Adobe has announced plans to integrate third-party generative AI tools, including OpenAI’s Sora, into its popular video editing software Premiere Pro.
Adobe just introduced a slew of new AI capabilities coming to Adobe Premiere Pro. – New AI-powered tools in Premiere Pro – A new proprietary AI model called Firefly Video – Third-party AI model integrations with OpenAI, Runway, and Pika Labs pic.twitter.com/O61bYl6Z6N
— Rowan Cheung (@rowancheung) April 16, 2024
Adobe is exploring partnerships with leading AI providers like OpenAI’s Sora, RunwayML, and Pika. This open approach aims to give users the flexibility to choose AI models that best suit their workflow needs, the company said in its blog.
Deepa Subramaniam, Adobe’s vice president of product marketing for creative professional apps, said that Adobe hasn’t finalised the revenue-sharing arrangement for third-party AI tools on its platform.
The US-based software company also announced that it is developing a new Firefly Video Model that will join the already released Firefly Image, Vector, Design, and Text Effects Models.
Adobe is providing a compensation of $120 to its community of photographers and artists for submitting videos depicting ordinary activities like walking or various emotions such as joy and anger to train its model, according to recent reports.
Adobe is seeking over 100 short clips of people in actions, emotions, and simple anatomy shots, excluding copyrighted or offensive content. The payment averages $2.62 to $7.25 per minute of submitted video.
The company has also introduced new generative AI tools to Premiere Pro, one of which is Generative Extend. This tool can be used to make shots a little longer by generating entirely new frames at the beginning or end of a clip.
New AI tools in Premiere Pro, like Object Addition/Removal, simplify object editing in shots by replacing moving objects, removing unwanted items, or adding set dressings. Generative B-Roll feature creates custom video clips with simple text prompts, reducing time spent on finding suitable footage.
Adobe is also introducing ‘Content Credentials,’ which will label the videos created by generative AI and specify the models used in the media that users are viewing. Content Credentials will be supported inside Premiere Pro, to help create a chain of trust from creation to editing to publication.
The post Adobe Adds OpenAI’s Sora, RunwayML, and Pika to Premiere Pro appeared first on Analytics India Magazine.
In a surprising announcement today, Microsoft has revealed a strategic investment of $1.5 billion in G42, UAE-based AI technology holding company. The partnership announcement also disclosed that Brad Smith, Vice Chair and President of Microsoft, will now serve on the G42 Board of Directors.
The investment aims to fortify the partnership between G42 and Microsoft, with a particular focus on expanding AI technologies and skilling initiatives not only in the UAE but also across the globe. Under this collaboration, G42 will run its AI applications and services on Microsoft Azure, facilitating the delivery of advanced AI solutions to global public sector clients and large enterprises.
“Microsoft’s investment in G42 marks a pivotal moment in our company’s journey of growth and innovation, signifying a strategic alignment of vision and execution between the two organizations. This partnership is a testament to the shared values and aspirations for progress, fostering greater cooperation and synergy globally,” said H.H. Sheikh Tahnoon bin Zayed Al Nahyan, chairman of G42.
Beyond Borders
The collaboration between G42 and Microsoft extends beyond technology deployment, and the partners are committed to bringing advanced AI and digital infrastructure to countries in the Middle East, Central Asia, and Africa.
“Our two companies will work together not only in the UAE, but to bring AI and digital infrastructure and services to underserved nations. We will combine world-class technology with world-leading standards for safe, trusted, and responsible AI, in close coordination with the governments of both the UAE and the United States,” said Smith.
Further, the partnership will also support and promote the development of skilled and diverse AI workforce and talent pool. The investment of $1 billion into a development fund specifically for developers underscores the commitment to fostering talent in AI-related fields.
G42 Partnering with the Tech Giants
Last year, G42 announced their strategic partnership with OpenAI, where the company spoke about leveraging OpenAI’s generative AI models for UAE’s financial services, energy, healthcare and many other sectors.
G42 Group CEO Peng Xiao and OpenAI CEO and co-founder Sam Altman. Source: G42
Interestingly, MGX, an AI-focused investment company in Abu Dhabi, was in talks to invest in OpenAI’s chip venture. MGX is also led by G42’s Sheikh Tahnoon.
G42 had also partnered with IBM through its G42 Cloud subsidiary, and recently, the Jais-13b- chat foundation model is available on IBM WatsonX. The Jais Arabic LLM is made by Core42, which is owned by G42.
The post Microsoft Invests $1.5 billion in UAE-based AI Company G42 appeared first on Analytics India Magazine.
Empowering educators with AI is a crucial step towards providing access to quality learning resources and ensuring equitable opportunities for all students.
Over the years, several initiatives have been mushrooming in the space. For instance, The Connect Institute’s Ujjwal Shiksha recently empowered educators to customise their teaching methodologies. This would ensure that each student’s unique learning requirements are addressed, thus optimising their academic and personal growth.
Here, they are redefining student assessments through data and analytics, and providing educators with comprehensive insights into students’ overall performance. This data-driven approach enables them to design personalised plans, ensuring that every student receives the necessary support to improve.
Working along similar lines, the Bharti Airtel Foundation has introduced ‘TheTeacherApp’, a platform for teachers to explore and learn high-quality content.
At The Rising 2024, Mamta Saikia, CEO of Bharti Airtel Foundation, highlighted the organisation’s progress, stating, “We designed the app acknowledging the demand for high-quality information and a safe place to connect with other educators.
“Initially, we collaborated with 15,000 teachers in rural areas. Within 6-8 months, the number has surged to 35,000 teachers actively participating. Remarkably, these educators have also played a significant role in crafting courses for our educational app”, she added.
Another interesting initiative is Infinity Learn’s VISTA (Virtual Intelligent System for Tailored Academics), designed to harness AI to address the issues encountered by both educators and learners. The objective of the initiative is to “Empower Educators for Tomorrow”.
From conceptualising lesson plans to identifying resources and extracting insights, the tool ensures educators are equipped with the most-advanced digital tools, enabling them to recalibrate their teaching strategies for a new era.
AI for Education
Promising a new frontier in learning, Khanmigo, an AI-powered teaching assistant built upon OpenAI’s large language model, was launched in March 2023. Functioning as a virtual tutor, the Khan Academy-built teaching assistant embodies the qualities of a nurturing teacher, guiding students through their learning endeavours with precision and care.
Utilising advanced AI algorithms, Khanmigo tailors its approach to each student, providing customised pathways to understanding and mastery. Just like a dedicated educator, Khanmigo leads individual learners toward the correct answers through a series of logical and educational steps, fostering knowledge acquisition, critical thinking, and problem-solving skills.
Can India Close the Literacy Gap Book?
As per the 2011 Census data, the literacy rate stood at 84.1% in urban areas, whereas it was notably lower at 68.9% in rural regions. Therefore, integrating AI technology into education becomes crucial to narrow this gap and equip every child with the essential skills and knowledge to succeed in the digital era.
