Everyone is aware of the inflationary model of the early universe in which the volume of space expands exponentially then slows down. AI-augmented HPC (AHPC for short) has started to expand creating new space in the scientific universe, a space that was not accessible (computationally tractable) to traditional HPC numerical methods in the past.
In the universe of numeric computation, one way to predict the future is to draw lines based on the past. Though not always perfect, predicting how fast a supercomputer will run the HPC benchmark in the future is often about extending lines. These lines reflect computational efficiencies and bottlenecks that ultimately shape the near-term exceptions for the future. The same is true for many other applications—benchmark the code, draw lines, and set reasonable expectations.
The linear universe of HPC is about to enter an inflationary period. The capabilities and reach of HPC are going to accelerate with the use of generative AI (i.e., LLMs). Hallucinations notwithstanding, a well-trained LLM can find relationships or features that are foreign to scientists and engineers. An LLM can recognize a “feature-ness” in data. Consider a feature like “speed” that is shared by different types of objects, such as automobiles, dogs, computers, molasses, etc. Each of these has a form of “speed-ness” associated with it. An LLM can recognize “speed-ness” and make associations, relationships, or analogies between totally different pieces of data. (e.g. “a car is faster than a dog” or “this computer is as slow as molasses”)
There are “dark features” in data that we don’t know about. With proper training, LLMs are good at recognizing and exploiting “dark-feature-ness” in data. That is relationships or a “feature-ness” that scientists and engineers cannot see but are still there nonetheless.
AI-augmented HPC uses these dark features to expand HPC’s computational space. Often called “surrogate models,” these new tools will provide scientists and engineers with a shortcut to potential solutions by suggesting the best candidates. For instance, instead of 10,000 possible pathways to a solution, the LLM can narrow the field of viable solutions by several orders of magnitude, making what was once a computationally intractable problem a solvable problem.
In addition, using foundational models feels like an NP-hard problem. Creating the model is computationally expensive, but testing results are often trivial (or at least possible in much less time). We are entering the era of AI-augmented HPC, where AI is used to assist traditional HPC computational domains by providing solutions with less computation or recommending optimized solution spaces that are more tractable.
These remarkable breakthroughs are happening now. Instead of trying to create large general AI models like ChatGPT or Llama, AI-augmented HPC seems to be focusing on specialized foundational models designed to address specific scientific domains. Examples of three such models are described here.
The limits and impact of AI-augmented HPC are unknown because scientists and engineers can’t see the “dark feature-ness” that foundational models can recognize. Advances will not be linear. As described below, early foundation models portend a huge expansion of the computational science space.
Programmable Biology: EvolutionaryScale ESM3
The holy grail of biological science is the ability to understand and navigate sequence (DNA), structure (proteins), and function (cells, organs). Each of these areas represents active research in its own right. Combining these processes would open a new era of programable biology. Like any new technology, there are risks, and the rewards include new medicines, cures, and medicines that were not previously possible.
A new company, EvolutionaryScale, has developed a life sciences foundational model, ESM3 (EvolutionaryScale Model 3), that has the potential to engineer biology from the first principles in the same way as machines or microchips and computer programs. The model was trained on almost 2.8 billion protein sequences sampled from organisms and biomes (a distinct geographical region with specific climate, vegetation, and animal life) and offered significant updates over previous versions.
Attempts to do biological engineering are difficult. Based on the human genome (and others), protein folding tries to figure out the shape proteins will take in biological environments. This process is computationally intensive, and one of the most successful efforts, AlphaFold, uses deep learning to speed up the process.
As a proof of concept, EvolutionaryScale has released a new preprint (currently in preview, pending submission to bioRxiv) where they describe the generation of a new green fluorescent protein (GFP). Fluorescent proteins are responsible for the glowing colors of jellyfish and corals and are important tools in modern biotechnology. The new protein identified with ESM3 has a sequence that is only 58% similar to the closest known natural fluorescent proteins, yet it fluoresces with a similar brightness to natural GFPs. The process is described in more detail on the company blog.
