In part 1 of the series “A Different AI Scenario: AI and Justice in a Brave New World,” we outlined some requirements for the role that AI would play in enforcing our laws and regulations in a more just and fair manner and what our human legislators must do to ensure those more just and fair outcomes.
Let’s look at a real example of how AI is being used to enforce our laws and regulations in a more unbiased, consistent, and transparent manner…robot umpires.
Rise of the Robot Umpires
Baseball has always been an excellent testing ground for analytics (Strat-o-matic baseball, Sabermetrics, Money Ball, etc.). While baseball rules are clearly defined, enforcing them has always been left to humans. And the inconsistent and obscure enforcement of those baseball rules is being challenged.
In 2018, Major League Baseball (MLB) professional umpires missed 34,294 strike zone calls. That same year, 55 games were ended on incorrect calls by umpires[1]. The inconsistent enforcement of the strike zone impacts the fortunes of teams and players in a sport where teams are worth tens of billions of dollars and the top players earn nearly a quarter of a billion dollars.
The challenge is that human umpires are…well, human. And humans have ingrained biases and prejudices that are put on full display when that human stands behind home plate in a professional baseball game and must distinguish between balls and strikes in a fraction of a second (Figure 1).
Figure 1: Human Inconsistencies in Enforcing Rules Impacts the Sports Integrity
Enter Robot umpires. A robot umpire is an automated system to call balls and strikes. The system uses a radar or a camera to track the location and trajectory of each pitch and compares it with the predefined strike zone calibrated for the physical dimensions of each batter. The system then communicates the call to the human umpire via an earpiece or a screen.
Some baseball purists are concerned that the robot umpire is too black and white and that the best human umpires consider specific nuances of the players before rendering their call. For example, a pitcher like Greg Maddux, with a history of outstanding pitching performance, has “earned the benefit” of a slightly larger strike zone. Or a Hall of Fame batter like Barry Bonds has “earned the benefit” of a smaller strike zone given his historical batting performance (Figure 2).
Figure 2: “Earned the Right” and Humanizing the AI Models
Adding these nuances to the enforcement of the strike zone is what makes humans human. But let’s decompose what “earned the right” really means:
“Earned” means to whom special consideration is given in enforcing a rule given that person’s historical performance. “Earned” determines the “who” in rule enforcement leniency.
“The Right” means how many degrees of latitude are given to that person when considering rule enforcement leniency; that is, the level of latitude from the defined rule the person is given based on their historical performance.
This “earned the right” concept of considering additional factors in enforcing a law or regulation can apply to several other scenarios, including:
A driver may have “earned the right” for police officer leniency for a speeding ticket based on their driving record, safe driving behaviors, weather conditions, amount of traffic, time of day, etc.
A customer may have “earned the right” for credit agent leniency for a credit card late fee charge based on their payment history, frequency of late payments, FICO score, lifetime value, etc.
A student may have “earned the right” for teacher leniency to a student for missing a homework deadline based on their academic record, classroom workload, extracurricular activities, personal circumstances, attendance record, etc.
An employee may have “earned the right” for manager leniency for an unexcused absence based upon their hardworking reputation, attendance record, performance reviews, positive organizational influence, outside volunteer efforts, etc.
A state resident may have “earned the right” for DMV clerk leniency for not providing the proper documentation in renewing their driver’s license based on years of residence, on-time payment history, timely filing of paperwork, etc.
Yes, the AI model can be engineered to give people rule enforcement leniency based on their past performance. The key is that the criterion for receiving leniency is determined beforehand. And it is transparent why someone is given such leniency.
Legal Tests: Frye and Standard Daubert Standards
We can learn much from the legal community about the proper and thoughtful enforcement of laws and regulations. The legal community has decades of experience regarding the admissibility of evidence in legal enforcement cases. For example, the Frye standard is a judicial test used to determine the admissibility of scientific evidence based on the scientific community’s generally accepted scientific methods. And because the Frye standard has been criticized for being too rigid, many states and federal courts have adopted the Daubert standard, which considers other factors such as the scientific method’s testability, peer review, and error rate.
We could leverage the years of learning from applying the Frye and Daubert standards to select the variables and metrics that comprise a healthy, unbiased, fair AI Utility Function. For example, the Frye and Daubert standards could filter out variables and metrics in the AI Utility function that are not generally accepted by the relevant scientific community, testability, or peer review (Figure 3).
Figure 3: The Frye and Daubert Legal Admissibility Standards
The Frye, Daubert, and Kumho (another legal admissibility test) standards are judicial tests to determine the admissibility of scientific and expert evidence in enforcing laws and regulations. By integrating the learnings from applying these standards into the construction of the AI Utility Function and AI Certification models, we can learn how to balance simplicity, flexibility, transparency, and accountability in designing and evaluating AI models and their supporting AI Utility Function that enforce laws and regulations.
Summary: Create a More Fair, Just, and Empowered Society Part 2
As a society, we should aim to use AI to create a more fair and just world for everyone. This is an essential goal as we strive to leverage technology to improve the quality of life and opportunities for all, regardless of their background, status, or location. We must not allow this chance to be squandered or taken over by a privileged few with the resources and influence to exploit this pivotal moment for their selfish interests.
Part 3 will complete this blog series by discussing the importance of AI Governance and the role of an AI Model Audit Trail and AI certification engines to monitor and ensure unbiased, fair, and consistent application of AI.
[1] MLB Umpires Missed 34,294 Ball-Strike Calls in 2018. Bring on Robo-umps? https://www.bu.edu/articles/2019/mlb-umpires-strike-zone-accuracy/
Intel is all set for its ‘AI Everywhere’ event coming on December 14, with a bunch of AI announcements, which it touts would usher in its top place in the generative AI realm.
The Chip company is planning the release of its Gaudi3 AI accelerator chip at its event, which would be a major game changer for the company. Gelsinger believes that the supercomputer that Intel is building will be the largest in Europe. He even hinted at Gaudi3, which according to him, would be two times faster than Gaudi2.
To put it in perspective, this comes after Intel has already been providing Gaudi2 AI chips for training models. Interestingly, Gaudi2 works 2.4 times faster than the NVIDIA A100, and is almost coming close to the H100 Hopper GPU.
Gaudi3 is expected to arrive with a 5nm chip. The accelerators are set to provide a significant boost with up to 4 times the BFloat16 capabilities, double the compute power, 1.5 times the network bandwidth, and a 1.5 times increase in HBM capacities (144 GB compared to 96 GB). Looking ahead to 2025, the successor to Gaudi3, Falcon Shores, will merge the AI capabilities of Gaudi with the powerful GPUs from Intel, all within a single package.
All about AI?
Intel is embarking on a bold journey in AI to compete with NVIDIA, AMD. At Intel Innovation 2023 in September, the company revealed its ambitious roadmap for the next few years, making it clear that they are going all in on AI. This includes their monster 288-core Xeon CPU, based on Emerald Rapids architecture, that’s coming next year.
The company has also announced that Stability.AI would purchase a Gaudi2-based AI supercomputer with Xeon processors overseeing 4,000 Gaudi2 accelerators.
What caught the industry’s attention were the processors in the pipeline such as Arrow Lake, Lunar Lake, and Panther Lake scheduled for 2024 and 2025. These processors represent a significant leap forward in Intel’s pursuit of technological excellence.
Intel is planning to onboard another version of AI accelerator superchip, Falcon Shores 2, by 2026. “We have a simplified roadmap as we bring together our GPU and our accelerators into a single offering,” CEO Pat Gelsinger said. Though this is a far out vision, the close by announcements are no joke as well.
Furthermore, Intel’s Falcon Shores chips were originally conceived as a fusion of CPU and GPU cores, representing the company’s inaugural venture into the ‘XPU’ architecture for high-performance computing. Nonetheless, a few months ago, Intel astounded the industry by opting for a GPU-only approach and deferring the chip’s release until 2025. The company’s voyage into the realm of AI and GPUs has encountered a series of twists and turns.
The focus on developers
The announcement on Meteor Lake, set to launch on December 14, was undoubtedly a headline-grabber because as CEO Pat Gelsinger said, the processor will “power-efficient AI acceleration and local inference on the PC”.
Gelsinger emphasised the company’s commitment to engineering excellence and showcased its efforts to democratise AI with the “AI PC” concept, which is similar to AMD’s Ryzen AI PCs. This innovation is made possible by Intel’s forthcoming “Meteor Lake” laptop chip, which incorporates new AI data-crunching features.
The AI PC concept aims to bring AI capabilities directly to personal computers, allowing users to run generative AI chatbots, like ChatGPT, locally, without relying on cloud data centres, and even for inference models such as Llama 2.
Moreover, to compete with AMD’s ROCm and NVIDIA’s CUDA, developers can utilise the oneAPI programming model to build and optimise AI and high-performance computing workloads. In addition, Intel has revealed Project Strata, a commercial software platform set to launch in 2024, aimed at supporting distributed edge infrastructure and applications with modular building blocks and premium services.
Focusing on developers, Intel had already announced the general availability of its Intel Developer Cloud platform, offering developers the opportunity to test and deploy AI and high-performance computing applications with the latest CPUs, GPUs, and AI accelerators.
The platform includes access to fifth-generation Xeon Scalable processors, Intel Data Center GPU Max Series, Intel Gaudi2 deep learning processors, and Intel software and tools.
All of this clearly shows that Intel might make a significant mark on December 14, as the road it’s taking with Gaudi3, upgrades to Xeon for AI PC, and the prowess of Gaudi2, all hints towards just that.
While Intel navigates its strategic adjustments, it’s noteworthy that NVIDIA has also taken a substantial leap by venturing into the CPU market with the GH200 supercomputer, which it has already started rolling out. This expansion into CPUs complements NVIDIA’s existing prowess in GPUs and AI technologies, while venturing into the CPU market.