In 2023, CBSE incorporated AI as a skill module for Grades 6–8 and as a skill subject for Grades 9–12. Currently, several organisations are developing virtual assistants for educators, parents, and students to enhance learning experiences.
These advancements include personalised tutoring for individual students, translating textbooks into local dialects to break language barriers, and updating educational resources to align with current curriculum standards.
The post Leveraging AI in Indian Rural Education appeared first on Analytics India Magazine.
Data Automation Tools play a crucial role in transforming how businesses handle data. They offer advanced functionalities that streamline data management processes, enabling organizations to enhance efficiency and accuracy. By automating tasks such as data entry, validation, and analysis, these tools reduce manual intervention and minimize the risk of errors. Moreover, data automation tools provide real-time insights, support scalability, and empower businesses to make informed decisions swiftly. As organizations strive to stay competitive in today’s data-driven landscape, leveraging data automation tools becomes imperative for optimizing operations and driving growth.
The importance of data in business
Data stands at the heart of modern business operations, driving decision-making, uncovering trends, and providing valuable insights into customer behavior. In an increasingly digital world, the ability to gather and analyze data accurately and efficiently can set a company apart from its competitors. Traditional manual and labor-intensive data handling methods can lead to bottlenecks, inaccuracies, and missed opportunities. Businesses are confronted with the challenge of managing vast amounts of data, necessitating the adoption of more sophisticated approaches to data handling. The efficient management of data is not just a logistical necessity; a strategic asset that enables businesses to respond dynamically to market changes, understand customer needs better, and tailor their strategies accordingly. As such, the importance of data in business cannot be overstated—it underpins every strategic decision, shapes marketing campaigns, and influences product development, making it crucial for sustained competitive advantage.
Introduction to data automation tools
Data automation tools are innovative solutions designed to simplify the complex business data management process. Using tools to collect, process, and analyze automatically, these tools help businesses streamline operations, ensuring data is handled efficiently and accurately. At their core, data automation tools are about minimizing manual intervention, reducing the risk of errors, and allowing people to concentrate on more important work. These tools vary widely in functionality, from automating data entry and validation to sophisticated analysis and reporting capabilities. The essence of data automation is in its power to quickly and dependably turn primary data into valuable knowledge. By using these tools, businesses can improve their decisions and operational efficiency and gain a competitive edge in their respective markets. Data automation tools are, therefore, not just about managing data more effectively; they’re about redefining what’s what’s possible in business intelligence and strategy.
Benefits of data automation in business strategy
Data automation significantly enhances business strategy, offering numerous advantages that streamline operations and boost decision-making. Here are the key benefits:
Reduces Human Error: Automating data tasks ensures accuracy, eliminating standard data entry and processing mistakes.
Saves Time: Frees up staff from manual data handling, allowing them to focus on strategic tasks and innovation.
Provides Real-Time Insights: Enables businesses to make swift, informed decisions by delivering up-to-the-minute data.
Supports Scalability: Handles increasing data volumes efficiently as businesses grow without a proportional increase in manual labor or costs.
These points highlight how data automation optimizes current processes and lays the groundwork for future growth and innovation. By leveraging these tools, businesses can navigate the digital landscape more effectively, turning data into a strategic asset that drives success and competitiveness.
How automation tools are changing business models
Automation tools significantly reshape business models by enabling companies to leverage data-driven strategies effectively. In the past, business models were often constrained by the limitations of manual data processing, which could be slow and error-prone. Today, the integration of automation tools allows businesses to pivot and adapt to market demands with unprecedented speed and efficiency. These tools facilitate the creation of new business models centered around real-time data analysis and insight-driven decision-making. For instance, companies can now offer personalized services at scale, thanks to automated data analysis that identifies customer preferences and behaviors. Similarly, businesses can optimize their operations and supply chains by analyzing real-time data streams, reducing costs, and improving service delivery. This shift towards data-centric business models enhances operational efficiency and opens up new avenues for innovation, customer engagement, and competitive differentiation, fundamentally changing how businesses operate and deliver value.
Implementing data automation in your business
Implementing data automation in your business begins with understanding your specific data challenges. It involves identifying the areas where automation can have the most significant impact. Begin by assessing your current data management processes to pinpoint inefficiencies or bottlenecks that could benefit from automation. Once these areas are identified, research and select data automation tools that align with our business needs. Considering how easy it is to use and integrate current systems and their ability to grow.
Teaching your team how to use the new tools is essential for a seamless change and to get the most out of automation. Provide comprehensive training sessions covering how to use the tools and best practices for data management and security. Additionally, implementing data automation should be a phased process, starting with small, manageable projects before scaling up. This approach allows you to adjust and refine your strategy based on initial results and feedback. Ensuring a successful integration of data automation into your business operations.
Challenges and considerations
Implementing data automation comes with its challenges and considerations. Initial setup and integration costs can be significant, and businesses must weigh these against the long-term benefits. Staff training is another crucial aspect. As employees need to adapt to new technologies and workflows, which can initially disrupt productivity. Additionally, selecting the right automation tools that fit seamlessly into existing systems and processes requires careful evaluation. Security and data privacy are also paramount, with businesses needing to ensure that automated systems comply with regulatory standards. Despite these challenges, with thoughtful planning and execution, the advantages of data automation can far outweigh the hurdles. Leading to improved efficiency and strategic insight.
Final words
Data automation is a transformative force in the business landscape, offering a pathway to enhanced accuracy, efficiency, and strategic decision-making. By embracing these tools, companies can navigate the complexities of modern data management. Ensuring their business models remain agile and competitive in the ever-evolving market.
Machine learning in FinTech is a critical enabler in tech-driven banking, where efficiency and innovation are key to staying ahead of the competition. It transforms obstacles into lucrative possibilities by revolutionizing crucial areas such as risk management, fraud detection, algorithmic trading, and compliance.
In the year that artificial intelligence (AI) had its most spectacular public debut, it might look like machine learning (ML) has been reduced to a fad.
However, it is the furthest thing possible from the truth. Even if it might not be as popular as before, machine learning is still very much in demand today. This is so that deep learning may be used to train generative AI. FinTech is no exception.
With a projected global market size of about US$158 billion in 2020 and rising at an 18% compound annual growth rate (CAGR) to reach a staggering $528 billion by 2030, machine learning is one of the most valuable tools available to financial institutions for process optimization. And in the end, as our most recent State of AI study goes into great depth, save expenses.
Use cases of machine learning in FinTech
Machine learning is solving some of the industry’s core issues. Fraud, for instance, affects more than simply insurance or cryptocurrencies. Furthermore, strong regulatory compliance transcends domain boundaries. Regardless of your industry or type of business, machine learning in finance offers a variety of ways to convert concerns into gains.
