

Meta has introduced quantized versions of its Llama 3.2 models, enhancing on-device AI performance with up to four times faster inference speeds, a 56% model size reduction, and a 41% decrease in memory usage.
Check out the models on Hugging Face.
These models, designed to operate effectively on mobile devices, can now be accessed through Meta and Hugging Face, expanding deployment possibilities across mobile CPUs in collaboration with Arm, MediaTek, and Qualcomm.
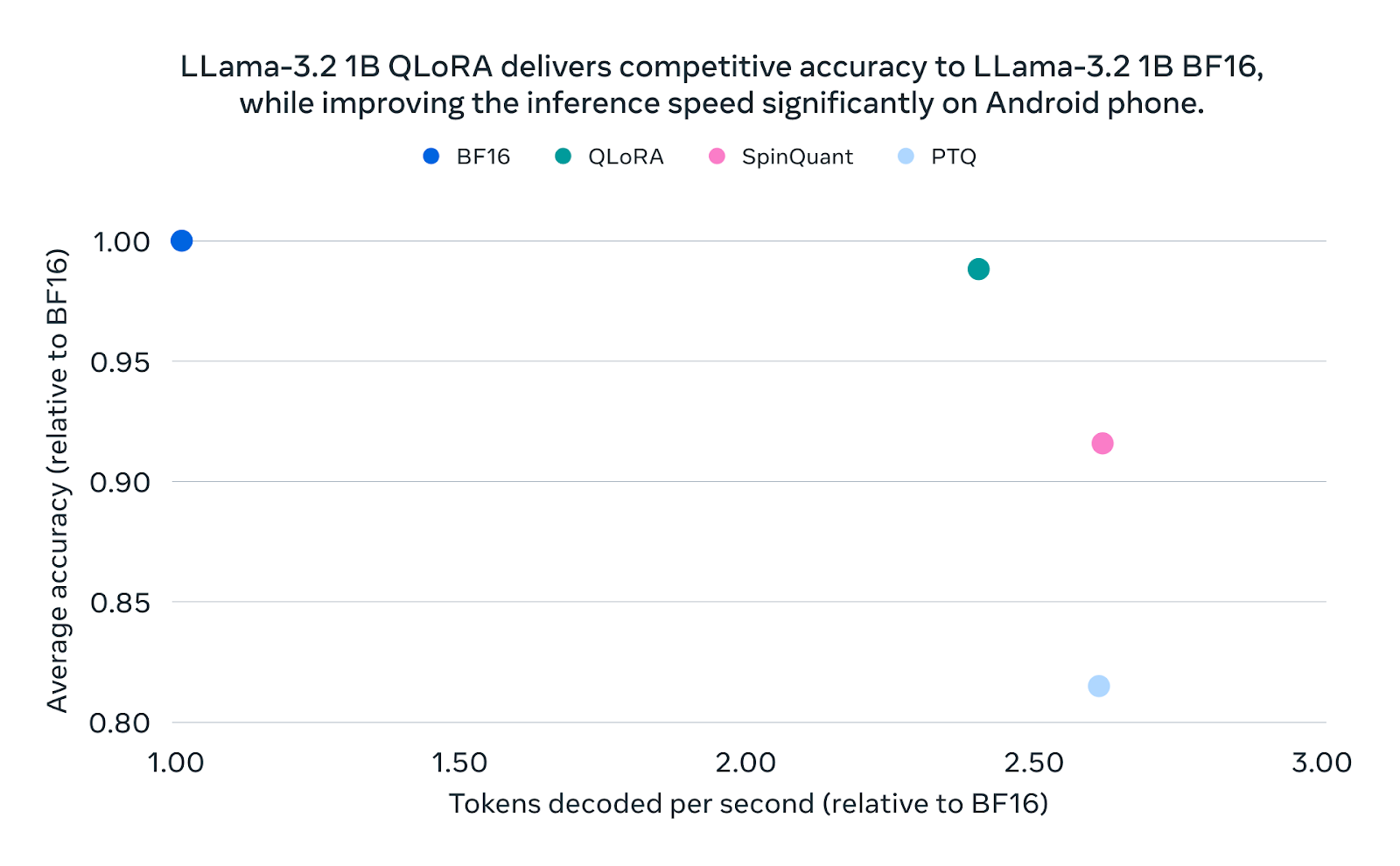
These quantized Llama models in the 1B and 3B categories are designed to match the quality and safety standards of their original versions while offering significant improvements in performance, achieving speeds 2-4 times faster. Additionally, these models reduce memory usage by an average of 41% and decrease model size by 56% compared to the initial BF16 format.
The Llama Stack reference implementation, through PyTorch’s ExecuTorch framework, supports inferences for both quantization techniques. Developed in partnership with industry leaders, these optimised models are now available for Qualcomm and MediaTek SoCs with Arm CPUs.
Meta is also exploring additional performance gains through NPU support, collaborating with partners to integrate NPU functionalities within the ExecuTorch open-source ecosystem. These efforts aim to optimise Llama 1B and 3B quantized models specifically for NPU utilisation, enhancing the models’ efficiency across a broader range of devices.
Previously, quantized models often sacrificed accuracy and performance, but Meta’s use of Quantization-Aware Training (QAT) and LoRA adaptors ensures that the new models maintain quality and safety standards. Meta utilised SpinQuant, a state-of-the-art quantization method, to prioritise model portability, reducing size while preserving functionality.
