AI in the Cloud: Google, Microsoft, and Amazon’s Divergent Strategies August 1, 2023 by Agam Shah 
(Blue Planet Studio/Shutterstock)
There is no one way to buy AI services, but a few purchase models are emerging. One is like shopping for groceries: you can have it delivered to your doorstep or see options in a store and checkout with a customized experience.
The top cloud makers have distinctly different AI storefronts with responsive chatbots, image generators, and soon, multimodal models that can do everything. The difference is in the experience, tools and level of engagement customers want with their large-language models.
Microsoft and Google offer a mix of readymade AI models that companies can rent without wasting time on customizing and finetuning. Both companies have solid foundational models for which customers will have to pay a premium.
Amazon’s approach is to focus on tools and cloud services around third-party foundational models. AWS executives argue the hype around the size and type of models will slip away as AI goes mainstream. Amazon also wants to provide options so customers do not put all their eggs in one AI basket and can play around with models before selecting the best one that suits their needs.
Packaging the Cloud for AI
Decades ago, AI courses in universities talked about the concept of finding answers by recognizing patterns and trends in vast threads of data, resembling the functionality of the brain. Companies have developed vast repositories, but AI became possible only with GPUs and AI chips able to run complicated algorithms that generate answers.
Cloud providers are generating business ideas based on these three structures: gathering data, providing the algorithms and datasets, and providing the hardware that can provide the fastest answers from the datasets.
The differences are in how the cloud makers are packaging the three and presenting them to customers. There are exceptions like Meta’s Llama 2 large-language model, which is available via Microsoft’s Azure and Amazon’s AWS.
AI is not new, and the top cloud providers for years have provided machine-learning technologies specific to applications. AI as a form of general intelligence — in this case large-language models – was not mainstream yet. At the time, Google and Meta were researching their own LLMs, which the companies detailed in academic papers.
But Generative AI burst on the scene late last year with ChatGPT, an OpenAI chatbot that answered questions, provided summaries, wrote poetry, and even generated software code. ChatGPT reached 100 million users in under two months, and cloud providers realized there was money to be made from their homegrown LLMs.
Microsoft's Approach
Microsoft and Google locked down their AI models as centerpieces of their business strategies. Microsoft's GPT-4, which is based on OpenAI models, was first implemented in Bing, and now Windows 11 is being populated with AI features that are driven by the large-language model. The LLM is also being used in the "Co-pilot" feature in Microsoft 365, which will help compile letters, summarize documents, write letters, and create presentations.

