
Image from Adobe Firefly
“There were too many of us. We had access to too much money, too much equipment, and little by little, we went insane.”
Francis Ford Coppola wasn’t making a metaphor for AI companies that spend too much and lose their way, but he could have been. Apocalypse Now was epic but also a long, difficult and expensive project to make, much like GPT-4. I’d suggest that the development of LLMs has gravitated to too much money and too much equipment. And some of the “we just invented general intelligence” hype is a little insane. But now it’s the turn of open source communities to do what they do best: delivering free competing software using far less money and equipment.
OpenAI has taken over $11Bn in funding and it is estimated GPT-3.5 costs $5-$6m per training run. We know very little about GPT-4 because OpenAI isn’t telling, but I think it’s safe to assume that it isn’t smaller than GPT-3.5. There is currently a world-wide GPU shortage and – for a change – it’s not because of the latest cryptocoin. Generative AI start-ups are landing $100m+ Series A rounds at huge valuations when they don’t own any of the IP for the LLM they use to power their product. The LLM bandwagon is in high gear and the money is flowing.
It had looked like the die was cast: only deep-pocketed companies like Microsoft/OpenAI, Amazon, and Google could afford to train hundred-billion parameter models. Bigger models were assumed to be better models. GPT-3 got something wrong? Just wait until there's a bigger version and it’ll all be fine! Smaller companies looking to compete had to raise far more capital or be left building commodity integrations in the ChatGPT marketplace. Academia, with even more constrained research budgets, was relegated to the sidelines.
Fortunately, a bunch of smart people and open source projects took this as a challenge rather than a restriction. Researchers at Stanford released Alpaca, a 7-billion parameter model whose performance comes close to GPT-3.5’s 175-Billion parameter model. Lacking the resources to build a training set of the size used by OpenAI, they cleverly chose to take a trained open source LLM, LLaMA, and fine-tune it on a series of GPT-3.5 prompts and outputs instead. Essentially the model learned what GPT-3.5 does, which turns out to be a very effective strategy for replicating its behavior.
Alpaca is licensed for non-commercial use only in both code and data as it uses the open source non-commercial LLaMA model, and OpenAI explicitly disallows any use of its APIs to create competing products. That does create the tantalizing prospect of fine-tuning a different open source LLM on the prompts and output of Alpaca… creating a third GPT-3.5-like model with different licensing possibilities.
There is another layer of irony here, in that all of the major LLMs were trained on copyrighted text and images available on the Internet and they didn’t pay a penny to the rights holders. The companies claim the “fair use” exemption under US copyright law with the argument that the use is “transformative”. However, when it comes to the output of the models they build with free data, they really don’t want anyone to do the same thing to them. I expect this will change as rights-holders wise up, and may end up in court at some point.
This is a separate and distinct point to that raised by authors of restrictive-licensed open source who, for generative AI for Code products like CoPilot, object to their code being used for training on the grounds that the license is not being followed. The problem for individual open-source authors is that they need to show standing – substantive copying – and that they have incurred damages. And since the models make it hard to link output code to input (the lines of source code by the author) and there’s no economic loss (it’s supposed to be free), it’s far harder to make a case. This is unlike for-profit creators (e.g, photographers) whose entire business model is in licensing/selling their work, and who are represented by aggregators like Getty Images who can show substantive copying.
Another interesting thing about LLaMA is that it came out of Meta. It was originally released just to researchers and then leaked via BitTorrent to the world. Meta is in a fundamentally different business to OpenAI, Microsoft, Google, and Amazon in that it isn’t trying to sell you cloud services or software, and so has very different incentives. It has open-sourced its compute designs in the past (OpenCompute) and seen the community improve on them – it understands the value of open source.
Meta could turn out to be one of the most important open-source AI contributors. Not only does it have massive resources, but it benefits if there is a proliferation of great generative AI technology: there will be more content for it to monetize on social media. Meta has released three other open-source AI models: ImageBind (multi-dimensional data indexing), DINOv2 (computer vision) and Segment Anything. The latter identifies unique objects in images and is released under the highly permissive Apache License.
