An integral part of ML Engineering is building reliable and scalable procedures for extracting data, transforming it, enriching it and loading it in a specific file store or database. This is one of the components in which the data scientist and the ML engineer collaborate the most. Typically, the data scientist comes up with a rough version of what the data set should look like. Ideally, not on a Jupyter notebook. Then, the ML engineer joins this task to support making the code more readable, efficient and reliable.
ML ETLs can be composed of several sub-ETLs or tasks. And they can be materialized in very different forms. Some common examples:
- Scala-based Spark job reading and processing event log data stored in S3 as Parquet files and scheduled through Airflow on a weekly basis.
- Python process executing a Redshift SQL query through a scheduled AWS Lambda function.
- Complex pandas-heavy processing executed through a Sagemaker Processing Job using EventBridge triggers.
Entities in ETLs
We can identify different entities in these types of ETLs, we have Sources (where the raw data lives), Destinations (where the final data artifact gets stored), Data Processes (how the data gets read, processed and loaded) and Triggers (how the ETLs get initiated).
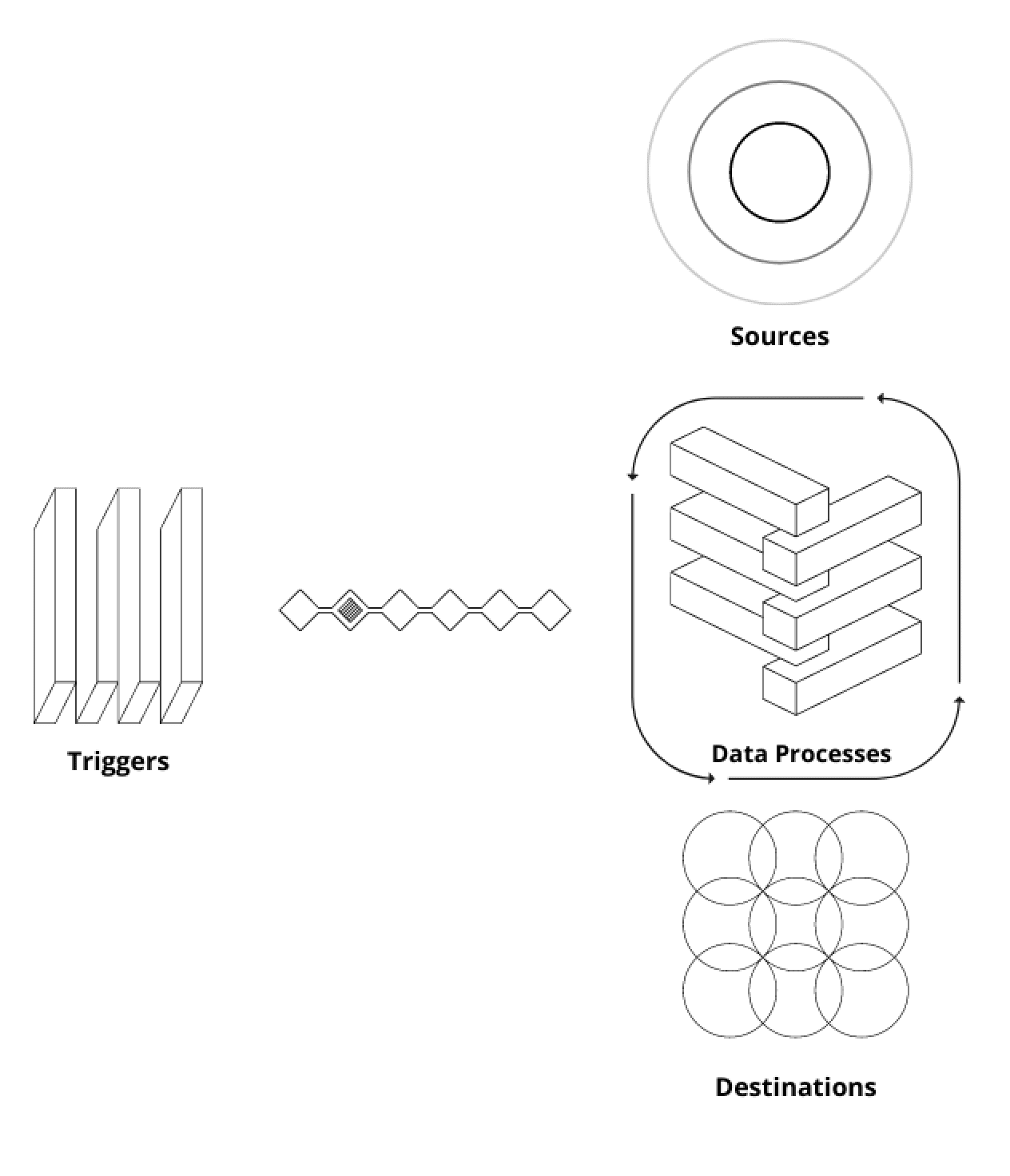
- Under the Sources, we can have stores such as AWS Redshift, AWS S3, Cassandra, Redis or external APIs. Destinations are the same.
