
When you’ve heard the phrase ‘coding is useless’ for a mind-numbingly excessive variety of instances, take a deep breath and pause. A brand new benchmark from researchers throughout notable universities in america and Canada has sparked a twist within the story.
It seems that AI is much from fixing among the most complicated coding issues as we speak.
A examine by New York College, Princeton College, the College of California, San Diego, McGill College, and others signifies a major hole between the coding capabilities of present-day LLMs and elite human intelligence.
LLMs Battle to Use Novel Insights for Drawback Fixing
The researchers started by stating the shortcomings of the benchmarks out there as we speak. As an example, the LiveCodeBench analysis suffers from “inconsistent environments, weak check circumstances susceptible to false positives, unbalanced problem distributions, and the lack to isolate the results of search contamination”.
They added that different benchmarks, like SWE-Bench, check the fashions on code upkeep somewhat than algorithmic design.
Different benchmarks, like CodeELO, do introduce aggressive programming issues. Nonetheless, their reliance on static and archaic points makes it tough to test if fashions are retrieving options based mostly on reasoning or reminiscence.
To alleviate such issues, the researchers launched LiveCodeBench Professional, an analysis benchmark for coding designed to keep away from knowledge contamination. The fashions had been evaluated with 584 issues sourced straight from ‘world-class contests’ earlier than options or discussions had been out there.
Moreover, a group of Olympiad medalists annotates every drawback within the benchmark to classify it based mostly on its problem degree and nature—whether or not it’s knowledge-heavy, observation-heavy, or logic-heavy.
Sadly, none of those fashions solved a single drawback within the ‘Laborious’ class. Even one of the best and newest fashions from OpenAI, Google, Anthropic, and others that had been evaluated scored 0%.
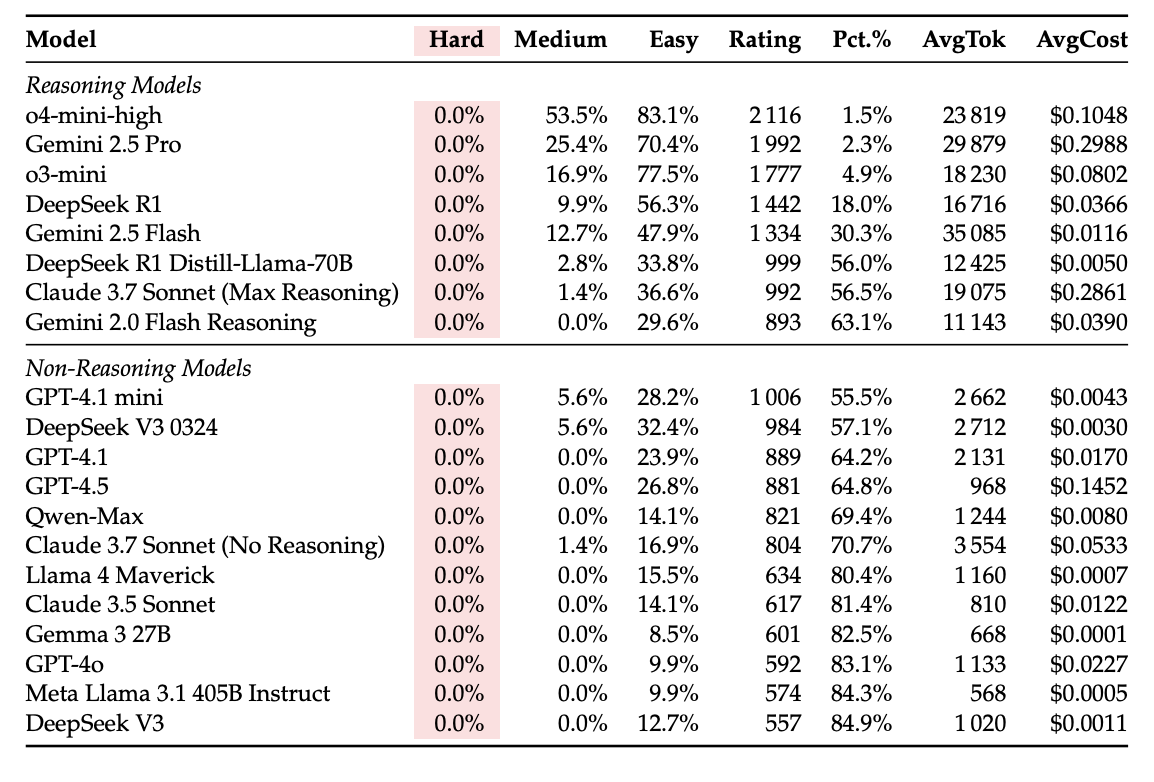
Within the ‘Medium’ problem class, OpenAI’s o4-mini-high mannequin scored the best at 53.5%.
