In this article, I explore 10 additional features that have a big impact on LLM/RAG performance, in particular on speed, latency, results relevancy (minimizing hallucinations, exhaustivity), memory use and bandwidth (cloud, GPU, training, number of parameters), security, explainability, as well as incremental value for the user. I published the first part here. These features are implemented in my xLLM system, and most are discussed in detail in my LLM coursebook, available here.
11. Distillation
In my system, I build two frontend tables q_dictionary and q_embeddings each time a user generates a new prompt, in order to retrieve the relevant content from the corpus. These tables are similar and linked to the dictionary and embeddings backend tables, but far smaller and serving a single prompt. Then, I remove single tokens that are part of a multi-token when both have the same count in the dictionary. See Figure 1. It makes the output results more concise.
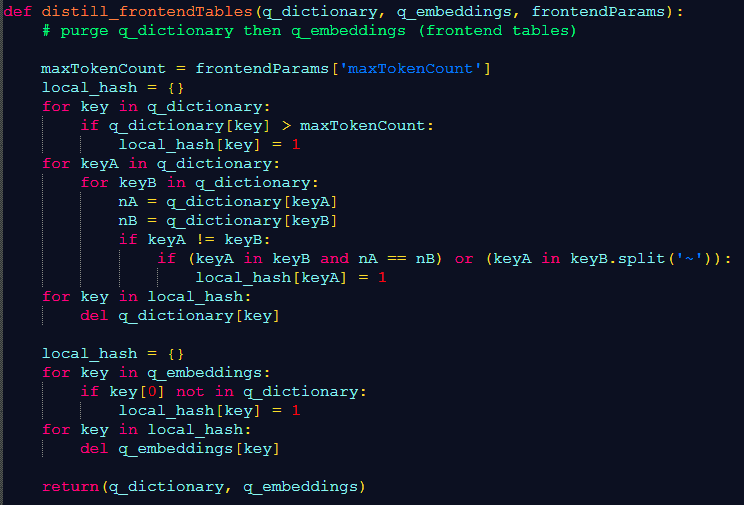
This step is called distillation. In standard LLMs, you perform distillation on backend rather than frontend tokens using a different mechanism, since multi-tokens are usually absent; it may result in hallucinations if not done properly. Also, in standard LLMs, the motivation is different: reducing a 500 billion token list, to (say) 50 billion. In my xLLM, token lists are at least 1000 times smaller, so there is no real need for backend distillation.
Also, I keep a single copy of duplicate text entities. These are the core text elements found in the corpus, for instance paragraphs, PDFs, web pages and so on. As in Google search, when blending content from multiple sources (sometimes even from a single source, or for augmentation purposes), some text entities are duplicated, introducing a bias in the results, by giving too much weight to their tokens.
12. Reproducibility
Most GenAI applications rely on deep neural networks (DNN) such as GAN (generative adversarial networks). This is the case for transformers, a component of many LLMs. These DNNs rely on random numbers to generate latent variables. The result can be very sensitive to the seed (to initialize the random number generators). In many instances, particularly for synthetic data generation and GPU-based apps, the author does not specify seeds for the various PRNG (pseudo-random number generator) involved, be it from the Numpy, Random, Pandas, PyTorch libraries, base Python, or GPU.
The result is lack of reproducibility. This is not the case with my algorithms, whether GAN or NoGAN. All of them lead to reproducible results, including the xLLM system described here, which does not rely on transformers or random numbers. There have been some attempts to improve the situation recently, for instance with the set_seed function in some transformer libraries. However, it is not a full fix. Furthermore, the internal PRNGs found in Python libraries are subject to change without control on your side. To avoid these problems, I invite to check out my own PRNGs, some of them faster and better than any other on the market, with one of them requiring just one small line of code. See my article “Fast Random Generators with Infinite Period for Large-Scale Reproducible AI and Cryptography”, available here.
Without sharing the seeds, the only way to make the model reproducible is to save the full model each time, with its billions of weights, instead of a handful of seed parameters. It also makes testing more difficult.
