
Image by Author
SQL (Structured Query Language), as you probably, know, helps you collect data from databases.
It is specifically designed for that. In other words, it works with rows and columns, allowing you to manipulate data from databases using SQL queries.
What is SQL Query?
A SQL query is a bunch of instructions you give to the database to collect information from it.
You can collect and manipulate data from the database by using these queries.
By using them, you can create reports, perform data analysis, and more.
Due to these queries' form and length, execution times might be significant, primarily if you work with larger data tables.
Why Do We Need SQL Query Optimization?
SQL query optimization's purpose is to make sure you efficiently use the resources. In plain English, it reduces execution time, saves costs, and improves performance. It is an important skill for developers and data analysts. It’s not only important to return the right data from the database. It’s also important to know how efficiently you do that.
You should always ask yourself: “Is there a better way to write my query?”
Let’s talk more in-depth about the reasons for that.
Resource efficiency: Poorly optimized SQL queries would consume excessive system resources, like CPU and memory. This might lead to reduced overall system performance. Optimizing SQL queries ensures these resources are used efficiently. This, in turn, leads to better performance and scalability.
Reduced execution time: If the queries run slowly, this will negatively impact user experience. Or on an application performance if you have an application running. Optimizing queries can help reduce execution time, providing faster response times and a better user experience.
Cost savings: Optimized queries can diminish the hardware and infrastructure needed to support the database system. This can lead to cost savings in hardware, energy, and maintenance costs.
Check out “Best Practices to Write SQL Queries” that can help you find out how your code structure can be improved, even if it is correct.
SQL Query Optimization Techniques
Here’s the overview of the SQL query optimization techniques we’ll cover in this article.
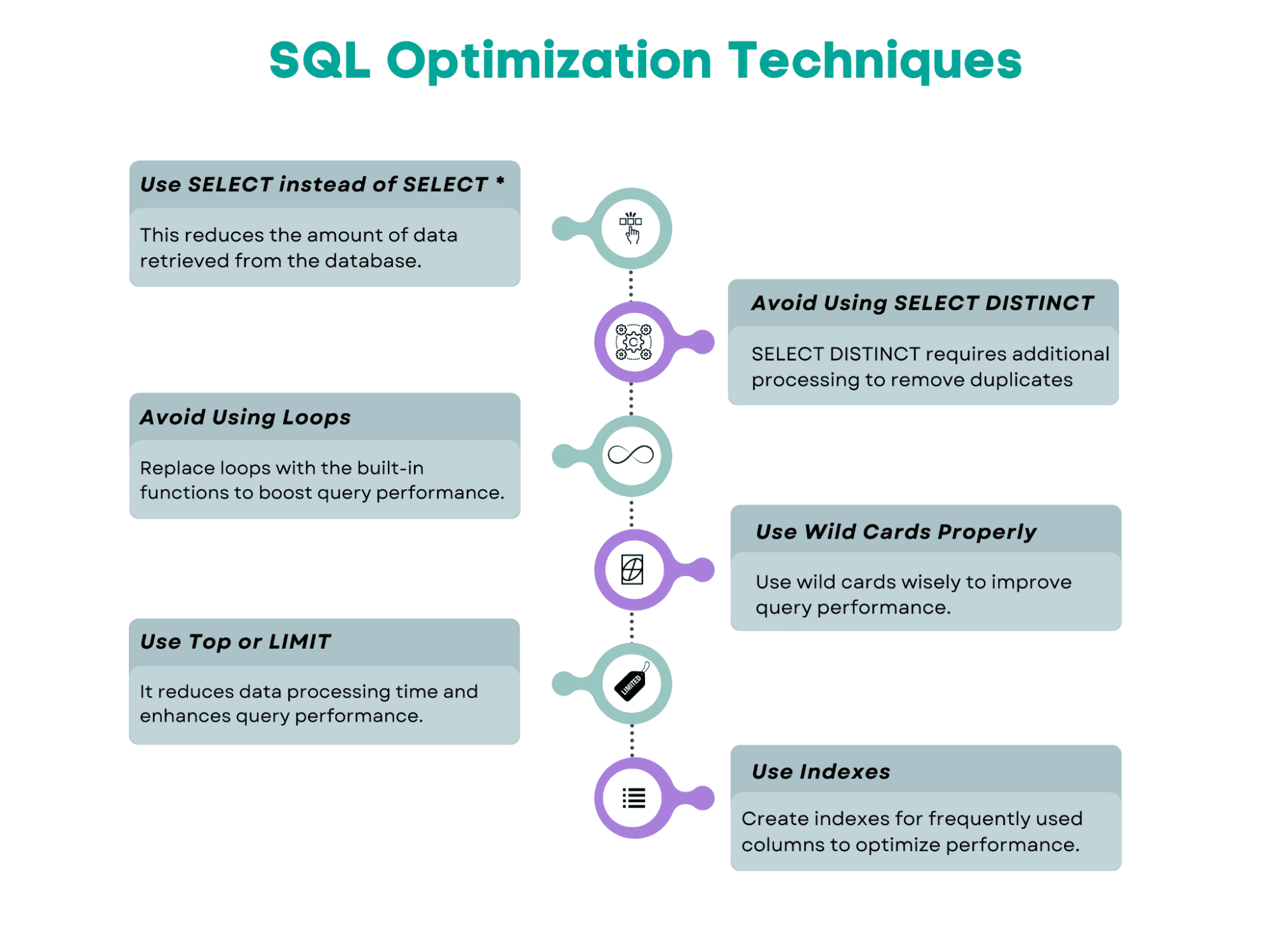
Image by Author
Here's the flowchart that shows the suggested steps to follow when optimizing the SQL query. We will follow the same approach in our examples. It's worth noting that optimization tools can also help improve query performance. So, let's explore these techniques by beginning with the well-known SQL command, SELECT.
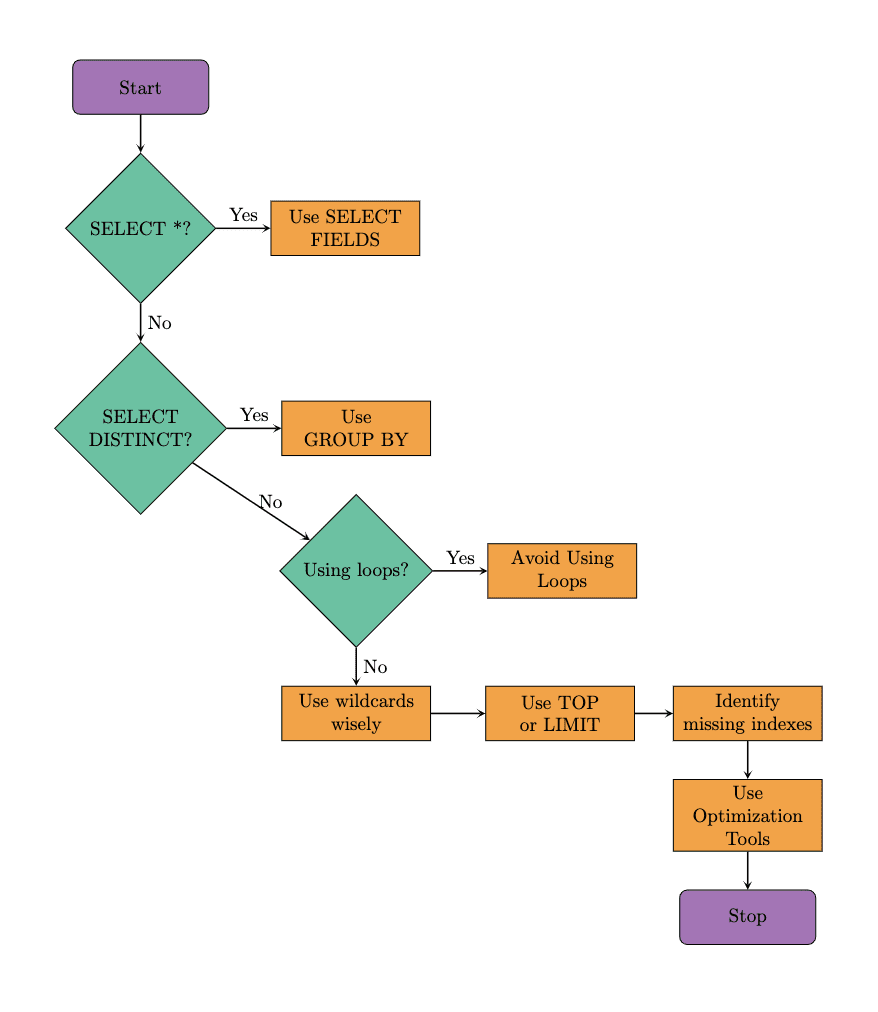
Image by Author
Use SELECT With Specified Fields Instead of SELECT *
When you use SELECT *, it will return all the rows and all the columns from the table(s). You need to ask yourself whether you really need that.