AMD is also all-in on AI compute by partnering with Microsoft, Meta, and several OEM companies. At the AMD Advancing AI event, the company has unveiled various lines of AI announcements including the Instinct MI300X AI accelerators to compete with NVIDIA H100, updates to ROCm, and Ryzen AI PCs for on-device computing.
The post Can Intel Play Catch-Up with NVIDIA and AMD? appeared first on Analytics India Magazine.
This week in AI: Mistral and the EU’s fight for AI sovereignty Kyle Wiggers Devin Coldewey 9 hours
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week, Google flooded the channels with announcements around Gemini, its new flagship multimodal AI model. Turns out it’s not as impressive as the company initially made it out to be — or, rather, the “lite” version of the model (Gemini Pro) Google released this week isn’t. (It doesn’t help matters that Google faked a product demo.) We’ll reserve judgement on Gemini Ultra, the full version of the model, until it begins making its way into various Google apps and services early next year.
But enough talk of chatbots. What’s a bigger deal, I’d argue, is a funding round that just barely squeezed into the workweek: Mistral AI raising €450M (~$484 million) at $2 billion valuation.
We’ve covered Mistral before. In September, the company, co-founded by Google DeepMind and Meta alumni, released its first model, Mistral 7B, which it claimed at the time outperformed others of its size. Mistral closed one of Europe’s largest seed rounds to date prior to Friday’s fundraise — and it hasn’t even launched a product yet.
Now, my colleague Dominic has rightly pointed out that Paris-based Mistral’s fortunes are a red flag for many concerned about inclusivity. The startup’s co-founders are all white and male, and academically fit the homogenous, privileged profile of many of those in The New York Times’ roundly criticized list of AI changemakers.
At the same time, investors appear to be viewing Mistral — as well as its sometime rival, Germany’s Aleph Alpha — as Europe’s opportunity to plant its flag in the very fertile (at present) generative AI ground.
So far, the largest-profile and best-funded generative AI ventures have been stateside. OpenAI. Anthropic. Inflection AI. Cohere. The list goes on.
Mistral’s good fortune is in many ways a microcosm of the fight for AI sovereignty. The European Union (EU) desires to avoid being left behind in yet another technological leap while at the same time imposing regulations to guide the tech’s development. As Germany’s Vice Chancellor and Minister for Economic Affairs Robert Habeck was recently quoted as saying: “The thought of having our own sovereignty in the AI sector is extremely important. [But] if Europe has the best regulation but no European companies, we haven’t won much.”
The entrepreneurship-regulation divide came into sharp relief this week as EU lawmakers attempted to reach an agreement on policies to limit the risk of AI systems. Lobbyists, led by Mistral, have in recent months pushed for a total regulatory carve-out for generative AI models. But EU lawmakers have resisted such an exemption — for now.
A lot’s riding on Mistral and its European competitors, all this being said; industry observers — and legislators stateside — will no doubt watch closely for the impact on investments once EU policymakers impose new restrictions on AI. Could Mistral someday grow to challenge OpenAI with the regulations in place? Or will the regulations have a chilling effect? It’s too early to say — but we’re eager to see ourselves.
Here are some other AI stories of note from the past few days:
A new AI alliance: Meta, on an open source tear, wants to spread its influence in the ongoing battle for AI mindshare. The social network announced that it’s teaming up with IBM to launch the AI Alliance, an industry body to support “open innovation” and “open science” in AI — but ulterior motives abound.
OpenAI turns to India: Ivan and Jagmeet report that OpenAI is working with former Twitter India head Rishi Jaitly as a senior advisor to facilitate talks with the government about AI policy. OpenAI is also looking to set up a local team in India, with Jaitly helping the AI startup navigate the Indian policy and regulatory landscape.
Google launches AI-assisted note-taking: Google’s AI note-taking app, NotebookLM, which was announced earlier this year, is now available to U.S. users 18 years of age or older. To mark the launch, the experimental app got integration with Gemini Pro, Google’s new large language model, which Google says will “help with document understanding and reasoning.”
OpenAI under regulatory scrutiny: The cozy relationship between OpenAI and Microsoft, a major backer and partner, is now the focus of a new inquiry launched by the Competition and Markets Authority in the U.K. over whether the two companies are effectively in a “relevant merger situation” after recent drama. The FTC is also reportedly looking into Microsoft’s investments in OpenAI in what appears to be a coordinated effort.
Asking AI nicely: How can you reduce biases if they’re baked into a AI model from biases in its training data? Anthropic suggests asking it nicely to please, please not discriminate or someone will sue us. Yes, really. Devin has the full story.
Meta rolls out AI features: Alongside other AI-related updates this week, Meta AI, Meta’s generative AI experience, gained new capabilities including the ability to create images when prompted as well as support for Instagram Reels. The former feature, called “reimagine,” lets users in group chats recreate AI images with prompts, while the latter can turn to Reels as a resource as needed.
Respeecher gets cash: Ukrainian synthetic voice startup Respeecher — which is perhaps best known for being chosen to replicate James Earl Jones and his iconic Darth Vader voice for a Star Wars animated show, then later a younger Luke Skywalker for The Mandalorian — is finding success despite not just bombs raining down on their city, but a wave of hype that has raised up sometimes controversial competitors, Devin writes.
Liquid neural nets: An MIT spinoff co-founded by robotics luminary Daniela Rus aims to build general-purpose AI systems powered by a relatively new type of AI model called a liquid neural network. Called Liquid AI, the company raised $37.5 million this week in a seed round from backers including WordPress parent company Automattic.
More machine learnings
Predicted floating plastic locations off the coast of South Africa.Image Credits: EPFL
Orbital imagery is an excellent playground for machine learning models, since these days satellites produce more data than experts can possibly keep up with. EPFL researchers are looking into better identifying ocean-borne plastic, a huge problem but a very difficult one to track systematically. Their approach isn’t shocking — train a model on labeled orbital images — but they’ve refined the technique so that their system is considerably more accurate, even when there’s cloud cover.
Finding it is only part of the challenge, of course, and removing it is another, but the better intelligence people and organizations have when they perform the actual work, the more effective they will be.
Not every domain has so much imagery, however. Biologists in particular face a challenge in studying animals that are not adequately documented. For instance, they might want to track the movements of a certain rare type of insect, but due to a lack of imagery of that insect, automating the process is difficult. A group at Imperial College London is putting machine learning to work on this in collaboration with game development platform Unreal.
Image Credits: Imperial College London
By creating photo-realistic scenes in Unreal and populating them with 3D models of the critter in question, be it an ant, stick insect, or something bigger, they can create arbitrary amounts of training data for machine learning models. Though the computer vision system will have been trained on synthetic data, it can still be very effective in real-world footage, as their video shows.
You can read their paper in Nature Communications.
Not all generated imagery is so reliable, though, as University of Washington researchers found. They systematically prompted the open source image generator Stable Diffusion 2.1 to produce images of a “person” with various restrictions or locations. They showed that the term “person” is disproportionately associated with light-skinned, western men.
Not only that, but certain locations and nationalities produced unsettling patterns, like sexualized imagery of women from Latin American countries and “a near-complete erasure of nonbinary and Indigenous identities.” For instance, asking for pictures of “a person from Oceania” produces white men and no indigenous people, despite the latter being numerous in the region (not to mention all the other non-white-guy people). It’s all a work in progress, and being aware of the biases inherent in the data is important.
Learning how to navigate biased and questionably useful model is on a lot of academics’ minds — and those of their students. This interesting chat with Yale English professor Ben Glaser is a refreshingly optimistic take on how things like ChatGPT can be used constructively:
When you talk to a chatbot, you get this fuzzy, weird image of culture back. You might get counterpoints to your ideas, and then you need to evaluate whether those counterpoints or supporting evidence for your ideas are actually good ones. And there’s a kind of literacy to reading those outputs. Students in this class are gaining some of that literacy.
If everything’s cited, and you develop a creative work through some elaborate back-and-forth or programming effort including these tools, you’re just doing something wild and interesting.
And when should they be trusted in, say, a hospital? Radiology is a field where AI is frequently being applied to help quickly identify problems in scans of the body, but it’s far from infallible. So how should doctors know when to trust the model and when not to? MIT seems to think that they can automate that part too — but don’t worry, it’s not another AI. Instead, it’s a standard, automated onboarding process that helps determine when a particular doctor or task finds an AI tool helpful, and when it gets in the way.
Increasingly, AI models are being asked to generate more than text and images. Materials are one place where we’ve seen a lot of movement — models are great at coming up with likely candidates for better catalysts, polymer chains, and so on. Startups are getting in on it, but Microsoft also just released a model called MatterGen that’s “specifically designed for generating novel, stable materials.”
Image Credits: Microsoft
As you can see in the image above, you can target lots of different qualities, from magnetism to reactivity to size. No need for a Flubber-like accident or thousands of lab runs — this model could help you find a suitable material for an experiment or product in hours rather than months.
Google DeepMind and Berkeley Lab are also working on this kind of thing. It’s quickly becoming standard practice in the materials industry.
As the world navigates the intricate intersection of technology and human progress, tech women leaders are leading from the front, lending their expertise, creativity, and EQ to propel the AI industry into new frontiers.
Let’s delve into the stories and achievements of these trailblazers, demonstrating that the future of technology is not only diverse but distinctly female.
Mira Murati, the CTO of OpenAI, is one of the most celebrated technology leaders of our time and how! Recently, when the entire OpenAI drama played out with the ousting of Sam Altman, it was Murati who helmed the company briefly for those tumultuous days. She ensured that productivity wasn’t hit.
As the CTO, Murati nurtured OpenAI helping it become the company it is today. She led the team to create path-breaking products such as ChatGPT, DALL-E and GPT-4. Mira is an Albanian engineer, who moved to Canada as a teenager to study at an international school in Vancouver. She graduated from Dartmouth with a degree in mechanical engineering and later moved to San Francisco.