13. Explainable AI
Do you really need billions of weights (called parameters) that you compute iteratively with a neural network and thousands of epochs? Not to mention a stochastic gradient descent algorithm that may or may not converge. I do it with zero weight, see my article “Zero-Weight LLM for Accurate Predictions and High-Performance Clustering”, here.
The idea consists of using functions that require few if any parameters, such as PMI (pointwise mutual information), an alternative to the cosine distance and activation functions to measure keyword correlations. It is similar to some regularization methods in regression, with highly constrained or even fixed parameters, drastically reducing the dimensionality (or degrees of freedom) of the problem. Instead of estimating billions of weights with a deep neural network, the weights are governed by a few explainable hyperparameters. It makes fine-tuning much faster and a lot easier. This in turn allows for several benefits, see the next two sections.
14. No training
With zero parameter, there is no need for training, though fine-tuning is still critical. Without the big neural network machinery, you or the user (thanks to explainable parameters) can fine-tune with in-memory database (the backend tables structured as nested hashes in my case), and in real time, with predictable outcome resulting from any change. There is no risk of overfitting.
The result is a full in-memory LLM running on a laptop, without GPU. And custom output as the user can play with his favorite set of hyperparameters. Of course, you can also use algorithms such as smart grid search to automate the fine-tuning, at least to find the best possible default hyperparameter set. What’s more, your LLM can run locally, which increases security and reduces external dependencies, especially valuable to corporate clients.
15. No neural network
In the previous section, I described an LLM that does not use a neural network. In particular, it does not need transformers. The concept of transformer-free LLM/RAG is not new. Indeed, it is gaining in popularity. However, at least in the case of xLLM, prompt results are bullet list items grouped in sections: references, tags, categories, related keyword, links, datasets, PDFs, titles, and even full text entities coming from the corpus if desired, via the backend tables. With each item having its own relevancy score.
This conciseness and exhaustivity is particularly useful to business professionals or for me. It acts as a search tool, much better than Google or internal search boxes found on countless websites. However, beginners prefer well-worded, long, coherent English sentences that form a “story”. In short, generated rather than imported text, even though the quality of the imported text (full sentences) is high, because it comes from professional websites.
To satisfy beginners or any user fond on long English sentences, you would need to add an extra layer on top of the output. This may require a neural network, or not. Currently, my xLLM returns items with a text entity ID attached to them, rather than the full content. A typical prompt may result in 20 IDs grouped into sections and clusters. The user can choose the IDs most relevant to his interests, then request the full content attached to these IDs, from the prompt menu. Displaying the full content by default would result in the user facing a flood of output text, defeating the purpose of conciseness.
16. Show URLs and references
As explained earlier, my xLLM returns URLs, references, and for each corpus entry (a text entity), even the email address of the employee maintaining the material in question in your organization. Other benefits include concise yet exhaustive results, relevancy scores attached to each item in the results, and local implementation.
17. Taxonomy-based evaluation
Assessing the quality of LLMs is a difficult problem, as there is no “perfect answer” to compare with. The problem is similar to evaluating clustering algorithms: both solve unsupervised learning problems. In special cases such as LLM for predictive analytics (a supervised learning technique), evaluation is possible via standard cross-validation techniques, see here. Reversible translators from one language to another (English to German, or Python to Java) are easier to evaluate: translate from English to German, then from German back to English. Repeat this cycle 20 times and compare the final English version, with the original one.
Since my xLLM mostly deals with knowledge graphs, one way to assess quality is to have it reconstruct the internal taxonomy of the corpus, pretending we don’t know it. Then compare the result with the actual taxonomy embedded in the corpus and retrieved during the crawl. Even then, the problem is not simple. In one example, the reconstructed taxonomy was less granular than the original one, and possibly better depending on the judge. But definitely different to some significant extent.
18. Augmentation via prompt data
A list of one million user prompts is a data gold mine. You can use it to build agents, create an external taxonomy for taxonomy augmentation, detect what is missing in the corpus and address the missing content (possibly via augmentation). Or create lists of synonyms and abbreviations to improve your LLM. Imagine a scenario where users are searching for PMI, when that word is nowhere mentioned in your corpus, replaced instead by its expansion “pointwise mutual information”. Now, thanks to user queries, you can match them both.
