“Eventually all our interactions with the digital world will be mediated by AI assistants. This means that AI assistants will constitute a repository of all human knowledge and culture; they will constitute a shared infrastructure like the internet is today,” said Yann LeCun, one of the three godfathers of AI, in his talk at GenAI Winter School recently.
He urged platforms to be open-source and said that we cannot have a small number of AI assistants controlling the entire digital diet of every citizen across the world, taking a dig at OpenAI and a few other companies without naming them.
“This will be extremely dangerous for diversity of thought, for democracy, for just about everything”, he added.
There have been examples galore of things going wrong and biases taking the center stage when only a few companies have the power and control to manufacture the ‘cultural understanding’ for the entire world. They either tend to ignore different cultures or end up overcompensating in ticking off the ‘diversity’ check box.
Case in point: Google’s extra-‘woke’ chatbot Gemini that tried to forcefully inject diversity into pictures with a disregard for historical context. “It’s DEI gone mad,” exclaimed the notably agitated users.
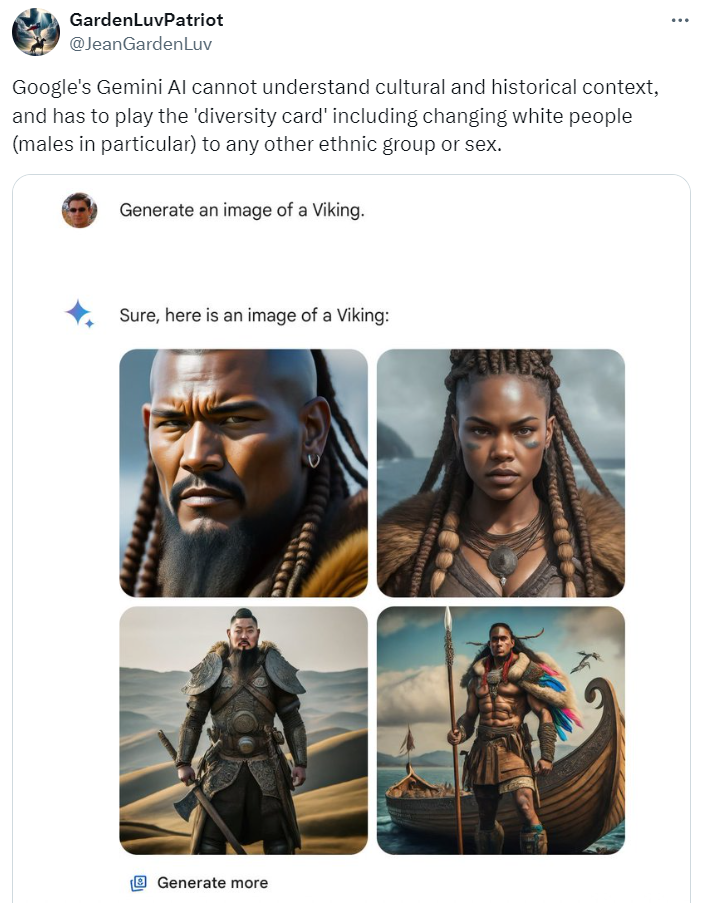
Source: X
We Need Open-Source Base Models
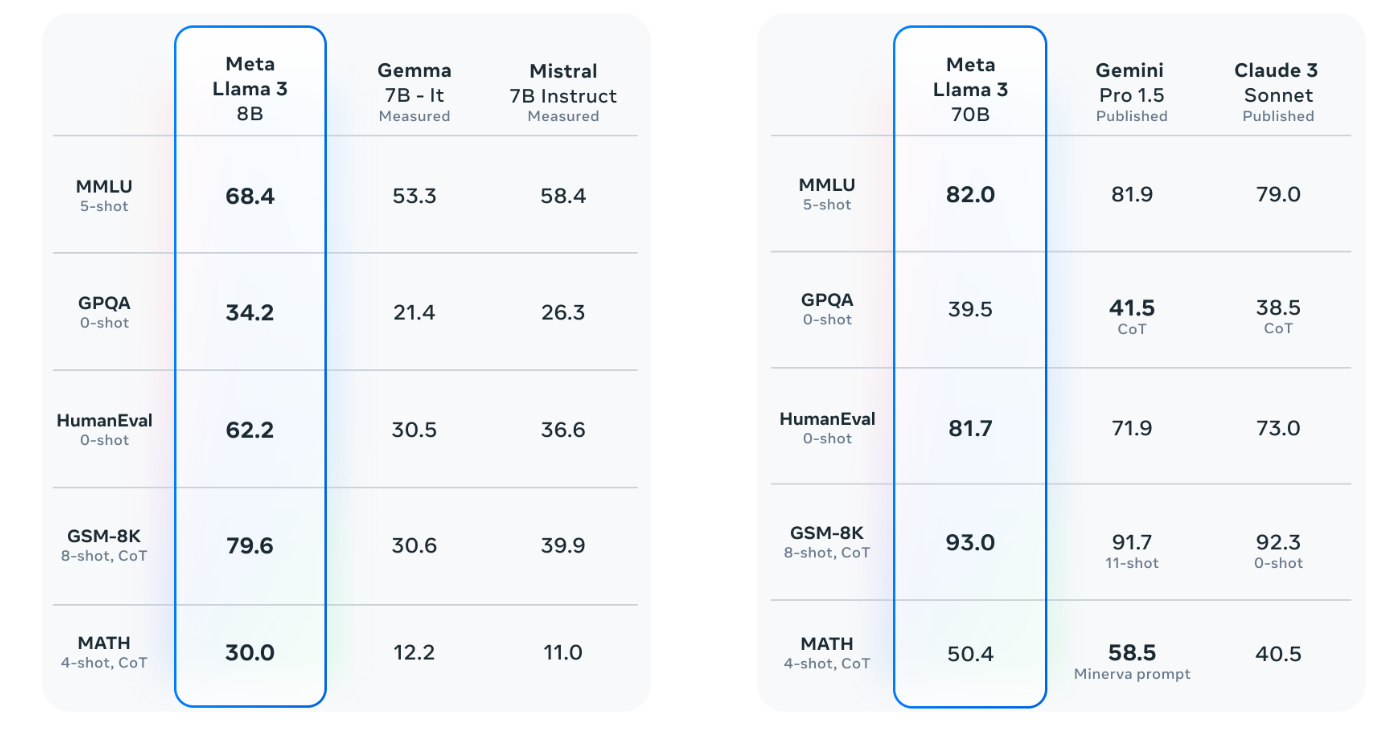
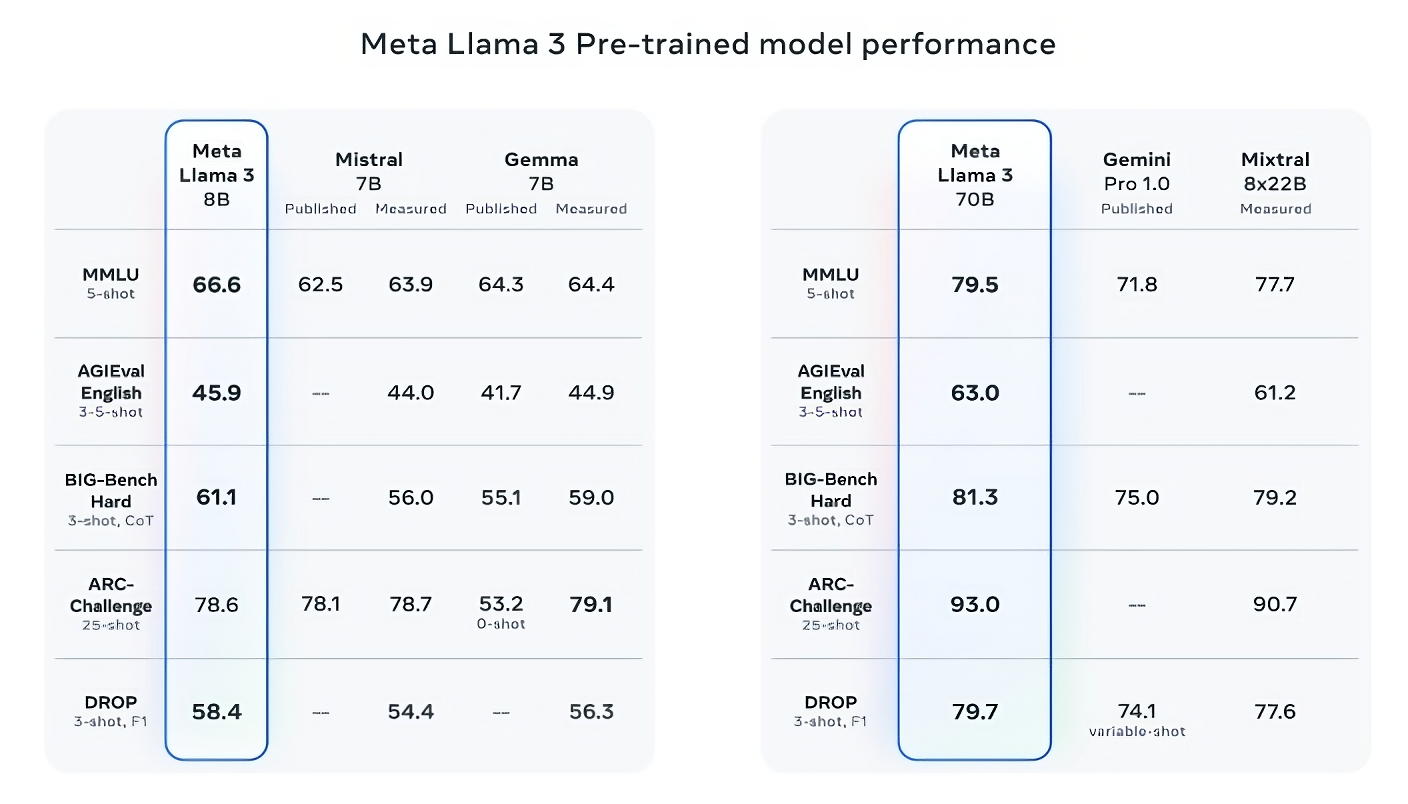
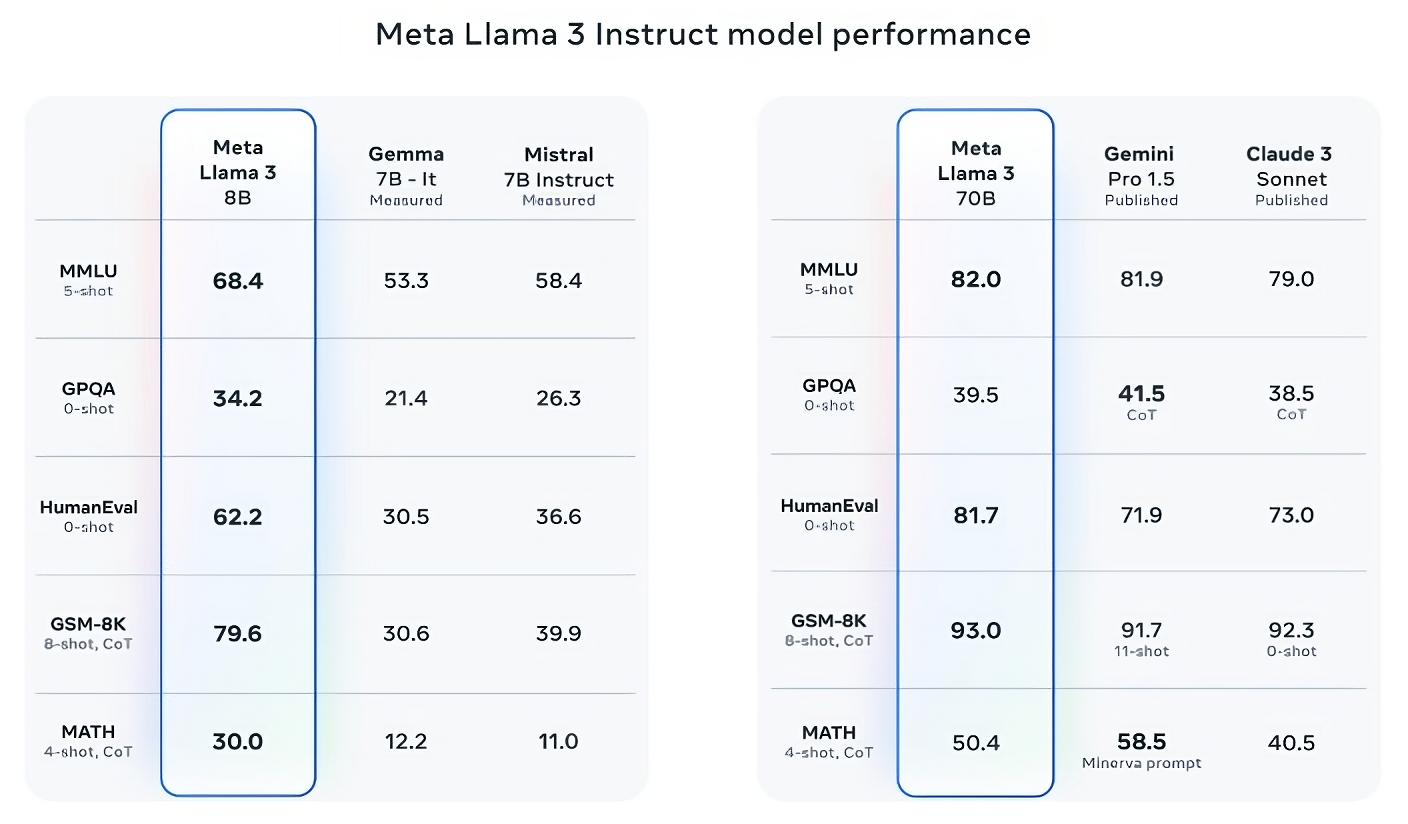
“So what we need is not one AI assistant, we need base models like Llama 2, Mistral, and Gemma that can be fine-tuned by anybody so that, for example, it speaks Arabic and understands the culture of Morocco and knows everything about Marrakech,” said LeCun.
