Co-Author by Srujan and Travis Thompson
The data domain has matured profusely and has come a long way since the advent of thick files in the basement. The journey has been nothing short of fascinating and equally thrilling as the software revolution. The good part is we are right in the middle of the data revolution and have the opportunity to witness it first-hand.
We were staring at completely different problems 5-10 years ago, and today we are staring at a completely new set. Some sprung up as a consequence of the Cambrian explosion of data, and some surprisingly originated as a consequence of the solutions devised to solve the initial problems.
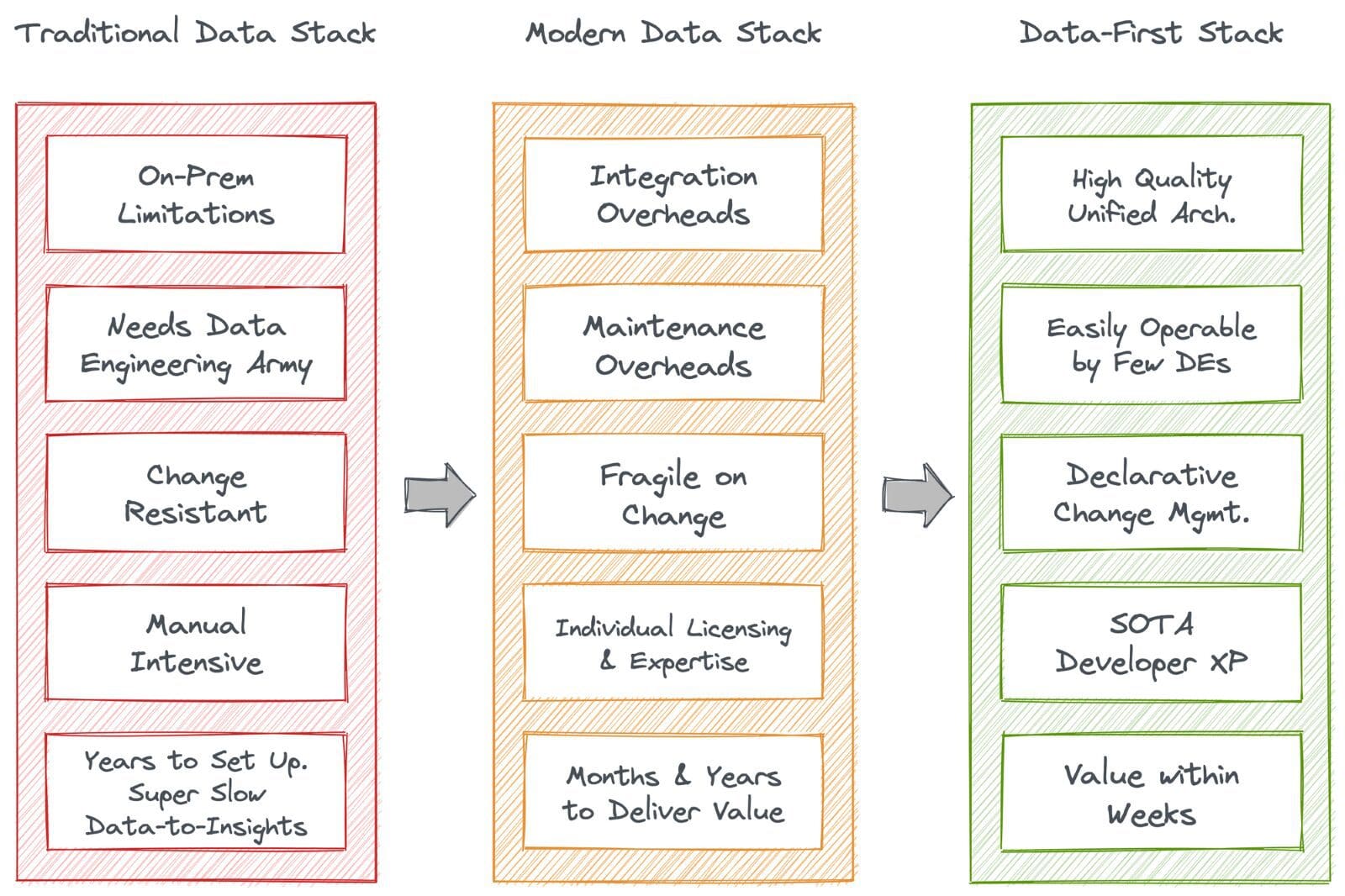
This led to many transitions across a plethora of data stacks and architectures. However, what stood out were three simple yet fundamentally pivoting stacks: The Traditional Data Stack, the Modern Data Stack, and the Data-First Stack. Let’s see how that played out.
