

OpenAI recently introduced a new model called sCM (simplified continuous-time consistency model), which achieves sample quality comparable to diffusion models but requires only two sampling steps, significantly speeding up the generative process for tasks like image, audio, and video generation.
In a new paper titled “Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models”, OpenAI researchers Cheng Lu and Yang Song argue that simple, consistency models, aka sCM, offer a more efficient and faster method for generating high-quality samples compared to traditional diffusion models.
The researchers believe that this provides a significant ~50x speedup in generation time, making it much more efficient for real-time applications across image, audio, and video domains. The sCM’s stability in training and scalability to large datasets further enhance its edge over traditional diffusion models.
The researchers said that the model is trained with 1.5 billion parameters on ImageNet 512×512, generating high-quality samples in 0.11 seconds on an A100 GPU.
The outcome: Provides high-quality results while using less than 10% of the computational resources typically required by diffusion models.
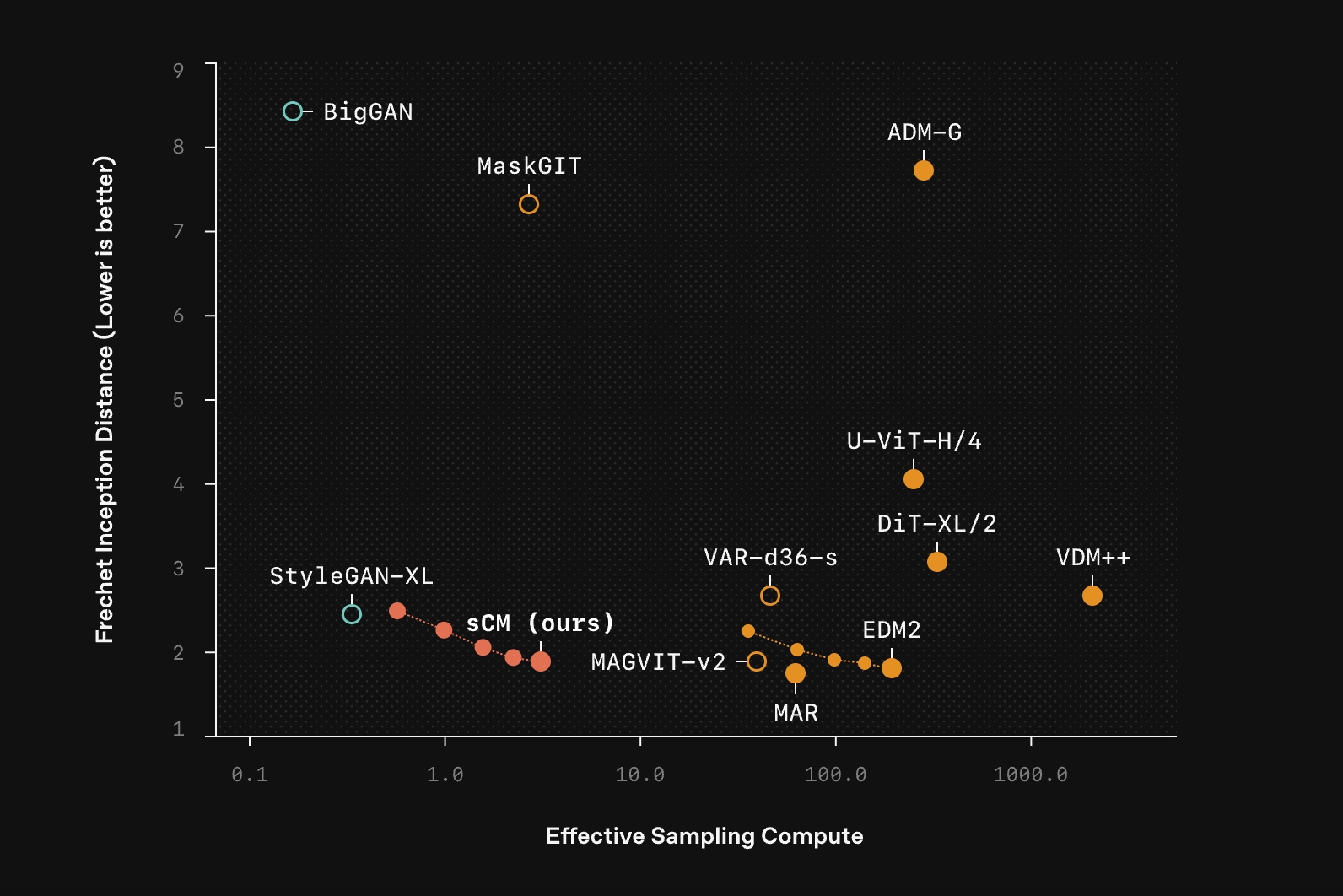
In terms of benchmark performance, the researchers claimed that sCM achieved hieves Fréchet Inception Distance (FID) scores of 2.06 on CIFAR-10, 1.48 on ImageNet 64×64, and 1.88 on ImageNet 512×512, narrowing the quality gap to within 10% of leading diffusion models.
