MLPerf Training 3.0 Showcases LLM; Nvidia Dominates, Intel/Habana Also Impress June 29, 2023 by John Russell 
As promised, MLCommons added a large language model (based on GPT-3) to its MLPerf training suite (v3.0) and released the latest round of results yesterday. Only two chips took on the LLM challenge – Nvidia’s H100 GPU and Intel/Habana’s Gaudi2 deep learning processor – each showcasing different strengths. Not surprisingly, the newer H100 was the clear performance winner.
MLCommons reported, “The MLPerf Training v3.0 round includes over 250 performance results, an increase of 62% over the last round, from 16 different submitters: ASUSTek, Azure, Dell, Fujitsu, GIGABYTE, H3C, IEI, Intel & Habana Labs, Krai, Lenovo, Nvidia, joint Nvidia- CoreWeave entry, Quanta Cloud Technology, Supermicro, and xFusion.” The number of submitters dipped slightly from last November (18) and last June (21) but the number of results submitted was up. Here’s a link to the full results.
“We’ve got almost 260 performance results, pretty significant growth over the prior round,” said David Kanter, executive director, MLCommons (parent organization for MLPerf) in media/analyst pre-briefing. “If you look at performance, generally speaking performance on each one of our benchmarks improved by between 5% and 54%, compared to the last round. So that’s a pretty, pretty nice showing. We also have our two new benchmarks, the new recommender and LLM. We had got three submitters to GPT-3 (based-test) and five submitters to DLRM-dcnv2.”


MLCommons also released results for the Tiny ML v1.1 inferencing benchmark (very small models, low power consumption) suite: “[They] include 10 submissions from academic, industry organizations, and national labs, producing 159 peer-reviewed results. Submitters include: Bosch, cTuning, fpgaConvNet, Kai Jiang, Krai, Nuvoton, Plumerai, Skymizer, STMicroelectronics, and Syntiant. This round includes 41 power measurements, as well. MLCommons congratulates Bosch, cTuning, fpgaConvNet, Kai Jiang, Krai, Nuvoton, and Skymizer on their first submissions to MLPerf Tiny.”
The big news, of course, was addition of a LLM to the suite. LLMs and generative AI are gobbling up much of the technology-communication air these days. Not only are LLMs expected to find ever widening use, but also expectations are high that thousands of smaller domain-specific versions of LLMs will be created. The result is likely to be high demand for both chips and systems to support these applications.
The new LLM joins BERT-Large which is a much smaller natural language processing model.
“Our LLM is based on pre-training GPT-3, the 175 billion (parameter) model that was originally described by OpenAI. Just to contrast this to the [NLP] MLPerf benchmark, Bert is a bidirectional encoder and has 340 million parameters. [That] gives you a sense of size and scope,” said Kanter.
“The C4 dataset (used by the GPT-3), as I mentioned is 305 gigabytes or 174 billion tokens. We are not training on all of C4, because that would take a really long time. We train on a portion of the training dataset to create a checkpoint, and the benchmark is training starting from that checkpoint on 1.3 billion tokens. Then we use a small portion of the validation dataset to do model accuracy evaluation to tell when you’ve got the right accuracy. To give you some rough numbers, this benchmark is about half a percent of the full GPT-3. We wanted to keep the runtime reasonable. But this is by far and away the most computationally demanding of our benchmarks. So the reference model is a 96 layer transformer,” said Kanter.


 Turning to the results for a moment. Nvidia was again the top performer. In terms of MLPerf showings, it is hard to overstate its Nvidia recurring dominance (systems using Nvidia accelerators). This isn’t to say the Intel showings (4th-gen Xeon and Gaudi4) were insignificant. They were (more later), but Nvidia GPUs remained king.
Turning to the results for a moment. Nvidia was again the top performer. In terms of MLPerf showings, it is hard to overstate its Nvidia recurring dominance (systems using Nvidia accelerators). This isn’t to say the Intel showings (4th-gen Xeon and Gaudi4) were insignificant. They were (more later), but Nvidia GPUs remained king.
David Salvator, director of AI, benchmarking and cloud, Nvidia, presented data comparing performance between accelerators.
