Copilot has quickly become a vital and strategic part of the Microsoft lineup of products and services. Whether you are a large enterprise, small business or merely a regular user of a Windows personal computer, at the very least, you are likely aware of Microsoft Copilot and its generative AI capabilities.
Microsoft is currently offering three versions of Copilot to its customers:
- The free Copilot version is available to everyone using Windows, Microsoft Edge or the Bing website.
- The Copilot Pro version is also available to everyone using Windows, Microsoft Edge or the Bing website, but requires an additional $20/month subscription fee.
- The Copilot 365 version is available to Microsoft 365 subscribers who pay an additional $30/month/user subscription fee.
But which version of Microsoft Copilot is right for you and your business, and what should you know about each version besides the price of access?
Microsoft Copilot version comparison
| Feature | Microsoft Copilot | Copilot Pro | Copilot 365 |
|---|---|---|---|
| Functional operation | General questions return general answers | General questions return general answers | Specific questions return specific answers |
| Data source | Bing searches and internet | Bing searches and internet | Organizational data generated internally |
| Cost | Free | $20/user/month | $30/user/month |
| Best use casease | General users and small business | SMBs with a need for reliability and speed | SMBs and enterprises with large data pools |
How to choose the best version of Microsoft Copilot
Regardless of which version of Microsoft Copilot you decide to use, the software’s basic operation remains the same: Ask a question, get an answer. The differences between each version rest in how the AI accesses its foundational data sources and where that data comes from.
Free Microsoft Copilot
The free version of Microsoft Copilot pulls the data it uses for its natural language processing models from Bing searches and other aggregated information tracked by Microsoft. Basically, the AI’s generative results are based on internal sources, external sources via Bing Search and various custom data sources.
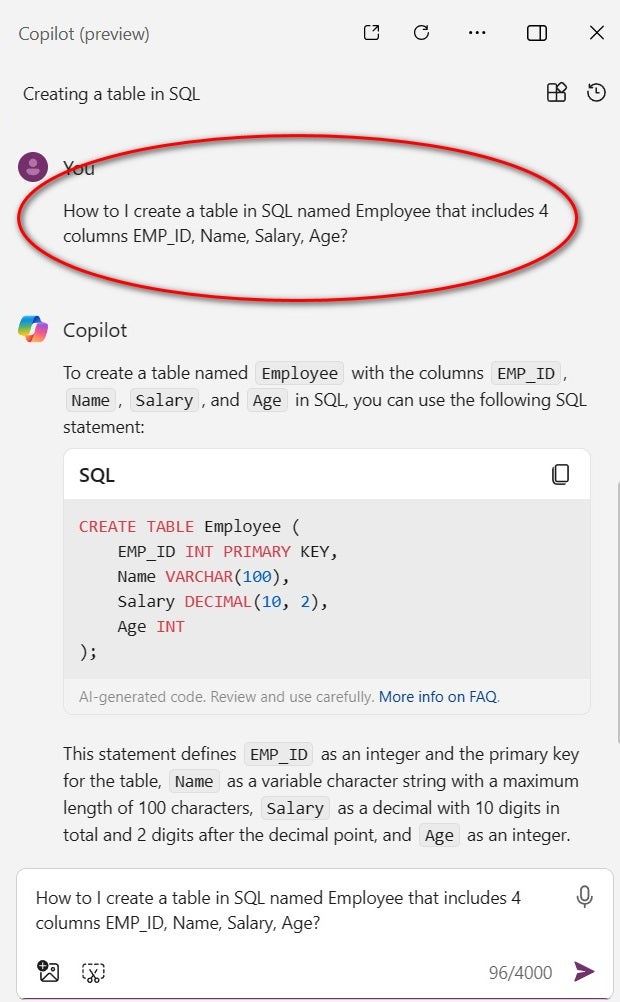
This gives the Copilot platform leeway to answer any general question (Figure A). Often, this makes it less effective when users require a specific and detailed answer to a specific and detailed question. The free version of Microsoft Copilot is intended for general use and should be used in that manner. If general answers to general questions are what you need from generative AI, then Copilot may be all you need.