- The Data Processes are typically run under ephemeral Docker containers. We could add another level of abstraction using Kubernetes or any other AWS managed service such as AWS ECS or AWS Fargate. Or even SageMaker Pipelines or Processing Jobs.You can run these processes in a cluster by leveraging specific data processing engines such as Spark, Dask, Hive, Redshift SQL engine. Also, you can use simple single-instance processes using Python processes and Pandas for data processing. Apart from that, there are some other interesting frameworks such as Polars, Vaex, Ray or Modin which can be useful to tackle intermediate solutions.
- The most popular Trigger tool is Airflow. Others that can be used are Prefect, Dagster, Argo Workflows or Mage.
 Should I use a Framework?
Should I use a Framework?
A framework is a set of abstractions, conventions and out-of-the-box utilities that can be used to create a more uniform codebase when applied to concrete problems. Frameworks are very convenient for ETLs. As we’ve previously described, there are very generic entities that could potentially be abstracted or encapsulated to generate comprehensive workflows.
The progression that I would take to build an internal data processing framework is the following:
- Start by building a library of connectors to the different Sources and Destinations. Implement them as you need them throughout the different projects you work on. That’s the best way to avoid YAGNI.
- Create simple and automated development workflow that allows you to iterate quickly the codebase. For example, configure CI/CD workflows to automatically test, lint and publish your package.
- Create utilities such as reading SQL scripts, spinning up Spark sessions, dates formatting functions, metadata generators, logging utilities, functions for fetching credentials and connection parameters and alerting utilities among others.
- Choose between building an internal framework for writing workflows or use an existing one. The complexity scope is wide when considering this in-house development. You can start with some simple conventions when building workflows and end up building some DAG-based library with generic classes such as Luigi or Metaflow. These are popular frameworks that you can use.
Building a “Utils” Libraries
This is a critical and central part of your data codebase. All your processes will use this library to move data around from one source into another destination. A solid and well-though initial software design is key.
But why would we want to do this? Well, the main reasons are:
- Reusability: Using the same software components in different software projects allows for higher productivity. The piece of software has to be developed only once. Then, it can be integrated into other software projects. But this idea is not new. We can find references back in 1968 on a conference whose aim was to solve the so-called software crisis.
- Encapsulation: Not all the internals of the different connectors used through the library need to be shown to end-users. Hence, by providing an understandable interface, that’s enough. For example, if we had a connector to a database, we wouldn’t like that the connection string got exposed as a public attribute of the connector class. By using a library we can ensure that secure access to data sources is guaranteed. Review this bit
- Higher-quality codebase: We have to develop tests only once. Hence, developers can rely on the library because it contains a test suite (Ideally, with a very high test coverage). When debugging for errors or issues we can ignore, at least at first pass, that the issue is within the library if we’re confident on our test suite.
- Standardisation / “Opinionation”: Having a library of connectors determines, in certain way, the way you develop ETLs. That is good, because ETLs in the organization will have the same ways of extracting or writing data into the different data sources. Standardisation leads to better communication, more productivity and better forecasting and planning.
When building this type of library, teams commit to maintain it over time and assume the risk of having to implement complex refactors when needed. Some causes of having to do these refactors might be:
- The organisation migrates to a different public cloud.
- The data warehouse engine changes.
- New dependency version breaks interfaces.
- More security permission checks need to be put in place.
- A new team comes in with different opinions about the library design.a
Interface classes
If you want to make your ETLs agnostic of the Sources or Destinations, it is a good decision to create interface classes for base entities. Interfaces serve as template definitions.
