

Everyone loves retrieval-augmented generation (RAG). It has revolutionised how AI systems process and respond to user queries by leveraging external knowledge sources. At the same time, everyone wants to replace RAG with something new as it doesn’t meet all the diverse needs of modern enterprises.
As the demands for nuanced, complex, and adaptive AI systems grow, the traditional RAG approach—often dubbed vanilla RAG—is reaching its limitations. This is where agentic RAG comes into play. Agentic RAG represents an advanced architecture that combines the foundational principles of RAG with the autonomy and flexibility of AI agents, promising a future where AI systems are more adaptive, proactive, and intelligent.
What Exactly is Agentic RAG?
Armand Ruiz, VP of product-AI platform at IBM, shared on LinkedIn that agentic RAG is here, and it aligns with the future of AI, which he believes is also agentic. He posted the GitHub repository for LangChain agentic RAG system using IBM’s Granite 3.0 8B Instruct model on Watsonx.
Regardless, in its conventional form, vanilla RAG involves a linear pipeline where user queries are processed through retrieval, reranking, synthesis, and response generation. While it effectively generates grounded and contextually relevant answers, vanilla RAG struggles with flexibility. It relies heavily on predefined knowledge sources, lacks mechanisms for validating retrieved data, and operates as a one-shot retriever without iterative refinement.
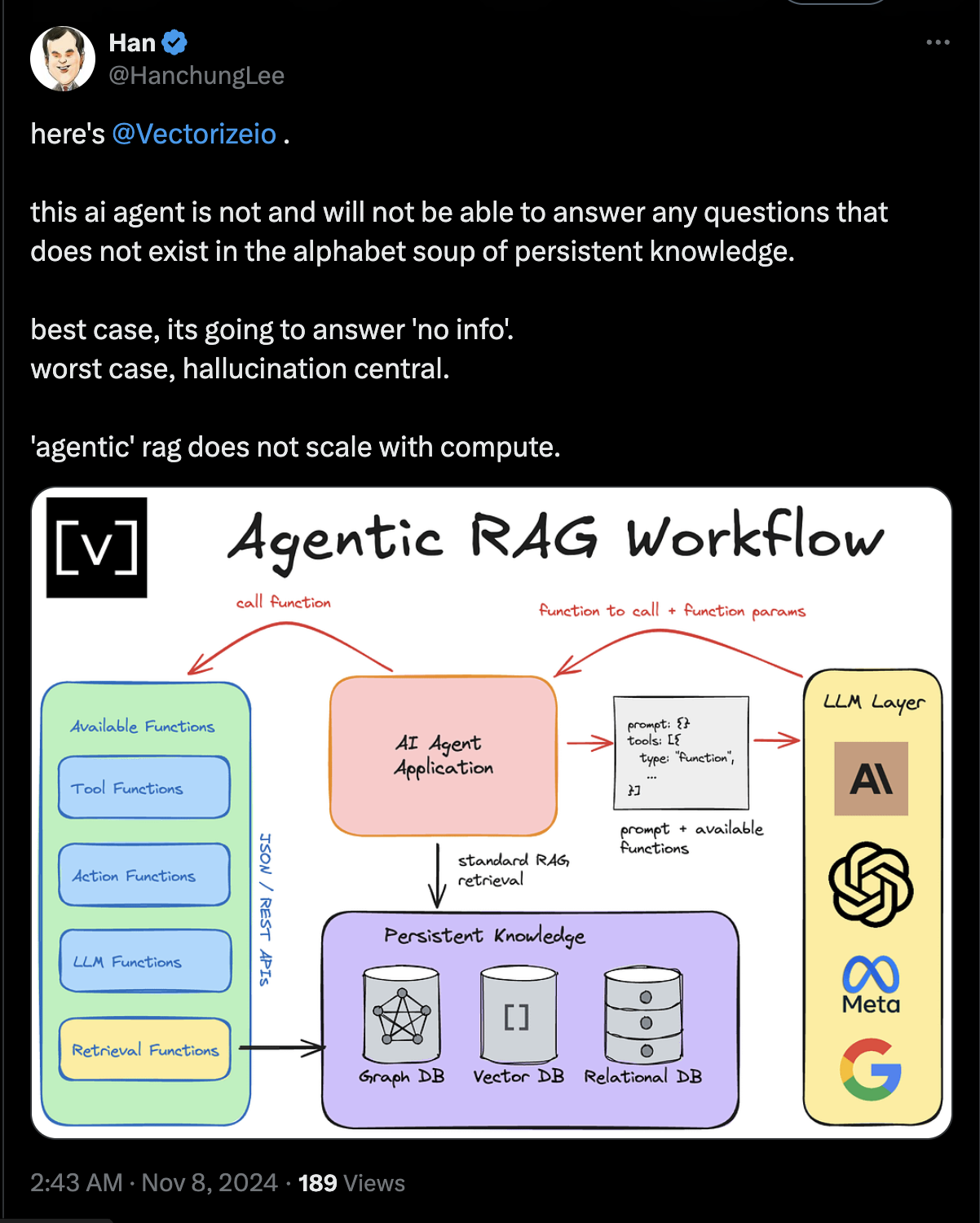
Agentic RAG addresses these shortcomings by integrating AI agents into the RAG pipeline. These agents act autonomously, orchestrating complex tasks like planning, multi-step reasoning, and tool utilisation. This agentic approach transforms static retrieval systems into dynamic frameworks capable of adapting strategies based on evolving data and user needs.
At the core of agentic RAG is the ability to incorporate agents at various stages of the RAG pipeline. It allows users to build systems with complete autonomy to reason and execute specific tools when needed.
Technology partner manager Erika Cardenas, and machine learning engineer Leonie Monigatti at Weaviate explained that Agents determine whether external knowledge is needed, select the appropriate retrieval tool (e.g., vector search, web search, APIs), and formulate queries tailored to the task.

Further, instead of relying on the initial retrieved data, agents validate its relevance and re-retrieve if necessary, ensuring the final output aligns with the user’s intent. Agents can also access diverse tools, from calculators and email APIs to web searches and proprietary databases, significantly broadening the scope of what can be retrieved and processed.