Instead of scanning the whole database, use the specific fields after SELECT.
In the example, we will replace SELECT * with specific column names. As you will see, this will reduce the amount of data retrieved.
As a result, queries run more quickly since the database must obtain and provide the requested columns, not all of the table's columns.
This minimizes the I/O burden on the database, which is especially helpful when a table includes lots of columns or plenty of data rows.
Below is the code before the optimization.
SELECT * FROM customer;Here is the output.
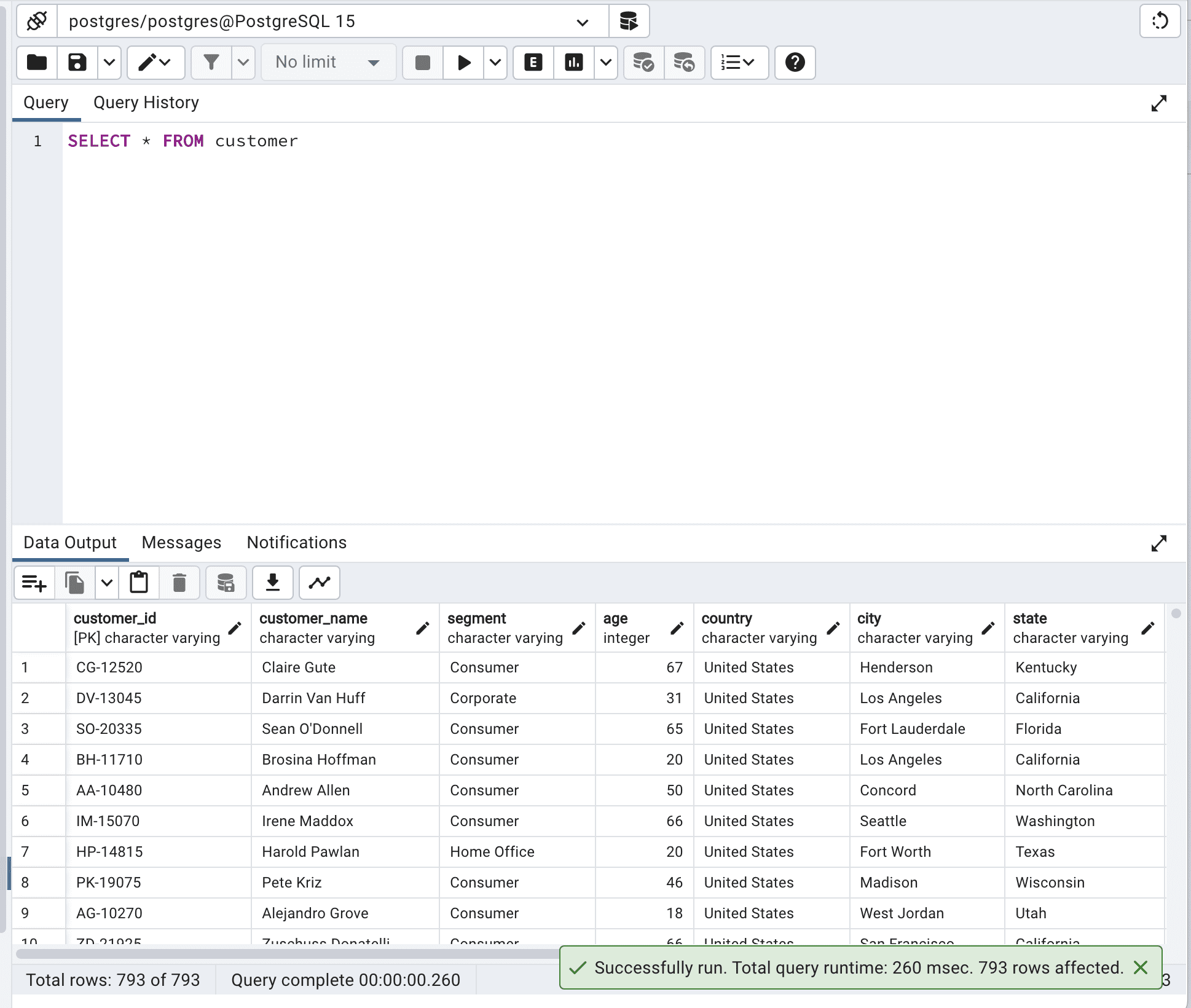
The total query runtime is 260 msec. This can be improved.
To show you that, I will select only 3 different columns instead of selecting all.
You can select the column you need according to your project needs.
Here is the code.
SELECT customer_id, age, country FROM customer;And this is the output.
