
Every day we see a new chatbot — either built by a big-tech/recently funded company, or from the open source community. In the race to replicate OpenAI’s ChatGPT, developers have been taking a lot of shortcuts. The most common one these days is training the chatbots on data generated by ChatGPT.
The most recent chatbot claims to outperform ChatGPT. OpenChat, an open source chat alternative that is touted as decentralised, recently achieved a score of 105.7% compared to ChatGPT on Vicuna GPT-4 Benchmark. A huge feat, but not true when looked at closely.

This is the second model that claims to perform better than ChatGPT on the same Vicuna Benchmark. Earlier, Orca, a 13-billion parameter model, which was also trained on GPT-4 data, claimed to outperform OpenAI’s model.
Same-old, same-old
To start with, OpenChat is built on top of LLaMA-13B. This means that the model is already not up for commercial use as Meta’s LLaMA is for research purposes only, and not up for commercial use. Furthermore, there is another thing that should be considered before boasting about the benchmarks of the model — the dataset used for fine-tuning. This LLaMA-based model is trained on a set of 6k conversations from the 90k conversations available on ShareGPT, a hub for sharing ChatGPT and GPT-4 generated outputs on the internet.
When it comes to evaluating and benchmarking on Vicuna GPT-4 Benchmark, it only tests for style and not the information generated by the model. Furthermore, it is a GPT-based evaluation metric, which means that any model trained on ChatGPT or GPT-4 data will be rated higher when tested by GPT, making the benchmarking untrustworthy.
Recently, Hugging Face found a similar problem with other open source models as well. The founders of Hugging Face claimed there was a lot of discrepancy between the evaluation benchmarks put up on the papers of the models and when the models are evaluated on the Hugging Face benchmarks. David Hinkle, VP of software engineering at Securly, pointed out that a lot of recent models that claim they are outperforming LLaMA or GPT-4 are nowhere on the Open LLM Leaderboard.
Tall claims, short results
In short, it is a big claim to make that a model trained on ChatGPT data outperforms the same when benchmarking on a metric built on top of the same model. For an analogy, it is like a student giving an exam, rewriting the answers to match with the correct answers provided by the teacher, to which the teacher matches the answers again. Obviously, it is going to perform better.
Andriy Mulyar, from Atlas Nomic AI, points this out saying this is all just a false hype. People imitating ChatGPT using ChatGPT generated output is a false path to follow. Furthermore, the only thing that these models are copying is the style of ChatGPT, making the chatbots’ quality sound better on individual tasks. If evaluated across the board considering all types of general tasks, ChatGPT is a much better assistant than any other.
Interestingly, after all the criticism, the researchers have realised that there is some problem with evaluating the model on Vicuna GPT-4 Benchmark. Hence, they have transitioned to MT-bench, to test OpenChat’s performance. In this case, the model performed significantly poorer than GPT-3.5 based ChatGPT, describing the discrepancy between the evaluation benchmarks.
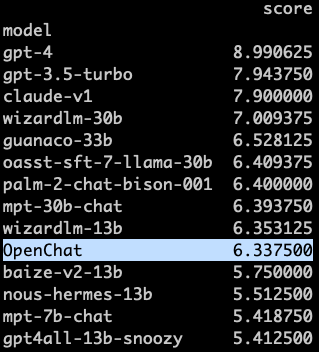
Users on Twitter have been pointing out that the model hallucinates even more than ChatGPT, and more than just the evaluation metrics used for the models. “I just tried this model and it is not good at all. Did you even try the model before posting this?” said a Twitter user.
Thanks to GPT
Whatever the metrics and benchmarks, one thing is getting increasingly clear about LLM-based chatbots — high-quality data works wonders. For this, the only model that should be thanked is ChatGPT, as every model today is being trained on synthetic data generated by the chatbot. No one has the secret sauce that OpenAI made for GPT. Recently, OpenAI was asked if open source would be able to replicate what the company has built through Vicuna or LLaMA, to which, Ilya Sutskever replied with a negative.
The trend of “this new model beats all other models in benchmarks” has been going on for a while now, but when evaluated on the same metrics as the others, “the news model” fails to perform. Moreover, even though the open source community has been trying to replicate ChatGPT, training it on ChatGPT’s data might not be the best way forward, as OpenAI is already under several lawsuits for training on internet data.
The post Open Source Chatbots Are Nowhere Close to ChatGPT appeared first on Analytics India Magazine.
{kind=link}