1. Algorithmic trading
Many businesses employ the very successful tactic of algorithmic trading to automate their financial choices and boost transaction volume. It entails carrying out trading orders following pre-written trading directives made possible by machine learning algorithms. Since it would be hard to replicate the frequency of trades done by ML technology manually, every significant financial company invests in algorithmic trading.
2. Detecting and preventing fraud
Machine learning solutions in FinTech constantly learn and adapt to new scam patterns, improving safety for your company’s operations and clients. This is in contrast to the static nature of classic rule-based fraud detection.
Algorithms for machine learning can identify suspicious activity and intricate fraud patterns with great accuracy by examining vast datasets.
IBM demonstrates how machine learning (ML) can identify fraud in up to 100% of transactions in real-time, allowing financial institutions to minimize losses and take prompt action in the event of danger.
FinTech systems that use machine learning (ML) can detect numerous forms of fraud, including identity theft, credit card fraud, payment fraud, and account takeovers. This allows for complete security against a wide range of threats.
3. Regulatory compliance
Regulatory Technology (RegTech) solutions are among the most popular use cases of machine learning in banking.
ML algorithms can identify correlations between recommendations since they can read and learn from huge regulatory papers. Thus, cloud solutions with integrated machine-learning algorithms for the finance sector can automatically track and monitor regulatory changes.
Banking organizations can also keep an eye on transaction data to spot irregularities. ML can guarantee that consumer transactions meet regulatory requirements in this way.
4. Stock market
The massive volumes of commercial activity generate large historical data sets that present endless learning potential. But historical data is just the foundation upon which forecasts are built.
Machine learning algorithms look at real-time data sources such as news and transaction results to identify patterns that explain the functioning of the stock market. The next step for traders is to choose a behavioral pattern and determine which machine learning algorithms to incorporate into their trading strategy.
5. Analysis and decision making
FinTech uses machine learning to handle and understand large amounts of data reliably. Through the integration of data analytics services, it offers thoroughly investigated insights that expedite real-time decision-making while saving time and money. Additionally, this technology improves the speed and accuracy of forecasting future market patterns.
FinTech companies can also use predictive analytics technologies to develop innovative, forward-thinking solutions that adapt to shifting consumer demands and market trends. With the help of data analytics and machine learning services working together, FinTech companies can foresee and successfully address new financial needs thanks to this proactive strategy.
How do companies benefit from machine learning in FinTech?
The above points highlight the use cases of machine learning, but what about the specifics? How may the main advantages of ML in FinTech be best summarized if limited to a small number of objective bullet points?
1. Automating repetitious processes
Automation is likely the most obvious machine learning benefit for FinTech, having several advantages. To validate client information in real-time without requiring manual input, for example, machine learning algorithms can expedite the customer onboarding process.
Furthermore, by doing away with the necessity for human data entry, automating the reconciliation of financial transactions saves time and money. The rest of your team will benefit from automation in more subtle ways. ML-driven automation removes the tedious work that prevents your professionals from working on more important projects.
2. Allocation of resources
Through pattern recognition, machine learning establishes the best allocation of funds, labor, and technology. As said before, robo-advisors use machine learning (ML) in FinTech investment management to assess each client’s risk profile and allocate assets ensuring each client’s portfolio is in sync with their financial goals and risk tolerance.
Furthermore, chatbots powered by machine learning offer round-the-clock customer care by allocating resources efficiently to handle a high volume of consumer inquiries. In this way, FinTech companies can increase the scope of their offerings without significantly increasing operating costs.
3. Reducing cost through predictive analytics
FinTech companies can find opportunities for cost reduction with the help of machine learning-driven predictive analytics. For instance, in lending machine learning (ML) can predict loan defaults, enabling lenders to spend resources more effectively to reduce prospective losses.
Another financial location uses customer pattern research to create a similar situation. Businesses may proactively retain customers and lower the cost of recruiting new ones by using machine learning to predict customer turnover.
4. Data processing
FinTech software development companies can leverage technologies like optical character recognition (OCR) and other automated document processing systems to extract important data-driven insights, as machine learning handles large-scale data processing and analysis.
This greatly reduces a company’s reliance on sizable data analysis teams and related costs by automating processes such as processing loan applications, Know Your Customer (KYC) checks, and regulatory compliance.
Case studies of implementation of machine learning in FinTech
Machine learning has been offering value to the FinTech software development industry. Here are some great case studies around the globe.
1. Credgenics
In 2022, Credgenics, an Indian SaaS startup specializing in legal automation and debt collection, attained a $47 billion total loan book, having processed over 40 million retail loans.
Over 100 enterprise customers have benefited from lower costs and collection times, increased legal efficiencies, and higher resolution and collection rates because of their machine learning-powered solutions.
2. The contract intelligence of JPMorgan Chase
In 2017, the biggest bank in the US unveiled a contract intelligence (COiN) platform that heavily leveraged natural language processing (NLP) to enable computers to understand voice and handwriting.
The primary goal of COiN was to automate labor-intensive, repetitive manual processes, like reviewing commercial credit agreements, which was estimated to require up to 360,000 labor hours in the instance of JPMorgan Chase. COiN could complete the task in a few seconds.
3. Wells Fargo
Wells Fargo is a worldwide financial services firm headquartered in the United States that employs machine learning solutions such as NLP, deep learning, neural networks, and predictive analytics enablers to handle individual and bulk client data points.
What makes this noteworthy? The capacity to identify the intent behind a customer’s phrasing in complaints, which may be overlooked during a typical transcript reading. This enables the organization to streamline operations, provide more efficient services, and foster stronger client relationships.
Conclusion
FinTech is not one of several professional industries concerned about AI apocalypses. That is not to say that trading organizations aren’t concerned about the potential ramifications of AI-powered false data — or that FinTech professionals aren’t keeping an eye on things.
However, none of the faster rate of modernization forced by technology is unique to FinTech. It’s in the name of technology that drives FinTech ahead and keeps it together. It is what differentiates the FinTech workforce as one of the most technologically advanced in any industry. To many, that is what drew them into FinTech in the first place. Our experts are intimately familiar with the situation.
Data is crucial for your business—it helps with decisions and growth. But sometimes, it’s stuck in different places and hard to use. Implementing an ETL Pipeline is like sharpening that blurry map and fixing the broken compass—it turns frustration into clarity!
But there’s good news! An ETL pipeline can help. It’s like an island of hope in this mess. It can organize your data, turn it into useful information, and help your business succeed. Let’s get started and make your data work for you.
Define your destination: Start with the end in mind
Building an ETL pipeline requires a clear roadmap, and that roadmap starts with a precise destination. This guiding principle is crucial for ensuring your pipeline delivers the right data in the right format to the right people at the right time.
1. Understand the business problem:
The first step is to delve into your pipeline’s problem. What business question are you trying to answer? What insights do you need to generate?
2. Identify the stakeholders:
Who will be consuming the data delivered by your pipeline? Are they data analysts, business intelligence teams, or executives making strategic decisions?