Finally we also had the alleged leaking of an internal Google document “We Have No Moat, and Neither Does OpenAI” which takes a dim view of closed models vs. the innovation of communities producing far smaller, cheaper models that perform close to or better than their closed source counterparts. I say allegedly because there is no way to verify the source of the article as being Google internal. However, it does contain this compelling graph:
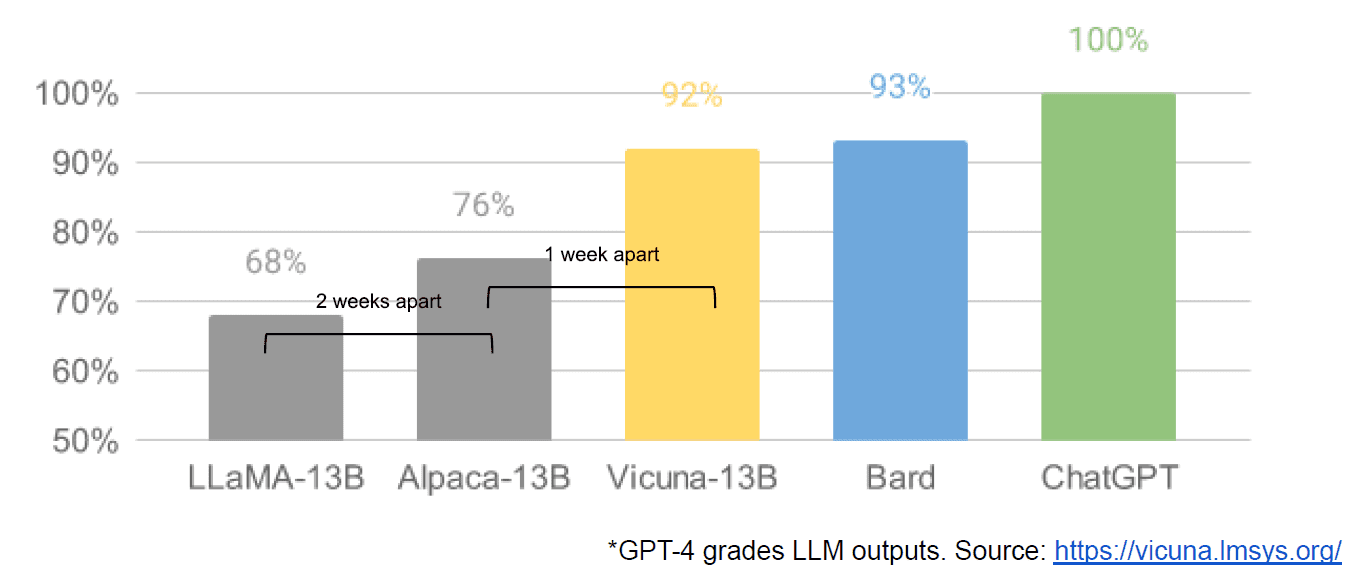
The vertical axis is the grading of the LLM outputs by GPT-4, to be clear.
Stable Diffusion, which synthesizes images from text, is another example of where open source generative AI has been able to advance faster than proprietary models. A recent iteration of that project (ControlNet) has improved it such that it has surpassed Dall-E2’s capabilities. This came about from a whole lot of tinkering all over the world, resulting in a pace of advance that is hard for any single institution to match. Some of those tinkerers figured out how to make Stable Diffusion faster to train and run on cheaper hardware, enabling shorter iteration cycles by more people.
And so we have come full circle. Not having too much money and too much equipment has inspired a cunning level of innovation by a whole community of ordinary people. What a time to be an AI developer.
Mathew Lodge is CEO of Diffblue, an AI For Code startup. He has 25+ years’ diverse experience in product leadership at companies such as Anaconda and VMware. Lodge is currently serves on the board of the Good Law Project and is Deputy Chair of the Board of Trustees of the Royal Photographic Society.
- Introducing MPT-7B: A New Open-Source LLM
- The 7 Best Open Source AI Libraries You May Not Have Heard Of
- Top Open Source Large Language Models
- GitHub Copilot Open Source Alternatives
- Baize: An Open-Source Chat Model (But Different?)
- OpenChatKit: Open-Source ChatGPT Alternative
{kind=link}