
Databricks has recently made an exciting announcement, introducing the English SDK for Apache Spark. This groundbreaking tool aims to enhance the overall Spark experience for users by using English as the driver of the software, instead of using it as a copilot.
Still in early stages of development, the SDK is still fairly simple to use and can simplify complex tasks by reducing the amount of coding required.
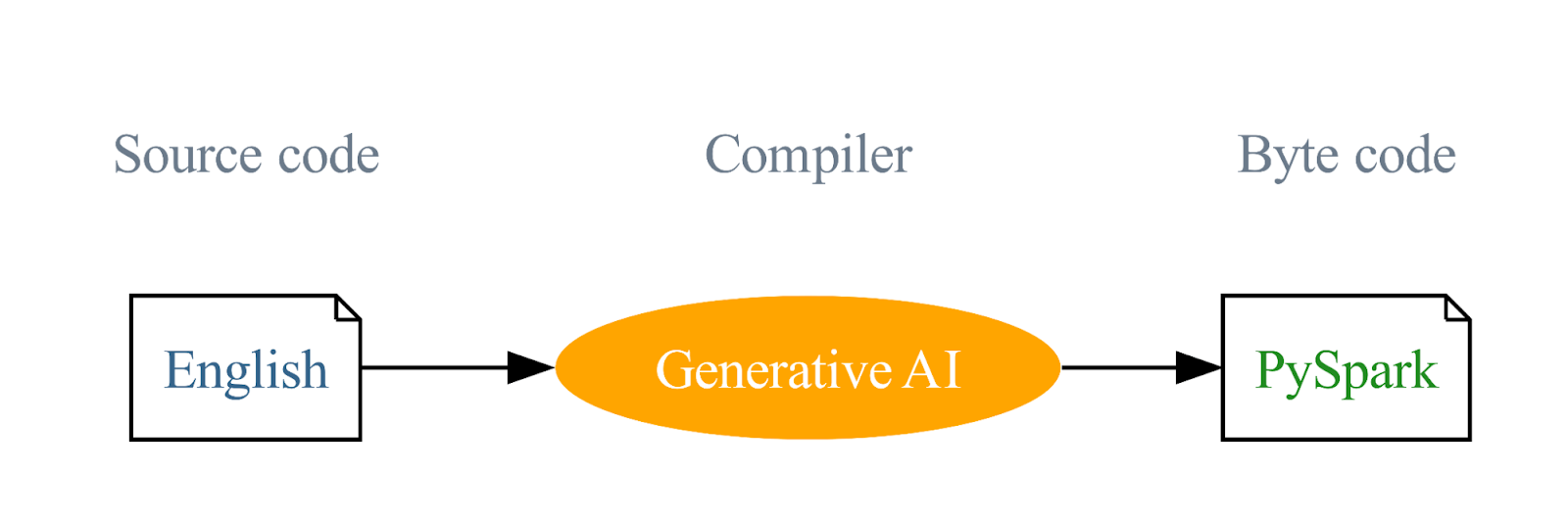
The blog tells how the journey of the company to build this SDK started out using English as a programming language, a trend that has been recently developing with the introduction of prompt engineering courses on ChatGPT. The company integrated generative AI with English instructions into PySpark and SQL code.
Read: Prompt Engineers Then, AI Engineers Now
The English SDK introduces several key features that streamline the Spark development process:
- Data Ingestion: With the SDK, you can initiate a web search using your specified description. Leveraging the power of the LLM (Language Model), it selects the most suitable result and seamlessly incorporates the retrieved web data into Spark. This entire process is accomplished in a single step, simplifying data ingestion.
- DataFrame Operations: The SDK offers a range of functionalities for working with DataFrames. It enables transformations, plotting, and explanations based on your English description. These features greatly enhance code readability and efficiency, making DataFrame operations more intuitive and straightforward.
- User-Defined Functions (UDFs): Creating UDFs becomes a streamlined process with the SDK. By utilising a simple decorator, you can provide a docstring, and the AI takes care of code completion. This feature simplifies UDF creation, allowing you to focus on defining the function while the AI handles the rest.
- Caching: The SDK incorporates caching mechanisms that improve execution speed, ensure reproducible results, and optimise cost savings. By leveraging caching, the SDK enhances the overall performance of your Spark applications.
Apache Spark, a widely recognised platform in the field of large-scale data analytics, has gained immense popularity worldwide, with billions of annual downloads from 208 countries and regions. By leveraging Generative AI technology, the English SDK from Adobe Spark aims to further extend the reach of this dynamic community, making Spark more accessible and user-friendly than ever before.
Databricks recently also announced an acquisition worth $1.3 billion of MosaicML, an OpenAI competitor for making generative AI more accessible for organisations.
The post DataBricks Introduces English as a New Programming Language for Apache Spark appeared first on Analytics India Magazine.
{kind=link}