For example, you can have abstract classes for defining required methods and attributes of a DatabaseConnector. Let’s show a simplified example of how this class could look like:
from abc import ABC class DatabaseConnector(ABC): def __init__(self, connection_string: str): self.connection_string = connection_string @abc.abstractmethod def connect(self): pass @abc.abstractmethod def execute(self, sql: str): passOther developers would subclass from the DatabaseConnector and create new concrete implementations. For instance, a MySqlConnector or CassandraDbConnector could be implemented in this fashion. This would help end-users to quickly understand how to use any connector subclassed from the DatabaseConnector as all of them will have the same interface (same methods).
mysql = MySqlConnector(connection_string) mysql.connect() mysql.execute("SELECT * FROM public.table") cassandra = CassandraDbConnector(connection_string) cassandra.connect() cassandra.execute("SELECT * FROM public.table")Simples interfaces with well-named methods are very powerful and allow for better productivity. So my advice is to spend quality time thinking about it.
The right documentation
Documentation not only refers to docstrings and inline comments in the code. It also refers to the surrounding explanations you give about the library. Writing a bold statement about what’s the end goal of the package and a sharp explanation of the requirements and guidelines to contribute is essential.
For example:
"This utils library will be used across all the ML data pipelines and feature engineering jobs to provide simple and reliable connectors to the different systems in the organization".Or
"This library contains a set of feature engineering methods, transformations and algorithms that can be used out-of-the-box with a simple interface that can be chained in a scikit-learn-type of pipeline".Having a clear mission of the library paves the way for a correct interpretation from contributors. This is why open source libraries (E.g: pandas, scikit-learn, etc) have gained such a great popularity these last years. Contributors have embraced the goal of the library and they are committed to follow the outlined standards. We should be doing something pretty similar at organizations.
Right after the mission is stated, we should develop the foundational software architecture. How do we want our interfaces to look like? Should we cover functionality through more flexibility in the interface methods (e.g: more arguments that lead to different behaviours) or more granular methods (e.g: each method has a very specific function)?
After having that, the styleguide. Outline the preferred modules hierarchy, the documentation depth required, how to publish PRs, coverage requirements, etc.
With respect to documentation in the code, docstrings need to be sufficiently descriptive of the function behaviour but we shouldn’t fall into just copying the function name. Sometimes, the function name is sufficiently expressive that a docstring explaining its behaviour is just redundant. Be concise and accurate. Let’s provide a dumb example:
❌No!
class NeptuneDbConnector: ... def close(): """This function checks if the connection to the database is opened. If it is, it closes it and if it doesn’t, it does nothing. """ ✅Yes!
class NeptuneDbConnector: ... def close(): """Closes connection to the database."""Coming to the topic of inline comments, I always like to use them to explain certain things that might seem weird or irregular. Also, if I have to use a complex logic or fancy syntax, it is always better if you write a clear explanation on top of that snippet.
# Getting the maximum integer of the list l = [23, 49, 6, 32] reduce((lambda x, y: x if x > y else y), l)Apart from that, you can also include links to Github issues or Stackoverflow answers. This is really useful, specially if you had to code a weird logic just to overcome a known dependency issue. It is also really convenient when you had to implement an optimisation trick that you got from Stackoverflow.
These two, interface classes and clear documentation are, in my opinion, the best ways to keep a shared library alive for a long time. It will resist lazy and conservative new developers and also fully-energized, radical and highly opinionated ones. Changes, improvements or revolutionary refactors will be smooth.
Applying Software Design Patterns to ETLs
From a code perspective, ETLs should have 3 clearly differentiated high-level functions. Each one related to one of the following steps: Extract, Transform, Load. This is one of the simplest requirements for ETL code.
def extract(source: str) -> pd.DataFrame: ... def transform(data: pd.DataFrame) -> pd.DataFrame: ... def load(transformed_data: pd.DataFrame): ...Obviously, it is not mandatory to name these functions like this, but it will give you a plus on readability as they are widely accepted terms.
DRY (Don’t Repeat Yourself)
This is one of the great design patterns which justifies a connectors library. You write it once and reuse it across diferent steps or projects.
Functional Programming
This is a programming style that aims at making functions “pure” or without side-effects. Inputs must be immutable and outputs are always the same given those inputs. These functions are easier to test and debug in isolation. Therefore, provides a better degree of reproducibility to data pipelines.
With functional programming applied to ETLs, we should be able to provide idempotency. This means that every time we run (or re-run) the pipeline, it should return the same outputs. With this characteristic, we are able to confidently operate ETLs and be sure that double runs won’t generate duplicate data. How many times you had to create a weird SQL query to remove inserted rows from a wrong ETL run? Ensuring idempotency helps avoiding those situations. Maxime Beauchemin, creator of Apache Airflow and Superset, is one known advocate for Functional Data Engineering.