Daniela Amodei, the co-founder and president of Anthropic, stands tall in the artificial intelligence realm. Her commitment to developing AI systems that are reliable, interpretable, and controllable has steered her through a remarkable journey marked by numerous accomplishments and accolades.
She joined Stripe in 2013 when it was still a young company and quickly rose from a solo recruiter to lead recruiter, growing the team from 45 to 300 members. After working at Stripe, Daniela joined OpenAI, where she held various positions. After leaving OpenAI, Dario and Daniela Amodei founded Anthropic in 2021, aiming to make AI safer. They brought on board at least nine other talented individuals from OpenAI who shared their vision.
Lisa Su
Dr Lisa Su stands as a trailblazing figure in the technology industry, renowned for her exceptional leadership and contributions to semiconductor innovation. Serving as the president and CEO of Advanced Micro Devices (AMD), she has revitalized the company, steering it towards remarkable growth and technological advancements.
Dr Su’s strategic vision, technical expertise, and commitment to diversity and inclusion have solidified her as a prominent leader, earning accolades such as being named among Fortune’s ‘World’s 50 Greatest Leaders’. Her impact resonates not only within AMD but across the entire semiconductor landscape.
With a blend of strategic insight and a touch of visionary leadership, Julie Sweet conquered complex landscapes of business, leaving a trail of innovation in her wake. In September 2019, as the CEO of Accenture, she not only navigated the intricate tapestry of global business but also painted the future with strokes of transformative ideas.
Julie’s multifaceted expertise extends beyond corporate realms; she served as Accenture‘s general counsel, secretary, and chief compliance officer for five years. Beyond her corporate duties, she actively contributes to global initiatives, serving on the World Economic Forum Board of Trustees.
Timnit Gebru, a prominent computer scientist and ethical AI advocate, has significantly shaped the discourse on artificial intelligence. As a former co-lead of Google’s Ethical AI team, she was instrumental in highlighting the importance of responsible AI development. She has done some groundbreaking research and holds a PhD from the Stanford Artificial Intelligence Lab.
Gebru co-founded the Black in AI affinity group, and as the founder of the Distributed Artificial Intelligence Research Institute (DAIR), she has been a central figure in the field of ethical AI. She was named one of the World’s 50 Greatest Leaders by Fortune and one of Nature’s ten people who shaped science in 2021, and in 2022, one of Time’s most influential people.
Daphne Koller, an esteemed Israeli-American computer scientist, has left an indelible mark on machine learning and probabilistic models, particularly in biology and human health. TIME recognized her as one of the 100 most influential people in 2013, a distinction that underscored her groundbreaking contributions.
Currently leading Insitro, a biotech startup merging machine learning and biology for drug discovery, Koller has played a crucial role in advancing graphical and temporal models. Her co-authored textbook on Probabilistic Graphical Models remains a definitive reference, and her introduction to Module Networks has revolutionised gene activity modelling.
Sandra Rivera is a seasoned technology executive known for her impactful leadership in the semiconductor and technology sector. Currently, she serves as Intel’s executive vice president and chief people officer, overseeing the company’s global human resources and driving initiatives related to organisational transformation and talent development. With a strong technical background and an MBA from Arizona State University, Rivera led Intel’s efforts in network transformation.
She previously led the Network Platforms Group of over 3,000 employees that drove the transformation of network infrastructure to Intel-based solutions and enabled breakthrough ways to integrate Intel’s silicon and software portfolio to create greater customer value.
Lila Ibrahim serves as the chief operating officer at Google DeepMind, a prominent AI research firm dedicated to advancing science and benefiting humanity through solving intelligence challenges. In her role, she oversees various functions such as operations, governance and ethics, policy, communications, and people and culture.
Ibrahim, with a 30-year career, has contributed to major tech companies like Intel and Coursera, where she served as president and played a key role in global education outreach. She co-founded and chaired the non-profit, Team4Tech, and served on the Board of Gannett, helping it become the largest US print media company.
Bindu Reddy is the CEO and co-founder of Abacus. AI. Before starting Abacus, she was the general manager of the AI verticals at AWS. This organisation created and launched Amazon Personalise and Amazon Forecast, the first AI services that enable organisations to easily build custom deep learning models.
Before that, she was the CEO and co-founder of Post Intelligence, a deep learning company that built services for social media influencers that Uber bought. Bindu previously worked at Google, where she was a product manager for Google applications, including Docs, Sheets, Slides, Sites and Blogger. She holds a master’s degree from Dartmouth and a bachelor’s degree from the Indian Institute of Technology, Mumbai.
Sharon Zhou, the co-founder & CEO of Lamini, is building the future of LLMs. Also a CS faculty at Stanford, Sharon’s mission is to make complex technology like generative artificial intelligence highly usable and accessible to everyone. At Stanford, she led over 50 PhD and undergraduate research groups in AI and published award-winning research at the world’s leading AI conferences.
Sharon created and continues to teach one of the largest classes on Coursera, Generative Adversarial Networks, which currently has over 250,000 students. She received her PhD from Stanford in generative artificial intelligence under Dr Andrew Ng and served as an AI advisor to key AI policymakers in Washington, DC.
The post Top 10 Women Leaders Who Are Killing It in AI appeared first on Analytics India Magazine.
Rules Approved for EU AI Act December 8, 2023 by Alex Woodie
The European Union’s AI Act took a big step toward becoming law today when policymakers successfully hammered out rules for the landmark regulation. The AI Act still requires votes from Parliament and the European Council before becoming law, after which it would go into effect in 12 to 24 months.
The AI Act has been in the works since 2018, the same year that the EU’s General Data Protection Regulation (GDPR) went into effect, as European lawmakers seek to protect the continent’s residents from the negative impacts of artificial intelligence.
As we’ve previously reported, the new law would create a common regulatory and legal framework for the use of AI technology, including how it’s developed, what companies can use it for, and the consequences of failing to adhere to requirements.
Earlier drafts of the law categorize AI by use cases in a four-level pyramid. At the bottom are systems deemed a minimal risk which would be free from regulation. This would include things like search engines. Above that would be systems with limited risks, such as chatbots, which would be subject to certain transparency requirements.
Organizations would need to gain approval before implementing AI in the high-risk category, which would include things such as self-driving cars, credit scoring, law enforcement use cases, and safety components of products like robot-assisted surgery. The government would set minimum safety standards for these systems, and the government would maintain a database of all high-risk systems.
The EU Act would completely ban certain AI uses deemed to have an unacceptable risk, such as real-time biometric identification systems, social scoring systems, and applications designed to manipulate the behavior or people or “specific vulnerable groups.
The launch of ChatGPT one year ago and the rise of generative AI in 2023 has solidified regulators’ desire to shield people from the harmful aspects of AI. According to an article in the New York Times, EU policymakers adapted the AI Act to account for the emergence of GenAI by adding requirements for large AI model creators “to disclose information about how their systems work and to evaluate for ‘systemic risk.’”
According to the Times, policymakers finally agreed on AI Act rules after three days of negotiations, including a marathon 22-hour session on Wednesday. It’s not clear how soon a draft of the finalized AI Act law would be available to the public. If it’s approved in the European Union’s legislative bodies, it would likely go into force one to two years later.
One of the areas of the new law that had yet to be hammered out before this week’s rulemaking session included penalties. Violations of the GDPR can bring penalties equal to up to 4% of a company’s annual revenue or €20 million, whichever is greater.
Editor's note: This article first appeared in Datanami.
Related
About the author: Alex Woodie
Alex Woodie has written about IT as a technology journalist for more than a decade. He brings extensive experience from the IBM midrange marketplace, including topics such as servers, ERP applications, programming, databases, security, high availability, storage, business intelligence, cloud, and mobile enablement. He resides in the San Diego area.
In the rapidly evolving landscape of artificial intelligence, Google's latest announcement of its AI model, Gemini, was met with both anticipation and controversy. The tech giant, known for pushing the boundaries of AI capabilities, recently released a demonstration video of Gemini that has since become the center of a heated debate. This video, intended to showcase the prowess of Gemini, has instead sparked allegations of misleading the public regarding the model's real-time capabilities.
At the heart of this controversy lies the question of authenticity and transparency in the portrayal of AI technologies. Critics suggest that the demonstration video may have overstated Gemini's ability to interact and respond in real time, raising concerns about the ethical implications of such misrepresentations. This incident not only highlights the challenges in accurately demonstrating advanced AI systems but also underscores the growing scrutiny under which these technological advancements are being placed.
Overview of Gemini AI and the Demonstration Video
Gemini AI represents Google's stride towards creating an AI model that surpasses current standards in both complexity and capability. Touted as Google's most advanced AI model to date, Gemini has been designed to handle a variety of tasks, showcasing a level of versatility and adaptability that marks a significant step forward in the field of artificial intelligence.
The demonstration video released by Google was crafted to highlight Gemini's remarkable abilities in voice and image recognition. In a series of segments, the video displayed Gemini engaging in spoken conversations, akin to a sophisticated chatbot, while also demonstrating its proficiency in recognizing and interpreting visual images and physical objects. One notable example featured in the video was Gemini's ability to articulate the differences between a drawing of a duck and a rubber duck, showcasing its nuanced understanding of both context and content.
However, it's these very capabilities, as presented in the video, that have become the focal point of the controversy. The accusations point towards a potential misrepresentation of Gemini's real-time processing abilities, suggesting that the impressive demonstrations might not have been as spontaneous or real-time as the video implied. This gap between the portrayed and actual capabilities of Gemini has opened up a discourse on the ethics of AI demonstrations and the responsibility of tech giants in maintaining transparency with their audience.
