The newest outcomes from FrontierMath, a benchmark take a look at for generative AI on superior math issues, present OpenAI’s o3 mannequin carried out worse than OpenAI initially said. Whereas newer OpenAI fashions now outperform o3, the discrepancy highlights the necessity to scrutinize AI benchmarks carefully.
Epoch AI, the analysis institute that created and administers the take a look at, launched its newest findings on April 18.
OpenAI claimed 25% completion of the take a look at in December
Final 12 months, the FrontierMath rating for OpenAI o3 was a part of the practically overwhelming variety of bulletins and promotions launched as a part of OpenAI’s 12-day vacation occasion. The corporate claimed OpenAI o3, then its strongest reasoning mannequin, had solved greater than 25% of issues on FrontierMath. As compared, most rival AI fashions scored round 2%, based on TechCrunch.
SEE: For Earth Day, organizations could factor generative AI’s power into their sustainability efforts.
On April 18, Epoch AI launched take a look at outcomes exhibiting OpenAI o3 scored nearer to 10%. So, why is there such an enormous distinction? Each the mannequin and the take a look at may have been completely different again in December. The model of OpenAI o3 that had been submitted for benchmarking final 12 months was a prerelease model. FrontierMath itself has modified since December, with a distinct variety of math issues. This isn’t essentially a reminder to not belief benchmarks; as a substitute, simply keep in mind to dig into the model numbers.
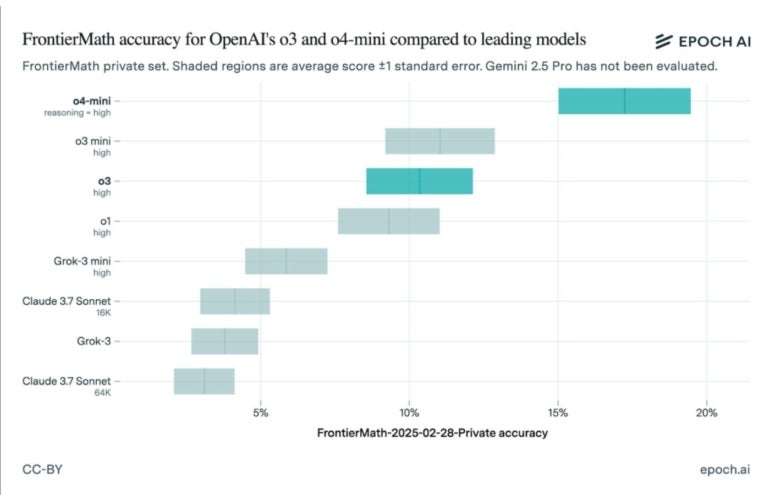
OpenAI o4 and o3 mini rating highest on new FrontierMath outcomes
The up to date outcomes present OpenAI o4 with reasoning carried out finest, scoring between 15% and 19%. It was adopted by OpenAI o3 mini, with o3 in third. Different rankings embody:
- OpenAI o1
- Grok-3 mini
- Claude 3.7 Sonnet (16K)
- Grok-3
- Claude 3.7 Sonnet (64K)
Though Epoch AI independently administers the take a look at, OpenAI initially commissioned FrontierMath and owns its content material.
Criticisms of AI benchmarking
Benchmarks are a standard option to evaluate generative AI fashions, however critics say the outcomes may be influenced by take a look at design or lack of transparency. A July 2024 research raised considerations that benchmarks usually overemphasize slim activity accuracy and endure from non-standradized analysis practices.
{kind=link}