AI fashions carried out higher on knowledge-heavy issues—ones that may be solved by stitching well-known templates, because the requisite problem-solving patterns seem ‘verbatim in coaching knowledge’. Even on logic-heavy issues, which require a patterned mind-set, these fashions carried out properly.
Nonetheless, they carried out poorly on observation-heavy issues, whose options hinge on the invention of novel insights — “one thing that can not be retrieved from memorised snippets alone”.
When these researchers identified the failure modes of those fashions, the biggest one was the place these fashions dedicated errors relating to the algorithms. “These are real conceptual slips, as an alternative of floor bugs,” mentioned the authors.
“LLMs often fail even on offered pattern inputs, suggesting incomplete utilisation of given info and indicating room for enchancment even in easy settings,” added the authors. In addition they mentioned that these fashions present a considerable enchancment in total efficiency with a number of makes an attempt to resolve the issues.
They concluded that these fashions resolve issues involving the implementation of methods, frameworks, and patterns however wrestle to resolve ones involving complicated reasoning, nuances, and edge circumstances.
“Regardless of claims of surpassing elite people, a major hole nonetheless stays, significantly in areas demanding novel insights,” they added.
For detailed info, comparisons, scores, and analysis mechanisms, try the technical report’s PDF right here.
This, nonetheless, is without doubt one of the many experiences that spotlight the shortcomings of AI-enabled coding, regardless of the optimism expressed by a number of tech leaders worldwide.
You Can’t Code for a Lengthy Time With AI
Just lately, an Oxford researcher, Toby Ord, proposed that AI brokers may need a “half-life” when performing a activity.
This was in relation to a different analysis from METR (Mannequin Analysis & Risk Analysis), which confirmed that the capability of AI brokers to deal with longer duties doubled each seven months.
They measured that the doubling time for an 80% success fee is 213 days, and for 50%, it’s 212 days, establishing consistency of their findings.
When Ord analysed the analysis, he found that, similar to radioactive decay, the AI agent’s success fee adopted an exponential decline.
As an example, if an AI mannequin might full a one-hour activity with 50% success, it solely had a 25% probability of efficiently finishing a two-hour activity. This means that for 99% reliability, activity period have to be lowered by an element of 70.