“We essentially normalize the performance across the board (slide below), using as close to comparable GPU counts as we can to do the normalization. And what we’ve done here is normalized to H100, and shown a couple of competitors and how they fared,” said Salvator at a separate Nvidia briefing. “The basic takeaway is it first of all, we run all the workloads, which is something we’ve done since the beginning with MLPerf. We are unique in that regard. But the main takeaway is that we are significantly faster than competition. We are running all the workloads and basically either setting or breaking records on all of them.”
Nvidia also touted its joint submission with cloud provider CoreWeave of its HGX H100 infrastructure. The submission used 3584 H100 GPUs. “This instance is a live commercial instance that the CoreWeave GA’d at GTC. They were one of the very first to go GA with their HGX H100 instances. The instances have 8 SXM GPUs and make use of our third-generation switch technology to allow all communication at full bandwidth speed of 900 gigabytes per second,” said Salvator.



While there’s some quibbling around the edges, no one really disputes Nvidia dominance in MLPerf training. A broader question, perhaps is what does Nvidia’s dominance mean for the MLPerf Training benchmark?
Given the lack of diversity of branded accelerators (and to a lesser extent CPUs) in the MLPerf Training exercise, the twice-a-year issuing of results is starting to feel repetitive. Nvidia wins. Scarce rival “accelerator” chips – just two this time, including a CPU – typically are making a narrower marketing/performance points. Intel made no bones about this in the latest round, conceding Nvidia H100 performance at the top end.
The result: Rather than being a showcase for different accelerator chips’ performance, the MLPerf Training exercise, at least for now, broadly tracks Nvidia progress, and is really best suited as a spotlight for system vendors to tout the strength of their various system configurations using various Nvidia chips and preferred software frameworks. Perhaps it is best to think of the MLPerf Training exercise in this narrower way. The situation is a little different in other MLPerf categories (inference, edge, Tiny, HPC, etc.) Training is the most computationally-intense of the MLPerf benchmarks.
Kudos to Intel for the creditable showings from both 4th-gen Xeon and Gaudi2. The Intel position as spelled out by Jordan Plawner, senior director, AI product, was interesting.
Broadly speaking about CPUs, he argued that 4th gen Xeon, bolstered by many technical features such as built in matrix multiply and mixed precision capabilities, is well-suited for small-to-medium size model training, up to tens of billions or parameters. Moreover, while many CPU vendors have touted similar training and inference capabilities, none have them have participated in MLPerf. The submitted 4th-gen Xeon systems were without separate accelerators.
“You might have a real customer that says ‘I have all my Salesforce data, my own proprietary data, that I won’t even share with other people inside the company, let alone to an API [to an outside model].’ Now that person needs to fine tune the 7 billion parameter model with just his or her salesforce data, and give access to just the people who have asked who are allowed to have access, so they can query it and ask it, questions and generate plans out of it,” said Plawner. Intel’s 4th gen Xeon does that perfectly well, he contends.
So far, Intel is the only CPU maker that has MLPerf submissions that use only the CPU to handle training/inference tasks. Other CPU vendors have touted these AI-task capabilities in their chips but none has so far competed in that fashion. Plawner took a shot at them.
“The Intel Xeon scalable processor is the only CPU that’s submitted. For us, that’s an important point. We hear results that they get in the lab, and I say yes, but can you upstream those results into DeepSpeed, PyTorch, and TensorFlow, because that’s all that matters. I don’t care about the hardware roofline. I care about the software roofline. So there are lots of CPU companies out there and lots of startups in the accelerator space as well, and, to me, MLPerf is the place where you show up or don’t. As a CPU company, we have a lot of CPU competition and a lot of people wrapping AI messages around their CPUs. I say fine, are you going to submit to MLPerf? Let’s see your software. Let’s see how it works out of the box, don’t show me an engineered benchmark,” said Plawner.
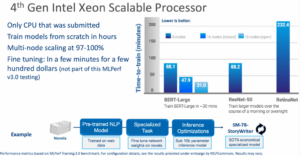

Intel makes a different argument for Habana’s Gaud2. Basically, it’s that yes, H100 currently is the top performer…if you can get them. Intel argues H100s are in short supply and unless you’re a huge customer, you can’t get them. Meanwhile, Gaudi2, argues Intel, is already par with (or better than) Nvidia’s A100 GPU and is built to handle large models. Compared with H100, the Gaudi chip is slower, but still very high-performing and offers a cost-performance advantage.