3. Define the data requirements:
What specific data points are needed to solve the identified problem? This step involves detailing the data fields, definitions, and expected format.
4. Choose the destination system:
Where will the processed data reside? Common destinations include data warehouses, data lakes, cloud-based platforms, or enterprise resource planning (ERP) systems.
5. Outline the transformation needs:
What transformations will make the extracted data usable in the chosen destination system? This step in the ETL process could involve cleaning and filtering data, joining datasets, applying calculations, or standardizing formats.
6. Document your decisions:
Clearly document your choices for each step mentioned above. This roadmap becomes a valuable reference point for the pipeline’s development, testing, and future maintenance.
Choose wisely: Pick the right tools for the job
Choosing the right ETL tool is like selecting the perfect glue – it holds everything together seamlessly and ensures smooth data flow. But with many options, picking the right ETL tool can be overwhelming.
Here are some factors to help when choosing your ETL tool:
1. Data volume and complexity:
Low-volume, simple data: Open-source options like Airflow or Luigi might suffice.
High-volume, complex data: Consider enterprise-grade tools like Informatica PowerCenter or IBM DataStage for robust features and scalability.
2. Budget and licensing:
Open-source tools: Free to use but require in-house expertise for development and maintenance.
Commercial tools: Paid licenses come with support and pre-built connectors but can be expensive.
3. Ease of use and user interface:
Visual drag-and-drop interfaces: Ideal for beginners or business analysts requiring low coding.
Code-based tools: Offer greater flexibility and customization for experienced developers.
4. Scalability and future needs:
Cloud-based solutions: Scale effortlessly to handle increasing data volumes.
On-premise solutions: Provide greater control and security but require dedicated hardware.
5. Feature set and integrations:
Pre-built connectors: Simplify data extraction and loading from various sources.
Built-in transformation capabilities: Reduce the need for external tools and coding.
Modularize your masterpiece: Divide and conquer
Identify modules: Divide your pipeline into logical units based on functionality. Each module should perform a specific transformation, like data extraction, filtering, joining, or loading.
Define interfaces: Clearly define how modules interact with each other. Input and output data formats, flow patterns, and error-handling mechanisms should be well-documented.
Encapsulate logic: Each module should be self-contained, with its code, dependencies, and configuration. This ensures isolation and minimizes code dependencies.
Choose reusable components: Opt for libraries and frameworks with pre-built components for common tasks, reducing development time and improving code quality.
Version control: Track changes and manage different versions of each module. Version control allows for rollbacks, experimentation, and collaboration.
Test as your data depends on it
Testing your ETL pipeline isn’t just an option; it’s a must! That’s why we need to verify every step of the way:
Data extraction: We double-check that the data coming from its source is exactly what we need and there are no missing or incorrect pieces.
Data transformation: We test all the calculations and adjustments applied to the data to ensure they’re accurate and make sense. Imagine following a recipe – you wouldn’t add the wrong spice or skip a step, would you?
Data loading: Finally, we ensure the transformed data lands safely in its final destination, like putting a perfectly cooked dish on the right plate. No spills, no missing ingredients, just pure data goodness!
Automate your processes
Automate as much as possible. Almost any repetitive task in your pipeline can be automated. Here are some common examples:
ETLPipeline Scheduling: Set your pipeline to run automatically at specific times, like every hour or day, ensuring your data is always fresh and up to date.
Data Monitoring: Implement automated tools to continuously check your data quality and health, informing you of potential issues.
Alerting and Notification: Automatically send alerts via email or text whenever errors occur or key metrics change, empowering you to take immediate action.
Error Recovery: Automate recovery processes to fix minor errors automatically and bring your pipeline back online without manual intervention.
Monitor and measure
Your ETL pipeline has many moving parts, but some key metrics to keep an eye on include:
Job Duration: How long does it take your pipeline to run? Long running times might indicate inefficiencies or bottlenecks.
Data Volume: How much data is your pipeline processing? This helps you understand resource usage and plan for future growth.
Transformation Accuracy: Are your calculations and transformations happening correctly? Monitoring ensures reliable data.
Data Completeness: Are all the expected data points present and accounted for? Incomplete data can lead to misleading insights.
Error Rates: How often do errors occur during processing? Keeping track helps you identify and fix problem areas.
Evolve and adapt
In the world of data management, your ETL pipeline isn’t static; it needs to change and grow as circumstances do. It’s important to avoid relying on a rigid setup that can’t handle shifts in data patterns.
Adapting your pipeline isn’t complicated:
Modular Approach: Break your pipeline into parts, making adding or changing elements for new data or tasks easy.
Monitor: Monitor your pipeline’s performance to know when to make adjustments.
Stay Updated: Learn from industry events and new tools to keep your pipeline modern.
Clean Code: Regularly tidy up your code to keep your pipeline efficient and flexible.
Automate: Let automation handle routine tasks so you can focus on making meaningful changes.
Conclusion
Creating reliable and efficient ETL pipelines requires careful planning, informed choices, and best practice implementation. By following these tips, you can build data pipelines that are the envy of your peers, empowering data-driven decisions and propelling your organization forward. Now go forth, data wranglers, and conquer that ETL jungle!
Think of a battlefield — not filled with soldiers but cyber warriors. The Defense Industrial Base (DIB) stands as the front line. This digital battleground faces nonstop cyberattacks, each one getting trickier.
Here, the Department of Defense uses the Cybersecurity Maturity Model Certification (CMMC) 2.0 program to protect sensitive, unclassified information.
The stakes are enormous; one compliance slip could cost defense contractors their contracts and threaten national security. Non-compliance ripples damage reputations and shakes trust in our defense network. So, achieving CMMC compliance fortifies our nation’s cybersecurity.
CMMC is mandatory for all contractors handling Controlled Unclassified Information (CUI) in the Defense Industrial Base (DIB). It standardizes cybersecurity to protect sensitive government data. Not complying with CMMC risks losing defense contracts, fines, and reputation damage.
Good news though? Avoiding these common mistakes streamlines your CMMC compliance journey, achieving the needed security stance.
5 common mistakes to avoid in CMMC compliance
Image Source
1. Lack of planning and understanding
Keeping up with cybersecurity rules is challenging. Lots of groups find it hard. Their struggle isn’t from not trying. The CMMC regulations are tricky. They call for careful watch. Thoughtful planning is critical.
Take an aerospace supplier as an example. They may try their best. But CMMC’s demands are complex. Just looking at requirements isn’t enough. Their approach may have gaps. Their cybersecurity isn’t fully protected. It happens to many companies. They underestimate the challenge.
A defined roadmap for CMMC compliance isn’t optional — it’s crucial for business survival. Without one, organizations are defenseless against cyber threats. A comprehensive plan aligns cybersecurity practices into an integrated, fortified structure to fend off digital attacks.