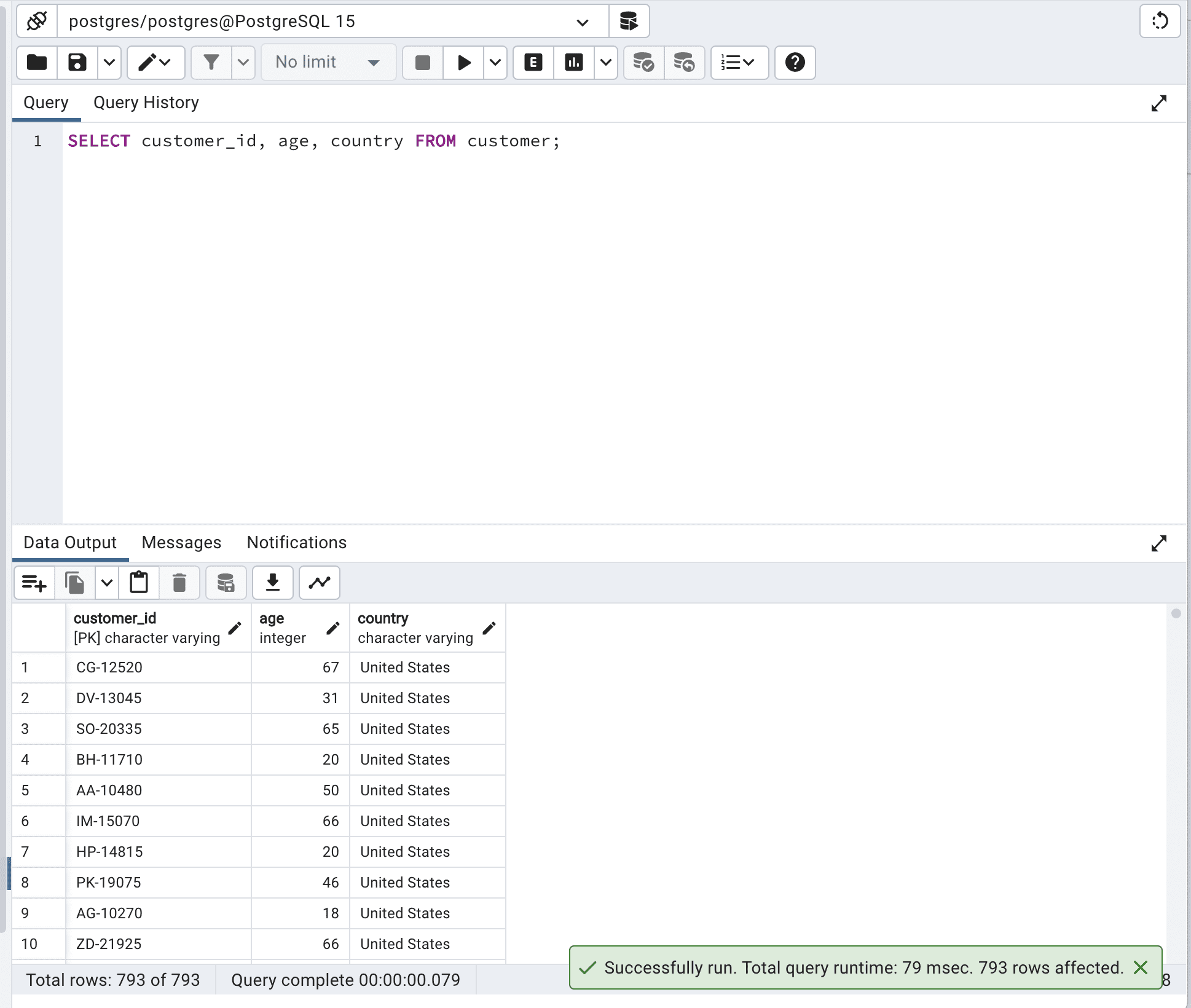
As you can see, by defining the fields we want to select, we do not force the database to scan all data it has, so the run time is reduced from 260 to 79msec.
Imagine what the difference would be with millions or billions of rows. Or hundreds of columns.
Avoid Using SELECT DISTINCT
SELECT DISTINCT is used to return unique values in a specified column. To do that, the database engine must scan the entire table and remove duplicate values. In many cases, using an alternative approach like GROUP BY can lead to better performance due to reducing the number of data processed.
Here is the code.
SELECT DISTINCT segment FROM customer;Here is the output.
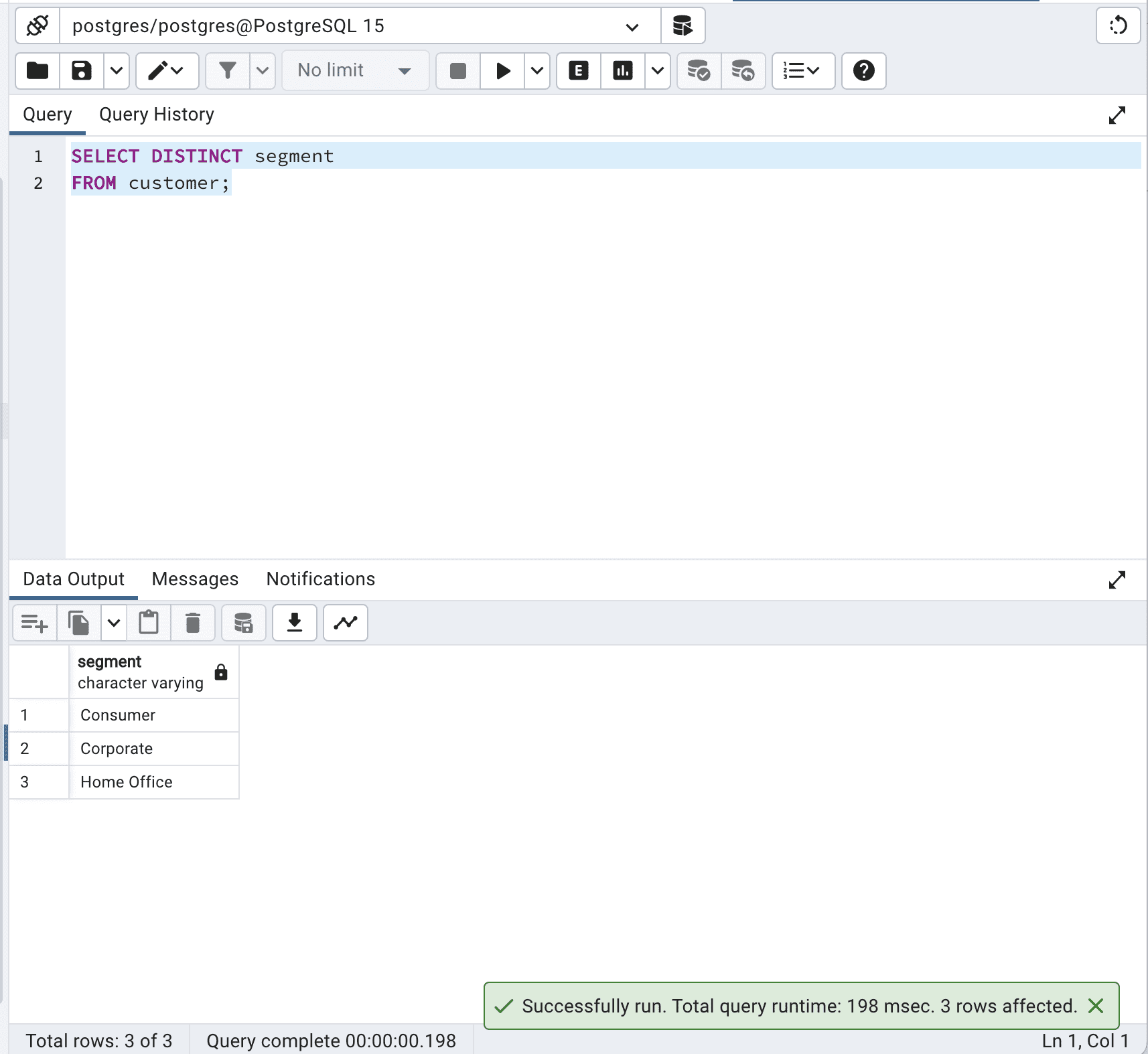
Our code?? retrieves the unique values in the segment column from the customer table. The database engine must process all records in the table, identify duplicate values, and return only unique values. This can be costly in terms of time and resources, particularly for large tables.
In the alternative version, the following query retrieves the unique values in the segment column by using a GROUP BY clause. The GROUP BY clause groups the records based on the specified column(s) and returns one record for each group.
Here is the code.
SELECT segment FROM customer GROUP BY segment;Here is the output.