“I want to set that context, right? Okay. But these large clusters or pods, as people call them, which is obviously more than just the chips, but it’s all the networking and distributed storage. It’s really purpose-built at a datacenter scale for lots of money. Gaudi 2 is the Intel product to do these large, large training for models that are 10s of billions up to hundreds of billions. [Some] people are talking about a trillion parameters. There’s no doubt that you need this kind of dedicated system at scale to do that,” said Plawner
“For Gaudi, I think the really critical point – and we’ll talk about the performance and was it competitive or how competitive – but the most important point is simply [that it’s] the only viable alternative to Nvidia on the market. Our customers are screaming for an alternative to Nvidia and those customers are working out of the framework levels so CUDA doesn’t matter it matter to them. Intel/Habana was the only other company to submit for GPT-3 and large scale training is now data center scale [activity]. And if you can’t do GPT-3 then all you have is a chip and maybe a box. But what you need is a cluster. That’s what Gaudi has built,” he said.
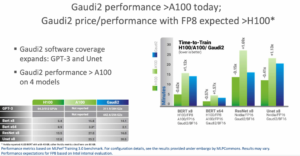

Wrapping up the 4th-gen Xeon/Gaudi2 positions, Plawner said Right now, you can’t buy one (H100) if you’re not Google or Microsoft. So as I said, Xeon is like a V100 class GPU (performance). Now, Gaudi is an A100 class today and it’s perfectly viable as customers are telling us and getting more interested in adopting it. You see here (slide) the H100 versus Gaudi2 performance per device is about 3.6x difference. Okay, I think that 3.6x is still significant, but I think we’re getting to diminishing returns. We’re talking about training (very large models) and hundreds of minutes.”
MLCommons holds a joint briefing before formally releasing results and the ground rules include not making directly competitive statements versus rival vendors. There was however some interesting comment around networking. Not surprisingly Nvidia touted InfiniBand while several others said fast Ethernet was quite adequate for LLM training.
As always, because system configurations differ widely and because there are a variety of tests, there is no single MLPerf winner as in the Top500 list. It was always necessary to dig into individual system submissions to make fair comparisons among them. MLCommons makes that fairly easy to on its web site. Also, MLCommons invites participating vendors to submit short statement describing their submissions. Those statements are appended to this article.
Link to MLPerf results, https://mlcommons.org/en/training-normal-30.
VENDOR STATEMENTS (unedited)
The submitting organizations provided the following descriptions as a supplement to help the public understand the submissions and results. The statements do not reflect the opinions or views of MLCommons.
Azure
Microsoft Azure is introducing the ND H100 v5-series which enables on-demand in sizes ranging from eight to thousands of NVIDIA H100 GPUs interconnected by NVIDIA Quantum-2 InfiniBand networking. As highlighted by these results, customers will see significantly faster performance for AI models over our last generation ND A100 v4 VMs with innovative technologies like:
- 8x NVIDIA H100 Tensor Core GPUs interconnected via next gen NVSwitch and NVLink 4.0
- 400 Gb/s NVIDIA Quantum-2 CX7 InfiniBand per GPU with 3.2Tb/s per VM in a non-blocking fat-tree network
- NVSwitch and NVLink 4.0 with 3.6TB/s bisectional bandwidth between 8 local GPUs within each VM
- 4th Gen Intel Xeon Scalable processors
- PCIE Gen5 host to GPU interconnect with 64GB/s bandwidth per GPU
- 16 Channels of 4800MHz DDR5 DIMMs
Last but not least, all Azure’s results are in line with on-premises performance and available on-demand in the cloud.
Dell Technologies
Businesses need an innovative, future-ready and high-performing infrastructure to achieve their goals. The continued growth of AI, for example, is driving business leaders to leverage AI further and examine how faster time-to-value will help them drive higher ROI.
The latest innovations in the Dell portfolio enable future-ready foundations with breakthrough compute performance for demanding, emerging applications such as Generative AI training of large language models, foundation models and natural language processing.
For the MLPerf training v3.0 benchmark testing, Dell submitted 27 results across 12 system configurations, including the Dell PowerEdge XE9680 and the Dell PowerEdge R760xa PCIe servers. Dell Technologies works with customers and partners including NVIDIA, to optimize software-hardware stacks for performance and efficiency, accelerating demanding training workloads.