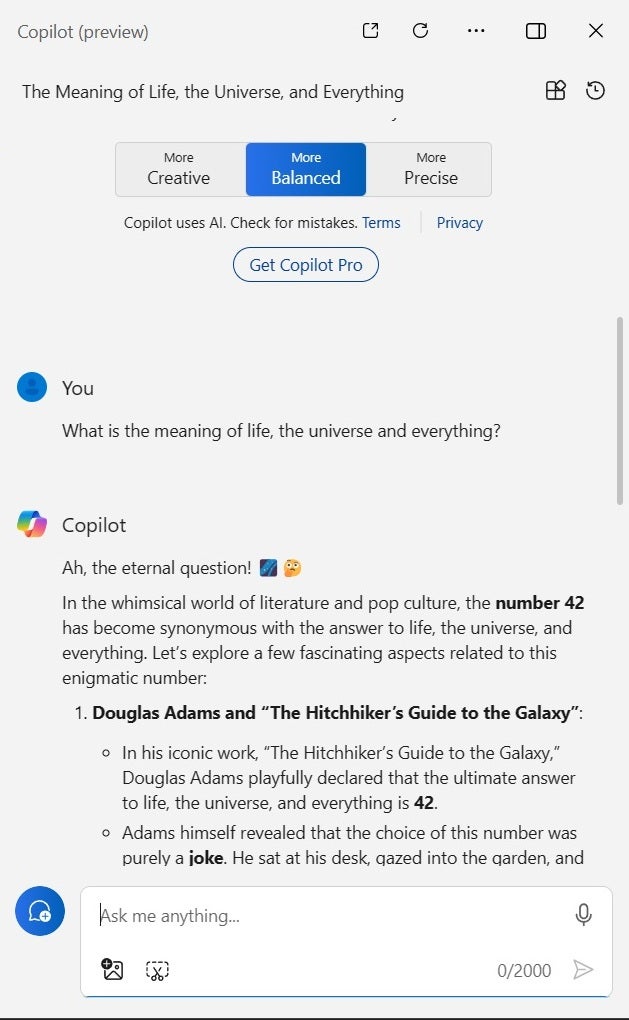
Microsoft Copilot Pro
The latest addition to the company’s generative AI line of software is called Microsoft Copilot Pro. This version of Copilot uses the same NLP models based on Bing searches and other aggregated information as the free version, but for an additional $20/user/month, the pro version grants priority access to GPT-4 and GPT-4 Turbo during peak times for accelerated performance.
In other words, Microsoft Copilot Pro will prioritize access to servers so you can get answers from its AI faster than those customers using the free version only. At least, that is the theory.
The reality is that the time difference between getting an answer from Copilot with the pro version and getting the same answer from the free version is almost negligible at this point. However, assuming AI continues to grow in popularity and use, it is possible getting an answer from Microsoft Copilot could slow down, making priority access much more appealing in the future.
If you plan to rely on Copilot for critical interactions, it might be in your best interest to pay for a subscription that grants priority access. With that said, it may also be financially prudent to wait for that need to arise first. You will have to decide which is best for your situation.
Microsoft Copilot 365
Microsoft Copilot 365 is much different from the free or Pro versions of the platform when it comes to where and how It pulls the data it uses for its NLP model. This is because Copilot 365 uses data gleaned from the data generated by the host organization.
Microsoft Copilot 365 is best used in enterprises, organizations and SMBs that generate large amounts of institutional data. By limiting what data goes into Copilot’s NLP data models, institutional customers can better control what answers the AI will generate. Think of it as easily accessible systematic institutional knowledge. Access to that institutional knowledge will cost $30/user/month, which is in addition to the normal Microsoft 365 subscription.
To illustrate the potential, consider this example. Let’s say you need to include the new official corporate logo for a sales proposal. Typically, you would email the marketing department asking for a link to the logo file; this transaction may require you to wait until the next day for a reply, possibly losing a sale. However, Copilot 365 should already know what the new official logo is and where to get it. By asking Copilot 365, you can find the official link to the new corporate logo in seconds, eliminating the need for an exchange of emails.
The caveat is that the institutional data accessed by Copilot must be accurate, vetted, verifiable and accessible. For Microsoft Copilot 365 to work effectively and efficiently, the institution involved must abandon the traditional concepts of compartmentalized and departmentalized information. For many enterprises and SMBs, this attitude adjustment with regard to data will be a large hurdle to overcome.
Microsoft Copilot 365 has the potential to be an extremely powerful tool for organizations willing to embrace the platform, the technology and the mindset required to implement it. Without that buy-in at all levels of the organization, AI also has the potential to be a terrible waste of energy, resources and time.
If your organization possesses a forward-looking collective mindset, Microsoft Copilot 365 may be exactly what you need to establish a competitive edge in your business marketplace. If implemented correctly, Copilot 365 should provide users with reliable, accurate and specific answers to specific questions. Decision makers at each organization will have to determine if the potential for solid answers is worth the implementation effort and the associated cost.
How do you choose a version of Microsoft Copilot?
The choice of which version of Microsoft Copilot will work best for you or your organization is entirely dependent on you and what you want from generative AI, including if you want nothing at all. At this point in the development cycle, the overall effectiveness of all AI platforms varies greatly. Microsoft Copilot has tremendous potential. All enterprises and SMBs should at least be experimenting with the platform.
Much like cloud computing and the Internet of Things were once technologies on the horizon, generative AI is a technology that is still in its nascent development period. But just like those innovations, AI will play a vital role in future work environments. Therefore, it will be advantageous for organizations, businesses and users — operating at all levels — to become familiar with the capabilities and limitations of Microsoft Copilot and other AI platforms.