Evolutionary Fundamentals: Patterns that Triggered Change in the Data Landscape
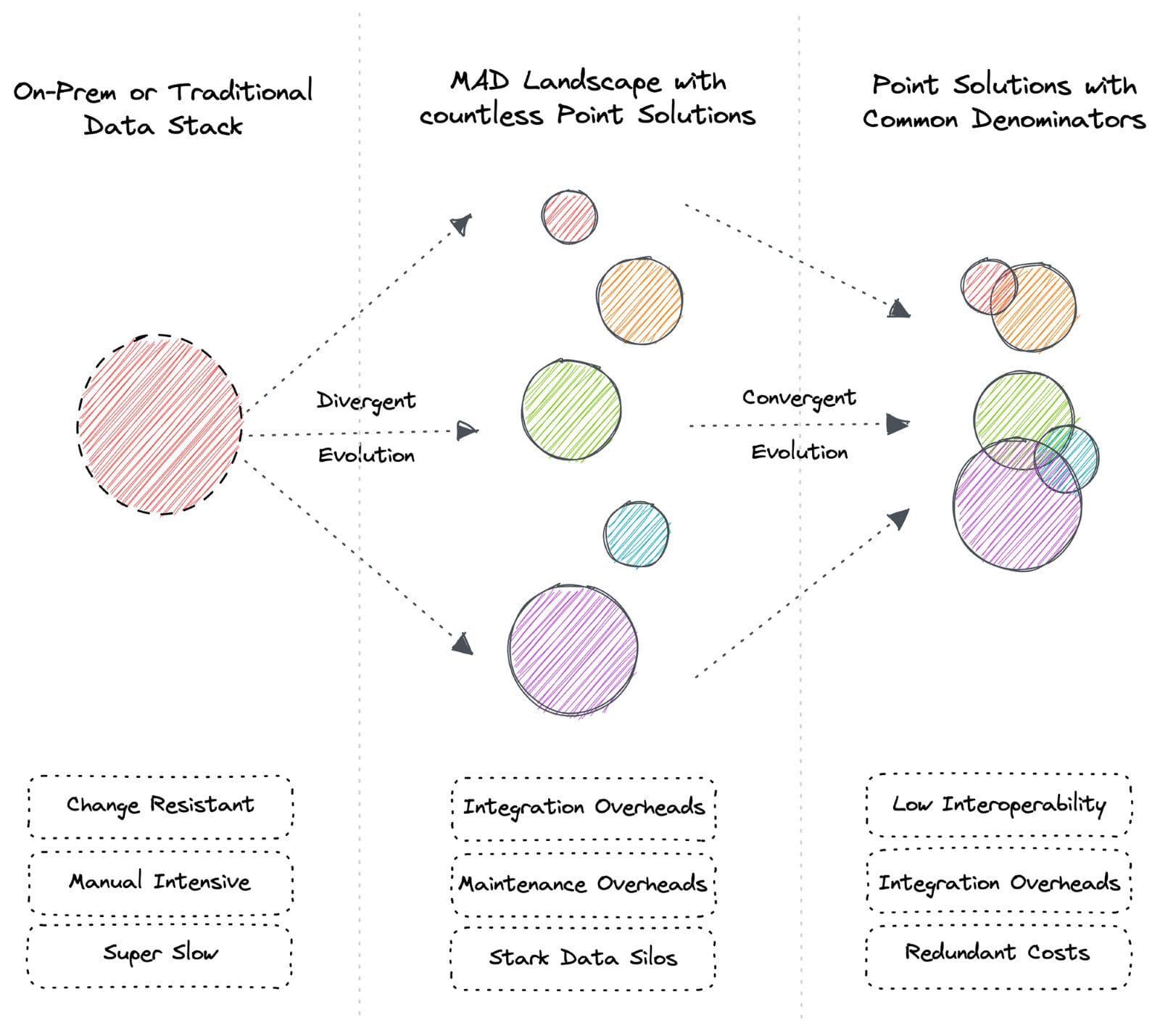
There are two broad patterns of evolution: Divergent and Convergent. These broad patterns apply to the data landscape as well.
Diversity of species on Earth is due to divergent evolution. Similarly, divergent evolution results in a wide range of tools and services in the data industry known as the MAD Landscape today. Convergent evolution creates variants of tools with shared features over time. For instance, both rats and tigers and very different animals, but both have similar features such as whiskers, fur, limbs, and tail.
Convergent evolution results in common denominators across tooling solutions, meaning users pay for redundant capabilities. Divergent evolution results in even higher integration costs and requires experts to understand and maintain each tool's unique philosophy.
Note that common denominators do not mean the point solutions are converging towards a unified solution. Instead, each point is developing solutions that intersect with other solutions by other points based on demand. These common capabilities have separate languages and philosophies and require niche experts.
For example, Immuta and Atlan are data governance and catalog solutions, respectively. However, Immuta is also developing a data catalog, and Atlan is adding governance capabilities. Customers tend to replace secondary capabilities with tools that specialize in them. This results in:
- Time invested in understanding the language and philosophy of each product
- Redundant cost of onboarding two tools with similar offerings
- High resource cost of niche experts; even more challenging since there’s a dearth of good talent
Now that we have a high-level understanding of evolutionary patterns, let’s look at how they manifest in the data domain. We’ll not go back too far for the sake of brevity.
Rewinding a few Years
The problems we have as a data industry today were starkly different from those 5-6 years ago. The primary challenge that organizations faced during that time was the massive transition from on-prem systems to the cloud. On-prem big data ecosystems and SQL warehouses (or the Traditional Data Stack aka TDS) were not only difficult to maintain with an extremely low uptime but also extremely slow when it came to the length of the data-to-insights journey. In short, scale and efficiency were far out of reach, especially due to the following barriers:
Army of Data Engineers
Any number of data engineers was not enough to maintain in-house systems. Everything from the warehouse and ETL to dashboards and BI workflows had to be engineered in-house, leading to most of the organisation’s resources being spent on building and maintenance instead of revenue-generating activities.
Pipeline Overwhelm
The data pipelines were complicated and interconnected, with many of them created to address new business needs. Sometimes, a new pipeline was necessary to answer a single question or to create a vast number of data warehouse tables from a smaller number of source tables. This complexity could be overwhelming and difficult to manage.
Zero Fault Tolerance
The data was neither safe nor trustworthy without any backup, recovery, or RCA. Data quality and governance were afterthoughts and sometimes even beyond the job description of engineers who toiled beneath the weight of plumbing activities.
Cost of Data Movement
Large data migration among legacy systems was another red flag and ate up huge resources and time. Moreover, it ended up in corrupted data and format issues, which took another bunch of months to solve or were dumped.
Change Resistant
The pipelines in the on-prem systems were highly fragile and, thus, resistant to frequent changes or any change at all, becoming a disaster for dynamic and change-prone data operations and making experiments costly.
Gruelling Pace
Months and years went behind deploying new pipelines to answer generic business questions. Dynamic business requests were out of the question. Not to mention the loss of active business during highly frequent downtimes.
Skill Deficit
High debt or cruft led to resistance in project handoffs due to critical dependencies. The dearth of the right skills in the market didn’t help the case and often led to months of duplicated tracks for critical pipelines.
Solutions at the Time and the Problems as a Result of the Solutions
The Emergence of Cloud and the Obligation to Become Cloud-Native
A decade ago, data was not seen as an asset as much as it is today. Especially since organisations did not have enough of it to leverage as an asset and also because they had to deal with countless issues to generate even one working dashboard. But over time, as processes and organisations became more digital and data-friendly, there was a sudden exponential growth in data generation and capture.
Organisations realised they could improve their processes by understanding historical patterns that were noticeable in volumes larger than their capacity. To address the persistent issues of TDS and empower data applications, multiple point solutions popped up and integrated into a central data lake. We called this combination the Modern Data Stack (MDS). It was undeniably an almost-perfect solution for the problems in the data industry at that point in time.
➡️ Transition to the Modern Data Stack (MDS)
MDS addressed some persistent problems in the data landscape of the time. Its biggest achievement has perhaps been the revolutionary shift to the cloud, which made data not just more accessible but also recoverable. Solutions such as Snowflake, Databricks, and Redshift helped large organisations migrate data to the cloud, pumping up reliability and fault tolerance.