Here are some of the latest highlights:
- The PowerEdge XE9680, which delivers cutting-edge performance with 8x NVIDIA H100 SXM GPUs, achieved tremendous performance gains across many benchmarks, including over 600% faster on BERT language processing testing versus current 4-way A100 SXM solutions (on v2.1 benchmarks).
- Image segmentation through object detection benchmarks also saw a 2 to 4x performance improvement over 4-way A100 solutions.
- The newest Dell PowerEdge XE8640 with 4x NVIDIA H100 SXM GPUs also saw some double gains over the 4-way A100.
- Similarly, comparing 4-way NVIDIA A100 PCIe vs H100 PCIe on PowerEdge servers also saw 2 to 2.5x performance improvements.
Training models and complex image detection require compute-intensive approaches, such as for Generative AI with Dell Technologies’ Project Helix. With Dell Technologies servers with NVIDIA GPUs, businesses can readily deploy the optimal performance foundation for AI/ML/DL and other initiatives.
Collaborate with our HPC & AI Innovation Lab and/or tap into one of our HPC & AI Centers of Excellence.
Fujitsu
Fujitsu offers a fantastic blend of systems, solutions, and expertise to guarantee maximum productivity, efficiency, and flexibility delivering confidence and reliability. We have continued to participate in and submit to every inference and training round since 2020.
In this training v3.0 round, we submitted two results. Our system used to measure the benchmark is new in two points compared to those in our past submissions. First, this system contains ten NVIDIA A100 PCIe 80GB GPUs and this number is more than that in any past submissions from Fujitsu. Next, all PCIe devices: GPUs, storages, and NICs are placed in PCI boxes outside nodes. These resources can be allocated to one node like in this submission, or to multiple nodes, and managed adaptively.
As for the results of benchmarks, we measured two tasks: resnet-50 and ssd-retinanet, and accomplished the best results in our past submissions. For resnet-50, we got 25.831min (8.13 % improvement) and 73.229 min (39.7 % improvement) for ssd-retinanet. We will continue to strive to provide attractive server products through the MLPerf benchmark.
Our purpose is to make the world more sustainable by building trust in society through innovation. We have a long heritage of bringing innovation and expertise, continuously working to contribute to the growth of society and our customers.
GIGABYTE
GIGABYTE is an industry leader in HPC & AI servers, and uses its hardware expertise, patented innovations, and industry connections to create, inspire, and advance. With over 30 years of motherboard manufacturing excellence and 20 years of design and production of server and enterprise products, GIGABYTE offers an extensive portfolio of data center products for x86 and Arm platforms.
In 2020, GIGABYTE joined MLCommons and submitted its first system- a 2U GPU server with AMD EPYC processors and sixteen NVIDIA T4 GPUs. Since then, we have continued to support the community by submitting our own systems for training and inferencing, as well as providing servers to submitters. In the past, we submitted systems for AMD EPYC and Intel Xeon processors, but last year we saw our first GIGABYTE systems using the Arm-based processor, Ampere Altra.
For MLPerf Training v3.0 we submitted an updated platform for NVIDIA H100 SXM5. Our server, G593-SD0, supports eight SXM5 modules and coordinates via dual Intel Xeon Platinum 8480+ processors.
Jumping from HGX platforms, from A100 to H100, we have seen drastic improvements in our training benchmarks. Across the board we saw an average reduction in time by 55%.
Results compared to v2.1 submission:
Image classification: 51% faster; from 28min to 13.5min
Image segmentation: 48% faster
Object detection, lightweight: 55% faster
Speech recognition: 44% faster
Natural language processing: 72% faster To learn more about our solutions, visit: https://www.gigabyte.com/Enterprise.
HabanaLabs
Intel and its Habana team are excited to announce impressive achievements on the MLPerf Training 3.0 benchmark. The Gaudi2 accelerator is one of only two solutions in the AI industry to have submitted GPT-3 training results, providing tangible validation that Gaudi2 provides the performance and efficiency required to serve customers training complex and large language models at scale. Gaudi2’s training results substantiate the accelerator’s efficient scaling up to very large clusters to support multi-billion parameter models such as the 175B parameter GPT-3 model. Gaudi2 delivered impressive time-to-train performance, as well as near-linear scaling of 95% from 256 to 384 Gaudi2s.