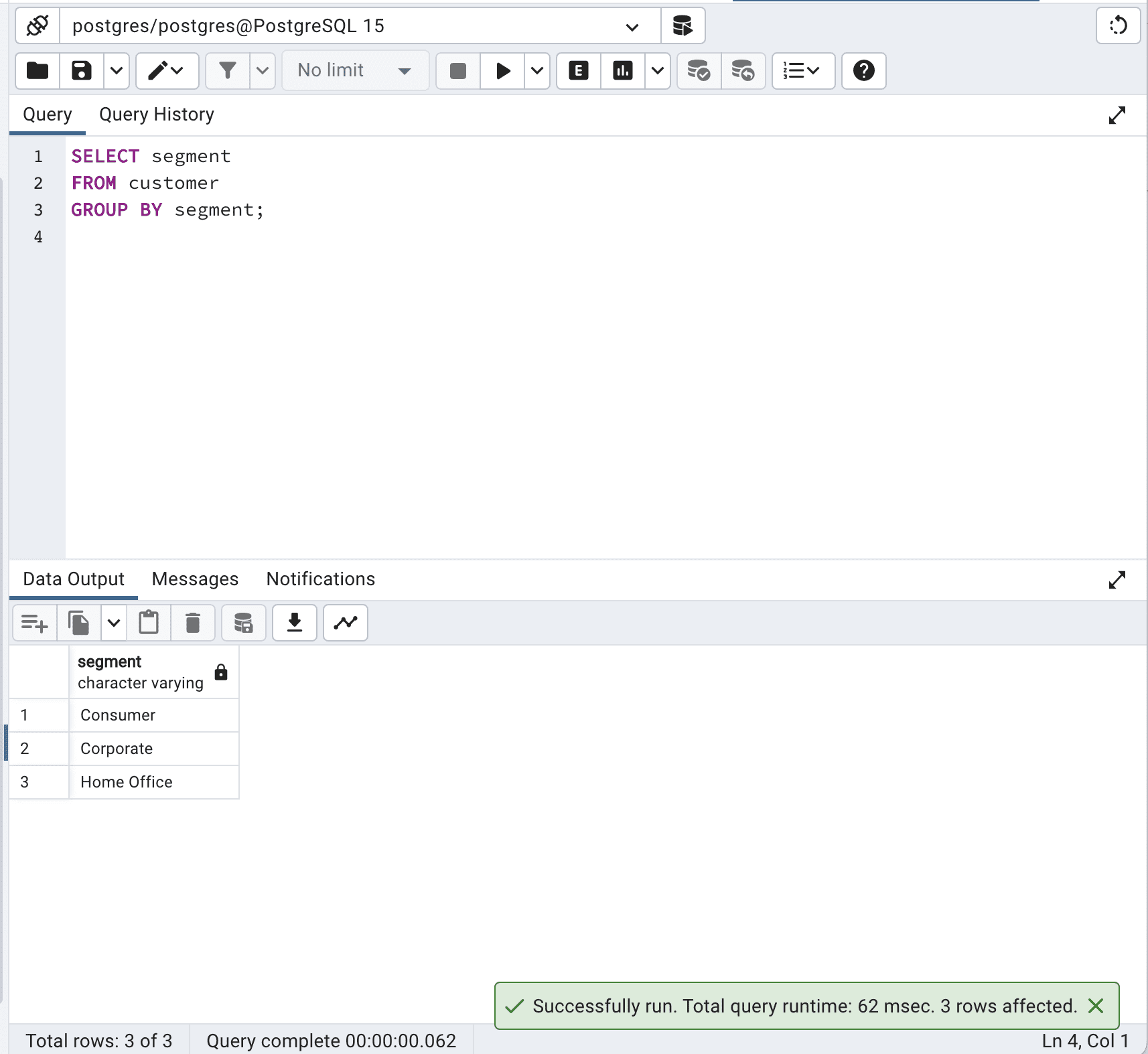
In this case, the GROUP BY clause effectively groups the records by the segment column, resulting in the same output as the SELECT DISTINCT query.
By avoiding SELECT DISTINCT and using GROUP BY instead, you can optimize SQL queries and reduce the total query time from 198 to 62 msec which is more than 3 times faster.
Avoid Using Loops
Loops might cause your query to be slower since they force the database to go through the records one by one.
When possible, use built-in operations and SQL functions, which can take advantage of database engine optimizations and process data more efficiently.
Let’s define a custom function with a loop.
CREATE OR REPLACE FUNCTION sum_ages_with_loop() RETURNS TABLE (country_name TEXT, sum_age INTEGER) AS $$ DECLARE country_record RECORD; age_sum INTEGER; BEGIN FOR country_record IN SELECT DISTINCT country FROM customer WHERE segment = 'Corporate' LOOP SELECT SUM(age) INTO age_sum FROM customer WHERE country = country_record.country AND segment = 'Corporate'; country_name := country_record.country; sum_age := age_sum; RETURN NEXT; END LOOP; END; $$ LANGUAGE plpgsql;The code above uses a loop-based approach to calculate the sum of ages for each country where the customer segment is 'Corporate'.
It first retrieves a list of distinct countries and then iterates through each country using a loop, calculating the sum of the ages of customers in that country. This approach can be slow and inefficient, as it processes the data row by row.
Let’s now run this function.
SELECT * FROM sum_ages_with_loop()Here is the output.
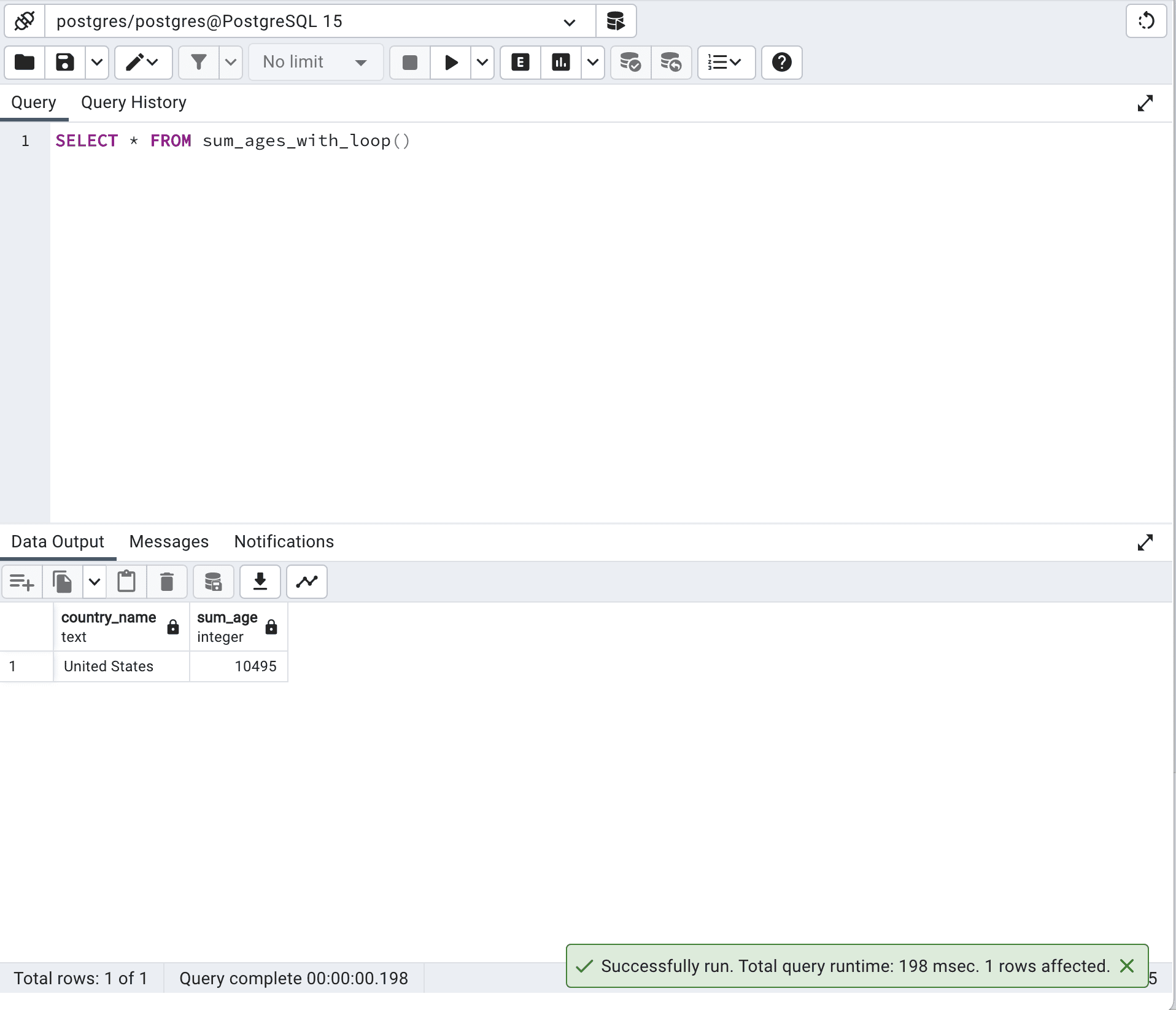
The runtime with this approach is 198 milliseconds.