Studies show most assessed companies fail key controls. It shows the danger of underestimating CMMC. Hope alone won’t work. Ignorance puts you at risk. Complying takes informed choices, robust planning, commitment to protecting defense systems.
2. Limited stakeholder buy-in
The CMMC compliance process needs coordination across departments, like instruments creating a symphony. With no conductor — executive backing — the melody becomes chaos. Many firms fail to meet requirements due to undervaluing stakeholder buy-in.
A survey shows that nearly half of aspiring CMMC-compliant organizations face challenges from insufficient executive support. This lack of commitment often stems from misunderstanding the comprehensive CMMC demands. Without top-level commitment, securing needed resources and cultivating a cybersecurity culture suffers.
Effectively communicating CMMC objectives and processes resonates stakeholder roles in safeguarding national security. Illustrate how compliance (or non-compliance) directly impacts the organization’s future prospects.
One defense firm fostered robust stakeholder engagement through educational workshops, empowering employee ownership. As a result, they achieved CMMC compliance enhanced cybersecurity posture, setting a new industry benchmark.
3. Incomplete gap assessment
Image Source
A gap assessment is an essential step to achieve CMMC compliance. However, many organizations rush through this process, overlooking crucial security vulnerabilities. This careless approach is risky like leaving doors unlocked in an unsafe neighborhood.
A comprehensive gap assessment is a critical process that strengthens an organization’s defenses against cyber threats. For example, a defense contractor might rush through their gap assessment to meet deadlines. Later, they could discover significant system vulnerabilities they missed.
Such oversights can lead to data breaches, exposing sensitive information. Recent findings show many organizations have failed to identify and address all security vulnerabilities during gap assessments. The need for a thorough gap assessment cannot be emphasized enough. It exposes weak links in an organization’s cybersecurity and provides a plan to address them.
Without this, organizations remain vulnerable to sophisticated cyberattacks targeting the DIB. A robust defense requires a meticulous gap assessment involving a detailed examination of current practices, a comparison with CMMC requirements, and a targeted action plan to resolve deficiencies.
4. Insufficient resource allocation
The path to CMMC compliance isn’t just intentions but demands substantial resource commitment. Aligning cybersecurity practices with CMMC’s stringent standards is hugely complex, requiring dedicated teams, adequate budgets, and continuous improvement focus.
Consider a small defense contractor underestimating necessary compliance resource allocation. Minimal budgeting and personnel, assuming existing staff could absorb extra workload. Yet CMMC intricacies quickly overwhelm limited resources, causing significant delays and partial measures failing DoD’s strict requirements.
Conversely, a larger organization may recognize CMMC’s resource-intensive nature. Strategically, it’ll increase cybersecurity budgets and expand teams with compliance and maintenance roles. By foreseeing required compliance requirements, they can achieve a high level of compliance, enhancing their overall posture and making them more attractive to DoD contracting partners.
5. Going it alone
Image Source
The CMMC compliance journey requires professional guidance; attempting it alone is akin to sailing uncharted waters without a navigator. Navigating the CMMC framework’s complexity and breadth can overwhelm, with high risks of misinterpretation or oversight.