Habana’s software has evolved significantly and continues to mature. In this GPT-3 submission we employed the popular DeepSpeed optimization library (part of Microsoft AI at scale), enabling support of 3D parallelism (Data, Tensor, Pipeline) concurrently, further optimizing performance efficiency of LLMs. Gaudi2 results on the 3.0 benchmark were submitted using BF16 datatype; we expect to see a substantial leap in Gaudi2 performance when our software support of FP8 and additional features are released in Q3.
In total, we reported results on four models, of which GPT-3 and Unet3D are new. All results are reported in PyTorch with the addition of TensorFlow on BERT and ResNet-50. Gaudi2 showed performance increases of 10% and 4% respectively for BERT and ResNet models as compared to the November submission. Habana results are submitted on its “out of the box” software, enabling customers to achieve comparable results when implementing Gaudi2 in their own on-premises or cloud implementations.
We look forward to continuing to report on Gaudi2 training, as well as inference performance, on future MLPerf benchmarks and expanding coverage results of models that best address the customer needs as they evolve.
IEI
IEI Industry Co., LTD is a leading provider of data center infrastructure, cloud computing, and AI solutions, ranking among the world’s top 3 server manufacturers. Through engineering and innovation, IEI delivers cutting-edge computing hardware design and extensive product offerings to address important technology arenas like open computing, cloud data center, AI, and deep learning.
In MLCommons Training V3.0, IEI made submissions on NF5468M6.
NF5468M6 is a highly versatile 4U AI server supporting between 4 and 16 NVIDIA single and double-width GPUs, making it ideal for a wide range of AI applications including AI cloud, IVA, video processing and much more. NF5468M6 offers ultra-high storage capacity and the unique function of switching topologies between Balance, Common and Cascade in one click, which helps to flexibly adapt to various needs for AI application performance optimization.
Intel
Intel has surpassed the 100-submission milestone this MLPerf cycle and remains the only CPU vendor to publish results. The training cycle is especially important as it demonstrates how Intel Xeon Scalable processors help enterprises avoid the cost and complexity of introducing special-purpose hardware for AI training. Our MLPerf Training v3.0 results on the 4th Gen Intel Xeon Scalable processor product line (codenamed Sapphire Rapids) mirror the preview results from last cycle, and we’ve also added a larger model – namely RetinaNet – to our list of submissions to demonstrate it is the best general-purpose CPU for AI training across a range of model sizes. The 4th Gen Intel Xeon Scalable processors with Intel Advanced Matrix Extensions (Intel AMX) deliver significant out-of-box performance improvements that span multiple frameworks, end-to-end data science tools, and a broad ecosystem of smart solutions. These results also highlight the excellent scaling efficiency possible using cost-effective and readily available Intel Ethernet 800 Series Network Adapters, which utilizes the open source Intel Ethernet Fabric Suite Software that’s based on Intel oneAPI.
Intel’s results show the reach of general-purpose CPUs for AI so customers can do more with the Intel-based servers that are already running their business. This is especially true for training the most frequently deployed models or transfer learning (or fine tuning) with an existing Xeon infrastructure. The BERT result in the open division is a great example of where Xeon was able to train the model in ~30 mins (31.06 mins) when scaling out to 16 nodes. In the closed division, 4th Gen Xeons could train BERT and ResNet-50 models in less than 50 mins (47.93 mins) and less than 90 mins (88.17 mins), respectively. Even for the larger RetinaNet model, Xeon was able to achieve a time of 232 mins on 16 nodes, so customers have the flexibility of using off-peak Xeon cycles either over the course of a morning, over lunch, or overnight to train their models.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex .
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See
backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names
and brands may be claimed as the property of others.
Krai
Founded by Dr Anton Lokhmotov in 2020, KRAI is a growing team of world-class engineers that is revolutionizing how companies develop and deploy AI solutions on state of the art hardware. Recognizing the growing importance of AI and the limitations of Computer Systems, KRAI and its technologies were created to serve leading industry partners and revolutionize AI solution development. Our team has been actively contributing to MLPerf since its inception in 2018, having prepared over 60% of all Inference and over 80% of all Power results to date. This feat was possible thanks to our unique workflow automation approach that unlocks the full potential of AI, software, and hardware co-design. We are proud to partner with companies like Qualcomm, HPE, Dell, Lenovo, and more.
