
A study by Google DeepMind introduces the concept of “Socratic learning,” a method where AI improves itself through language interactions or games.
Per this research, by feeding its outputs back into its inputs, the system enables continuous self-improvement without external input. This study is inspired by Socrates’ idea of learning through internal questioning, showing how AI improves itself within closed systems.
Inside the Socratic Framework Learning
The language games framework is a way to help AI systems learn and improve by using language in meaningful, interactive activities. Inspired by Wittgenstein’s ideas, it treats language as something that gets its meaning through use, like in “games” where agents follow rules to achieve specific goals.
These games have three main parts: agents (the players) who use language to communicate, rules that guide what they can do, and feedback (a scoring system) to show how well they are performing.
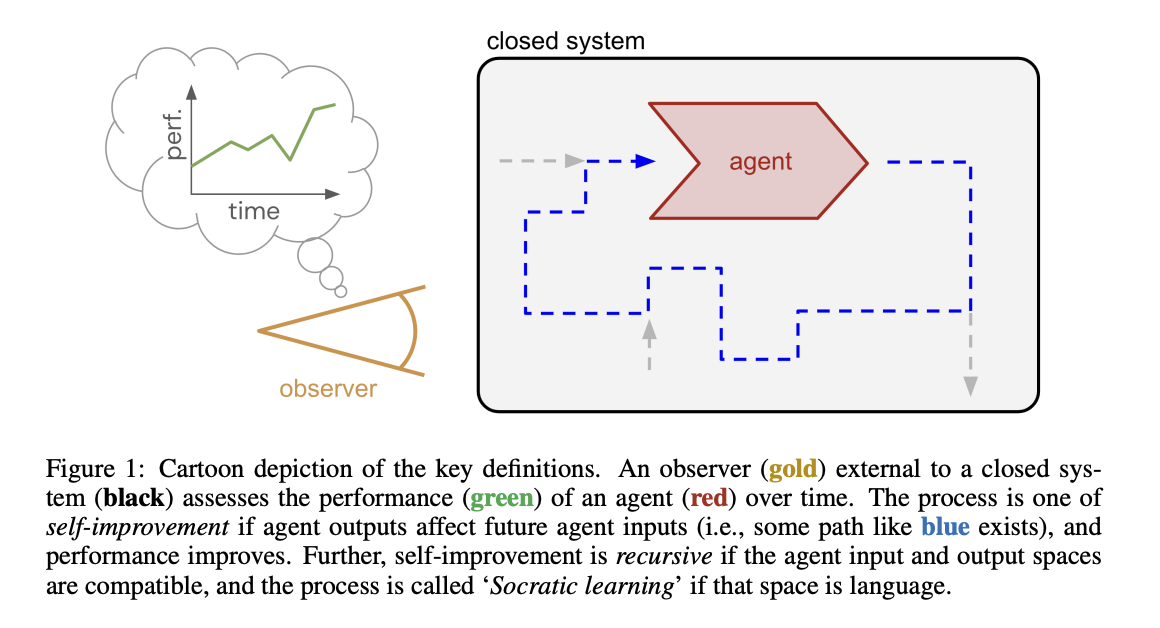
This approach helps AI learn by practicing over and over, getting better each time. It also provides clear feedback to keep the learning on track and exposes the AI to many different situations to build a variety of skills. For example, AI can practice debating to improve reasoning, role-playing to understand new situations, or negotiating to become better at making decisions and communicating. This makes learning focused, interactive, and effective.
Limitations of AI Autonomy
The language games framework and Socratic learning face key challenges. Misaligned feedback can lead AI to learn undesirable behaviours, and limited diversity in closed systems risks over-specialisation. Resource constraints like insufficient computational power hinder scalability, while the AI may drift from its objectives, optimising for unintended outcomes. The framework is also largely theoretical, with no proven practical applications. Additionally, recursive self-improvement risks amplifying errors over time. These challenges highlight the need for careful design, diverse inputs, and robust oversight to ensure effective and aligned AI learning.
Unlike most AI research that relies on external data, feedback, or sensory grounding, this paper focuses on closed systems, where the AI must achieve self-improvement entirely within its internal environment. This removes reliance on external inputs, making it unique in its scope.
There’s extensive discussion about this framework online, and a Reddit user noted that while applying the game paradigm to language is highly promising, designing effective scoring systems for language-based outcomes remains a major challenge.
Is Recursive Learning Deepmind’s Path to AGI?
Google DeepMind also introduced Genie 2, a large-scale foundation world model capable of generating a wide variety of playable 3D environments. Genie 2’s helps agents become more adaptable and able to generalise across different tasks.
DeepMind is creating more flexible AI systems that can learn in constantly changing environments. These advances could impact areas like self-driving cars, real-time simulations, AI-generated content, and climate forecasting. They also mark an important step towards achieving Artificial General Intelligence (AGI).
On the whole, this study is inspired by the idea of agents improving themselves through feedback, like AlphaZero in reinforcement learning (RL). It focuses on using language as a tool for reasoning and self-learning.
The post Google DeepMind Introduces Socratic Learning with Language Games appeared first on Analytics India Magazine.
{kind=link}