Professionals provide the needed expertise and clarity for effectively navigating the intricate requirements. Organizations seeking professional assistance report a smoother, more efficient path to compliance. They gain expert insights into the CMMC framework’s nuances, particularly complex at higher levels with stringent requirements.
Companies with compliance consultants improved cybersecurity posture more than those without. Leveraging available resources and assistance programs eases the compliance burden.
The CMMC Accreditation Body’s marketplace, local Procurement Technical Assistance Centers (PTACs), and DoD Small Business Offices (SBOs) offer invaluable support, connecting businesses with funding, training, and guidance for CMMC implementation.
Final take
The CMMC compliance journey seems challenging, but possible with help. Don’t try alone – use experts and tools for smoother sailing. It guards vital data and keeps the defense chain secure. Need more info? ComplianceForge has thorough policy guides to ace your CMMC demands.
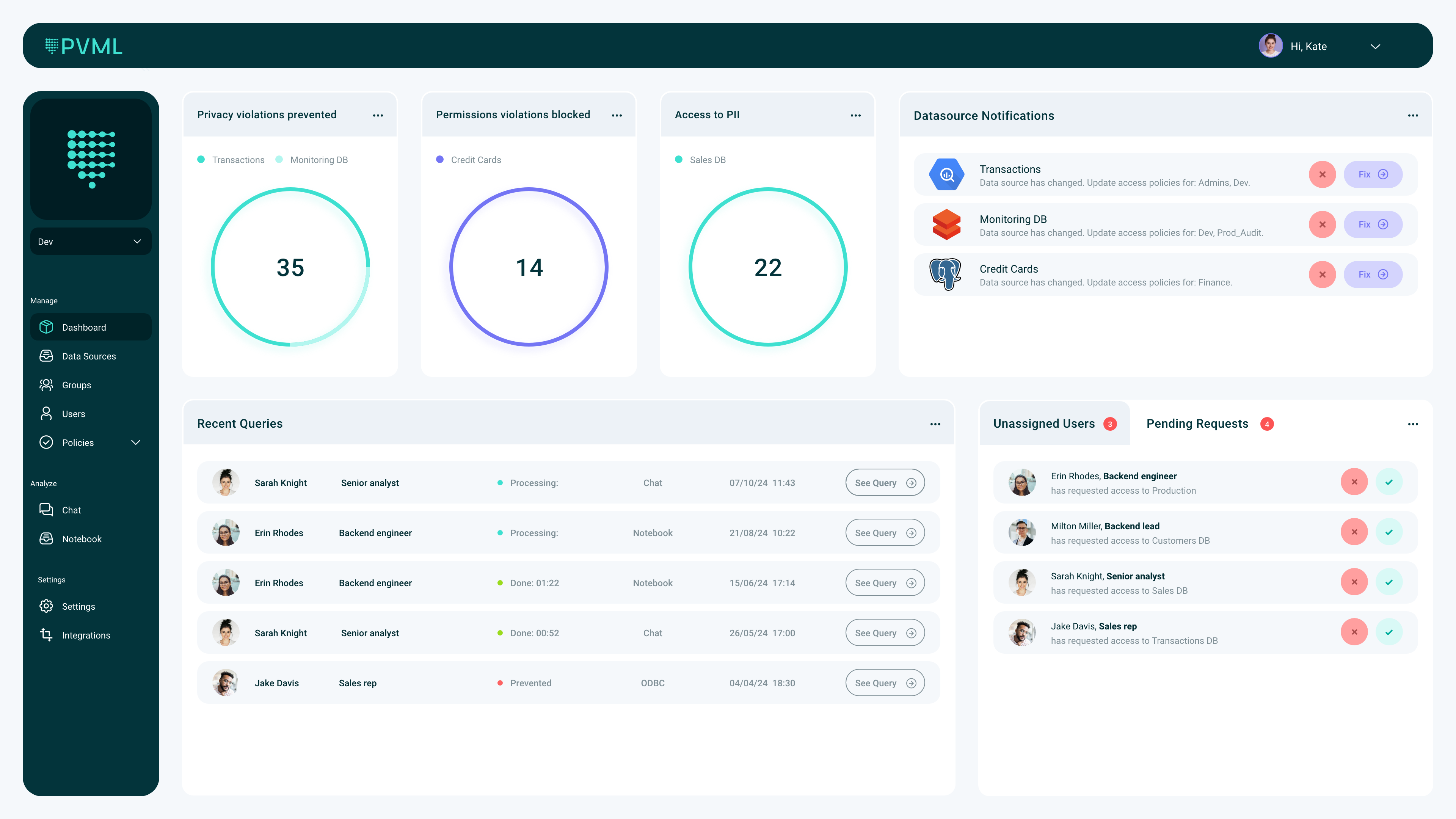
PVML combines an AI-centric data access and analysis platform with differential privacy Frederic Lardinois @fredericl / 8 hours
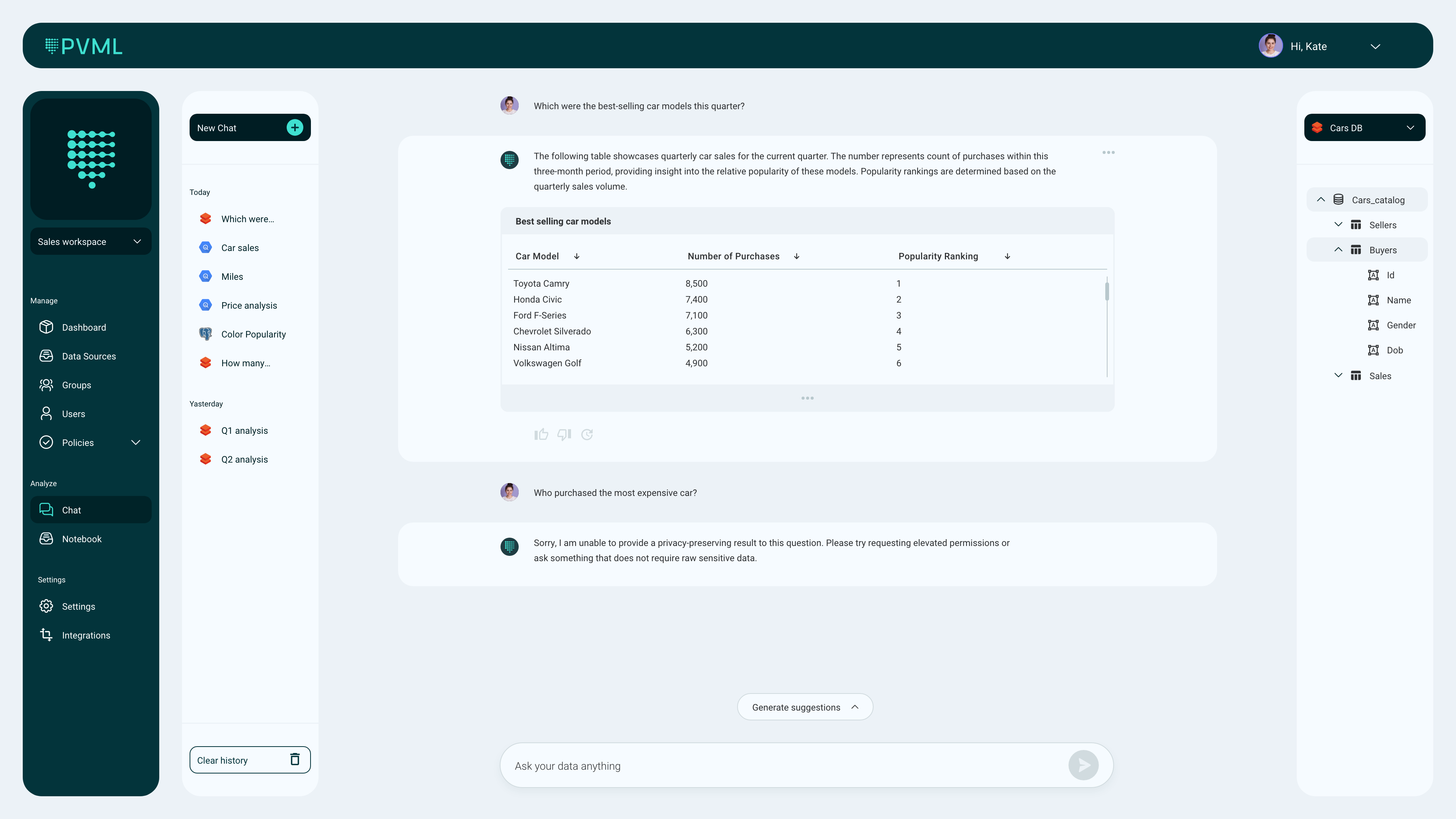
Enterprises are hoarding more data than ever to fuel their AI ambitions, but at the same time, they are also worried about who can access this data, which is often of a very private nature. PVML is offering an interesting solution by combining a ChatGPT-like tool for analyzing data with the safety guarantees of differential privacy. Using retrieval-augmented generation (RAG), PVML can access a corporation’s data without moving it, taking away another security consideration.
The Tel Aviv-based company recently announced that it has raised an $8 million seed round led by NFX, with participation from FJ Labs and Gefen Capital.
Image Credits: PVML
The company was founded by husband-and-wife team Shachar Schnapp (CEO) and Rina Galperin (CTO). Schnapp got his doctorate in computer science, specializing in differential privacy, and then worked on computer vision at General Motors, while Galperin got her master’s in computer science with a focus on AI and natural language processing and worked on machine learning projects at Microsoft.
“A lot of our experience in this domain came from our work in big corporates and large companies where we saw that things are not as efficient as we were hoping for as naïve students, perhaps,” Galperin said. “The main value that we want to bring organizations as PVML is democratizing data. This can only happen if you, on one hand, protect this very sensitive data, but, on the other hand, allow easy access to it, which today is synonymous with AI. Everybody wants to analyze data using free text. It’s much easier, faster and more efficient — and our secret sauce, differential privacy, enables this integration very easily.”
Differential privacy is far from a new concept. The core idea is to ensure the privacy of individual users in large datasets and provide mathematical guarantees for that. One of the most common ways to achieve this is to introduce a degree of randomness into the dataset, but in a way that doesn’t alter the data analysis.
The team argues that today’s data access solutions are ineffective and create a lot of overhead. Often, for example, a lot of data has to be removed in the process of enabling employees to gain secure access to data — but that can be counterproductive because you may not be able to effectively use the redacted data for some tasks (plus the additional lead time to access the data means real-time use cases are often impossible).