Comparing “entry-level” options for training neural networks is of interest to many with limited resources. Our submissions uniquely use NVIDIA RTX A5000 GPUs. While A100 and A30 GPUs are more performant and efficient for ML Training, A5000 GPUs are more affordable for small organizations.
Another interesting point to note is that adopting a more recent software release doesn’t necessarily bring performance improvements. Comparing our ResNet50 submissions, we observe that the NVIDIA NGC MxNet Release 22.04 (CUDA 11.6) container enabled 12% faster training than the Release 22.08 (CUDA 11.7) on the dual A5000 system we tested.
Our team is committed to pushing the boundaries of MLPerf benchmarking in all categories, including Training ML. We are excited to pre-announce releasing the KRAI X automation technology in the near future. KRAI technologies deliver fully optimized end-to-end AI solutions, based on constraints and performance goals. Our technologies enable system designers to design and deploy AI solutions faster, by removing tedious manual processes. We are thrilled to continue helping companies develop, benchmark and optimize their AI solutions.
Nvidia
We are excited to make our first available submission and our first large-scale MLPerf Training submissions using up to 768 NVIDIA H100 Tensor Core GPUs on our internal “Pre-Eos” AI supercomputer. We are also thrilled to partner with cloud service provider, CoreWeave, on a joint submission using up to 3,584 NVIDIA H100 Tensor Core GPUs on CoreWeave’s HGX H100 infrastructure on several benchmark tests, including MLPerf’s new LLM workload, based on GPT-3 175B.
NVIDIA H100 Tensor Core GPUs ran every MLPerf Training v3.0 workload and, through software optimizations, achieved up to 17% higher performance per accelerator compared to our preview submission using the same H100 GPUs just six months ago.
Through full-stack craftsmanship, the NVIDIA AI platform demonstrated exceptional performance at scale across every MLPerf Training v3.0 workload, including the newly-added LLM workload as well as the updated DLRM benchmark. The NVIDIA AI platform was also the only one to submit results across every workload, highlighting its incredible versatility.
The NVIDIA AI platform starts with great chips and from there, innovations across core system software, powerful acceleration libraries, as well as domain-specific application frameworks enable order-of-magnitude speedups for the world’s toughest AI computing challenges. It’s available from every major cloud and server maker, and offers the quickest path to production AI and enterprise-grade support with NVIDIA AI enterprise.
Additionally, we were excited to see 11 NVIDIA partners submit great results in this round of MLPerf Training, including both on-prem and cloud-based submissions.
We also wish to commend the ongoing work that MLCommons is doing to continue to bring benchmarking best practices to AI computing, enable peer-reviewed, apples-to-apples comparisons of AI and HPC platforms, and keep pace with the rapid change that characterizes AI computing.
NVIDIA + CoreWeave
CoreWeave is a specialized cloud provider that delivers a massive scale of GPU compute on top of a fast, flexible serverless infrastructure. We build ultra-performant cloud solutions for compute-intensive use cases, including machine learning and AI, visual effects and rendering, batch processing and pixel streaming.
CoreWeave is proud to announce our first, and record setting, MLPerf submission in partnership with NVIDIA. CoreWeave’s MLPerf submission leveraged one of the largest HGX clusters in the world, featuring the latest HGX servers with NVIDIA H100 SXM5 GPUs, Intel 4th Generation Xeon Scalable Processors, and NVIDIA ConnectX-7 400G NDR InfiniBand and Bluefield-2 ethernet adapters.
This massive HGX cluster is one of the many GPU clusters built and designed for general purpose, public cloud consumption via the CoreWeave platform. The MLPerf submission, and the creation of several new HGX clusters, demonstrates CoreWeave’s ability to deliver best-in-class performance for the world’s most demanding AI/ML workloads in the public cloud.
Quanta Cloud Technology
Quanta Cloud Technology (QCT) is a global datacenter solution provider that enables diverse HPC and AI workloads. For the latest round of MLPerf Training v3.0, QCT submitted two systems in the closed division. QCT’s submission included tasks in Image Classification, Object Detection, Natural Language Processing, Speech Recognition, and Recommendation, achieving the specified quality target using its QuantaGrid-D54Q-2U System and QuantaGrid D74H-7U, a preview system. Each benchmark measures the wall-clock time required to train a model.
