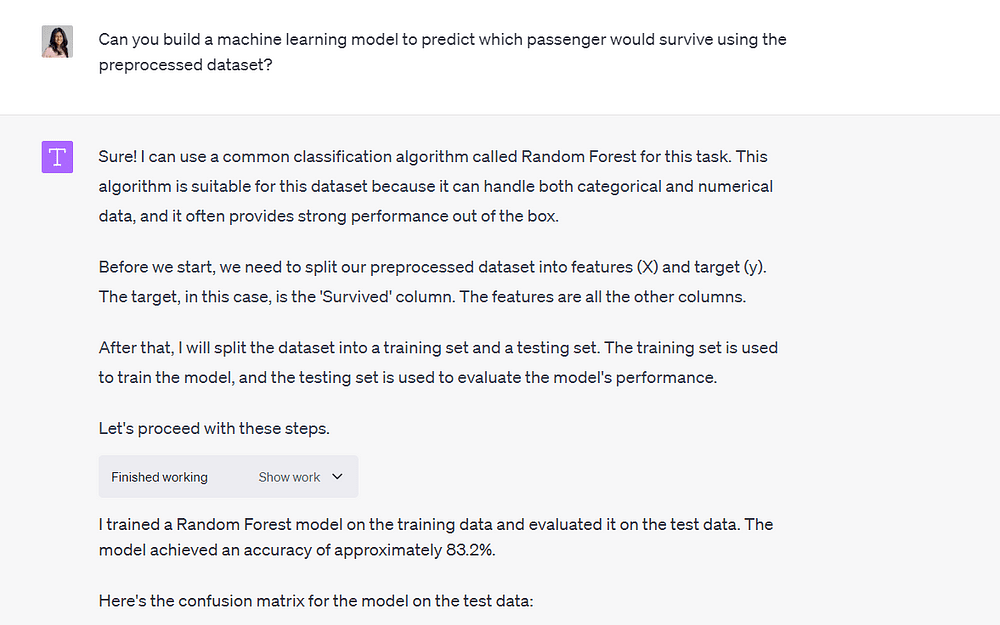
Image by Author
It built the model in under a minute and was able to reach an accuracy of 83.2%.
It also provided me with a confusion matrix and classification report summarizing model performance, and explained what all the metrics represented:

Image by Author
I asked ChatGPT to provide me with an output file mapping the model predictions with passenger data.
I also wanted a downloadable file of the machine learning model it created, since we can always perform further fine-tuning and train on top of it in the future:
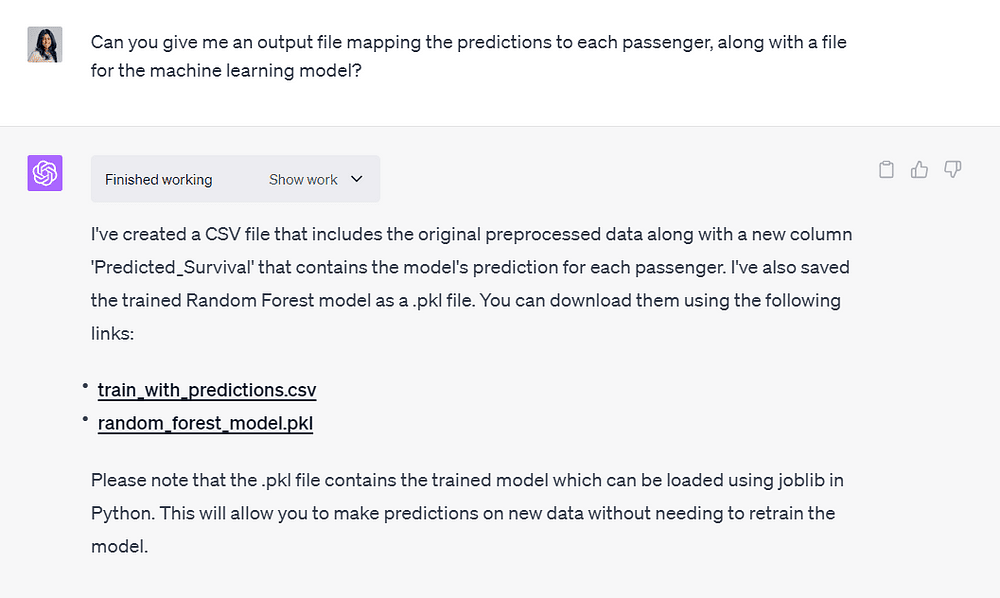
Image by Author 5. Code Explanations
Another application of Code Interpreter that I found useful was its ability to come up with code explanations.
Just the other day, I was working on a sentiment analysis model and found some code on GitHub that was relevant to my use case.
I didn’t understand the entire code, as the author had imported libraries I wasn’t familiar with.
With Code Interpreter, you can simply upload a code file and ask it to explain each line clearly.
You can also ask it to debug and optimize the code for better performance.
Here is an example?—?I uploaded a file containing code I wrote years ago to build a Python dashboard:

Image by Author
Code Interpreter broke down my code and clearly outlined what was done in each section.

Image by Author
It also suggested refactoring my code for better readability and explained where I could include new sections.
Instead of doing this myself, I simply asked Code Interpreter to refactor the code and provide me with an improved version:
Image by Author
Code Interpreter rewrote my code to encapsulate each visualization into separate functions, making it easier to understand and update.
What Does ChatGPT Code Interpreter Mean For Data Scientists?
There is a lot of hype around Code Interpreter right now, since this is the first time we are witnessing a tool that can ingest code, understand natural language, and perform end-to-end data science workflows.
However, it is important to keep in mind that this is just another tool that is going to help us do data science more efficiently.
So far, I’ve been using it to build baseline models on dummy data, since I’m not allowed to upload sensitive company information onto the ChatGPT interface.
Furthermore, Code Interpreter does not have domain-specific knowledge. I generally use the predictions it generates as baseline forecasts?—?I often have to tweak the output it generates to match my organization’s use case.
I cannot present the numbers generated by an algorithm that has no visibility into the inner workings of the company.
Finally, I don’t use Code Interpreter for every project, since some of the data I work with comprise millions of rows and reside in SQL databases.
This means that I still have to perform much of the querying, data extraction, and transformation by myself.
If you are an entry-level data scientist or aspire to become one, I’d suggest learning how to leverage tools like Code Interpreter to get the mundane parts of your job done more efficiently.
That’s all for this article, thanks for reading!
Natassha Selvaraj is a self-taught data scientist with a passion for writing. You can connect with her on LinkedIn.
More On This Topic
- Free ChatGPT Course: Use The OpenAI API to Code 5 Projects
- 7 Ways ChatGPT Makes You Code Better and Faster
- 7 Tips To Produce Readable Data Science Code
- How to Use ChatGPT to Improve Your Data Science Skills
- ChatGPT for Data Science Cheat Sheet
- ChatGPT for Data Science Interview Cheat Sheet