Consistency Models vs Diffusion Models
The key differentiator of sCM (simplified continuous-time consistency model) over diffusion models is that it achieves comparable sample quality while requiring only two steps for sampling, as opposed to the dozens or hundreds of sequential steps typically needed in diffusion models.
Simply put, current diffusion models require many steps to generate a sample, limiting their speed and use in real-time applications. This changes with the new sCM approach.
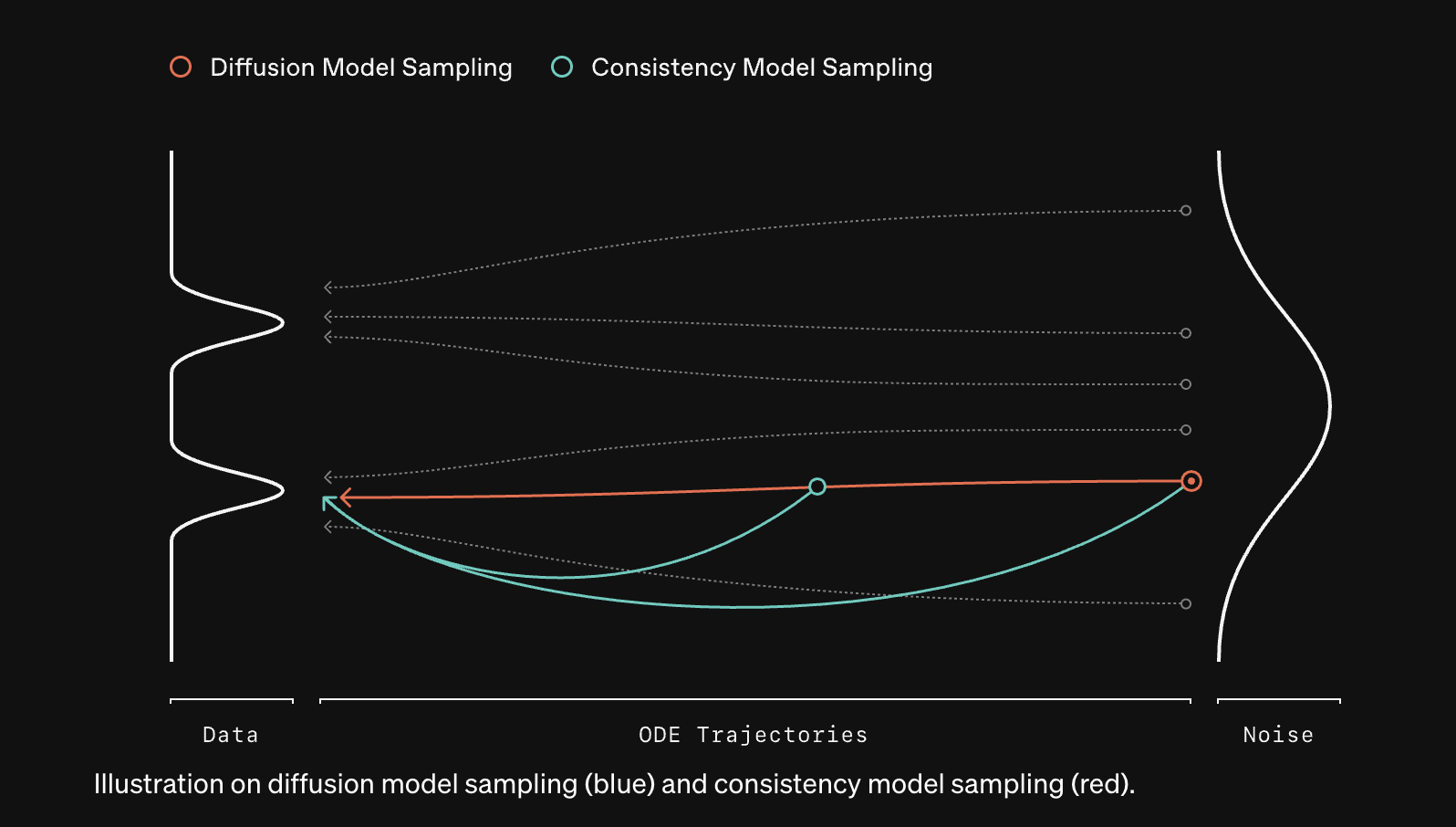
Why are Consistency Models Faster? The researchers said that diffusion models gradually transform noise into samples through numerous denoising steps, while consistency models aim to produce noise-free samples in just one or two steps. This faster approach is illustrated by a direct sampling path, unlike the slow, gradual process of diffusion models.
This is Unprecedented for Consistency Models. “For the first time, consistency models can be stably scaled to one of the hardest academic image generation dataset: ImageNet 512×512. Our class-conditioned sample quality almost matches the state-of-the-art diffusion models, but requires only <1/50 effective sample compute,” said Lu, author of the research paper. “Real time multimodal generation is on the horizon,” Lu added.
Many believe this could become the foundation for real-time generation of audio, video, and images in the future. This also helps explain the delay in the release of Sora and the new version of DALL-E – where OpenAI would possibly need to deploy sCM to make the models faster. sCM will have a huge impact on future creative projects.
The post OpenAI Researchers Introduce sCM, a Faster, More Efficient Alternative to Diffusion Models appeared first on AIM.