Let’s see our optimized SQL code.
SELECT country, SUM(age) AS sum_age FROM customer WHERE segment = 'Corporate' GROUP BY country;Here is its output.
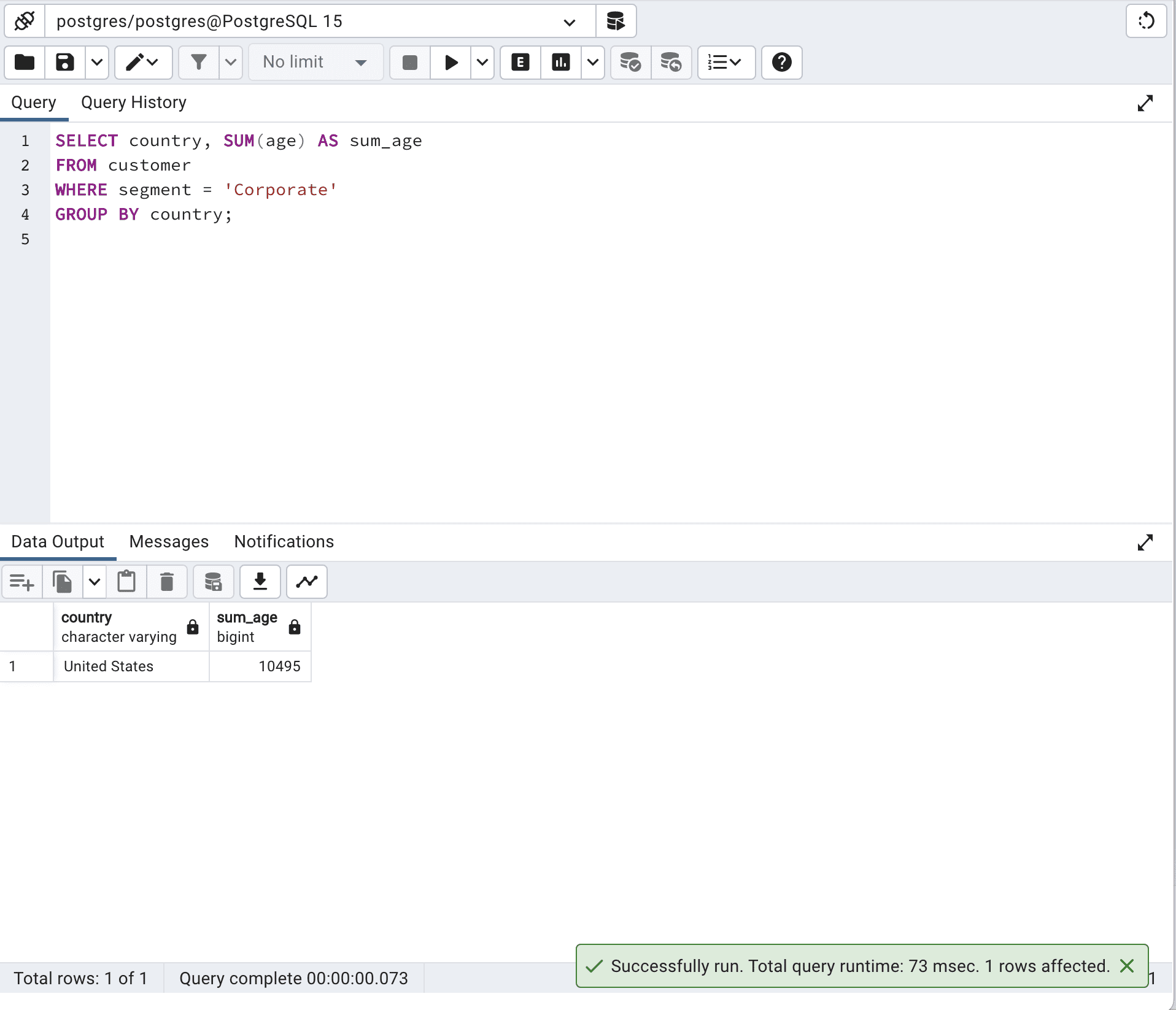
In general, the optimized version using a single SQL query will perform better, as it takes advantage of the database engine's optimization capabilities.
In order to get the same result in our first code, we use a loop in a PL/pgSQL function, which is often slower and less effective than doing it with a single SQL query. And it forces you to write much more lines of code!
Use Wild Cards Properly
The proper use of wildcards is vital for optimizing SQL queries, especially when it comes to matching strings and patterns.
Wildcards are special characters used in SQL queries to find specific patterns.
The most common wildcards in SQL are “%” and ” _”, where “%“ represents any sequence of characters and “_” represents a single character.
Using wildcards wisely is important because improper usage can lead to performance issues, especially in large databases.
However, using them efficiently can greatly improve the performance of string-matching and pattern-matching queries.
Now let’s see our example.
This query uses the RIGHT() function to extract the last three characters of the customer_name column and then checks if it equals 'son'.
SELECT customer_name FROM customer WHERE RIGHT(customer_name, 3) = 'son';Here is the output.