The controversy surrounding Google's Gemini AI demonstration video primarily revolves around the authenticity of its real-time capabilities. Critics have pointed out that the video, contrary to what some viewers might infer, was not a demonstration of Gemini's abilities in a live, real-time setting. Instead, it was later revealed that the video used a series of still images and text prompts to simulate the interactions showcased. This revelation has raised significant concerns about the transparency and honesty of the demonstration.
The criticism hinges on the lack of clarity within the video regarding these modifications. Viewers of the video were given the impression of witnessing Gemini's advanced AI capabilities in real time, responding instantaneously to voice commands and visual cues. However, the reality that the video was a compilation of carefully selected and pre-processed inputs paints a different picture of Gemini's real-time proficiency. This discrepancy between expectation and reality has led to accusations of misleading representation, casting a shadow over the otherwise impressive technological achievements of Gemini.
Google's Response and Explanation
In response to the growing criticism, Google issued a statement clarifying the nature of the demonstration video. The company described the video as an “illustrative depiction” of Gemini's capabilities, emphasizing that it was intended to showcase the potential and range of the AI model's functionalities. Google maintained that the video was based on real multimodal prompts and outputs derived from testing, albeit presented in a condensed and streamlined format for the sake of brevity and clarity.
Google's stance is that the video was not meant to deceive but to inspire and demonstrate what is possible with Gemini. The company argued that such demonstrations are common in the industry, where the complexity of technologies often requires simplified representations to convey their potential effectively to a broader audience. Google's response highlights a fundamental challenge in the AI industry: balancing the need for clear and honest representation with the desire to showcase the cutting-edge capabilities of these rapidly evolving technologies. This challenge becomes particularly pronounced when the technology in question, like Gemini, represents a significant leap forward in AI capabilities.
Comparison with Previous Incidents and Industry Standards
The controversy surrounding Google's Gemini AI demonstration video is not an isolated incident in the tech industry, especially for Google. Comparing this situation with previous demonstrations by Google and other companies offers insight into industry practices and their implications. For example, Google's Duplex AI demonstration a few years ago faced similar skepticism over its authenticity, raising questions about the veracity of live AI demonstrations.
These incidents highlight a recurring challenge in the AI industry: the balance between creating impressive demonstrations to showcase technological advancements and maintaining transparency and realism. While it's common for companies to use edited or simulated content for clarity and impact, the line between representation and misrepresentation can often become blurred, leading to public skepticism.
This practice of enhanced demonstrations has a significant impact on public perception. It can lead to inflated expectations about the capabilities of AI technologies, which may not be entirely accurate or feasible in real-world applications. In the competitive landscape of AI development, where companies vie for both consumer attention and investor confidence, the authenticity of demonstrations can play a crucial role in shaping market dynamics.
Implications for the AI Industry and Public Perception
The Gemini AI controversy extends beyond Google, touching on broader issues of credibility and transparency in the AI sector. This incident serves as a reminder of the importance of ethical standards in AI demonstrations and communications. Misrepresentations, even if unintentional, can erode public trust in AI technologies, which is crucial for their acceptance and integration into everyday life.
The potential impact on consumer trust is significant. When the public perceives a disconnect between what is promised and what is delivered, it can lead to skepticism not just about a single product, but about the industry as a whole. This skepticism might slow down the adoption of new technologies or create resistance against them.
Moreover, the competition between leading AI models like Gemini and OpenAI's GPT-4 is intensely watched by both the industry and consumers. Incidents like this can influence the perception of who is leading in the AI race. The credibility of demonstrations and claims made by these companies can impact their standing and perceived innovation leadership in the AI community.
Ultimately, this situation underscores the need for greater transparency and ethical considerations in the presentation of AI technologies. As AI continues to advance and become more integrated into society, the way these technologies are showcased and communicated will play a crucial role in shaping public perception and trust in the AI industry.
Inventory management is crucial for businesses, but it can be tedious. It can make or break a business, regardless of its age. AI has revolutionized business management and inventory control. AI can now do more than just follow instructions. It can analyze inventory history, predict customer behavior, and anticipate business needs.
Want to know what will happen? Want to gauge audience perception of your product before launch? Who is the most likely to make a change?
Every company should make it a priority to conduct business forecasting. It predicts customer behavior, commodity prices, revenue, and more to help you make better decisions about your future. Surveys and market research were once the primary methods utilized in business forecasting. In the year 2023, artificial intelligence has the potential to improve business forecasting.
What is AI forecasting and why should you use it?
AI forecasting uses AI and machine learning to guess what will happen in the future. To guess how customers will act, what trends will happen, and how the market will move.
AI forecasting is more accurate than traditional methods as it considers more data points. A market research survey asks about place, gender, age, and age. It guesses based on what you do on social media, the web, and past purchases.
Conventional methods of forecasting are slower than machine learning. AI approaches provide real-time information for surveys and market research, unlike traditional methods that can take weeks or months to complete.
Through the provision of insights into the future, data-driven forecasting enables you to make more informed decisions regarding your business. AI is the way to maintain a competitive advantage.
How can AI enhance business forecasting in 2023?
Years of uncertainty for global businesses. Companies have been forced to alter their operations as a result of the pandemic, and fluctuations in the economy have made things even more difficult. Now more than ever, forecasting is essential.
AI provides real-time data and insights that are helpful for business forecasting. Social media can be monitored by AI in order to discover early product launches. Use this information to make real-time adjustments to your marketing strategies and messaging in order to gain a competitive advantage.
AI can forecast the behavior of customers. AI systems analyze behavior patterns to make future recommendations. AI may suggest giving discounts to customers who might buy from a competitor.
AI will improve business forecasting in 2023 with accurate insights. Use AI now to stay ahead.
How does AI forecasting work?
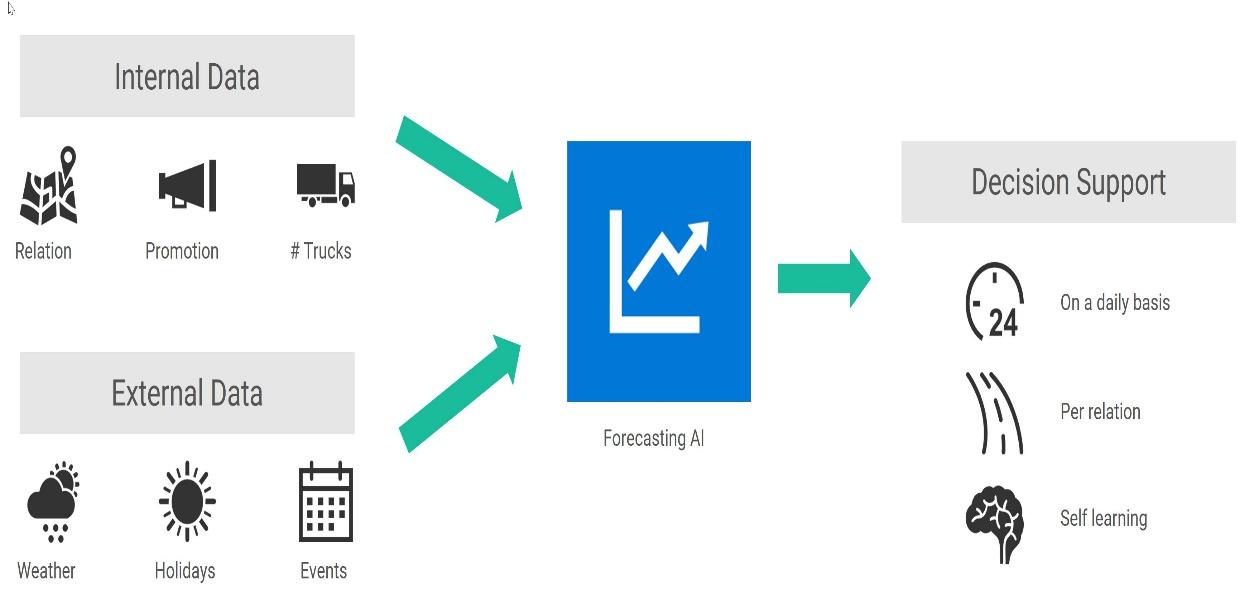
By generating more precise depictions of demand causality in comparison to more conventional methods, artificial intelligence makes demand forecasting more accurate. The shift from traditional forecasting to demand sensing and shaping is made possible by solutions that utilize AI and ML.
Demand Sensing uses automation and machine learning to analyze various data, such as demographics, weather, price changes, and consumer sentiment, in order to make sense of it in relation to your historical data. Through the utilization of insights, demand shaping is able to enhance forecasting and develop superior products, promotions, and marketing campaigns in order to expand market size and share opportunities.
AI forecasting automates analysis and suggests actions, relieving planners of heavy lifting and improving forecast accuracy. Actions can be automated or authorized by planners.