Data leaders who were pro-TDS for various reasons, including budget constraints, felt obligated to move to the cloud and remain competitive after seeing successful transitions in other organizations. This required convincing the CFO to prioritise and invest in the transition, which was accomplished by promising value in the near future.
But becoming cloud-native did not just end in migrating to the cloud, which in itself was a hefty cost. Becoming truly cloud-native also meant integrating a pool of solutions to operationalise the data in the cloud. The plan seemed good, but the MDS ended up dumping all data into a central lake, resulting in unmanageable data swamps across industries.
💰 Investments in Phantom Promises
- Cost of migrating huge data assets to the cloud
- Cost of keeping the cloud up and running
- Cost of individual licences for point solutions required to operationalise the cloud
- Cost of common or redundant denominators across point solutions
- Cost of cognitive load and niche expertise to understand varying philosophies of every tool
- Cost of continuous integration whenever a new tool joins the ecosystem
- Cost of continuous maintenance of integrations and consequently flooding pipelines
- Cost of setting up data design infrastructures to operationalise the point solutions
- Cost of dedicated platform teams to keep the infrastructure up and running
- Cost of storing, moving, and computation for 100% of the data in data swamps
- Cost of isolated governance for every point of exposure or integration point
- Cost of frequent data risks due to multiple points of exposure
- Cost of de-complexing dependencies during frequent project handoffs
As you can guess, the list is quite far from exhaustive.
🔄 The Vicious Cycle of Data ROI
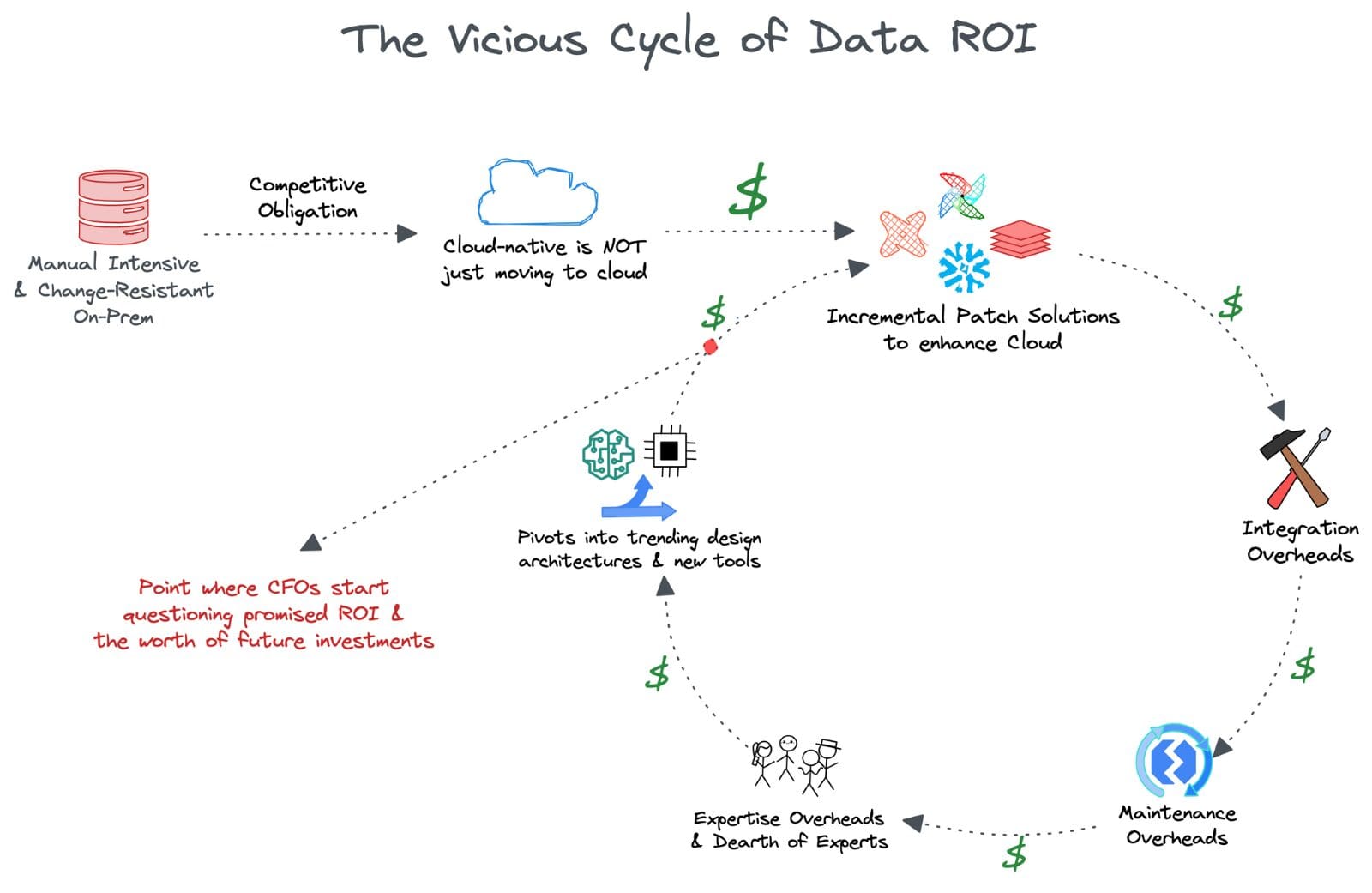
Data leaders, including CDOs and CTOs, soon felt the burden of unrealised promises on investments which were at the scale of millions of dollars. Incremental patch solutions created as many problems as they solved, and data teams were back to the fundamental problem of being unable to use the rich data they owned.
The absence of futureproofing was a serious risk for leaders, with their tenure in organizations cut to less than 24 months. To ensure CFOs see returns, they latched onto trending data design architectures and new tooling innovations that unfurled new promises.
At this point, the office of the CFO inevitably started questioning the credibility of the promised results. More dangerously, they started questioning the worth of investing in data-centric verticals themselves. Wouldn’t millions spent on other operations have yielded a much better impact within five years?
If we look a little deeper and come closer to the actual solutions we discussed above, it will throw more light on how data investments have rusted over the years, especially due to hidden and unexpected costs.