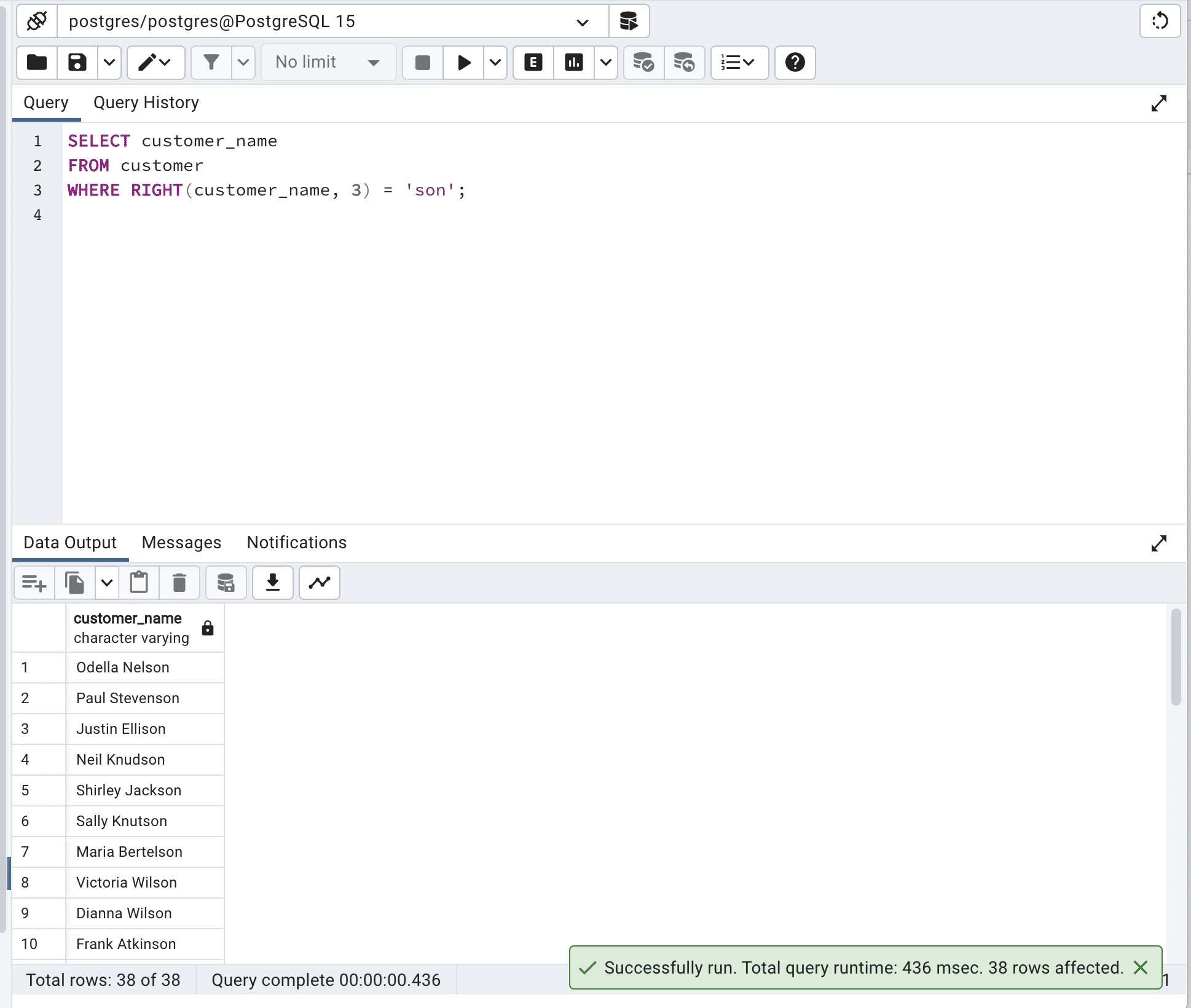
Although this query achieves the desired result, it is not that efficient because the RIGHT() function has to be applied to every row in the table.
Let’s optimize our code by using wildcards.
SELECT customer_name FROM customer WHERE customer_name LIKE '%son';Here is the output.
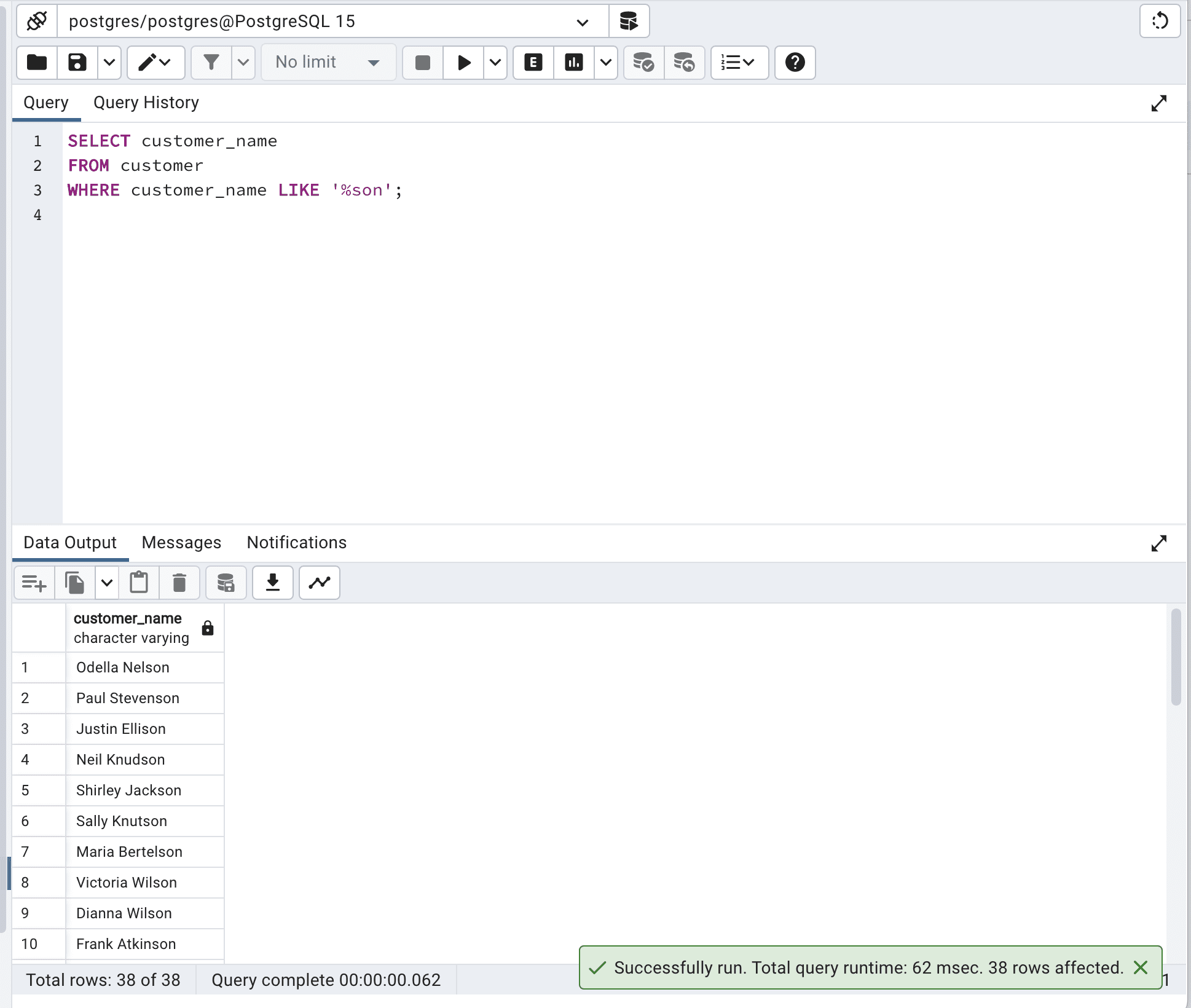
This optimized SQL query uses the LIKE operator and the wildcard “%” to search for records where the customer_name column ends with 'son'.
This approach is more efficient because it takes advantage of the database engine's pattern-matching capabilities, and it can make better use of indexes if available.
And as we can see, the total query time is reduced from 436 msec to 62 msec, which is almost 7 times faster.
Use Top or LIMIT to Limit the Number of Sample Results
Using TOP or LIMIT to limit the sample results is vital for optimizing SQL queries, particularly when dealing with large tables.
These clauses allow you to retrieve only a specified number of records from a table rather than all the records, which can be beneficial for performance.