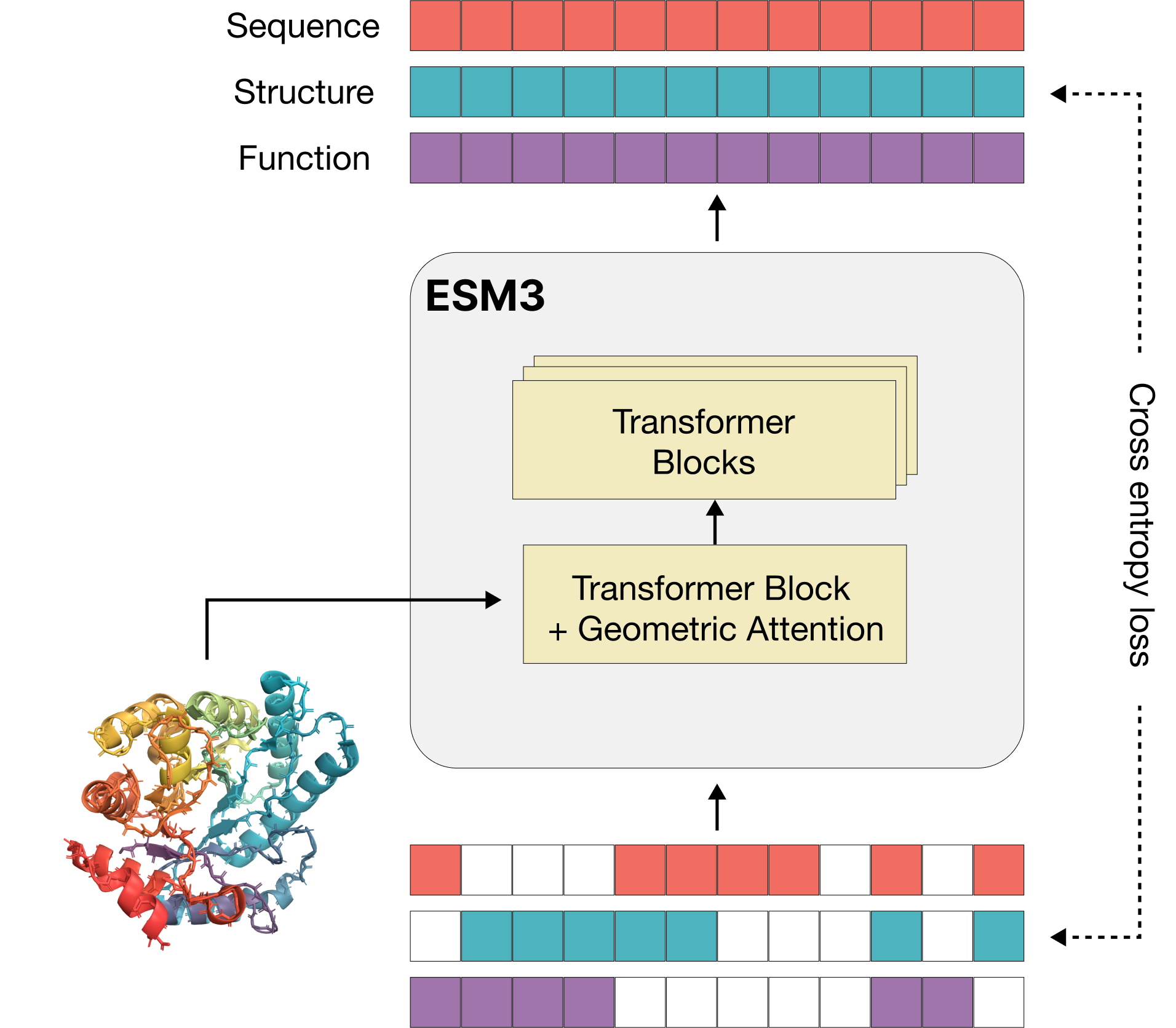
ESM3 is a multi-track transformer that jointly reasons over protein sequence, structure, and function. (Source: EvolutionaryScale)
Generating a new GFP by pure chance (or trial and error) from among a huge number of sequences and structures would be virtually impossible. EvolutionaryScale states, “From the rate of diversification of GFPs found in nature, we estimate that this generation of a new fluorescent protein is equivalent to simulating over 500 million years of evolution.”
In their introductory blog, EvolutionaryScale mentions safety and responsible development. Indeed, just as a foundational model like E3M3 can be asked to create new candidates for curing cancer, it could be asked to create lethal substances — more lethal than those currently known. AI safety will become more important as foundation models continue improving and becoming more pervasive.