Image Credits: PVML
The promise of using differential privacy means that PVML’s users don’t have to make changes to the original data. This avoids almost all of the overhead and unlocks this information safely for AI use cases.
Virtually all the large tech companies now use differential privacy in one form or another, and make their tools and libraries available to developers. The PVML team argues that it hasn’t really been put into practice yet by most of the data community.
“The current knowledge about differential privacy is more theoretical than practical,” Schnapp said. “We decided to take it from theory to practice. And that’s exactly what we’ve done: We develop practical algorithms that work best on data in real-life scenarios.”
None of the differential privacy work would matter if PVML’s actual data analysis tools and platform weren’t useful. The most obvious use case here is the ability to chat with your data, all with the guarantee that no sensitive data can leak into the chat. Using RAG, PVML can bring hallucinations down to almost zero and the overhead is minimal since the data stays in place.
But there are other use cases, too. Schnapp and Galperin noted how differential privacy also allows companies to now share data between business units. In addition, it may also allow some companies to monetize access to their data to third parties, for example.
“In the stock market today, 70% of transactions are made by AI,” said Gigi Levy-Weiss, NFX general partner and co-founder. “That’s a taste of things to come, and organizations who adopt AI today will be a step ahead tomorrow. But companies are afraid to connect their data to AI, because they fear the exposure — and for good reasons. PVML’s unique technology creates an invisible layer of protection and democratizes access to data, enabling monetization use cases today and paving the way for tomorrow.”
Adobe has announced the upcoming integration of generative AI technologies into Premiere Pro, its professional video editing software. These new features, scheduled for release later this year, aim to streamline video editing workflows and provide editors with innovative tools to enhance their creative output. The company's commitment to advancing professional video editing capabilities is evident in this preview of the breakthrough generative AI innovations set to transform the industry.
What Are the New Generative AI Tools in Premiere Pro?
These powerful tools, designed to address common challenges and streamline the editing process, include:
Generative Extend: This game-changing feature allows editors to seamlessly add frames to clips, making them longer and more flexible. By generating additional media on-demand, Generative Extend ensures that editors have the necessary footage to create polished and precisely timed sequences.
Object Addition & Removal: This tool simplifies the process of manipulating video content, allowing editors to effortlessly select and track objects within a scene and replace them with ease. Object Addition & Removal provides editors with unparalleled control over the visual elements in their projects.
Text-to-Video: Perhaps the most exciting generative AI workflow coming to Premiere Pro, this tool allows editors to generate entirely new footage directly within the software by simply typing text prompts or uploading reference images. The potential applications for Text-to-video are vast, from creating storyboards to generating B-roll footage that seamlessly integrates with live-action sequences.
By introducing these cutting-edge generative AI workflows, Adobe is empowering video editors with the tools they need to push the boundaries of their creativity and streamline their workflows. As these features become available in Premiere Pro later this year, professionals in the industry can look forward to a new era of efficient and innovative video editing that will redefine the way stories are told.
The company is also recognizing the value of collaboration and the potential for leveraging the strengths of various AI models to provide users with a comprehensive and versatile editing experience. To this end, Adobe is exploring the integration of third-party generative AI models directly into Premiere Pro.
By incorporating models from leading AI providers such as OpenAI, Runway, and Pika Labs, Adobe aims to offer its users a wide array of powerful tools and functionalities. Early explorations have yielded promising results, showcasing how these integrations could streamline workflows and expand creative possibilities.
For instance, professional video editors could potentially utilize video generation models from OpenAI and Runway to generate B-roll footage seamlessly within Premiere Pro. This would allow editors to quickly populate their projects with relevant and visually appealing supplementary footage, saving time and effort in the process.
Similarly, the integration of Pika Labs' capabilities with Premiere Pro's Generative Extend tool could enable editors to effortlessly add extra seconds to the end of a shot, providing greater flexibility in timing and transitions. By leveraging the strengths of these third-party models, Adobe aims to empower its users with a diverse range of tools and options, ensuring that they have the freedom to create content that aligns with their unique vision and style.
AI-Powered Audio Workflows in Premiere Pro
In addition to the forthcoming generative AI video tools, Adobe has announced the general availability of AI-powered audio workflows in Premiere Pro, set to launch in May. These new features are designed to give editors precise control over sound quality and streamline the audio editing process, making it more intuitive and efficient.
The AI-driven audio enhancements include interactive fade handles, which allow editors to create custom audio transitions quickly by simply dragging clip handles. This feature significantly reduces the time and effort required to achieve smooth, professional-sounding audio transitions.
Premiere Pro will also introduce a new Essential Sound badge, which utilizes AI to automatically categorize audio clips as dialogue, music, sound effects, or ambience. This intelligent tagging system provides editors with one-click access to the appropriate controls for each type of audio, simplifying the editing process and ensuring optimal results.
Furthermore, the update will include effect badges, visual indicators that make it easy for editors to identify clips with applied effects, add new ones, and access effect parameters directly from the sequence. This streamlined approach to managing audio effects will greatly enhance the efficiency and organization of the audio editing workflow.
Finally, the redesigned waveforms in the timeline will offer improved readability and visual feedback. The waveforms will intelligently resize as the track height changes, while vibrant new colors will make sequences easier to navigate and understand at a glance.
Empowering Video Editors with a New Adobe AI Suite
Adobe's preview of generative AI innovations in Premiere Pro and the general availability of AI-powered audio workflows demonstrate the company's unwavering commitment to improving video creation and production. By harnessing the power of artificial intelligence, Adobe is providing editors with the tools they need to streamline their workflows, explore new creative possibilities, and deliver compelling stories with greater efficiency and impact. As these cutting-edge features become available, professionals in the video editing industry can look forward to a new era of enhanced productivity and boundless creativity.
Nowadays, almost all businesses use generative AI and large language models after realizing their ability to boost accuracy in various tasks. These AI models have become the topic of social media discussions nowadays.
This blog explores more on the business and commercial uses of LLMs and genAI along with the differences between them.
What is generative AI in simple terms?
Generative AI is a type of machine learning model focused on the capability of dynamically producing results once it has been trained.
This capability to produce complicated forms of results, such as code or sonnets, is what differentiates generative AI from k-means clustering, linear regression, and different kinds of machine learning.
Generative AI models can only “produce” results as predictions according to the set of new data points.
After training a linear regression model to forecast test scores according to the number of hours spent researching, for instance, it can produce a new prediction if you give it the number of hours a fresh student spent researching.
In this case, you couldn’t rely on prompt engineering to understand the connection between these two values, which is possible with ChatGPT.
Model AI can create original and fresh content from the start when compared to traditional models, as they depend purely on already existing data to forecast outcomes.
After completion of these models’ learning processes, they produce statistically possible results when prompted and can be used to perform different tasks, such as:
Image generation according to present ones or using the style of one image to change or generate a fresh one.
Speech tasks include query/answer generation, meaning of the text or interpretation of the intent, transcription, and translation.