Now, let’s retrieve all information from the customer table.
SELECT * FROM customerHere is the output.
When dealing with larger tables, this operation can increase I/O and network latency, which might decrease your SQL query performance.
Now let’s optimize our code by limiting the output to 10.
SELECT * FROM customer LIMIT 10;Here is the output.
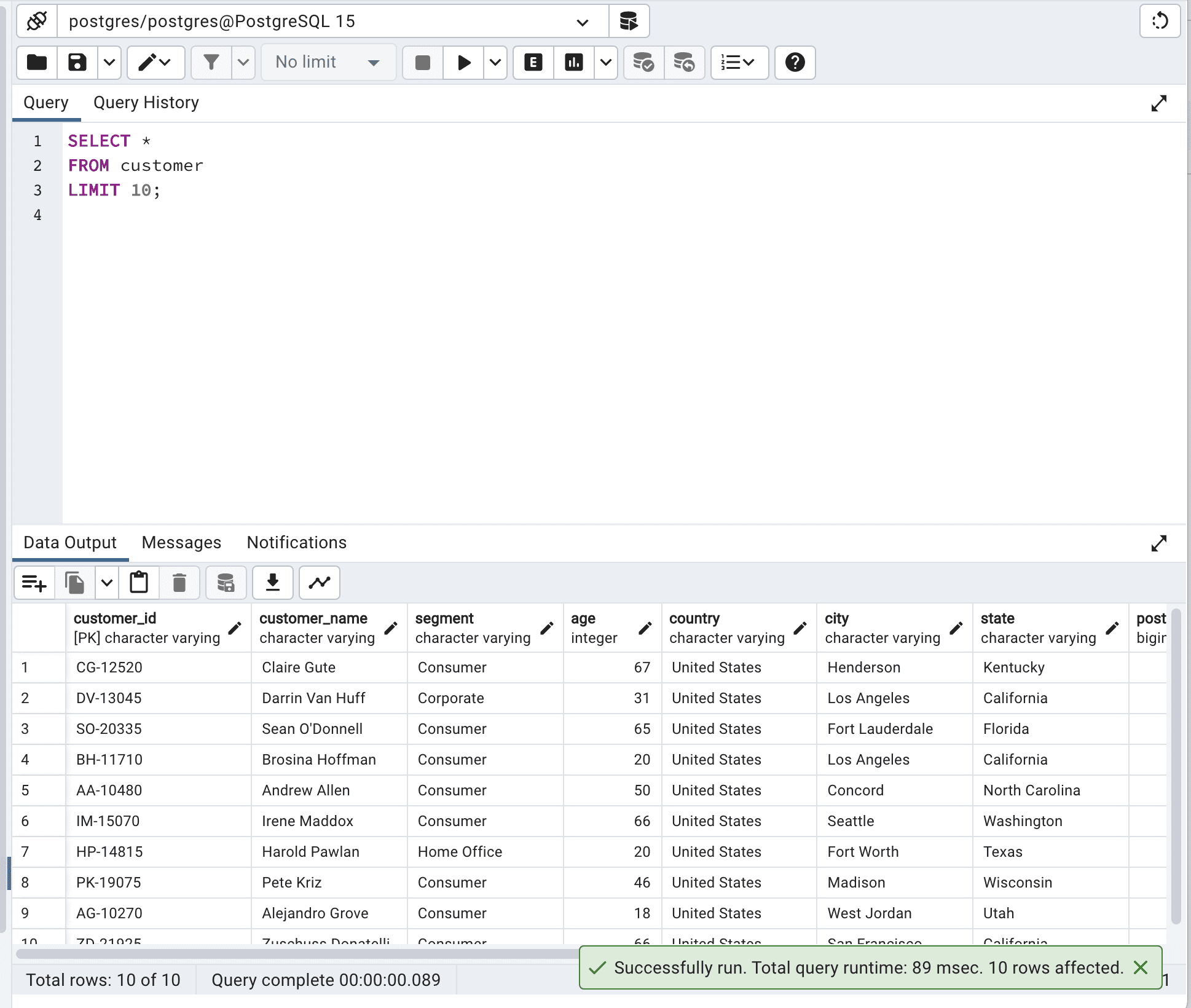
By limiting output, you will reduce network latency and memory usage and improve response time, especially with larger tables. In our example, after SQL query optimization, the total query runtime decreased from 260msec to 89msec.
So our query becomes almost 3 times faster.
Use Indexes
This time, we will Identify and create appropriate indexes for the columns used in the WHERE, JOIN, and ORDER BY clauses to improve query performance.
By indexing frequently accessed columns, the database can quicker retrieve data.
Now, let’s run the following query first.
SELECT customer_id, customer_name FROM customer WHERE segment = 'Corporate';Here is the output.
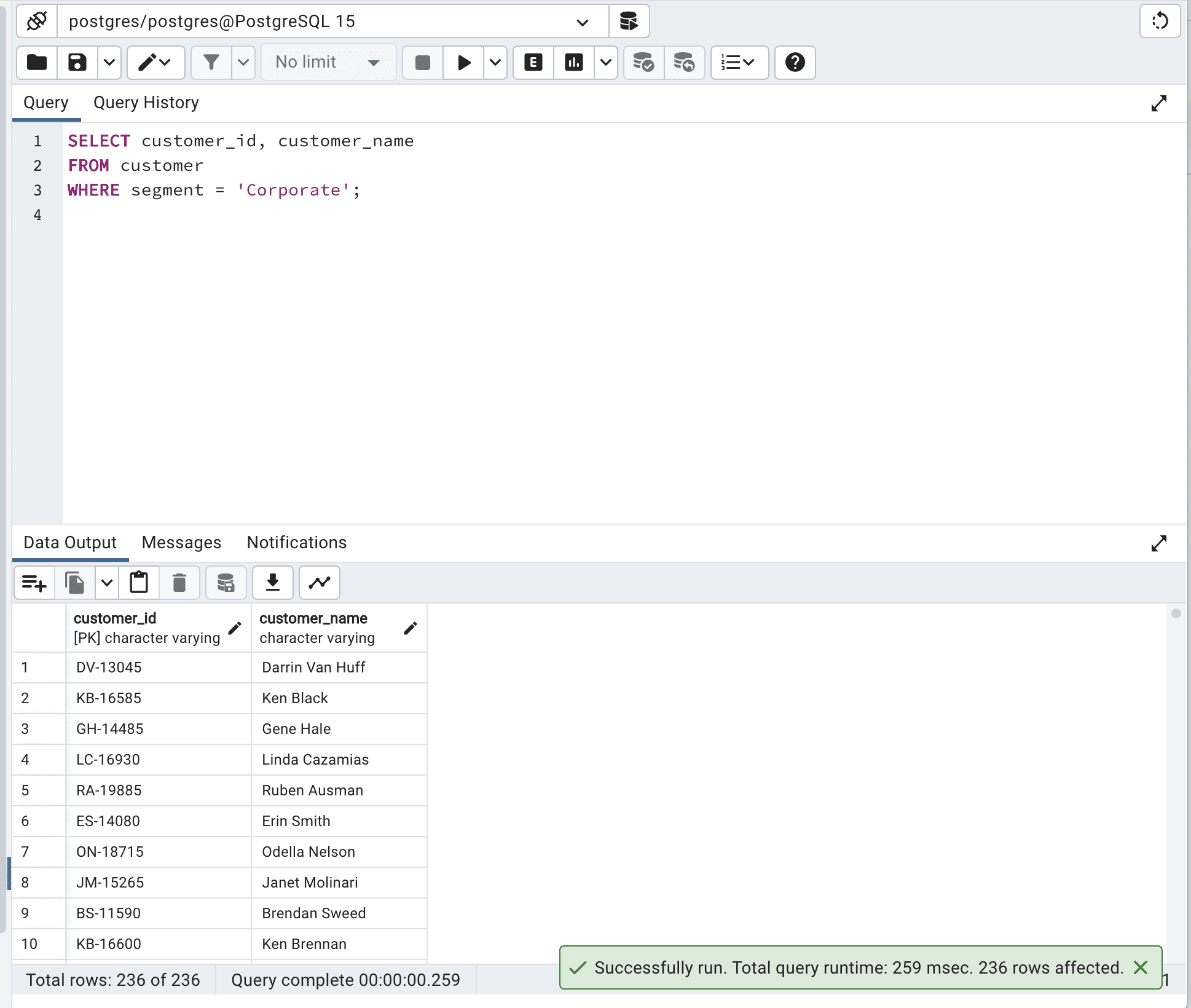
Our query runtime is 259 msec.