ChatGPT is the “iPhone moment” for AI.(SomYuZu/Shutterstock)
The creator of GPT-3.5, which powers ChatGPT and GPT-4, started off as a nonprofit firm with a promise to provide open models. OpenAI changed its status to a for-profit after, just months ahead of Microsoft investing $1 billion in the company. Microsoft is monetizing that investment with an OpenAI Azure service, which provides cloud-based access to the proprietary models developed by OpenAI.
Microsoft is also using OpenAI assets to lock customers to Azure, and the company’s final piece was to build up a GPU infrastructure on which to run those models. The company has built Azure supercomputers with thousands of Nvidia GPUs and is investing billions to build new data centers that are specially wired to meet the horsepower and power consumption of AI applications.
Google Looking at the Long-term
The readiness of OpenAI technologies in Microsoft’s infrastructure caught Google napping, which then played catch up by prematurely announcing plans to commercialize its LLM called PaLM into its search, mapping, imaging, and other products. Google then announced PaLM-2 in May, which is now being quietly integrated in its search products and Workspace applications. The company also combined its various AI groups – including DeepMind and Brain – into a single group.
After the initial panic and AI backlash directed toward Microsoft and OpenAI, Google has focused on safety and ethics and communicated its AI efforts as mostly experimental. But like Microsoft, Google – which is a big proponent of open-source tools — has locked down access to its latest model, called PaLM-2 with the hope to capitalize on it to generate long-term revenue. The company is also training its newer model called Gemini, which was originally developed by DeepMind and will be the foundation of the company’s next-generation AI offerings.
 Google’s PaLM-2 has not been commercialized to the extent of Microsoft’s GPT-4, but is available to some customers on Google Cloud via the Vertex AI offering. Google Cloud is a favorite among developers for the ability to customize models to specific needs, and the company has talked about how PaLM-2 could be used to create basic applications with just a few lines of code. Google also talked about Duet, which will allow users to be more productive in Workspace, much like Microsoft 365’s Co-pilot feature.
Google’s PaLM-2 has not been commercialized to the extent of Microsoft’s GPT-4, but is available to some customers on Google Cloud via the Vertex AI offering. Google Cloud is a favorite among developers for the ability to customize models to specific needs, and the company has talked about how PaLM-2 could be used to create basic applications with just a few lines of code. Google also talked about Duet, which will allow users to be more productive in Workspace, much like Microsoft 365’s Co-pilot feature.
The company is also embracing an open AI approach via its Built with AI model, which allows companies to partner with ISVs to build software on Google Cloud.
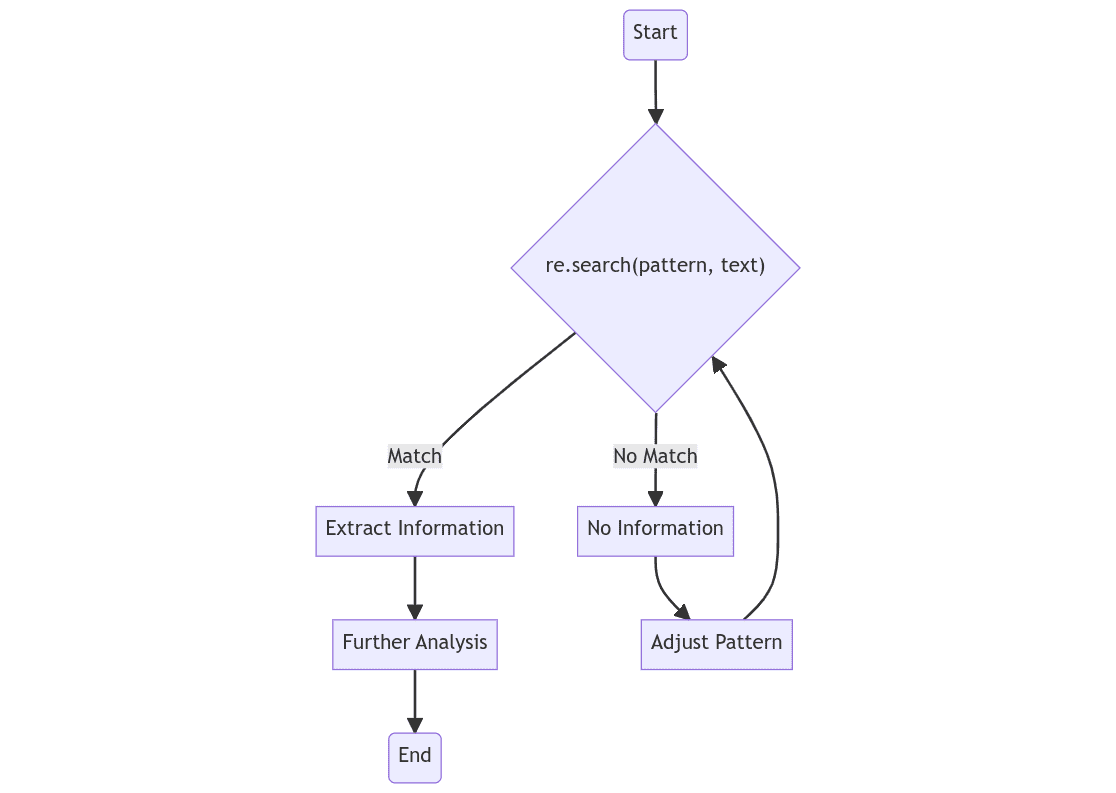
Google’s computational model for its PaLM-2 software stack in the Cloud is built around TPUs, which are homegrown AI chips that are packed into supercomputers. The TPUv4 supercomputers have 4,096 TPUv4 AI chips on 64 racks, which are interconnected via 48 optical circuit switches. Those supercomputers are one of the first known implementations of optical interconnects at the rack level. The company also offers customers Nvidia GPUs via A3 supercomputers, though the GPUs are not tuned to run PaLM-2 models and would generate slow results.
AWS Provides 'Compute at Your Fingertips'
Amazon is taking an alternate approach by providing flexibility at all levels, including the models and the hardware, to run AI on AWS. It is like a typical Amazon shopping experience – drop the AI of your choice, choose the computing required, and then pay on checkout.
Amazon is doubling down on computing with the recent EC2 P5 instances, in which 20,000 Nvidia H100 GPUs can be crammed into clusters that can provide up to 20 exaflops of performance. Users can deploy ML models scaling to billions or trillions of parameters.

Swami Sivasubramanian, VP of analytics, database and machine learning at AWS, delivers a keynote at AWS Summit in NYC.
“Cloud vendors are responsible for two of the drivers. The first one is the availability of compute at your fingertips. It is elastic, it is pay-as-you-go. You spin them up, you train, you pay for it, and then you shut them off, you do not pay for it anymore,” said Vasi Philomin, VP of generative AI at AWS.
The second is to provide the best technologies to get insights from the vast repositories. AWS recently introduced a new concept called Agents, which links independent data to large language models to answer questions. Foundational models can provide more useful answers by linking up to external databases. Agents was among many AI features in the cloud announced by AWS at the AWS Summit held recently in New York City.
But as AI matures, the models will matter less, and what will matter is the value and the capabilities for cloud providers to meet the demands of customers.
“I think the models will not be the differentiator. I think what will be the differentiator is what you can do with them,” Philomin said.




















 Dall E-2 (July)
Dall E-2 (July)