SOLID
We will use references to classes definitions, but this section can also be applied to first-class functions. We will be using heavy object-oriented programming to explain these concepts, but it doesn’t mean this is the best way of developing an ETL. There’s not a specific consensus and each company does it on its own way.
Regarding the Single Responsibility Principle, you must create entities that have only one reason to change. For example, segregating responsibilities among two objects such as a SalesAggregator and a SalesDataCleaner class. The latter is susceptible to contain specific business rules to “clean” data from sales, and the former is focused on extracting sales from disparate systems. Both classes code can change because of different reasons.
For the Open-Close Principle, entities should be expandable to add new features but not opened to be modified. Imagine that the SalesAggregator received as components a StoresSalesCollector which is used to extract sales from physical stores. If the company started selling online and we wanted to get that data, we would state that SalesCollector is open for extension if it can receive also another OnlineSalesCollector with a compatible interface.
from abc import ABC, abstractmethod class BaseCollector(ABC): @abstractmethod def extract_sales() -> List[Sale]: pass class SalesAggregator: def __init__(self, collectors: List[BaseCollector]): self.collectors = collectors def get_sales(self) -> List[Sale]: sales = [] for collector in self.collectors: sales.extend(collector.extract_sales()) return sales class StoreSalesCollector: def extract_sales() -> List[Sale]: # Extract sales data from physical stores class OnlineSalesCollector: def extract_sales() -> List[Sale]: # Extract online sales data if __name__ == "__main__": sales_aggregator = SalesAggregator( collectors = [ StoreSalesCollector(), OnlineSalesCollector() ] sales = sales_aggregator.get_sales()The Liskov substitution principle, or behavioural subtyping is not so straightforward to apply to ETL design, but it is for the utilities library we mentioned before. This principle tries to set a rule for subtypes. In a given program that uses the supertype, one could potential substitute it with one subtype without altering the behaviour of the program.
from abc import ABC, abstractmethod class DatabaseConnector(ABC): def __init__(self, connection_string: str): self.connection_string = connection_string @abstractmethod def connect(): pass @abstractmethod def execute_(query: str) -> pd.DataFrame: pass class RedshiftConnector(DatabaseConnector): def connect(): # Redshift Connection implementation def execute(query: str) -> pd.DataFrame: # Redshift Connection implementation class BigQueryConnector(DatabaseConnector): def connect(): # BigQuery Connection implementation def execute(query: str) -> pd.DataFrame: # BigQuery Connection implementation class ETLQueryManager: def __init__(self, connector: DatabaseConnector, connection_string: str): self.connector = connector(connection_string=connection_string).connect() def run(self, sql_queries: List[str]): for query in sql_queries: self.connector.execute(query=query)We see in the example below that any of the DatabaseConnector subtypes conform to the Liskov substitution principle as any of its subtypes could be used within the ETLManager class.
Now, let’s talk about the Interface Segregation Principle. It states that clients shouldn’t depend on interfaces they don’t use. This one comes very handy for the DatabaseConnector design. If you’re implementing a DatabaseConnector, don’t overload the interface class with methods that won’t be used in the context of an ETL. For example, you won’t need methods such as grant_permissions, or check_log_errors. Those are related to an administrative usage of the database, which is not the case.
The one but not least, the Dependency Inversion principle. This one says that high-level modules shouldn’t depend on lower-level modules, but instead on abstractions. This behaviour is clearly exemplified with the SalesAggregator above. Notice that its __init__ method doesn’t depend on concrete implementations of either StoreSalesCollector or OnlineSalesCollector. It basically depends on a BaseCollector interface.
How does a great ML ETL look like?
We’ve heavily rely on object-oriented classes in the examples above to show ways in which we can apply SOLID principles to ETL jobs. Nevertheless, there is no general consensus of what’s the best code format and standard to follow when building an ETL. It can take very different forms and it tends to be more a problem of having an internal well-documented opinionated framework, as discussed previously, rather than trying to come up with a global standard across the industry.
Hence, in this section, I will try to focus on explaining some characteristics that make ETL code more legible, secure and reliable.