With agentic RAG, it seems like the conversation around fine-tuning and RAG is finally dead. Agents can resolve queries with unparalleled accuracy and speed by retrieving information from community forums, internal knowledge bases, and documentation.
It is akin to a model being fine-tuned at the time of inference, also what some people call reasoning using multiple models. This is what LlamaIndex also calls the agentic RAG framework—adding LLM layers to reason over inputs and post-process the outputs.
This architecture isn’t limited to single-agent systems. In more advanced setups, multiple agents collaborate under the guidance of a meta-agent, with each specialised in tasks like summarising internal documents, retrieving public data, or analysing personal content like emails and chat logs.
RAG is Not the Answer?
Not everyone likes RAG.Amit Sheth, the chair and founding director of the Artificial Intelligence Institute of South Carolina (AIISC), replied to Ruiz’s post, claiming RAG bothers him in principle. “You need RAG because the core/backend/main AI system is inadequate,” Sheth said, adding that RAG systems are needed because the core AI systems are not good enough for accurate information, which makes it a loss of effort that went into building them.
Moreover, according to several researchers, if an agentic RAG thinks longer and gives no response because no information is available in the database, it is just a waste of compute, and thus, it does not scale with more compute.
In a bid to move beyond RAG, Google introduced a new approach—retrieval interleaved generation (RIG)—with its DataGemma model. This technique integrates LLMs with Data Commons, an open-source database of public data.
With RIG, if the AI model needs more current or specific data, it pauses to search for this information from reliable external sources like databases or websites. The model then seamlessly incorporates this newly acquired data into its response, alternating between generating content and retrieving information as needed.
When it comes to agentic RAG, however, the system dynamically adapts retrieval strategies, accessing varied tools and knowledge sources beyond static databases. With iterative retrieval and reasoning, agents ensure the data they retrieve is accurate and relevant.
Agents anticipate user needs and take preemptive actions, enabling a smoother and more efficient interaction process. This proactive and adaptive nature makes agentic RAG particularly effective in scenarios requiring detailed reasoning, multi-document comparison, and comprehensive decision-making. In this context, even approaches like RIG become less relevant.
The post Goodbye Vanilla RAG, Agentic RAG is Here appeared first on Analytics India Magazine.