Let’s try to improve on that by creating the index.
CREATE INDEX idx_segment ON customer (segment);Great, now let’s run our code again.
SELECT customer_id, customer_name FROM customer WITH (INDEX(idx_segment)) WHERE segment = 'Corporate';Here is the output.
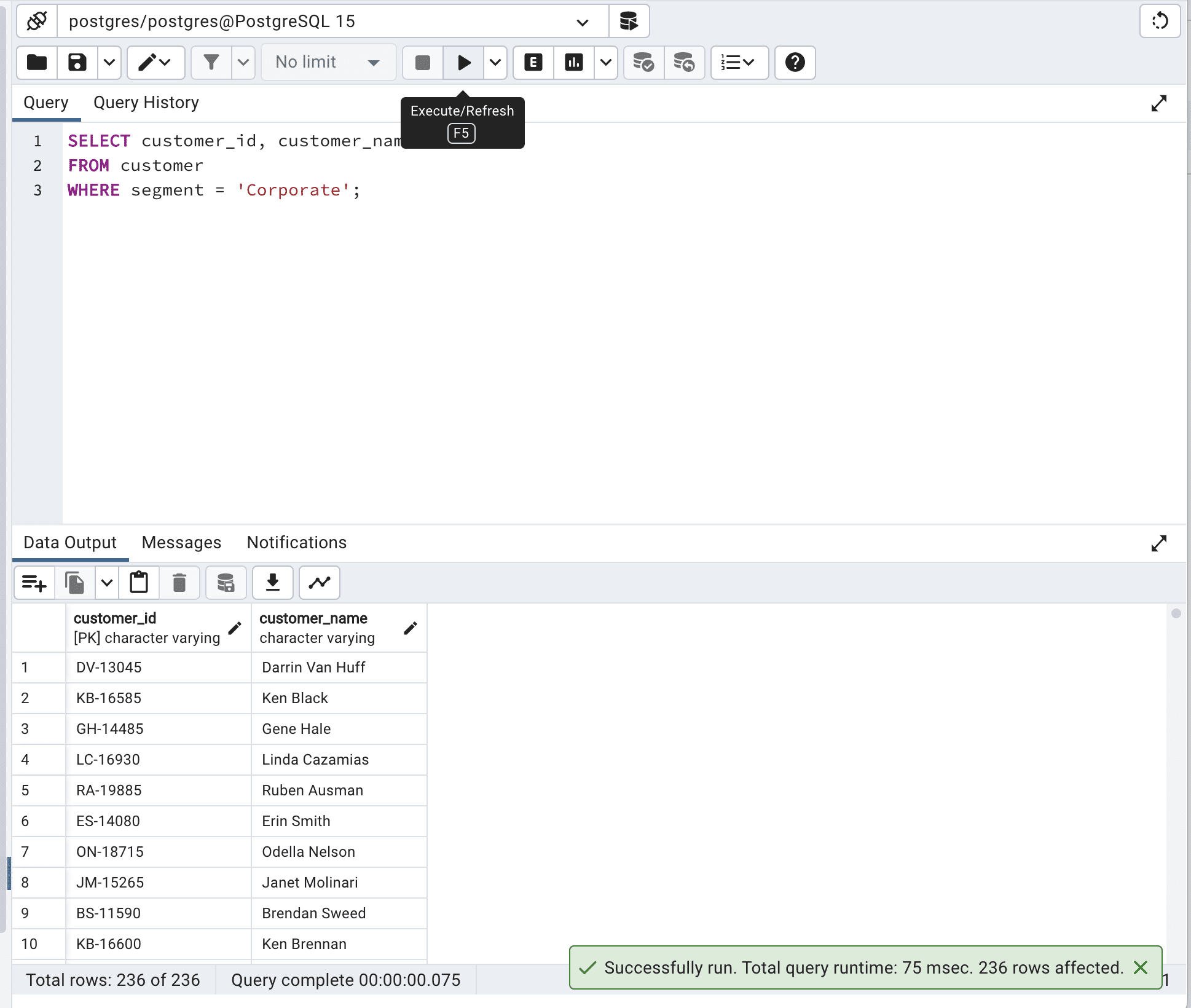
By using idx_segment in INDEX(), the database engine was able to efficiently search through the customer table based on the segment column, making the query run faster – it reduced the total query time from 259 msec. to 75 msec.
Bonus Section: Use SQL Query Optimization Tools
Due to the complexity of long codes and highly complex queries, you might consider using query optimization tools.
These tools can analyze your query execution plans, identify missing indexes, and suggest alternative query structures to help optimize your queries. Some popular query optimization tools include:
- SolarWinds Database Performance Analyzer: This tool helps you keep an eye on and improve database performance. It shows you problems with queries and how they are run. It works with different database systems like SQL Server, Oracle, and MySQL.
You can find it here.
- SQL Query Tuner for SQL Diagnostic Manager: This tool has advanced features for making queries work better, like performance tips, index checking, and showing how queries are run. It helps you make SQL queries better by finding and fixing issues.
- SQL Server Management Studio (SSMS): SSMS has built-in tools for checking performance and improving queries, like Activity Monitor, Execution Plan Analysis, and Index Tuning Wizard.
- EverSQL: EverSQL is an online tool that automatically improves your queries by looking at the database structure and how queries are run. It gives you advice and rewrites your SQL queries to make them work faster.
Using SQL query optimization tools and resources is vital to improving your queries. With these tools, you can learn how your queries work, find issues, and use best practices to get data faster and improve your applications.
If you want to simplify your complex SQL queries, look at this “How to Simplify Complex SQL Queries”.
Final Notes
The changes we made by optimizing the SQL queries above might seem insignificant due to their scale(ms). But as the amount of data you work with grows, these milliseconds will increase to seconds, minutes, and possibly even hours. You’ll realize then that these SQL query optimization techniques are highly important.
If you seek more, here are the top 30 SQL Query Interview Questions, which will help those who want to also prepare for an interview when learning.
Thanks for reading!
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.
- 4 Useful Intermediate SQL Queries for Data Science
- 15 Python Snippets to Optimize your Data Science Pipeline
- Book Metadata and Cover Retrieval Using OCR and Google Books API
- 5 Tricky SQL Queries Solved
- KDnuggets News, December 7: Top 10 Data Science Myths Busted • 4 Useful…
- Top 10 MLOps Tools to Optimize & Manage Machine Learning Lifecycle
{kind=link}