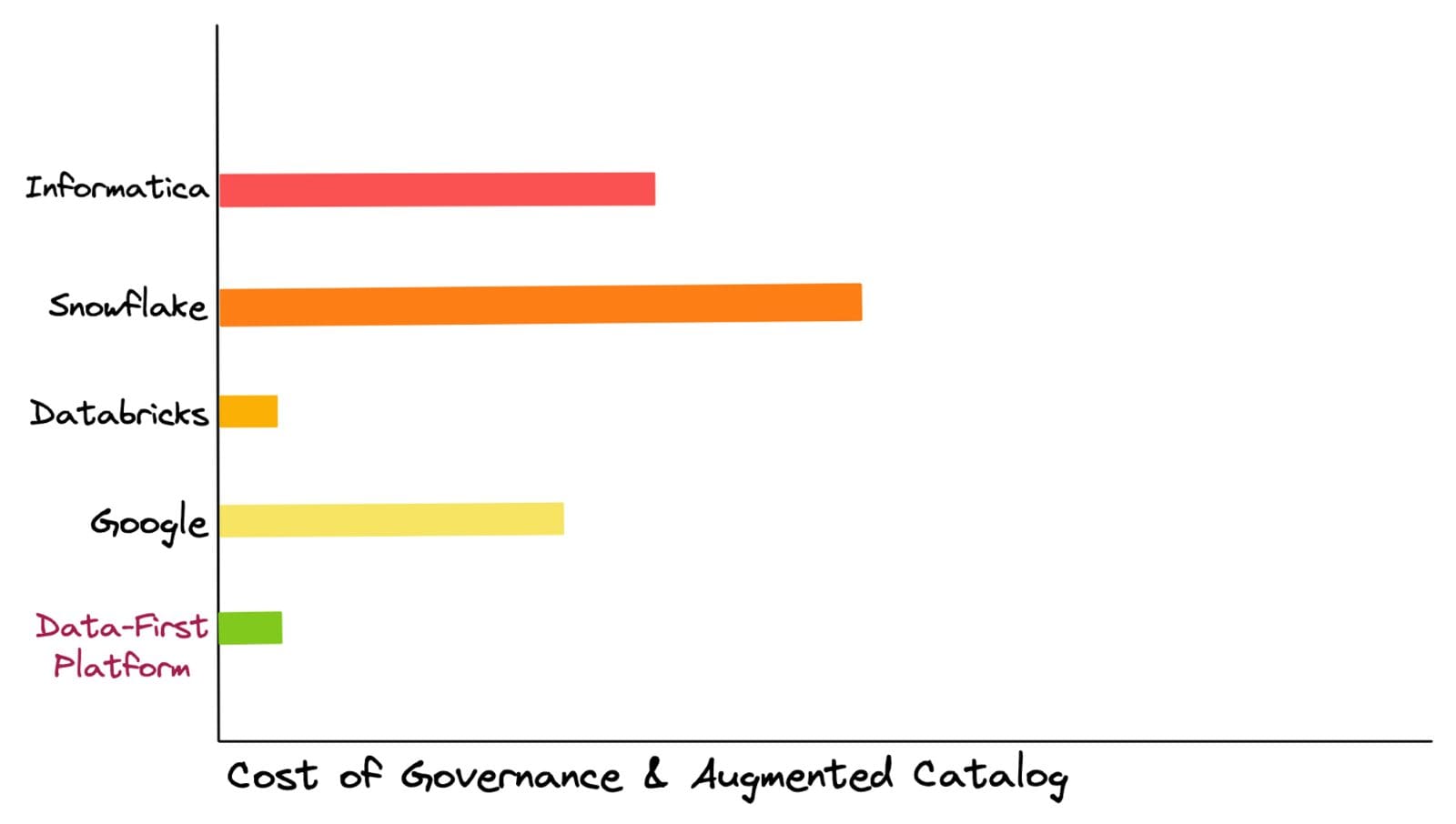
The estimation of TCO is done based on the cost of niche experts, migration, setup, computation for managing a fixed workload, storage, licensing fees, and cumulative cost of point solutions like governance, cataloguing & BI tools. Based on customers' experiences with these vendors, we have added checkered bars at the top as, more often than not, unexpected cost jumps are incurred while using these platforms.
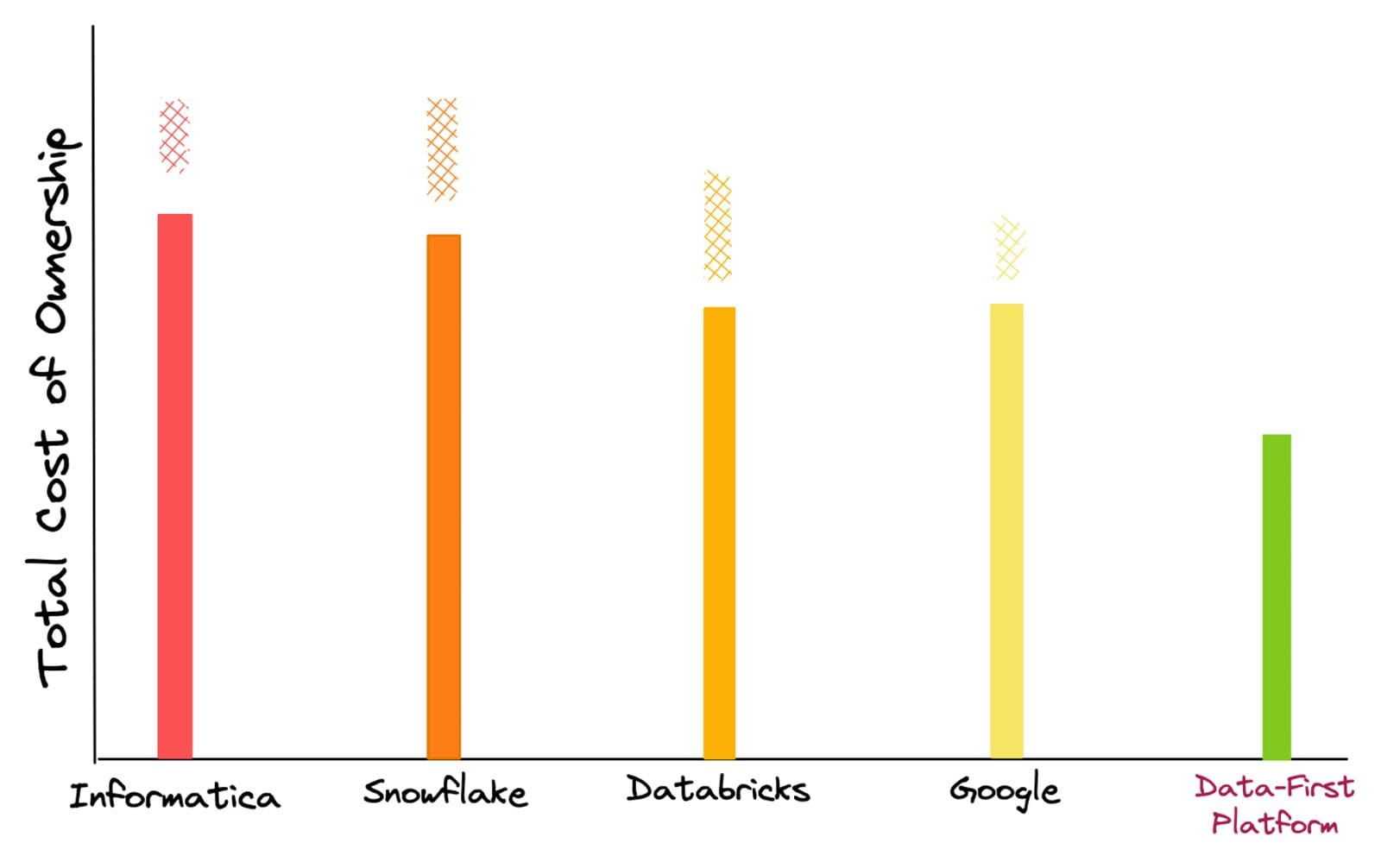
Due to the versatile nature of these costs, which could be as varied as an increase in workload or background queries to the pricing model itself, they can be best classified as ‘enigmatic costs.’ On the other hand, with a data-first approach that abstracts tooling complexities, there are no unexpected jumps in TCO. There is complete control over Compute provisioned for every Workload & Storage used.