He emphasised that those platforms must be open because we need a high diversity of AI assistants the same way we need a high diversity of the press so that we have no echo chambers and have multiple sources of information.
Currently, we are seeing a multitude of AI models flourish. From farming and healthcare, to education and entertainment, AI is conquering every field. And it doesn’t stop at chat-based solutions. Now, with advancements like voice-first in empathetic voice interface models like Hume AI, our interactions with these assistants are only getting better.
Soon, as LeCun said, this will give birth to a time when “we’re not going to be using search engines. Instead, when it comes to interacting with digital content, we’re basically going to be using our AI assistants. We’ll ask them questions, and they’ll provide the answers. They’ll assist us in our everyday lives”.
This further highlights the need to prevent monopoly in the production of these assistants. If it is through them that we are going to see and interact with the world, then there should be models as diverse as the world we live in. And, thanks to open-source base models, we are already seeing that happen.
Democratising AI Wholeheartedly
India is emerging as an open-source AI champion. From developing Devika, the open source alternative to Devin, and creating Ambari, a bilingual Kannada model built on top of Llama 2, to Telugu LLM Labs and Odia Llama, AI models in Indic languages are the biggest focus of the open source AI developers in India.
India’s vast diversity in languages, cultures, and populations means that a one-size-fits-all approach would not work here. Instead, open source allows for the creation of customised versions tailored to specific user groups, locations, regions, religions, etc., without the need to start from scratch for every individual use case.
Sarvam AI is building models such as OpenHathi on top of Llama. Another notable mention is the Indian agri-tech startup KissanAI, which unveiled Dhenu Vision LLMs for crop disease detection.
BharatGPT unveiled Hanooman, a new suite of Indic GenAI models. The makers said, “We don’t want it to be like ChatGPT, which suffers from the ‘I’m God and I know everything’ syndrome.” The primary focus areas are healthcare and education. Tech Mahindra’s foundational model Project Indus, is an initiative to challenge OpenAI.
Recent developments in other parts of the world like South Korean AI company Kakao Brain’s projects like KoGPT, a large-scale language model for Korean, and Karlo, an image generation model also paint a promising picture. The company aims to contribute to the AI community with open-source projects.
Tokyo-based Sakana AI, reported to be Japan’s first AI startup, is another such example.
All these developments from different regions of the world, involving different languages, cultures, etc., paint an optimistic outlook for LeCun’s suggestion that virtual assistants and AI platforms must be open-source, “Otherwise our culture will be controlled by a few companies on the West Coast of the US or in China.”
“What’s important now is that a lot of governments are thinking about the benefits and dangers of AI. Some of them are thinking that AI is too dangerous to put in the hands of everyone and they’re trying to regulate it and basically make open source AI illegal; regulate it out of existence. I think that’s extremely dangerous for the future of humanity,” LeCun said.
He emphasised that “it’s too dangerous to have AI controlled by a small number of people”.
Still a Lot to Improve

While moving towards such a future, as envisioned by LeCun, we should remember that LLMs and AI assistants can also become the harbinger of chaos and increase the amount of misinformation on the internet massively.
The GPT-4 paper reads, “Novel capabilities often emerge in more powerful models”, and highlights how the model can become “agentic”, meaning it can independently develop and pursue goals not originally programmed during its training.
“The model isn’t accurate in admitting its limitations,” which is a crucial point to note for every single user as well, said the paper.
Talking about the scope of misinformation, Air Canada’s chatbot goof-up serves as a warning sign. In that incident, according to a passenger’s screenshot of a conversation with Air Canada’s chatbot, the passenger was told he could apply for the refund “within 90 days of the date your ticket was issued” by completing an online form.

Source: X
However, when he applied for a refund, Air Canada said bereavement rates did not apply to completed travel and pointed to the bereavement section of the company’s website. Finally, the company was found liable for its chatbot’s misleading advice.
So, while envisioning a future in which most consumer access to the internet will be agents acting for consumers doing tasks and fending off marketers and bots. And, where tens of billions of agents on the internet will be normal, as posted by Vinod Khosla, we should also ensure that these agents are intelligent and reliable; built by diverse companies, based on diverse data, and cater to the needs of a diverse population.
The post ‘AI Platforms will Control What Everybody Sees,’ Says Meta’s AI Chief Yann LeCun appeared first on Analytics India Magazine.