19. Variable-length embeddings and database optimization
Embeddings of static length work well with vector databases. The price to pay is time efficiency due to the large size of the embeddings. With variable length and nested hash databases, you can speed up search dramatically.
Also, in my implementation, backend tables store text entity IDs along with embeddings, but not lengthy sentences (the full content). When retrieving results, the full original text associated to various items is not immediately displayed. Only the category, title, URL, related words and other short pieces of content, along with IDs. To retrieve the full content, the user must select IDs from prompt results. Then ask (from the command prompt) to fetch the full content attached to these IDs, from the larger database. You can automate this step, though I like the idea of the user selecting himself which IDs to dig in (based on score, category, and so on). The reason is because there may be many IDs shown in the prompt results, and the user’s choice may be different from algorithmic decisions.
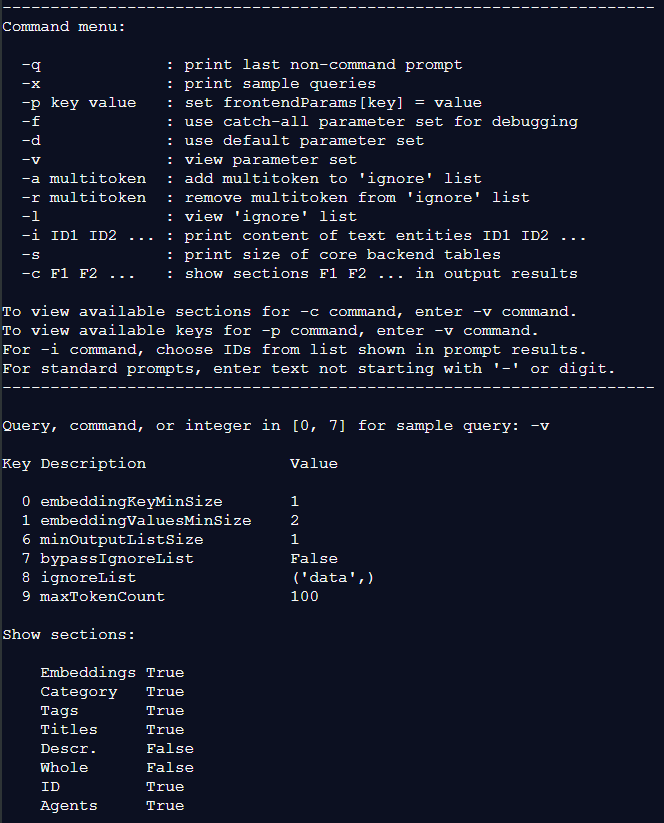
Figure 2 shows the command prompt in xLLM. Note the -p option for real-time fine-tuning, and the -i option to retrieve full content from a list of text entity IDs.
20. Favor backend over frontend engineering
The need for prompt engineering is due in part to faulty backend implementation. Too many tokens (most of them being noise), the choice of poor input sources (for instance, Reddit), too much reliance on embeddings only, and failure to detect and retrieve the embedded structure (knowledge graph, taxonomy) when crawling the corpus. Instead, knowledge graphs are built on top rather than from the ground up. Prompt engineering is the fix to handle the numerous glitches. Some glitches come the Python libraries themselves, see next section.
By revisiting the fundamentals, even crawling and the choice of input sources, you can build a better architecture from the beginning. You may experience fewer hallucinations (if any) and avoid prompt engineering to a large extent. Your token list can be much smaller. In our case, embeddings is just one of the many backend tables, and not the most important one. The use of large contextual tokens and multiple sub-LLMs with ad-hoc parameters and stopword lists for each one, also contributes to the quality and robustness of the system.
21. Use NLP with caution
Python libraries such as auto-correct, singularize, stopwords, and stemming, have numerous glitches. You can use them, but I recommend having do-not-auto-correct, do-not-singularize lists and so on, specific to each sub-LLM.
It is tempting to ignore punctuation, special or accented characters and upper cases to standardize the text. But watch out for potential side effects. These special text elements can be of great value if you keep them. Some words such as “San Francisco” are single-tokens disguised as double-tokens.
About the Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}