💣 Heavy proliferation of tooling made every stack maintenance-first and data-last.
With abundant tooling, as demonstrated by the MAD Landscape or MDS, it is becoming increasingly difficult for organisations to focus on solution development that actually brings in business results due to consistent attention drawn by maintenance tickets.
Poor data engineers are stuck in a maintenance-first, integration-second, and data-last economy. This involves countless hours spent on solving infrastructure drawbacks and maintaining data pipelines. And the infrastructure required to host and integrate multiple tooling is no less painful.
Data engineers are overwhelmed with a vast number of config files, frequent configuration drifts, environment-specific customisations for each file, and countless dependency overheads. In short, data engineers are spending sleepless nights just to ensure the data infra matches the uptime SLOs.
The tooling overwhelm is not just costly in terms of time and effort, but integration and maintenance overheads directly impact the ROI of the engineering teams in terms of literal cost while not enabling any direct improvement for business-driving data applications.
Here’s a representation of enterprise data movement through conventional ETL & ELT methods. It includes the cost of integrating both batch & streaming data sources and the orchestration of data workflows.
The increment in cost over the years is based on the assumption that, with time, the enterprise will increase the platform's usage in terms of the number of source systems integrated and subsequent data processing performed.
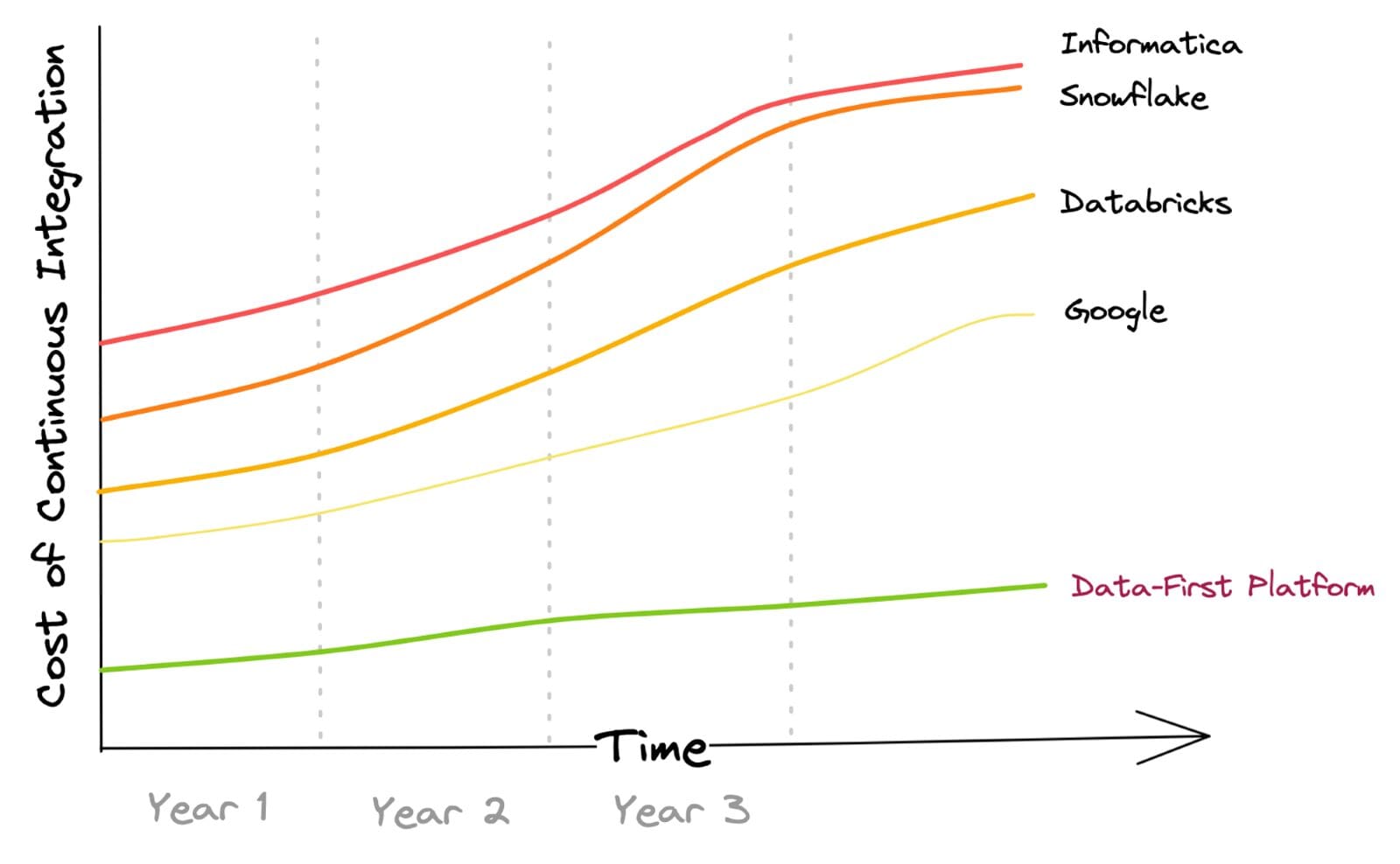
This has been found to be true for most customers across the vendors. In a Data-First approach, the data integration cost is nil to minimal due to its overarching belief in Intelligent Data Movement and abstracted integration management that allows data processing with minimal data movement.