EvolutionaryScale has pledged open development, placing their weights and code on GitHub. They also list eight independent research efforts that are using open ESM models.
Weather and Climate Prediction: Microsoft ClimaX
Another example of AI-augmented HPC is the Microsoft ClimaX model. Available as open source the ClimaX model is the first foundation model trained for weather and climate science.
State-of-the-art numerical weather and climate models are based on simulations of large systems of differential equations that relate the flow of energy and matter based on the known physics of different Earth-based systems. As is common, such a huge amount of computation necessitates large HPC systems. Although successful, these numeric models are often limited in terms of resolution due to the state-of-the-art underlying hardware. Machine learning (ML) models can offer an alternative benefiting from the scale of both data and compute. Recent attempts at scaling up deep learning systems for short- and medium-range weather forecasting have succeeded. However, most ML models are trained for a specific predictive task on specific datasets; they lack the general-purpose utility needed for weather and climate modeling.
Unlike many text-based Transformers (LLMs), ClimaX is based on a modified Vision Transformer (ViT) model from Google Research. ViT was originally developed for processing image data but has been modified to predict weather.
ClimaX can be fine-tuned for various prediction tasks to accommodate various uses and performs better than state-of-the-art prediction systems on several benchmarks. For example, when using the same ERA5 data, even at medium resolutions, ClimaX performs comparably, if not better than IFS (The Integrated Forecasting System a global numerical weather prediction system).

ClimaX is built as a foundation model for any weather and climate modeling task. On the weather front, these tasks include standard forecasting for various lead-time horizons at various resolutions, both globally and regionally. On the climate front, making long-term projections and obtaining downscaling results from lower-resolution model outputs are standard tasks. (Source: Microsoft)
ClimaX is built as a foundation model for any weather and climate modeling task. On the weather front, these tasks include standard forecasting for various lead-time horizons at various resolutions, both globally and regionally. On the climate front, making long-term projections and obtaining downscaling results from lower-resolution model outputs are standard tasks.
COVID-19 Variant Search at Argonne
Another successful use of a domain-specific foundational model was demonstrated by scientists from the U.S. Department of Energy’s (DOE) Argonne National Laboratory and a team of collaborators. The project developed an LLM to aid in the discovery of SARS-CoV-2 variants.
All viruses, like COVID-19, evolve as they reproduce (using the host cell machinery). With each generation, mutations occur, producing new variants. Many of these variants show no additional activity; however, some can be more deadly and contagious than the original virus. When a particular variant is considered more dangerous or harmful, it is labeled as a variant of concern (VOC). Predicting these VOCs is difficult because the possible variations are quite large. Indeed, the key is predicting possible variations that can be troublesome.
The researchers used Argonne Lab’s supercomputing and AI resources to develop and apply LLM models to track how viruses can mutate into more dangerous or more transmissible variants. The Argonne team and collaborators created the first genome-scale language model (GenSLM) that can analyze COVID-19 genes and rapidly identify VOCs. Trained on a year’s worth of SARS-CoV-2 genome data, the model can infer the distinction between various viral strains of the virus. In addition, GenSLM is the first whole genome-scale foundation model that can be altered and applied to other prediction tasks similar to VOC identification.
Previously, without GenSLMs, VOCs needed to be identified by individually going through every protein and mapping each mutation to see if any mutations were of interest. This process consumes large amounts of labor and time, and GenSLMs should help make this process easier.
The Figure shows that the GenSLM model can infer the distinction between various viral strains.