The QuantaGrid D54Q-2U powered by 4th Gen Intel Xeon Scalable processors delivers scalability with flexible expansion slot options including PCle 5.0, up to two double-width accelerators, up to 16TB DDR5 memory capacity and 26 drive bays, serving as a compact AI system for computer vision and language processing scenarios. In this round, the QuantaGrid-D54Q-2U Server configured with two NVIDIA H100-PCIe-80GB accelerator cards achieved outstanding performance.
The QuantaGrid D74H-7U is an 8-way GPU server equipped with the NVIDIA HGX H100 8-GPU Hopper SXM5 module, making it ideal for AI training. With innovative hardware design and software optimization, the QuantaGrid D74H-7U server achieved excellent training results.
QCT will continue providing comprehensive hardware systems, solutions, and services to academic and industrial users, and keep MLPerf results transparent with the public for the MLPerf training and inference benchmarks.
Supermicro
Supermicro has a long history of designing a wide range of products for various AI use cases. In MLPerf Training v3.0, Supermicro has submitted five systems in the closed division. Supermicro’s systems provide customers with servers built to deliver top performance for AI training workloads.
Supermicro’s mission is to provide application optimized systems for a broad range of workloads. For example, Supermicro designs and manufactures four types of systems for the NVIDIA HGX 8-GPU and 4-GPU platforms, each customizable for customers’ various requirements and workload needs through our building block approach. Supermicro offers a range of CPUs and quantities of GPU across multiple form factors for customers with different compute and environmental requirements. Furthermore, Supermicro provides customers choices on using cost-effective power supplies or genuine N+N redundancy to maximize the TCO. Now we also offer liquid cooling options for the latest NVIDIA HGX based-systems, as well as PCIe-based systems to help deployments use higher TDP CPUs and GPUs without thermal throttling.
Supermicro’s GPU A+ Server, the AS-4125GS-TNRT has flexible GPU support and configuration options: with active & passive GPUs, and dual root or single-root configurations for up to 10 double-width, full-length GPUs. Furthermore, the dual root configuration features directly attached 8 GPUs without PLX switches to achieve the lowest latency possible and improve performance, which is hugely beneficial for demanding scenarios our customers face with machine learning (ML) and HPC workloads.
The Supermicro AS-8125GS-TNHR 8U GPU Server demonstrated exceptional performance in the latest round of training. Equipped with 8x NVIDIA HGX H100 – SXM5 GPUs and support for PCIe expansion slots, this server significantly accelerates data transportation, offers impressive computational parallelism, and enhances the performance of HPC and AI/Deep Learning Training.
Supermicro’s SYS-821GE-TNHR is a high-performance, rack-mountable tower/workstation form factor GPU SuperServer. Designed to accommodate dual Intel CPUs and eight double-width NVIDIA H100 GPUs, this system delivers exceptional performance. With its outstanding results, the SYS-821GE-TNHR is an ideal choice for AI training, making it a compelling solution in the field today.
Supermicro offers a diverse range of GPU systems tailored for any environment. As part of their commitment to customer satisfaction, Supermicro continually fine-tunes these systems, ensuring optimized experiences and top-notch performance across a wide array of servers and workstations.
xFusion
xFusion Digital Technology Co., Ltd. is committed to becoming the world’s leading provider of computing power infrastructure and services. We adhere to the core values of “customer-centric, striver-oriented, long-term hard work, and win-win cooperation”, continue to create value for customers and partners, and accelerate the digital transformation of the industry.
In this performance competition of MLPerf Training v3.0, we used a new generation of GPU server product FusionServer G5500 V7 to conduct performance tests on all benchmarks under various GPU configurations and achieved excellent results.
FusionServer G5500 V7 (G5500 V7) is a new-generation 4U 2-socket GPU server. It supports a maximum of 10 x double-width GPU cards. We use Intel Xeon Platinum 6458Q CPU x2 and 8~10 A30 or L40 GPU configurations to test all evaluation items. It has made excellent achievements and achieved the best performance under the same GPU hardware configuration.
FusionServer G5500 V7 features high performance, flexible architecture, high reliability, easy deployment, and simplified management. It accelerates applications such as AI training, AI inference, high-performance computing (HPC), image and video analysis, and database, and supports enterprise and public cloud deployment.
This article first appeared on HPCwire.
{kind=link}