This approach allows for substantial compression without compromising on inference quality, and testing on devices like the Android OnePlus 12 confirms the models’ efficiency.
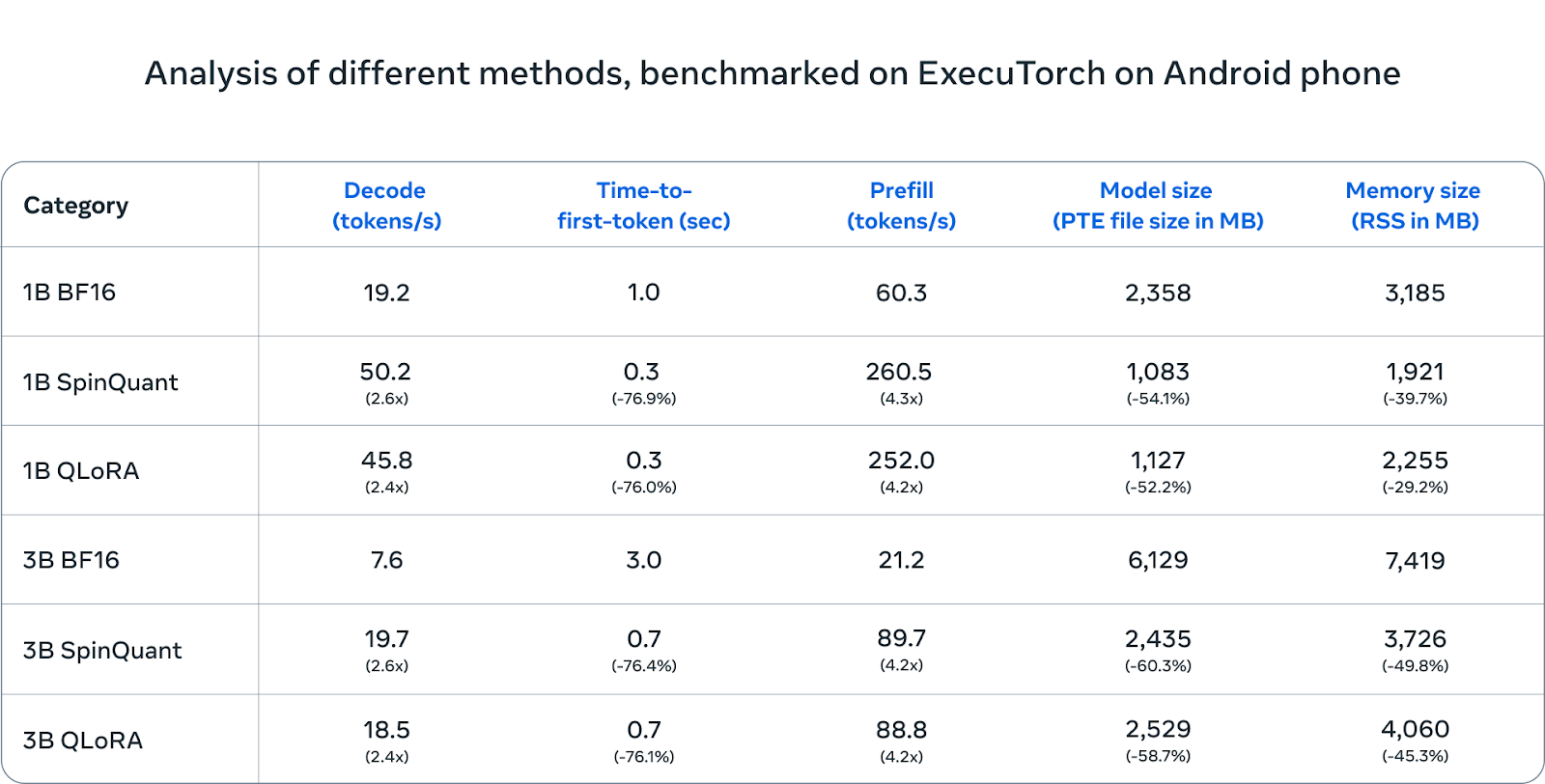
Performance testing has confirmed similar efficiencies on Samsung devices (S24+ for 1B and 3B, S22 for 1B) and shows comparable accuracy on iOS devices, though further performance evaluations are ongoing.
Quantization-Aware Training was applied to Llama 3.2 models by simulating quantization during the training process to optimise performance in low-precision environments. This process involved refining BF16 Llama 3.2 model checkpoints using QAT and an additional supervised fine-tuning (SFT) round with LoRA adaptors.
These adaptors maintain weights and activations in BF16, resembling Meta’s QLoRA technique, which combines quantization and LoRA for greater model efficiency.
Looking forward, Meta’s approach of making these quantized models will help in several on-device inference of AI models, including its products like Meta RayBan smart glasses.
In September, Meta had launched Llama 3.2, which beat all closed source models including GPT-4o on several benchmarks.
Meta recently also unveiled Meta Spirit LM, an open-source multimodal language model focused on the seamless integration of speech and text.
The post Meta Releases Quantized Llama 3.2 with 4x Inference Speed on Android Phones appeared first on AIM.