

Meta, the corporate behind the open-source Llama household of AI fashions, unveiled a brand new report on Monday titled ‘The Frontier AI Framework’.
This report outlines the corporate’s method to growing general-purpose AI fashions by evaluating and mitigating their “catastrophic dangers”. It focuses on large-scale dangers, comparable to cybersecurity threats and dangers from chemical and organic weapons.
“By prioritising these areas, we will work to guard nationwide safety whereas selling innovation,” learn a weblog submit from the corporate asserting the report.
The framework is structured round a three-stage course of: anticipating dangers, evaluating and mitigating dangers, and deciding whether or not the mannequin must be launched, restricted, or halted.
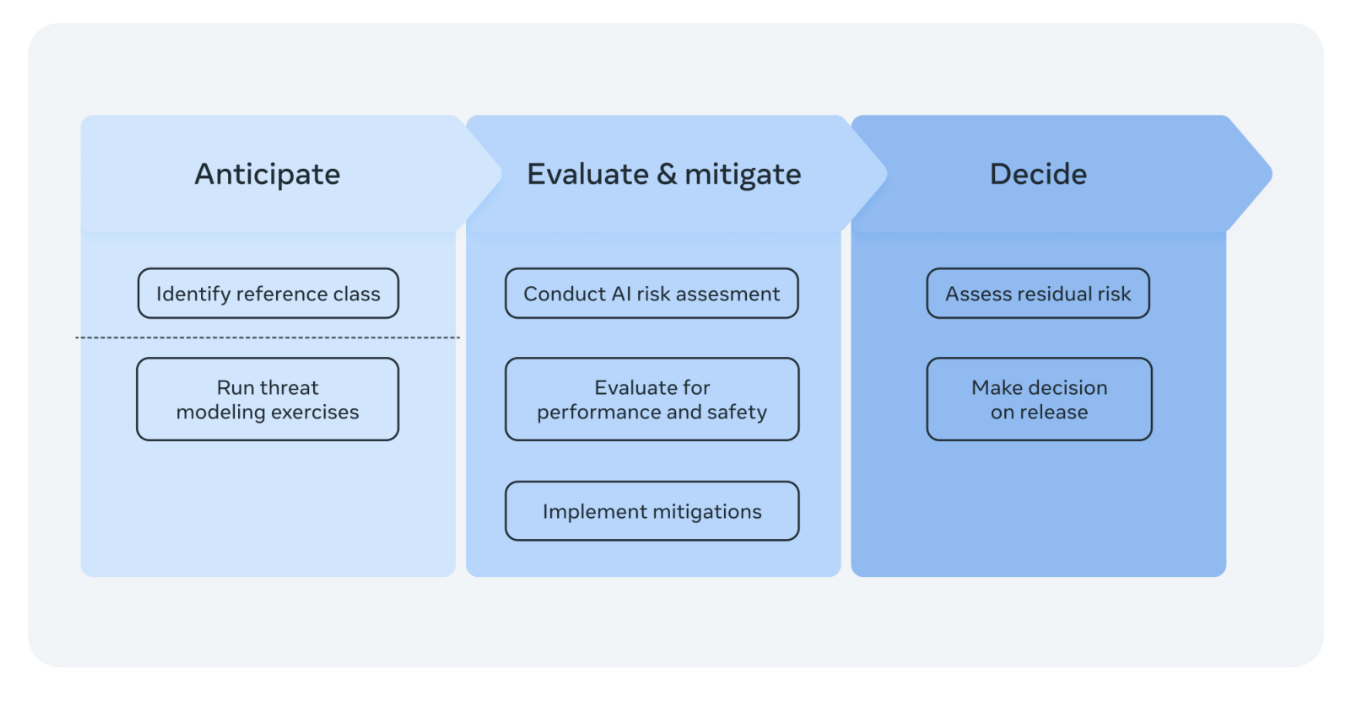
The report incorporates danger assessments from varied specialists in a number of disciplines, together with engineering, product administration, compliance and privateness, authorized and coverage, and different firm leaders.
If the dangers are deemed “important”, the framework suggests stopping the event of the mannequin and limiting entry to a small variety of specialists with safety protections.
If the dangers are deemed “excessive”, the mannequin shouldn’t be launched however might be accessed by a core analysis crew with safety protections. Lastly, if the dangers are “reasonable”, the mannequin might be launched as per the framework.
It is suggested that you simply learn the complete report to know every of those danger ranges intimately.
“Whereas it’s not attainable to thoroughly get rid of danger if we wish this AI to be a web optimistic for society, we consider it’s essential to work internally and, the place applicable, with governments and out of doors specialists to take steps to anticipate and mitigate extreme dangers that it might current,” the report said.
A number of corporations constructing AI fashions have unveiled such frameworks over time. For example, Anthropic’s ‘Accountable Scaling Coverage’ offers technical and organisational protocols that the corporate is adopting to “handle dangers of growing more and more succesful AI techniques”.
Anthropic’s coverage defines 4 security ranges. The upper the protection degree, the bigger the mannequin’s functionality, which will increase safety and security measures.
In October final yr, the corporate stated it was required to improve its safety measures to an AI security degree of three, which is the penultimate degree of security. This degree means that the mannequin’s functionality poses a “considerably increased danger”.
Equally, OpenAI has a constitution that outlines its mission to develop and deploy AI fashions safely. Moreover, the corporate commonly releases a system card for all of its fashions, which outlines its work concerning security and safety earlier than releasing any new variant.
The submit Meta’s New Report Reveals Methods to Stop ‘Catastrophic Dangers’ from AI appeared first on Analytics India Journal.