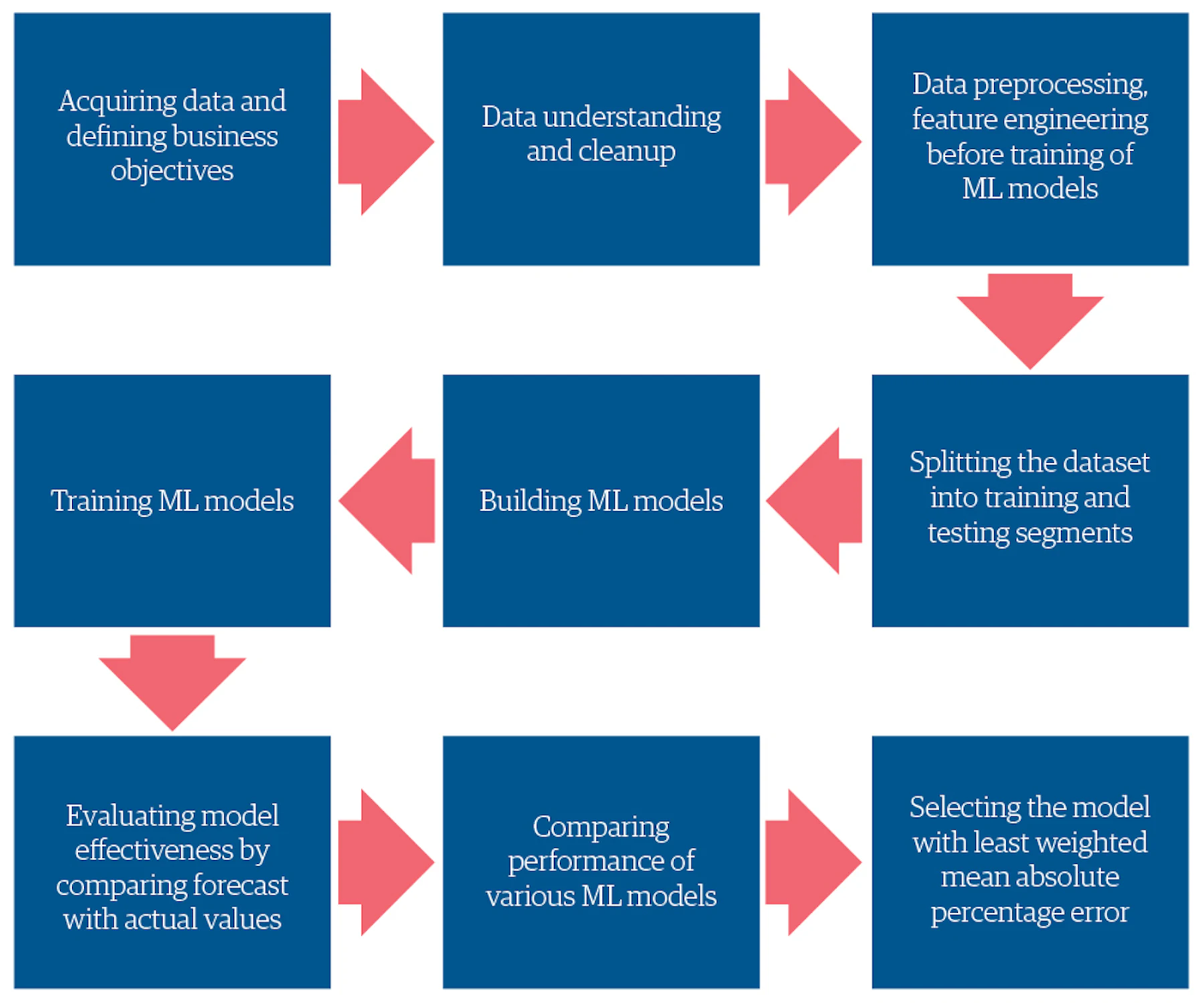
A typical AI/ML forecasting process looks like this:
Data collection and harmonization.
a. Clean b. Organize
Data analysis and feature engineering.
a. analysis b. segmentation c. feature creation and selection
Model creation and iteration.
a. algorithm creation b. model levels and slicing
Modeling: training, validation, tournaments, predictions, and guardrails.
Forecast generation and cycle start.
Common problems in AI forecasting
AI/ML activities and automation have challenges. Next-gen planning solution implementation will face:
Evolving roles and responsibilities
AI/ML forecasting needs data scientists and analysts, unlike traditional forecasting that required data administrators. Construct career path roadmaps for those who are planning. Give them the opportunity to become industry experts who are in high demand.
Python and R Skills
AI/ML methods are made in R and Python. It is possible to script algorithms in-house or by system integrators, or use libraries of algorithms that are already available. In order to ensure effective implementations and continuous optimization of solutions, it is essential to have language users who are skilled.
Model staleness
In some cases, data may become unavailable or obsolete. For an AI/ML solution to work, regular data updates are required. Use AI/ML to analyze data quality and suggest changes. Plan for the future by building a team to search and manage data.
Data privacy and security
There is an increase in the potential for security breaches when cloud-based solutions make use of open-source algorithms and external data. Data planning is very sensitive. Ensure secure planning solutions and processes to prevent theft and exploitation.
Performance
Using too much source data can slow down system performance. It is important to carefully measure the engine run times and user interface access. Prioritize dataset efficiency in implementation.
Overfitting
When it comes to planning solutions, overfitting is a problem because it makes source data more important than predictive results. When the forecast is overfit, it means that it is too similar to the data from the past. When compared to the past, the future will be comparable. Instead of using the ‘Best Fit’ forecasting method, you might want to think about using blended forecasting, which involves combining multiple forecasts to produce a composite prediction.
The evolution of Business forecasting techniques: Traditional versus machine learning methods
AI has solved business problems for years. AI and ML success relies on algorithms that learn through trial and error to improve performance. AI and ML processes often supplement existing business operations that rely on logic instructions, if-then rules, or decision matrices.
AI and ML will revolutionize business as technology advances. AI and ML in forecasting are highly interesting to enterprises for their usability. Enterprises used statistical forecasting methods like exponential smoothing and linear regressions for decision-making. Machine learning has replaced traditional methods in many data and analytics initiatives.
Choosing the right forecast method is important for time, effort, and costs (figure 1). We compare traditional and ML forecasting methods and discuss their advantages, disadvantages, and ideal use cases.
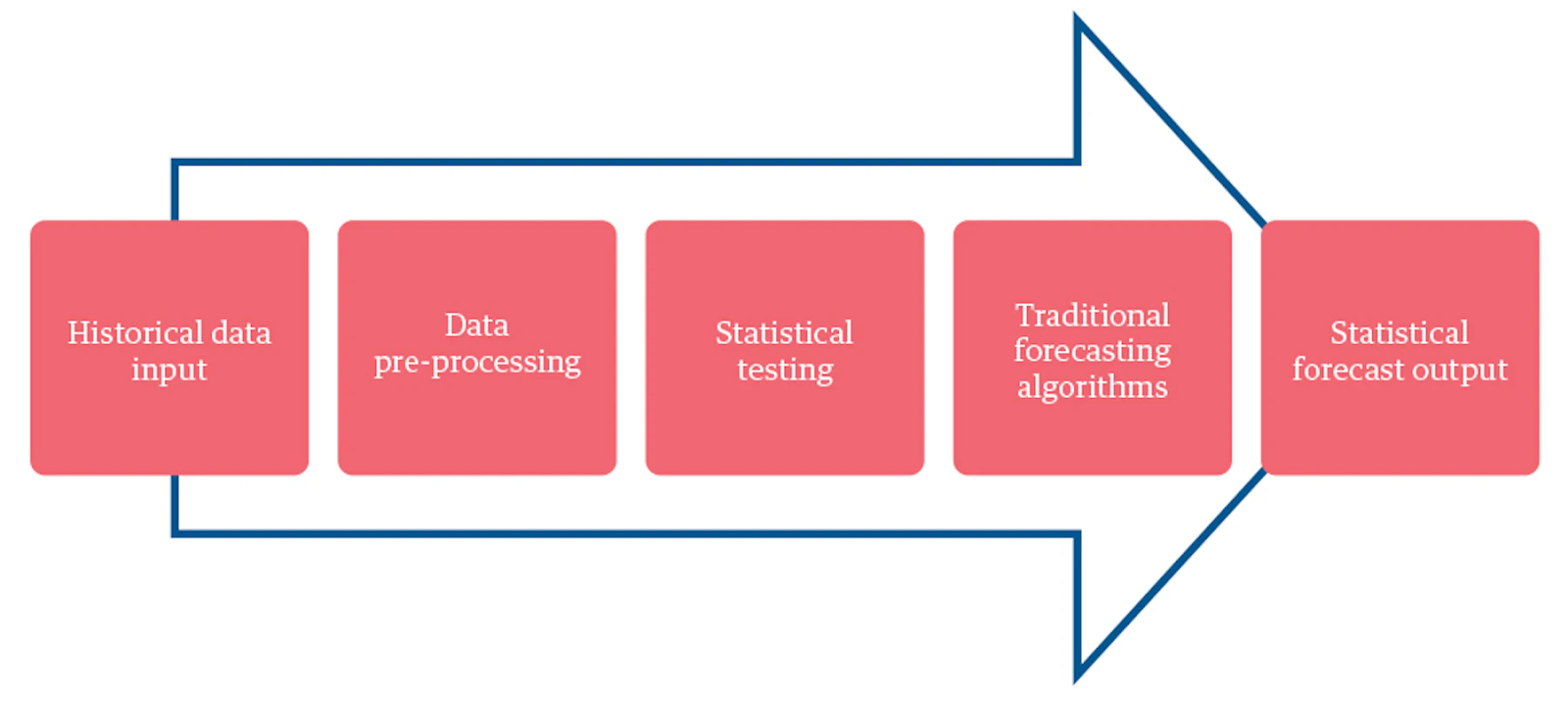
Traditional forecasting
Some examples of traditional algorithms include linear regression, ARIMA, and ARIMAX. These algorithms make use of predefined techniques and statistical models. The goal of traditional forecasting methods is to analyze datasets that are either univariate or multivariate and contain predictors that are countable, finite, and provide an explanation.
Forecasting models are used to estimate future values by utilizing historical records of various metrics that measure business performance. Whenever a prediction is made, a confidence interval is included to express the degree of certainty. The majority of the time, the data that pertains to business performance is univariate, which means that it is composed of observations on a single characteristic or variable.
Traditional statistical methods can accurately predict sales for fast-moving consumer products like dairy products using historical data. The forecast is based on limited and countable factors that impact sales. Although machine learning algorithms for sales forecasting are more accurate, they are not easily explainable and require a greater amount of information processing power.
Classical models used for accurate univariate data analysis include:
Moving avg.
SES
HW
DES
Average of SES, Holt, and DES.