🚧 Organisations are obligated to submit to the philosophy of the tools.
Managing a bundle of different solutions is not the end of it. Organisations are bound to follow these individual tools' pre-defined directions and philosophies. For example, if a Governance tool is onboarded, the data developer learns how to operate the tool, learns the specific ways it talks to other tools, and re-arranges the other tools to match the specifications of the new component.
Every tool has a say in the design architecture as a consequence of its own philosophy, making interoperability much more complex and selective. The lack of flexibility is also a reason behind the high cost of pivoting to new and innovative infrastructure designs, such as meshes and fabrics, that could potentially pump up the promised ROI.
An abundance of tooling with unique philosophies also requires abundant expertise. In practical terms, hiring, training, maintaining, and collaborating with so many data engineers is not possible. More so with the dearth of skilled and experienced professionals in the field.
🧩 Inability to Capture and Operationalise Atomic Insights
Rigid infrastructure, as a result of abundant tooling and integrations, meant low flexibility to tap into and channel atomic data bytes to the right customer-facing endpoints at the right moment. The lack of atomicity is also a result of low interoperability and isolated subsystems that do not have well-established routes to talk to each other.
A good example would be each point tool maintaining its separate metadata engine to operationalise metadata. The metadata engines have separate languages and transmission channels and are hardly able to communicate with each other unless specifically engineered to do so. These newly engineered channels also add to the maintenance tab. Usage data is lost in translation, and parallel verticals are not able to leverage the insights drawn from each other.
Moreover, data operations in the MDS are often developed, committed, and deployed in batches due to the inability to enforce software-like practices across the chaotic spread of MDS. Practically, DataOps is not feasible unless data, the only non-deterministic component of the data stack, is not plugged into a unified tier that could enforce atomic commits, vertical testing along the line of change, and CI/CD principles to eliminate not just data silos but also data code silos.
The Solution that Emerged to Combat the Consequent Problems of MDS
The transition from Traditional Data Stack to Modern Data Stack and then finally to the Data-First Stack (DFS) was largely unavoidable. The requirement for DFS was felt largely due to the overwhelming build-up of cruft (tech debt) within the bounds of data engineering. DFS came up with a unification approach or an umbrella solution that targeted the weak fragments of TDS and MDS as a whole instead of proponing their patchwork philosophy.
DFS brought self-serve capabilities to business teams. They could bring their own compute instead of fighting for IT resources (which is severely limiting business teams’ access to data in many enterprises). Sharing data with partners and monetising it in a compliant manner became easier with DFS. Instead of grinding to integrate hundreds of scattered solutions, users could put data first and focus on the core objectives: Building Data Applications that directly uplift business outcomes.
Reducing resource costs is one of the priorities for organisations in the current market, which is nearly impossible since compliance costs are very high when it comes to governing and cataloguing a scattered landscape of multiple point solutions. The unified infrastructure of DFS reduces that by composing these point capabilities into fundamental building blocks and governing those blocks centrally, instantly improving discoverability and transparency.
DFS’ cataloguing solution is comprehensive, as its Data Discoverability & Observability features are embedded with native governance and rich semantic knowledge allowing for active metadata management. On top of it, it enables complete access control over all the applications & services of the data infrastructure.
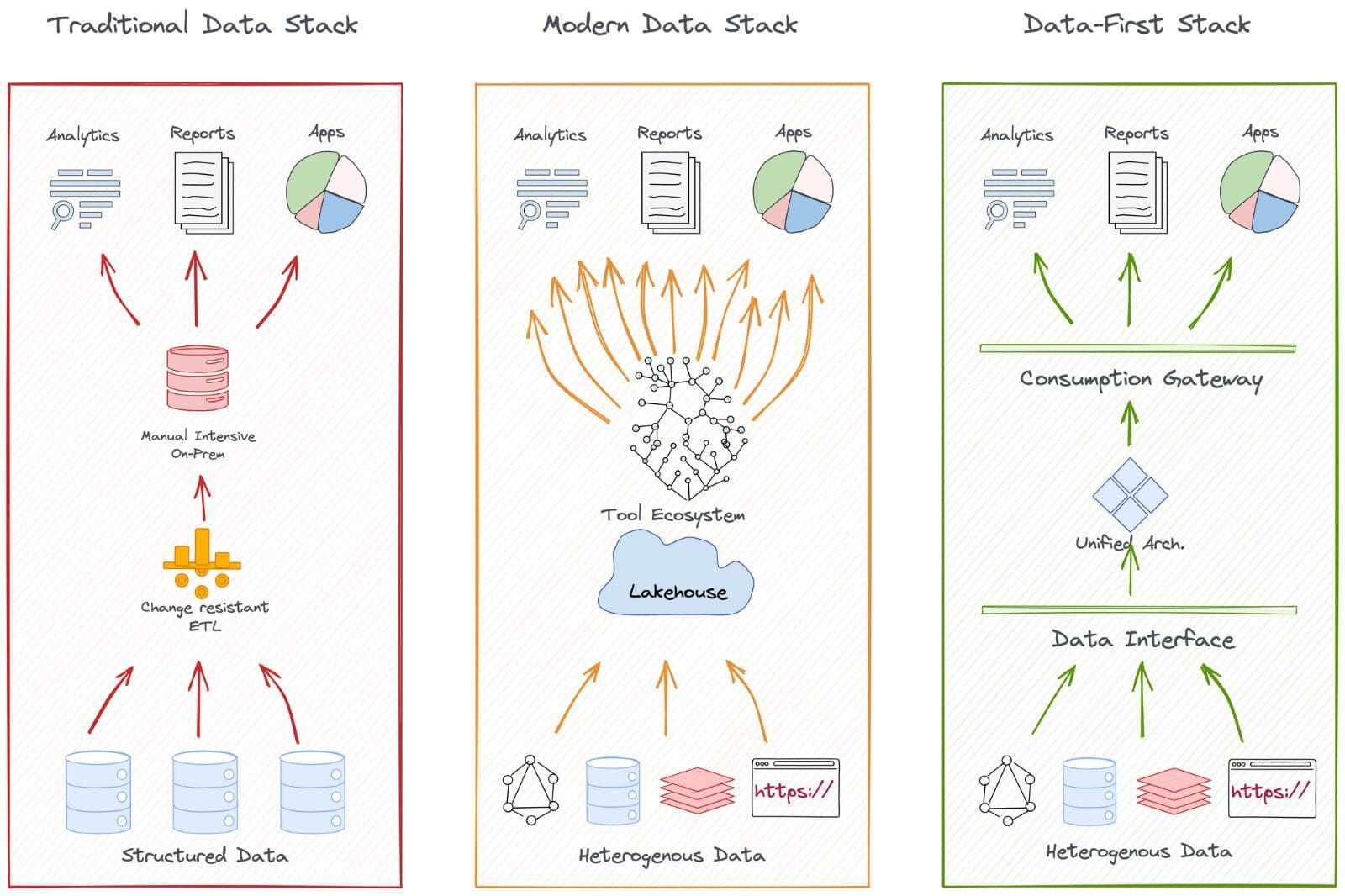
The Data-First Stack is essentially an Operating System (OS) which is a program that manages all programs necessary for the end user to have an outcome-driven experience instead of figuring out ‘how’ to run those programs. Most of us have experienced OS on our laptops, phones, and, in fact, on any interface-driven device. We are hooked to these systems because we are abstracted from the pains of booting, maintaining, and running the low-level nuances of day-to-day applications. Instead, we use such applications directly to drive outcomes.