What is generative AI vs “normal AI?”
It’s necessary to know GenAI vs. AI before implementing it in businesses. To use normal AI, specialized skills and knowledge are required, whereas anyone can use generative AI. When you are having a discussion about generative AI, then the question “What is the difference between generative AI and discriminative AI?” strikes your mind. Here are the major differences between generative AI and normal AI or discriminative AI:
Generative AI: understands intent and generates content in human tone (e.g., audio, video, text, code, music, and data).
Normal (traditional)AI: Forecast results for particular use cases according to past trends in data.
Generative AI: applies to different applications (e.g., answering complicated questions, creating audio and video, and creating new images) and use cases.
Normal AI: Closely defined, use-case-oriented (e.g., identify an anomaly in a photo, identify fraud, play chess).
Generative AI: data collected through the internet.
Normal AI: accurately chosen data for particular reasons.
Generative AI: More user interfaces (e.g., chat interfaces via web browsers and apps).Normal AI: specialized use-case-oriented applications (e.g., call centre screens, dashboards, and BI reports).
Is GPT a Generative AI?
Yes. GPT models belong to a category of models that are usually called “foundation models.” They can generate human-like content as they are trained on massive amounts of data and can predict the hidden words. Like this, they can usually perfectly forecast the next word, as they are probabilistic models.
What is LLM in simple words?
LLMs (Large Language Models) represent the best form of generative AI. Large language models are modern artificial intelligence systems that have the potential to produce meaningful and contextually valid content.
These models can understand complex trends and language structures as they go through training through huge amounts of datasets gathered from books, articles, websites, and so on.
Based on this, LLMs can progressively produce human-like text, respond to queries, perform particular tasks, and engage in conversations without losing fluency and expertise. Renowned and top large language model examples include Llama (Meta), BERT (Bidirectional Encoder Representations from Transformers), Bard (Google), and GPT-3 (Generative Pre-trained Transformer 3).
GPT-3, introduced by OpenAI, can execute tasks such as creative writing, generating codes, and translation. Google launched BERT, which can understand the search intent and is a base for search engine algorithms.
What is the architecture of an LLM model?
Today, in the natural language processing domain, collecting a dynamic list of large language models describes the expansion of AI-driven linguistic potentials.
When you start researching large language models, you’ll notice that they’re usually constructed using modern deep-learning techniques with a clear concentration on a neural network architecture called a transformer. Transformers are specially designed to process consecutive data, including text, by focusing on various elements of the input and capturing long-range dependencies.
Through this process, LLMs can understand the context and meaning associated with the words and sentences to create logical responses.
How do large language models (LLMs) work?
There are two steps, like pre-training and fine-tuning, that define the working procedures of large language models.
Pre-training: In this stage, the model learns the linguistic structures and statistical trends that exist in the text data, which allows it to produce a common grasp of language. This stage needs an extensive amount of information, frequently in the range of billions of words, to make sure the model records a broad range of contexts and language patterns.
Fine-tuning: In this stage, the LLM is trained on a particular dataset, personalized to the preferred task or application. This dataset is generally more focused and smaller, enabling the model to specialize in a specific task or domain. Additionally, current large language models can be used in online search, chatbots, DNA research, sentiment analysis, and customer service.
Types of large language models in machine learning
Raw or generic language models forecast the subsequent word according to the language in the training data. These models can perform data-recovery tasks.
Instruction-based language models are clearly trained to predict answers to the directions provided in the input. This lets them conduct sentiment analysis or produce code or text. Dialog-focused language models are properly trained to have a dialog by forecasting the succeeding response.
Generative AI vs LLM
It’s important to understand the concept of large language models vs. generative AI, as they both use neural networks and deep learning. Large language models have become popular with the introduction of modern generative tools such as Google’s Bard and ChatGPT.
Generative AI refers to artificial intelligence models that have the potential to produce content like text, images, music, video, and code. Generative AI examples are Midjourney, ChatGPT, and DALL-E.
Large language models are a type of generative AI that are trained on text and create textual content. A common example of generative text AI is ChatGPT. Generative AI acts as a platform for all large language models.
AI vs. LLM
Artificial intelligence technology has existed on the market since 1950 and focuses on developing machines that can mimic human intelligence.
Popular technologies like ML, generative AI (GAI), and large language models have been listed under AI.
Large language models have been developed from generative AI subsets. They can produce text in a conversational tone (human-like) by forecasting the possibility of a word based on the previously used words in the text.
AI represents a large field of study with GPT, ML, GAI, and LLMs, each of which has its own applications, characteristics, and related companies.
What are the components of a large language model?
Large language models include different neural network layers. Attention layers, embedding layers, recurrent layers, and feedforward layers cooperate to process the input text and produce output content.
“The attention layer” allows a language model to concentrate on single portions of the input text that are related to the present tasks. The responsibility of this layer is to produce perfect output.
Embeddings from the input text are created using “the embedding layer.” This portion of the large language model can capture the syntactic and semantic intent of the input.
“The feedforward layer (FFN)” consists of numerous completely connected layers that modify the input embeddings. While doing this, these layers let the model to fetch higher-level abstractions. “The recurrent layer” sequentially simplifies the words in the input text. It understands how words connect in a sentence.
Foundation model vs LLM
Even though both foundation models and LLMs are listed under AI models, they have their weaknesses and strengths. Foundation models are less data-intensive and have a more general purpose, whereas LLMs are more data-intensive and specialized. The excellent model to use for a specific task will depend on the requirements of that particular task.
Let’s discuss their major differences in detail:
Foundation models are generic
It means that these models can be used for all types of tasks. For instance, a foundation model can be used to develop a chatbot, write engaging content, and translate languages.
A large language model is usually only used for one or two tasks, including language translation or text generation.
LLMs are properly trained in language data
Asalready explained, LLMs are trained in such a way that they can understand the variations of language. It means they are experts in creating semantically relevant and grammatically accurate text. For instance, a LLM can be used to produce text that is both informative and engaging.
A foundation model may not be perfect enough at producing grammatically perfect text because it’s not purely trained on language data.
Foundation models are undeveloped
Foundation models are still immature, whereas large language models are developed and extensively used. This shows foundation models are likely to produce incorrect outputs.
On the other hand, large language models are more reliable and stable, but they might not be as creative as foundation models.
What is the future of LLM?
The new generation of LLMs will successively refine and get “smarter.” They will progressively grow in terms of managing more business applications. Their capability to translate content across various contexts will expand further, making them usable by business users of all levels of technical expertise.
Allowing more accurate data via domain-oriented LLMs developed for specific sectors or functions is another direction for the upcoming large language models. In other words, the use of these models could lead to new examples of shadow IT in companies.
Conclusion
In recent years, both generative AI and large language models have become more powerful. In the upcoming years, businesses not only use large language models for sentiment analysis and text generation, you can see almost all applications you use will be built on LLMs.