LinReg
ARIMA, ARIMAX
Unobserved component modeling
Classical models are transparent in their functioning. Outputs can be traced easily (figure 2).
Machine learning forecasting
ML forecasting algorithms use complex features and methods to improve forecast accuracy and minimize loss, similar to traditional methods. Additionally, the sum of squares for prediction errors is frequently used as the loss function.
The main difference is how they minimize. In order to minimize loss functions, the majority of machine learning methods use nonlinear techniques, whereas the majority of traditional methods use linear processes.
ML forecasting models used in business applications include:
ANN
LSTM-based neural network
RF
GRNN
KNN regression
CART
SVR
GPs
ML methods are more computationally intensive than statistical methods. ML model explanations may not always be clear. Due to the complexity of the data and the algorithms that are used, machine learning techniques may be superior for making predictions in business applications that contain a large amount of data.
Loan default prediction can be influenced by numerous customer factors. Statistical methods can be outperformed by machine learning algorithms. ML forecasting has the advantage of combining different techniques for higher accuracy.
The machine learning forecasting process
Customer history and purchase data can be streamlined with the help of AI. Before AI, reviewing inventory history was time-consuming and provided a general, but not detailed, picture. AI can mimic the human brain with faster recall and calculation. Enables analysis of consumer patterns and quick calculation of large data sets without manual Excel sorting. It can use external data, like market analysis, to determine buying patterns for the upcoming quarter or holiday season. Accurate inventory management saves money during sales increase.
AI can assist with time-consuming tasks like managing supplier relations in business. Choosing a supplier is hard because it’s tough to analyze product quality, cost, and delivery reliability. Business owners prefer convenience and avoid the hassle of evaluating and finding new suppliers based on metrics. People often rely on anecdotal evidence, like recent late or subpar shipments, when making decisions. AI systems can quickly evaluate and adapt to your business needs.
Author: Olga Ignateva “Businesses collect vast amounts of data, including wait times and production rates. However, with unstructured data and millions of bytes to analyze, humans struggle to match the precision and efficiency of AI.”
How to implement AI-driven Operations Forecasting in your business
Businesses constantly seek to unlock multiple sources of value in operations. AI is a game-changer in our fast-paced world. Data analytics and machine learning are combined in AI-driven forecasting in order to improve operational efficiency and make accurate predictions.
Processes for workforce planning and performance management should be automated, and costs should be reduced by 10-15% through increased efficiency. Isn’t it appealing? The predictive capabilities of AI models are available. Through the implementation of targeted performance management strategies, they both streamline operations and improve the resilience of the workforce.
Models of forecasting that are powered by AI unlock remarkable benefits. As we continue through this post, we will discuss how they function and how you can implement them in your company.
How do AI-driven forecast models work?
In order to analyze data and generate accurate predictions, artificial intelligence forecast models make use of algorithms and machine learning. In order to facilitate informed decision-making, models are used to recognize patterns, trends, and correlations in data.
The training of the model is essential to the success of AI forecasting. Historical data is used to teach the system. The model updates itself with more data over time, improving predictions with each iteration.
AI forecasting excels at handling complex datasets. It is possible for models to process large amounts of information in a quick and effective manner. Time is saved, and there is no room for human error in the analysis.
AI forecast models are highly adaptable. They can update predictions as new variables or In the event that new variables or unexpected events occur, they are able to update their predictions. Being flexible enables one to respond quickly and effectively in environments that are constantly changing.
In order to reap the benefits of your company, you require reliable data sources and a robust infrastructure that can handle high computational loads. AI forecast model needs collaboration between domain experts and data scientists.
Using machine learning algorithms that have been trained on a large amount of historical data, artificial intelligence forecast models are extremely accurate. They process complicated information in a short amount of time, which enables them to rely on reliable insights when making decisions and adapting to shifting markets or circumstances.
How to implement AI-driven forecasting in your business?
AI-driven forecasting can be valuable for your business with the right approach and guidance. Procedures to follow in order to implement AI-driven forecasting:
Define your objectives: Define your AI forecasting goals clearly. Clear objectives guide implementation strategy for improving efficiency, reducing costs, and enhancing customer satisfaction.
Gather quality data: AI algorithms are powered by data. Gain access to data that is both accurate and pertinent from a variety of sources within your organization. This includes data on sales, the behavior of customers, trends in the market, and other information.
Choose the right tools. Many AI forecast models are available now. Conduct research and analysis on the tools based on their various features, scalability, integration, and cost.
Build a skilled team: Requirement for forecasting based on AI proficiency in data analytics as well as knowledge of the industry-specific domain areas.
Integrate with existing systems: Work closely with IT teams to integrate the chosen forecast model with existing systems like CRM software or inventory management tools for seamless integration into your business operations.
Test and refine: Before deploying AI-driven forecast model across your business operations.
Evaluate performance regularly: Assess forecast model performance regularly.
Continuous learning process: Stay updated on AI advancements.
Case Studies
AI-driven forecasting is effective in various industries, as shown by several case studies. Companies have saved money, worked more efficiently, and made customers happier by using these technologies. AI-driven forecast models unlock value in operations. Here are some real-life examples. AI-based predictive models offer tangible benefits for businesses.
A manufacturing company had issues with workforce planning and performance management. By using AI for forecasting, they automated 50% of their workforce planning. Saved time, improved accuracy and efficiency, cost savings of 10-15%.
A retail business used AI-driven forecast models to improve inventory management. They analyzed sales data and external factors to optimize inventory levels and reduce costs while keeping popular products available.
A healthcare organization used AI models for patient demand forecasting. By predicting patient volumes based on factors like demographics, seasonality, and disease trends, they optimized resource allocation and staffing levels. Improved patient care outcomes, reduced operational costs.
AI-driven forecast models are versatile and effective in various industries. Businesses can benefit from using advanced technologies for workforce planning and supply chain optimization.
AI helps organizations forecast trends and make data-driven decisions. AI-driven forecast models unlock endless value sources!
Conclusion
AI integration revolutionizes business forecasting and planning by using machine learning to analyze data, predict customer behavior, and offer real-time insights for a competitive edge. AI is important for businesses because it improves decision-making by being accurate, fast, and adaptable, despite challenges like changing roles, programming skills, and data privacy concerns.
AI-powered forecasting models are a game-changer for business strategy. Advanced systems can revitalize operations, giving businesses valuable insights and predictive capabilities. Adopting this technology is essential in today’s market. AI helps businesses adapt and grow in uncertain times. AI is crucial for business forecasting. Those who use it can reshape their trajectories and thrive in the evolving business ecosystem.
Connected devices linked to the Internet of Things (IoT) — in association with 5G network technology — are now everywhere. But just wait until next-generation applications, such as artificial intelligence (AI), start running within these edge devices. Meanwhile, the low latency and higher data speeds of 5G and IoT will add a new real-time dimension to AI.
Consider an extended reality (XR) headset that not only provides a 3D view of the inside of an aircraft engine, but which also has on-board intelligence to point you to problem areas or to information on anomalies in that engine, which are immediately and automatically recognized and adjusted.
Also: Ahead of AI, this other technology wave is sweeping in fast
Chipmakers are already developing powerful yet energy-efficient processors — or "systems on a chip" — that can deliver AI processing within a small footprint device. For instance, Qualcomm just announced AI-capable Snapdragon chips that run on smartphones and PCs. Also on the horizon are a generation of NeuRRAM chips, developed at the University of California San Diego, which are capable of running sizeable AI algorithms on smaller devices.
Overall, the global number of connected IoT devices is projected to surpass 29 billion by 2027, which is more than 16.7 billion at the present time, a recent analysis from zScaler shows. "Consumer devices are smart and most common, but business process-oriented IoT generated the most transactions," the report's authors point out. "Manufacturing and retail devices accounted for 50%-plus of transactions, highlighting their widespread adoption and business-critical function in these sectors. Enterprise, home automation, and entertainment devices are generating the highest counts of plaintext transactions."
Now, 5G and IoT technologies are opening new doors to innovation within AI — and vice versa. AI "will be more effective when enabled with a local-level decision-making framework and with near real-time data," says Arun Santhanam, vice president and head of telecommunications at Capgemini Americas. "5G low latency innovation will be key for enabling the outcome of real-time data coming from relatively inexpensive IoT solutions."
Also: If AI is the future of your business, should the CIO be the one in control?
Most viable edge and AI use cases have been in the enterprise and IoT space, within industries such as healthcare and manufacturing, says Haifa El Ashkar, director of strategy of the telecommunications market and solutions at CSG. These companies "need to offer faster data transmission and real-time communication," she says. "5G's lower latency and faster processing capabilities, coupled with edge architectures, have proven crucial for applications that require quick decision making and responsiveness."
In healthcare, for example, "there are now AI-edge-supported medical devices such as laparoscopes, allowing surgeons to leverage real-time insights and make faster decisions on life-saving measures such as identifying anomalies that might otherwise have been missed or detecting bleeding in real time," says El Ashkar. "Without 5G, these industries would be unable to tap into edge networks and offer the services needed to meet the needs of powerful critical IoT uses cases such as these."
The proliferation of AI-enabled applications and services is also amplifying the power of 5G edge applications, El Ashkar continues. "When you combine the low latency of 5G networks and AI capabilities at the edge, enterprises can access real-time decision-making," she says. "With less time needed for data to travel back and forth between devices and data centers, AI algorithms running on edge devices are now offering real-time insights and actions that can improve response and increase the amount of valuable data available to the enterprise."
AI also improves connectivity, as it "can have a dramatic impact on the reliability and efficiency of wireless networks and enable new ways of staying connected," says Milind Kulkarni, vice president and head of InterDigital's Wireless Lab. "For example, the combination of 5G, cloud, and edge computing is crucial for empowering immersive experiences on new devices in more places and the development of connected ecosystems such as the metaverse. Innovations in 5G and computing capabilities help make these experiences a reality."