The Data Operating System (DataOS) is, thus, relevant to both data-savvy and data-naive organizations. In summary, it enables a self-serve data infrastructure by abstracting users from the procedural complexities of applications and declaratively serves the outcomes.
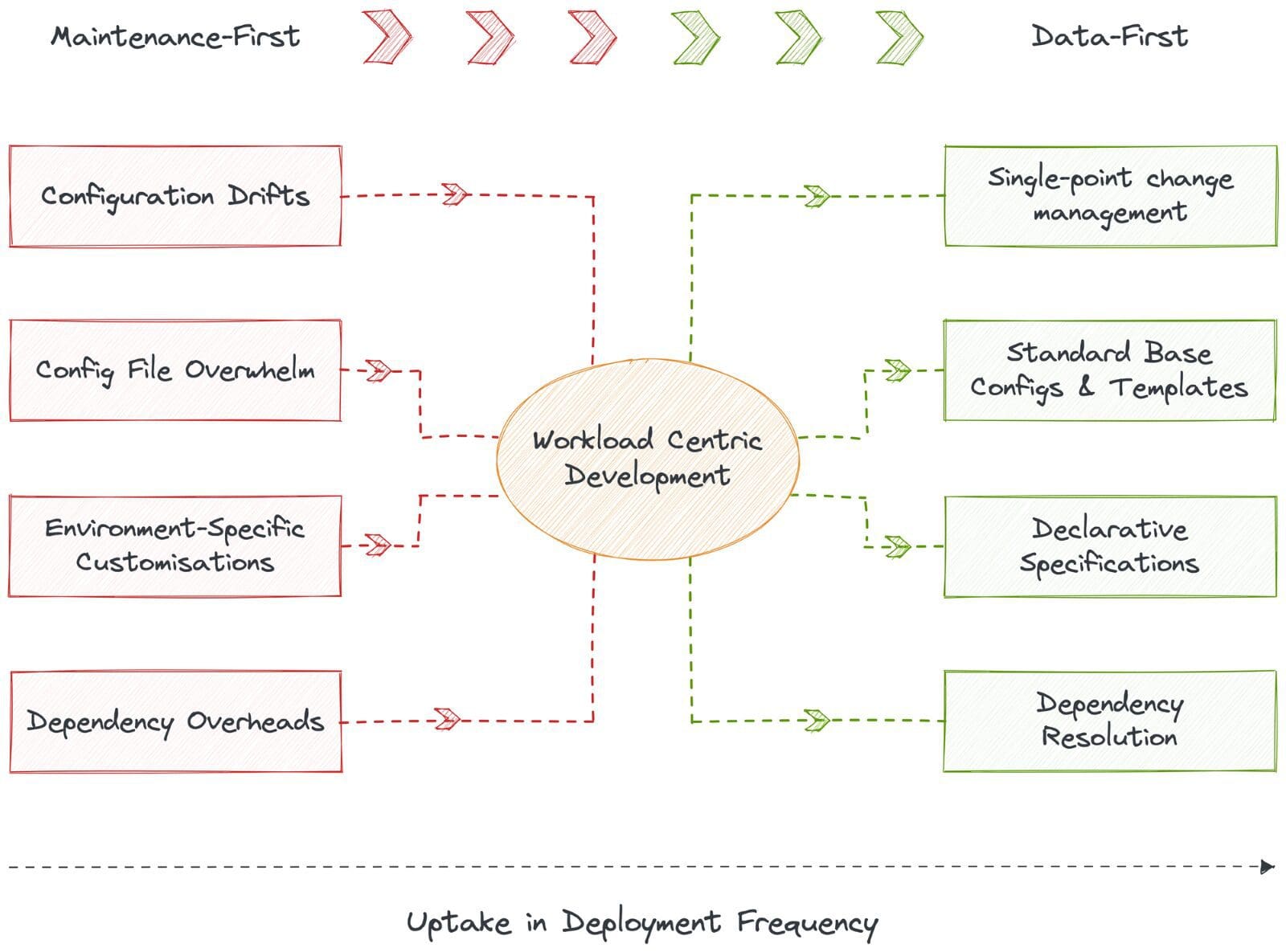
🥇 Transition from Maintenance-First to Data-First
The Data Operating System (DataOS) is the data stack that puts data first and understands organisations have to be users of data, not builders of data infrastructure. DataOS abstracts all the nuances of low-level data management, which otherwise suck out most of the data developer’s active hours.
A declaratively managed system drastically eliminates the scope of fragility and surfaces RCA lenses on demand, consequently optimising resources and ROI. This enables engineering talent to dedicate their time and resources to data and building data applications that directly impact the business.
Data developers can quickly deploy workloads by eliminating configuration drifts and vast number of config files through standard base configurations that do not require environment-specific variables. The system auto-generates manifest files for apps, enabling CRUD ops, execution, and meta storage on top. In short, DataOS provides workload-centric development where data developers declare workload requirements, and DataOS provides resources and resolves the dependencies. The impact is instantly realised with a visible increase in deployment frequency.
