
Amidst the hype around multimodal AI models and AI agents, Adept has unveiled the Fuyu-8B, a scaled-down version of their multimodal model now accessible through HuggingFace. The model can understand charts, documents, and diagrams, with its newly improved OCR capabilities.
This new model has garnered considerable attention for several key reasons that includes a simplified architecture. Fuyu-8B boasts a simple training process compared to other multimodal models, offering a more accessible, scalable, and deployable solution.
We’re open-sourcing a multimodal model: Fuyu-8B! Building useful AI agents requires fast foundation models that can see the visual world.
Fuyu-8B performs well at standard image understanding benchmarks, but it also can do a bunch of new stuff (below)https://t.co/7bTh6mDNEY— Adept (@AdeptAILabs) October 18, 2023
It is specifically tailored for digital AI agents by meticulously designing to cater to the specific needs of digital agents. It excels in handling arbitrary image resolutions, answering queries related to graphs, diagrams, UI-based questions, and precise localization on screen images. Perhaps most notably, Fuyu-8B exhibits remarkable speed, delivering responses for large images in under 100 milliseconds.
Despite being optimised for specific applications, Fuyu-8B performs admirably in standard image understanding benchmarks, such as visual question-answering and natural-image-captioning.
The Fuyu model eschews the complex and convoluted architecture of its counterparts. Instead, it employs a vanilla decoder-only transformer, omitting the need for a separate image encoder. Image patches are linearly projected into the first layer of the transformer, simplifying the model’s structure.
This architectural streamlining allows Fuyu to support image resolutions of any size, treating image tokens as it does text tokens. Special image-newline characters indicate line breaks, and the model utilises its existing position embeddings to adapt to different image sizes. This approach eliminates the need for separate high and low-resolution training stages, vastly simplifying the training and inference process.
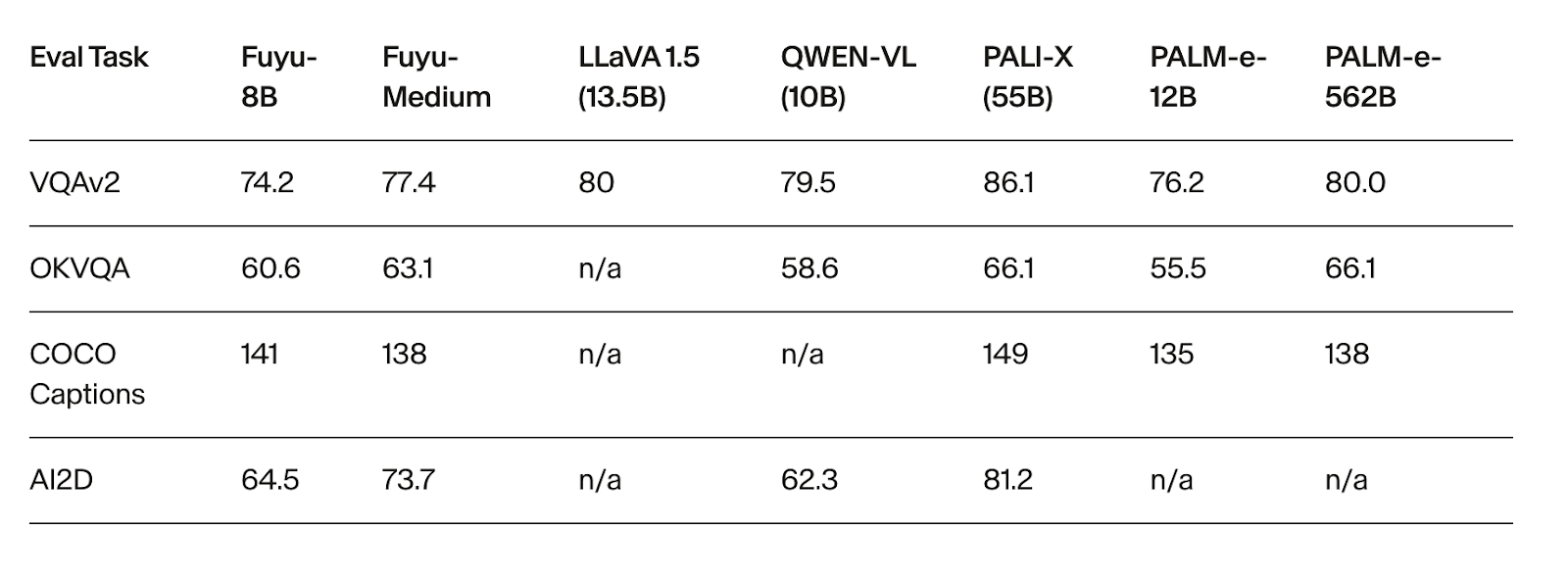
To assess the changes, Adept conducted evaluations on prominent image-understanding datasets, including VQAv2, OKVQA, COCO Captions, and AI2D. Fuyu-8B demonstrated robust performance, even in the realm of natural images. It notably outperformed models like QWEN-VL and PALM-e-12B on multiple metrics, despite having significantly fewer parameters. Even the Fuyu-Medium variant held its own against PALM-E-562B, boasting a fraction of the parameters.
Although PALI-X remains the leader on these benchmarks due to its fine-tuning for each specific task, it is essential to note that Adept’s primary focus does not revolve around optimising these benchmarks. Nevertheless, Fuyu-8B and its variations are promising additions to the field of multimodal models, offering a simpler yet highly effective alternative.
Read: Group of ML experts from big tech to create Adept.AI
The post Adept Releases Fuyu-8B for Multimodal AI Agents appeared first on Analytics India Magazine.
{kind=link}