

OpenAI has launched the Predicted Outputs feature for developers using GPT-4o and GPT-4o-mini which is designed to improve efficiency, while also reducing the latency of responses.
This feature allows users to input a ‘prediction string’, an anticipated segment of the output which significantly reduces response times during repetitive tasks or minor document edits.
Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://t.co/n6mqjQwQV1
Speed up:
– Updating a blog post in a doc
– Iterating on prior responses
– Rewriting code in an existing file, like @exponent_run here: pic.twitter.com/c9O3YtHH7N— OpenAI Developers (@OpenAIDevs) November 4, 2024
OpenAI has said that since most of the output of an LLM is known before generation, predicting them in advance means generating fewer tokens. It is almost always the highest latency step when using an LLM: as a general heuristic, cutting 50% of your output tokens may cut ~50% user latency.
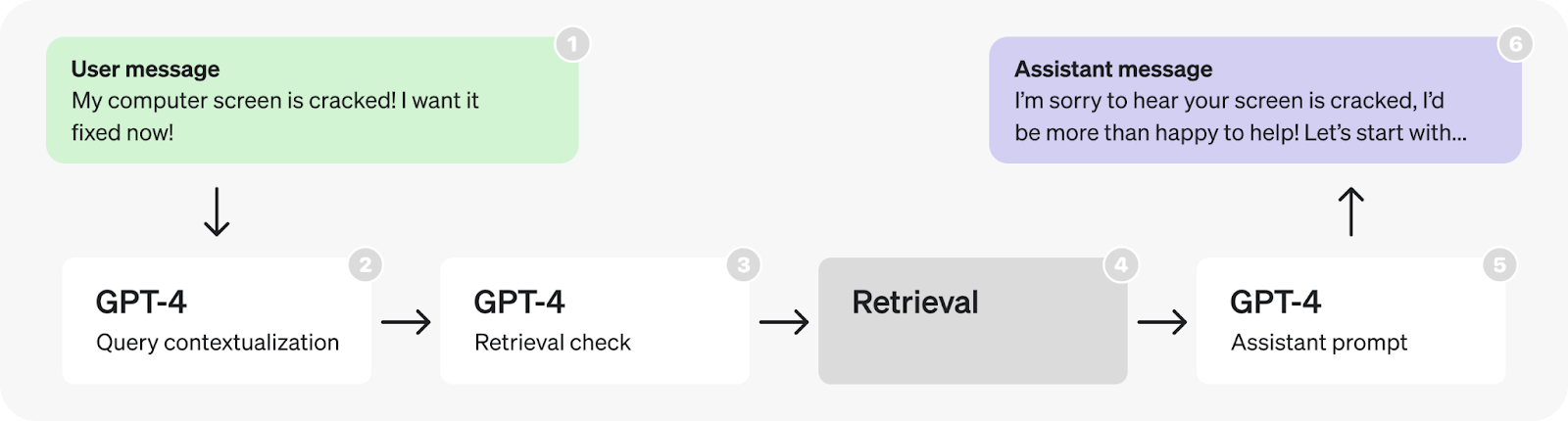
According to users who tested it, the typical applications of this feature include updating existing text or making small changes to code, such as renaming variables or rephrasing specific content, where the AI response can closely match the provided input.
Testing of this feature has shown it performs best when there’s a close match between the prediction and the model’s response. If the prediction string diverges from the model’s output, the tool can become less efficient, leading to slower responses and higher costs.
Read more about the feature here.
This predictive tool is deemed to be ideal for scenarios where developers know the general structure of the required output.
For example, if a user wants the model to reword a document with minor changes or adjust specific lines of code, the predictive input helps streamline responses by letting the model reuse parts of the pre existing text.
By contrast, the feature isn’t as beneficial for creating unique, original content, where responses cannot easily be anticipated in advance.
OpenAI encourages developers to experiment with the predictive text feature in controlled, predictable tasks to maximize efficiency, particularly in contexts that require frequent minor adjustments.
The post OpenAI Introduces Predicted Outputs for Improving Latency in LLMs appeared first on Analytics India Magazine.