💠 Convergence towards a Unified Architecture
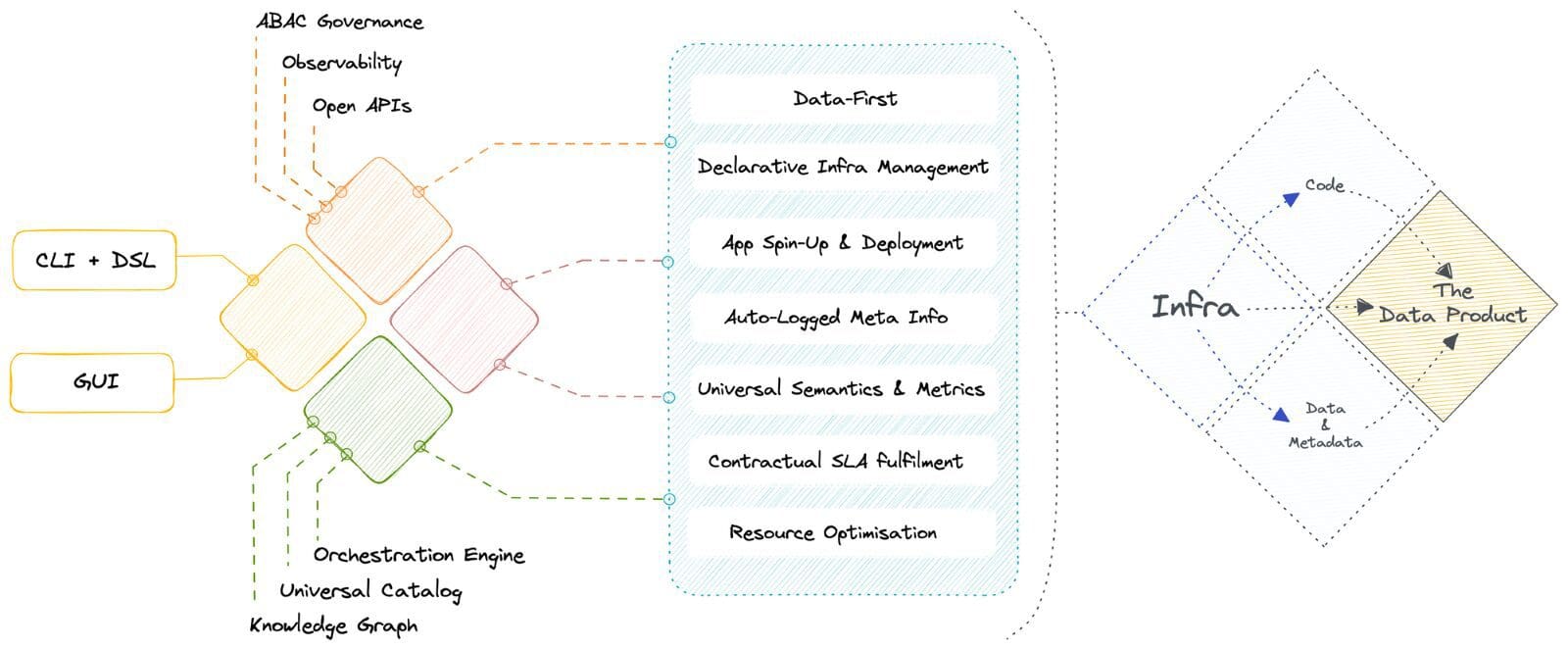
🧱 Transition from patchwork solutions to primitive building blocks
Becoming data-first within weeks is possible through the high internal quality of the composable Data Operating System architecture: Unification through Modularisation. Modularisation is possible through a finite set of primitives that have been uniquely identified as essential to the data stack in its most fundamental form. These primitives can be specifically arranged to build higher-order components and applications.
They can be treated as artefacts that could be source-controlled and managed using a version control system. Every Primitive can be considered an abstraction that allows you to enumerate specific goals and outcomes in a declarative manner instead of the arduous process of defining ‘how to reach those outcomes.’
🦾 Unifying pre-existing tooling for declarative management
Being artefact-first with open standards, DataOS is used as an architectural layer on top of any existing data infrastructure. It enables it to interact with heterogenous components native and external to DataOS. Thus, organizations can integrate their existing data infrastructure with new and innovative technologies without completely overhauling their existing systems.
It’s a complete self-service interface for developers to declaratively manage resources through APIs and CLI. Business users attain self-service through intuitive GUIs to directly integrate business logic into data models. The GUI interface also allows developers to visualise resource allocation and streamline resource management. This saves significant time and enhances productivity for developers, who can easily manage resources without extensive technical knowledge.
☀️ Central governance, orchestration, and metadata management
DataOS operates on a dual-plane conceptual architecture where the control is forked between one central plane for core global components and one or more data planes for localised operations. The Control plane helps admins govern the data ecosystem through centralised management and control of vertical components.
Users can centrally manage policy-based and purpose-driven access control of various touchpoints in cloud-native environments, with precedence to local ownership, orchestrate data workloads, compute cluster life-cycle management, and version control of DataOS resources, and manage metadata of different types of data assets.
⚛️ Atomic insights for experiential use cases
The industry is rapidly shifting from transactional to experiential use cases. Big bang insights drawn from large blocks of data over long periodic batches are now the secondary requirement. Atomic or byte-sized insights inferred from point data in near-real-time is the new ball game, and customers are more than willing to pay for it.
The common underlying layer of primitives ensures that data is visible across all touchpoints in the unified architecture and can be materialised into any channel through semantic abstractions as and when the business use case demands.
Animesh Kumar is the Chief Technology Officer & Co-Founder @Modern, and a co-creator of the Data Operating System Infrastructure Specification. During his 30+ years in the data engineering space, he has architected engineering solutions for a wide range of A-Players, including NFL, GAP, Verizon, Rediff, Reliance, SGWS, Gensler, TOI, and more.
Srujan is the CEO & Co-Founder @Modern. Over the course of 30 years in data and engineering Srujan has been actively engaged in the community as an entrepreneur, product executive and a business leader with multiple award-winning product launches at organisations like Motorola, TeleNav, Doot and Personagraph.
Travis Thompson (Co-Author): Travis is the Chief Architect of the Data Operating System Infrastructure Specification. Over the course of 30 years in all things data and engineering, he has designed state-of-the-art architectures and solutions for top organisations, the likes of GAP, Iterative, MuleSoft, HP, and more.
- Data Engineering Landscape in the AI-Driven World
- From Oracle to Databases for AI: The Evolution of Data Storage
- The Evolution From Artificial Intelligence to Machine Learning to Data…
- The First ML Value Chain Landscape
- How to Manage Your Complex IT Landscape with AIOps
- The Future of Work: How AI is Changing the Job Landscape
{kind=link}