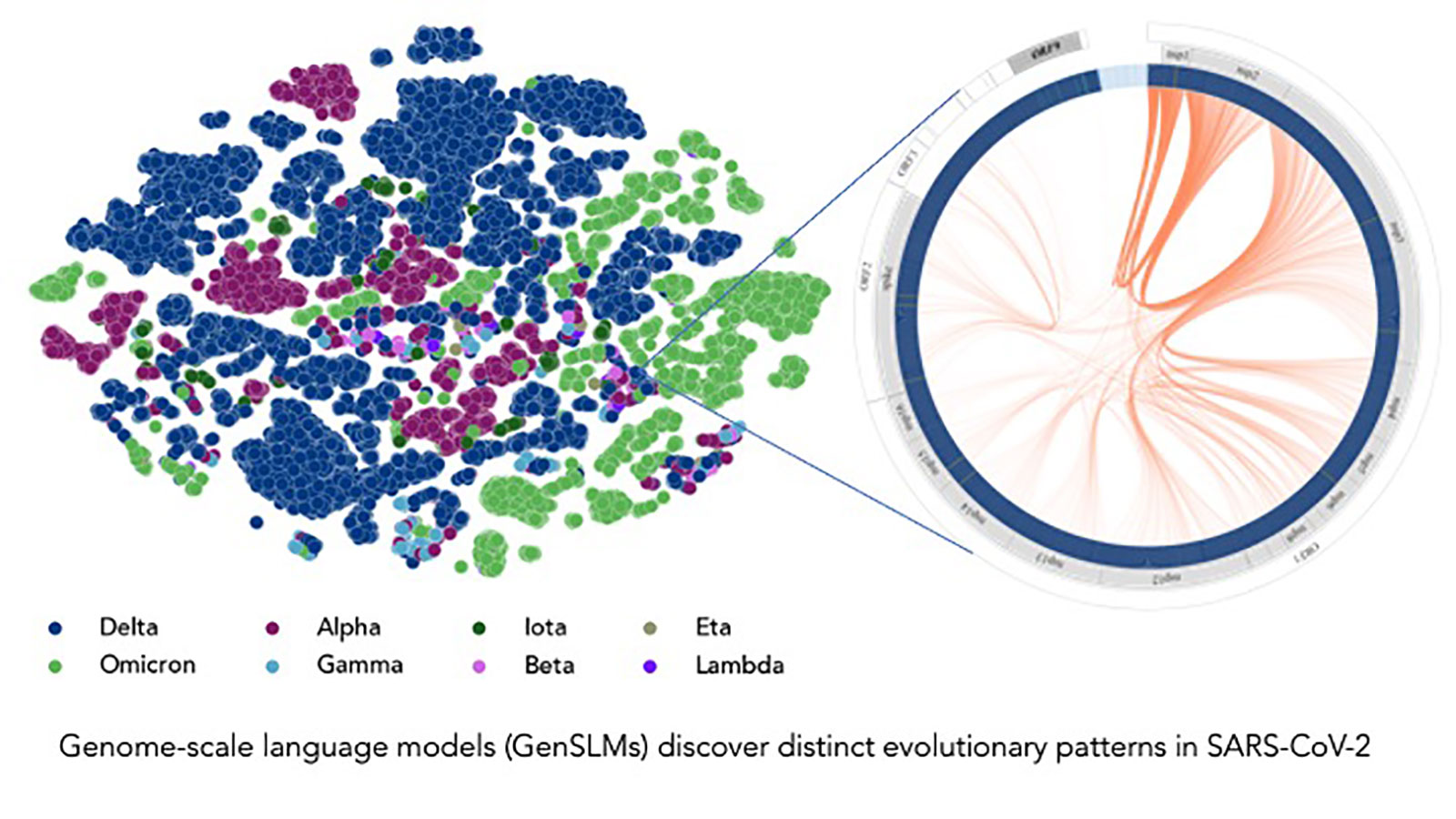
The model can infer the distinction between various viral strains based on a year’s worth of SARS-CoV-2 genome data. Each dot on the left corresponds to a sequenced SARS-CoV-2 viral strain, color-coded by variant. (Image by Argonne National Laboratory/Bharat Kale, Max Zvyagin and Michael E. Papka)
Led by computational biologist Arvind Ramanathan, the research team consisted of his colleagues at Argonne together with collaborators from the University of Chicago, NVIDIA, Cerebras Inc., University of Illinois at Chicago, Northern Illinois University, California Institute of Technology, New York University, and Technical University of Munich. A full description of the work can be found in their paper: GenSLMs: Genome-scale language models reveal SARS-CoV-2 evolutionary dynamics. It should be noted that the project was the recipient of the 2022 Gordon Bell Special Prize for High Performance Computing-Based COVID-19 Research for their new method of quickly identifying how a virus evolves.
Inflating Science
All three examples provide a much-expanded view of their respective domains. Currently, building and running LLM foundational models is still a specialized task. Despite the availability of hardware, creating new and enhanced models will become easier for domain practitioners. These foundational models will recognize the “dark-feature-ness” of their specific domains and allow science and engineering to expand into new vistas. The universe of science and technology is about to get much, much bigger.
{kind=link}