Also:Businesses need a new operating model to compete in an AI-powered economy While more centralized environments — cloud and data centers — may provide computing power for immersive experiences, "they may be too far from where low-latency resources are located," says Kulkarni. "So, to take advantage of the ultra-low latency that is one of the key benefits of 5G, edge computing plays a vital role by offering smaller amounts of storage and computation much closer to the device where it's needed. In addition, edge computing can be customized to support specific use cases such as storing content for delivery of video on demand or running AI algorithms for fast decision making on incoming data."
XR is an area where the capabilities of 5G are being pushed to the limit. "Currently there is a large amount of ongoing work within 3GPP that is focused on enhancing current networks to be more aware of and better support XR traffic," says Kulkarni. "XR pushes the limits of 5G in terms of latency at very high data rates, efficient video coding and network architecture, for example by taking advantage of edge computing's benefits."
5G's high speeds and low latency "will be required for industries to transition into the next stage of digital transformation," says El Ashkar. "This is critical to industries such as supply chain, healthcare and manufacturing, where increasingly more AI-infused and connected devices are becoming vital to daily operations."
Google’s best Gemini demo was faked Devin Coldewey @techcrunch / 1 day
Google’s new Gemini AI model is getting a mixed reception after its big debut yesterday, but users may have less confidence in the company’s tech or integrity after finding out that the most impressive demo of Gemini was pretty much faked.
A video called “Hands-on with Gemini: Interacting with multimodal AI” hit a million views over the last day, and it’s not hard to see why. The impressive demo “highlights some of our favorite interactions with Gemini,” showing how the multimodal model (i.e., it understands and mixes language and visual understanding) can be flexible and responsive to a variety of inputs.
To begin with, it narrates an evolving sketch of a duck from a squiggle to a completed drawing, which it says is an unrealistic color, then evinces surprise (“What the quack!”) when seeing a toy blue duck. It then responds to various voice queries about that toy, then the demo moves on to other show-off moves, like tracking a ball in a cup-switching game, recognizing shadow puppet gestures, reordering sketches of planets, and so on.
It’s all very responsive, too, though the video does caution that “latency has been reduced and Gemini outputs have been shortened.” So they skip a hesitation here and an overlong answer there, got it. All in all, it was a pretty mind-blowing show of force in the domain of multimodal understanding. My own skepticism that Google could ship a contender took a hit when I watched the hands-on.
Just one problem: The video isn’t real. “We created the demo by capturing footage in order to test Gemini’s capabilities on a wide range of challenges. Then we prompted Gemini using still image frames from the footage, and prompting via text.” (Parmy Olson at Bloomberg was the first to report the discrepancy.)
So although it might kind of do the things Google shows in the video, it didn’t, and maybe couldn’t, do them live and in the way they implied. In actuality, it was a series of carefully tuned text prompts with still images, clearly selected and shortened to misrepresent what the interaction is actually like. You can see some of the actual prompts and responses in a related blog post — which, to be fair, is linked in the video description, albeit below the ” . . . more.”
On one hand, Gemini really does appear to have generated the responses shown in the video. And who wants to see some housekeeping commands like telling the model to flush its cache? But viewers are misled about the speed, accuracy, and fundamental mode of interaction with the model.
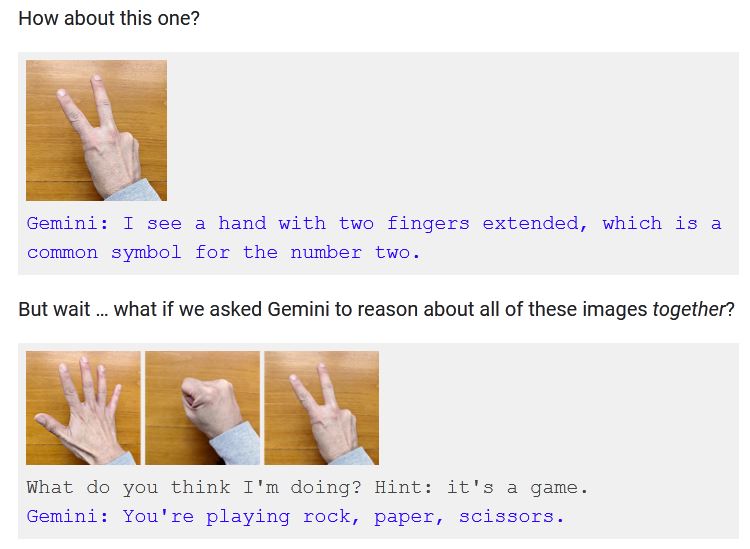
For instance, at 2:45 in the video, a hand is shown silently making a series of gestures. Gemini quickly responds, “I know what you’re doing! You’re playing Rock, Paper, Scissors!”
Image Credits: Google/YouTube
But the first thing in the documentation of the capability is how the model does not reason based on seeing individual gestures. It must be shown all three gestures at once and prompted: “What do you think I’m doing? Hint: It’s a game.” It responds, “You’re playing rock, paper, scissors.”
Image Credits: Google
Despite the similarity, these don’t feel like the same interaction. They feel like fundamentally different interactions, one an intuitive, wordless evaluation that captures an abstract idea on the fly, another an engineered and heavily hinted interaction that demonstrates limitations as much as capabilities. Gemini did the latter, not the former. The “interaction” showed in the video didn’t happen.
Later, three sticky notes with doodles of the sun, Saturn, and Earth are placed on the surface. “Is this the correct order?” Gemini says, “No, the correct order is Sun, Earth, Saturn.” Correct! But in the actual (again, written) prompt, the question is “Is this the right order? Consider the distance from the sun and explain your reasoning.”
Image Credits: Google
Did Gemini get it right? Or did it get it wrong and needed a bit of help to produce an answer they could put in a video? Did it even recognize the planets, or did it need help there as well?
In the video, a ball of paper gets swapped around under a cup, which the model instantly and seemingly intuitively detects and tracks. In the post, not only does the activity have to be explained, but also the model must be trained (if quickly and using natural language) to perform it. And so on.
These examples may or may not seem trivial to you. After all, recognizing hand gestures as a game so quickly is actually really impressive for a multimodal model! So is making a judgment call on whether a half-finished picture is a duck or not! Although now, since the blog post lacks an explanation for the duck sequence, I’m beginning to doubt the veracity of that interaction as well.
Now, if the video had said at the start, “This is a stylized representation of interactions our researchers tested,” no one would have batted an eye — we kind of expect videos like this to be half factual, half aspirational.
But the video is called “Hands-on with Gemini” and when they say it shows “our favorite interactions,” it implies that the interactions we see are those interactions. They were not. Sometimes they were more involved; sometimes they were totally different; sometimes they don’t really appear to have happened at all. We’re not even told what model it is — the Gemini Pro one people can use now, or (more likely) the Ultra version slated for release next year?
Should we have assumed that Google was only giving us a flavor video when they described it the way they did? Perhaps then we should assume all capabilities in Google AI demos are being exaggerated for effect. I write in the headline that this video was “faked.” At first I wasn’t sure if this harsh language was justified (certainly Google doesn’t; a spokesperson asked me to change it). But despite including some real parts, the video simply does not reflect reality. It’s fake.
Google says that the video “shows real outputs from Gemini,” which is true, and that “we made a few edits to the demo (we’ve been upfront and transparent about this),” which isn’t. It isn’t a demo — not really — and the video shows very different interactions from those created to inform it.
Update: In a social media post made after this article was published, Google DeepMind’s VP of Research Oriol Vinyals showed a bit more of how “Gemini was used to create” the video. “The video illustrates what the multimodal user experiences built with Gemini could look like. We made it to inspire developers.” (Emphasis mine.) Interestingly, it shows a pre-prompting sequence that lets Gemini answer the planets question without the sun hinting (though it does tell Gemini it’s an expert on planets and to consider the sequence of objects pictured).
Perhaps I will eat crow when, next week, the AI Studio with Gemini Pro is made available to experiment with. And Gemini may well develop into a powerful AI platform that genuinely rivals OpenAI and others. But what Google has done here is poison the well. How can anyone trust the company when they claim their model does something now? They were already limping behind the competition. Google may have just shot itself in the other foot.
I live in Northern California and have a new primary care doctor now. My previous primary care doctor, who has since retired, was part of the Stanford Health Care (SHC) system. My new doctor is merely in a different SHC office.
The new doctor has a very nice office, and the doctor and staff I’ve met are quite helpful. He was meticulous about noting down answers to questions he asked me during my visit in October. His notes were in addition to information his staff had collected from a comprehensive battery of forms I’d filled out and submitted online when I switched doctors within SHC.
I learned during the visit that SHC doesn’t have many recent records for me because my previous employer offered a physical exam benefit through a third party called Executive Health Exams (EHE). Fortunately, I’ve been healthy for a good long while, and I was really only going to the doctor once a year for the annual physical. So I’d just go to EHE instead of SHC, taking advantage of the benefit my previous employer was providing in the process.
A vaccination records integration tax example
The doctors and staff at EHE would also monitor my vaccination status and update my vaccinations when necessary. For example, EHE staffers gave me the Shingrex vaccine to prevent me from getting shingles, which I was at risk for because I am now in my 60s and had chicken pox when I was a child.
For some reason, my new doctor wasn’t able to find my EHE vaccination records, for example. This is even though SHC system doctors, I’ve learned from inquiring recently, do have access to Care Everywhere, which is EPIC’s medical records exchange. Care Everywhere is supposed to be a way for doctors such as my primary care doctor to view patient records generated by other providers.
In October after my visit, I went to the EHE site and requested that their records be sent to SHC. As I recall, I had requested before that EHE share those records with my previous primary care doctor’s office, as I mentioned also a SHC system.