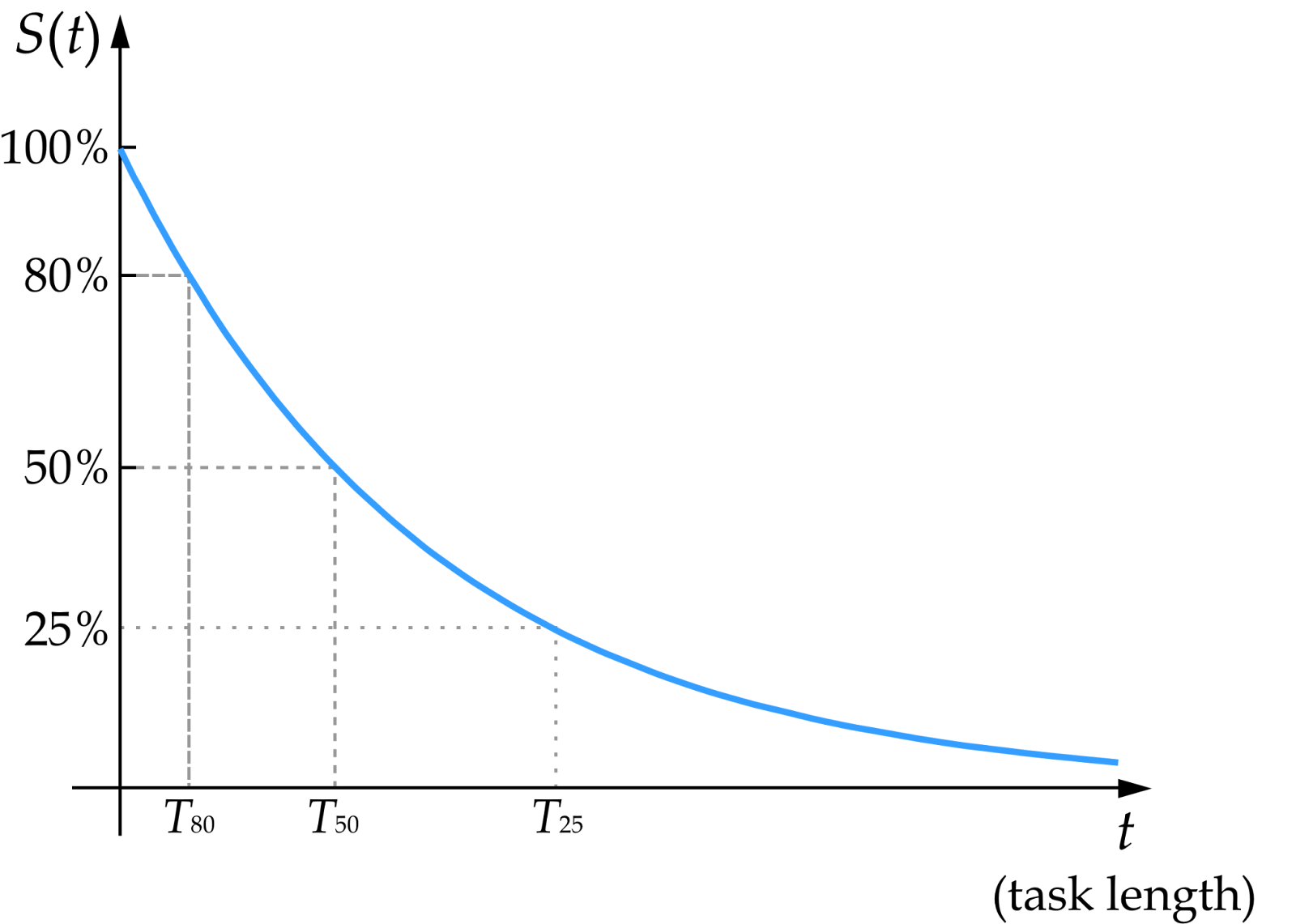
Supply: Toby Ord
Nonetheless, Ord noticed a time hole between the 50% success fee time horizon and the 80% success fee time horizon.
“For one of the best mannequin (Claude 3.7 Sonnet), it might obtain a 50% success fee on duties as much as 59 minutes vs solely quarter-hour if an 80% success fee was required,” mentioned Ord.
“If these outcomes generalise to the opposite fashions, then we might additionally see it like this: the duty size for an 80% success fee is 1/4 the duty size for a 50% success fee. Or by way of enchancment: what’s doable with a 50% success fee now’s doable with an 80% success fee in 14 months’ time (= 2 doubling instances),” he added.
Though METR signifies that AI brokers can deal with longer duties each 7 months, Ord’s evaluation reveals that high-reliability efficiency nonetheless calls for considerably shorter activity durations.
This implies the timeline for AI to deal with complicated coding initiatives stays unclear, regardless of regular enhancements in functionality.
The publish AI Fashions from Google, OpenAI, Anthropic Remedy 0% of ‘Laborious’ Coding Issues appeared first on Analytics India Journal.
{kind=link}