Command Line Applications
All Data Processes that you can think of are basically command line applications. When developing your ETL in Python, always provide a parametrized CLI interface so that you can execute it from any place (E.g, a Docker container that can run under a Kubernetes cluster). There are a variety of tools for building command-line arguments parsing such as argparse, click, typer, yaspin or docopt. Typer is possibly the most flexible, easy to use an non-invasive to your existing codebase. It was built by the creator of the famous Python web services library FastApi, and its Github starts keep growing. The documentation is great and is becoming more and more industry-standard.
from typer import Typer app = Typer() @app.command() def run_etl( environment: str, start_date: str, end_date: str, threshold: int ): ...To run the above command, you’d only have to do:
python {file_name}.py run-etl --environment dev --start-date 2023/01/01 --end-date 2023/01/31 --threshold 10Process vs Database Engine Compute Trade Off
The typical recommendation when building ETLs on top of a Data Warehouse is to push as much compute processing to the Data Warehouse as possible. That’s all right if you have a data warehouse engine that autoscales based on demand. But that’s not the case for every company, situation or team. Some ML queries can be very long and overload the cluster easily. It’s typical to aggregate data from very disparate tables, lookback for years of data, perform point-in-time clauses, etc. Hence, pushing everything to the cluster is not always the best option. Isolating the compute into the memory of the process instance can be safer in some cases. It is risk-free as you won’t hit the cluster and potentially break or delay business-critical queries. This is an obvious situation for Spark users, as all the compute & data gets distributed across the executors because of the massive scale they need. But if you’re working over Redshift or BigQuery clusters always keep an eye into how much compute you can delegate to them.
Track Outputs
ML ETLs generate different types of output artifacts. Some are Parquet files in HDFS, CSV files in S3, tables in the data warehouse, mapping files, reports, etc. Those files can later be used to train models, enrich data in production, fetch features online and many more options.
This is quite helpful as you can link dataset building jobs with training jobs using the identifier of the artifacts. For example, when using Neptune track_files() method, you can track these kind of files. There’s a very clear example here that you can use.
Implement Automatic Backfilling
Imagine you have a daily ETL that gets last day’s data to compute a feature used to train a model If for any reason your ETL fails to run for a day, the next day it runs you would have lost the previous day data computed.
To resolve this, it’s a good practice to look at what’s the last registered timestamp in the destination table or file. Then, the ETL can be executed for those lagging two days.
Develop Loosely Coupled Components
Code is very susceptible to change, and processes that depend on data even more. Events that build up tables can evolve, columns can change, sizes can increase, etc. When you have ETLs that depend on different sources of information is always good to isolate them in the code. This is because if at any time you have to separate both components as two different tasks (E.g: One needs a bigger instance type to run the processing because the data has grown), it is much easier to do if the code is not spaghetti!
Make Your ETLs Idempotent
It’s typical to run the same process more than once in case there was an issue on the source tables or within the process itself. To avoid generating duplicate data outputs or half-filled tables, ETLs should be idempotent. That is, if you accidentally run the same ETL twice with the same conditions that the first time, the output or side-effects from the first run shouldn’t be affected (ref). You can ensure this is imposed in your ETL by applying the delete-write pattern, the pipeline will first delete the existing data before writing new data.
Keep Your ETLs Code Succinct
I always like to have a clear separation between the actual implementation code from the business/logical layer. When I’m building an ETL, the first layer should be read as a sequence of steps (functions or methods) that clearly state what is happening to the data. Having several layers of abstraction is not bad. It’s very helpful if you have have to maintain the ETL for years.
Always isolate high-level and low-level functions from each other. It is very weird to find something like:
from config import CONVERSION_FACTORS def transform_data(data: pd.DataFrame) -> pd.DataFrame: data = remove_duplicates(data=data) data = encode_categorical_columns(data=data) data["price_dollars"] = data["price_euros"] * CONVERSION_FACTORS["dollar-euro"] data["price_pounds"] = data["price_euros"] * CONVERSION_FACTORS["pound-euro"] return dataIn the example above we are using high-level functions such as the “remove_duplicates” and “encode_categorical_columns” but at the same time we’re explicitly showing an implementation operation to convert the price with a conversion factor. Wouldn’t it be nicer to remove those 2 lines of code and replace them with a “convert_prices” function?
from config import CONVERSION_FACTOR def transform_data(data: pd.DataFrame) -> pd.DataFrame: data = remove_duplicates(data=data) data = encode_categorical_columns(data=data) data = convert_prices(data=data) return dataIn this example, readability wasn’t a problem, but imagine that instead, you embed a 5 lines long groupby operation in the “transform_data” along with the “remove_duplicates” and “encode_categorical_columns”. In both cases, you’re mixing high-level and low-level functions. It is highly recommended to keep a cohesive layered code. Sometimes is inevitable and over-engineered to keep a function or module 100% cohesively layered, but it’s a very beneficial goal to pursue.