Today I was wondering if my new SHC doctor had received the EHE records, so I called the main SHC medical records office because I assumed they manage a central records repository for a shared records service. The gentleman at the medical records office asked me how EHE sent the records, and I said I didn’t know. Were they sent by fax? I wasn’t sure. The gentleman said that if the records were faxed, that I should contact my doctor’s office directly.
I don’t know anyone besides healthcare organizations that uses a fax system anymore. It’s a bit ironic that SHC still does, given that Vint Cerf while at Stanford University was a key internet pioneer back in the 1970s.
Still navigating the thicket of interactive voice response
So I called my doctor’s office directly. The SHC phone system uses an interactive voice response (IVR) system which answers each call and reads callers at least one menu of options to route them to recorded instructions or a live person. The system’s designed to minimize the amount of time staff spends answering routine phone calls. If the caller has a frequently asked question, the IVR should be able to route them to a recording that answers their question.
If you’re in the US and an adult, you’re probably familiar with the IVR routine, which can be quite time consuming for the caller to navigate, particularly if there’s no provision for a caller to dial 0 and just get to a person directly. IVR first gained adoption in the US in the 1980s. Now a number of enterprises have dispensed with IVR and are using chatbots instead, which have their own issues.
In the case of SHC’s primary care offices, the IVR system greets a caller by saying “Thank you for calling Primary Care Stanford. If this is a medical emergency, please hang up and dial 911. Please listen carefully as our menu options have recently changed. We want to protect your health and that of those around you. If you’re calling in regards to monkeypox inquiries such as testing and vaccinations, press 6. If you’re calling in regards to COVID-19 testing and vaccinations, press 2. If you’re calling Primary Care, press 3.”
Callers must navigate through at least one and maybe two or three menu branches of options this way to go through the call routing process, and the time spent navigating is a burden placed on the shoulders of each caller. Often the menu items don’t describe what you’re looking for, and you’re faced with picking an option that seems most likely to get you to a live person so you can ask them directly for help.
Once I successfully completed the menu tree navigation process, I did connect with a staffer who noted down my query and said she’d forward it to my primary doctor’s team. At this point, I’ll wait to hear back from the team to see if SHC actually received the records.
Bottom line: The personal EHR integration tax and its healthcare industry context
Should each patient be required to become a permanent backup for the medical records integration and access process when necessary, as I have? No. I’ve spent hours prompting Stanford and EHE to get Stanford’s records up to date so my doctor’s office won’t keep asking me if I need this or that shot. My shots are up to date. Stanford needs the proof.
The previous paper-based system was actually better from the patient’s standpoint, because each patient had a shot card they owned and kept with them. Those doing the vaccinations would log each vaccination a patient received on that patient’s card. Parents would store, protect and take responsibility for their children’s shot cards along with their own. During the COVID-19 epidemic, the local county health system used a shot card system. That was the default.
Electronic health records (EHRs) have been around in some form or fashion since 1977. By 2024, the healthcare industry is forecast to spend nearly $20 billion annually on EHR systems alone. The bigger EHR implementations are multi-year projects. Florida-based AdventHealth, for example, embarked on a $660 million Epic EHR implementation in 2020, according to Freedonia Group. By the end of 2022, AdventHealth had spent $355 million on the implementation. EHR system bloat and waste is quite comparable to enterprise resource planning (ERP) system bloat and waste. And yet, EHR and ERP systems predominate, particularly among medium to large organizations.
What’s an alternative to a vendor cash cow-oriented medical records system that makes everyone else but the vendor chase after bits of scattered information? Allow each patient to own and control their own medical information via a patient knowledge graph–a modern equivalent to the shot card, but for all records. Each patient would grant access to that information via that patient’s secure Solid pod–a decentralized storage system that’s evolving from open web standards.
Providers would read and write in an authorized, secure way to the patient’s graph via apps designed to use Solid (an open standard in development) that’s access controlled by the patient. Result? Zero-copy integration and data sovereignty for personal medical information.
Why does it seem like we’re further away from this sort of human-centric information management than ever? Because enterprise information architecture is only changing gradually, at the edges. We’ll need to do much more awareness raising of the nature of the problem and the utility of the best, principled approach that respects data sovereignty — like the shot card used to, and like the original web was intended to.


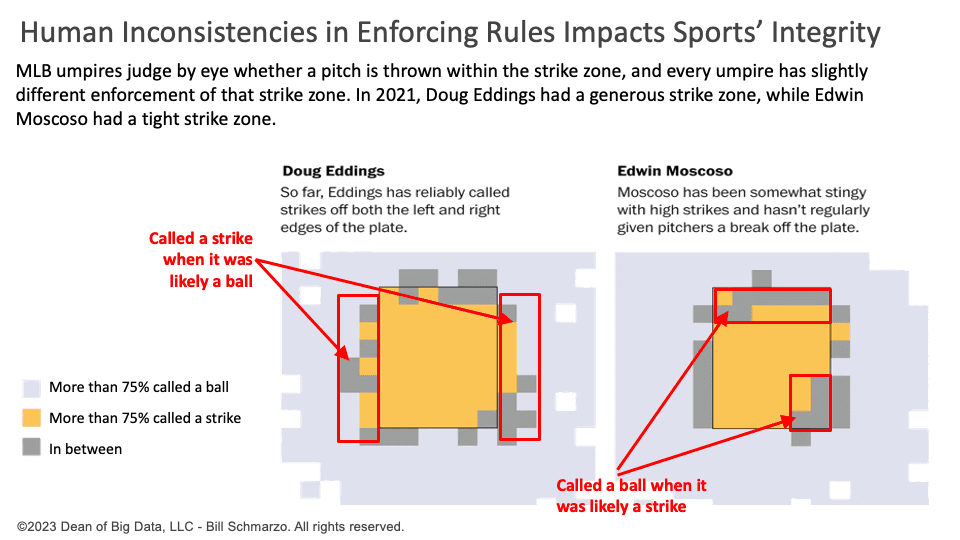
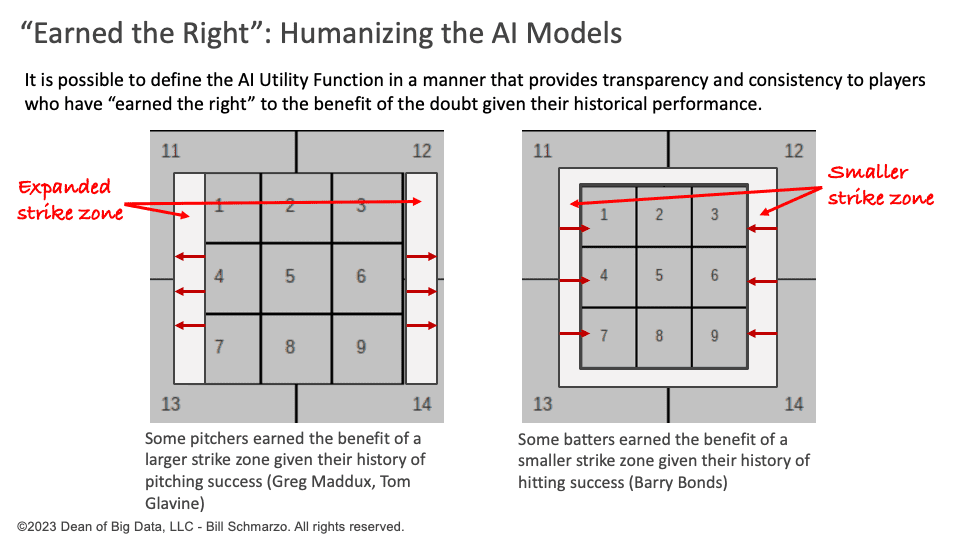




















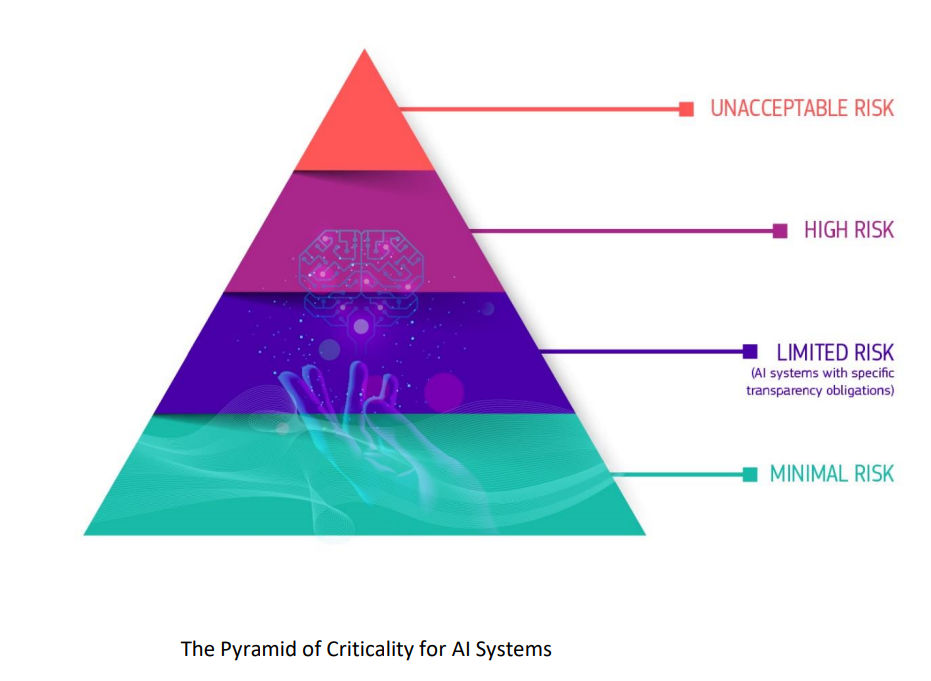
 About the author: Alex Woodie
About the author: Alex Woodie