Use Pure Functions
Don’t let side-effects or global states complicate your ETLs. Pure functions return the same results if the same arguments are passed.
❌The function below is not pure. You’re passing a dataframe that is joined with another functions that is read from an outside source. This means that the table can change, hence, returning a different dataframe, potentially, each time the function is called with the same arguments.
def transform_data(data: pd.DataFrame) -> pd.DataFrame: reference_data = read_reference_data(table="public.references") data = data.join(reference_data, on="ref_id") return dataTo make this function pure, you would have to do the following:
def transform_data(data: pd.DataFrame, reference_data: pd.DataFrame) -> pd.DataFrame: data = data.join(reference_data, on="ref_id") return dataNow, when passing the same “data” and “reference_data” arguments, the function will yield the same results.
This is a simple example, but we all have witnessed worse situations. Functions that rely on global state variables, methods that change the state of class attributes based on certain conditions, potentially changing the behaviour of other upcoming methods in the ETL, etc.
Maximising the use of pure functions leads to more functional ETLs. As we have already discussed in points above, it comes with great benefits.
Paremetrize As Much As You Can
ETLs change. That’s something that we have to assume. Source table definitions change, business rules change, desired outcomes evolve, experiments are refined, ML models require more sophisticated features, etc.
In order to have some degree of flexibility in our ETLs, we need to thoroughly assess where to put most of the effort to provide parametrised executions of the ETLs. Parametrisation is a characteristic in which, just by changing parameters through a simple interface, we can alter the behaviour of the process. The interface can be a YAML file, a class initialisation method, function arguments or even CLI arguments.
A simple straightforward parametrisation is to define the “environment”, or “stage” of the ETL. Before running the ETL into production, where it can affect downstream processes and systems, it’s good to have a “test”, “integration” or “dev” isolated environments so that we can test our ETLs. That environment might involve different levels of isolation. It can go from the execution infrastructure (dev instances isolated from production instances), object storage, data warehouse, data sources, etc.
That’s an obvious parameter and probably the most important. But we can expand the parametrisation also to business-related arguments. We can parametrise window dates to run the ETL, columns names that can change or be refined, data types, filtering values, etc.
Just The Right Amount Of Logging
This is one of the most underestimated properties of an ETL. Logs are useful to detect production executions anomalies or implicit bugs or explain data sets. It’s always useful to log properties about extracted data. Apart from in-code validations to ensure the different ETL steps run successfully, we can also log:
- References to source tables, APIs or destination paths (E.g: “Getting data from `item_clicks` table”)
- Changes in expected schemas (E.g: “There is a new column in `promotion` table”)
- The number of rows fetched (E.g: “Fetched 145234093 rows from `item_clicks` table”)
- The number of null values in critical columns (E.g: “Found 125 null values in Source column”)
- Simple statistics of data (e.g: mean, standard deviation, etc). (E.g: “CTR mean: 0.13, CTR std: 0.40)
- Unique values for categorical columns (E.g: “Country column includes: ‘Spain’, ‘France’ and ‘Italy’”)
- Number of rows deduplicated (E.g: “Removed 1400 duplicated rows”)
- Execution times for compute-intensive operations (E.g: “Aggregation took 560s”)
- Completion checkpoints for different stages of the ETL (e.g: “Enrichment process finished successfully”)
Manuel Martín is an Engineering Manager with more than 6 years of expertise in data science. He have previously worked as a data scientist and a machine learning engineer and now I lead the ML/AI practice at Busuu.
Manuel Martín is an Engineering Manager with more than 6 years of expertise in data science. He have previously worked as a data scientist and a machine learning engineer and now I lead the ML/AI practice at Busuu.
- Schedule & Run ETLs with Jupysql and GitHub Actions
- Software Engineering Best Practices for Data Scientists
- Awesome Tricks And Best Practices From Kaggle
- Can Data Science Be Agile? Implementing Best Agile Practices to Your Data…
- MLOps Best Practices
- MLOps: The Best Practices and How To Apply Them
{kind=link}