

Google DeepMind, in collaboration with Hugging Face, open sourced its research titled ‘Scalable watermarking for identifying large language model outputs’ in a bid to distinguish between human and AI content on the internet, driven by LLMs. Launched exactly a year ago, SynthID, their watermarking tool, is now available for wider access.
This research paper is Google’s attempt to establish transparency in the AI content space and answer questions like, “What’s real anymore?” SynthID can produce a digital watermark that’s imperceptible to humans and works across Google products to tag AI-generated images, videos, audio, and text.
The tool has already been deployed in Google’s Gemini and Gemini Advanced chatbots, serving millions of users. It is available on Google Cloud’s Vertex AI and supports Google’s Imagen and Veo models. Users can check if an image is AI-generated using Google’s ‘About this image’ feature in Search or Chrome.
Interestingly, SynthID’s watermarking process is designed to have negligible computational impact, which is ideal for both running on the cloud and on-device detection.
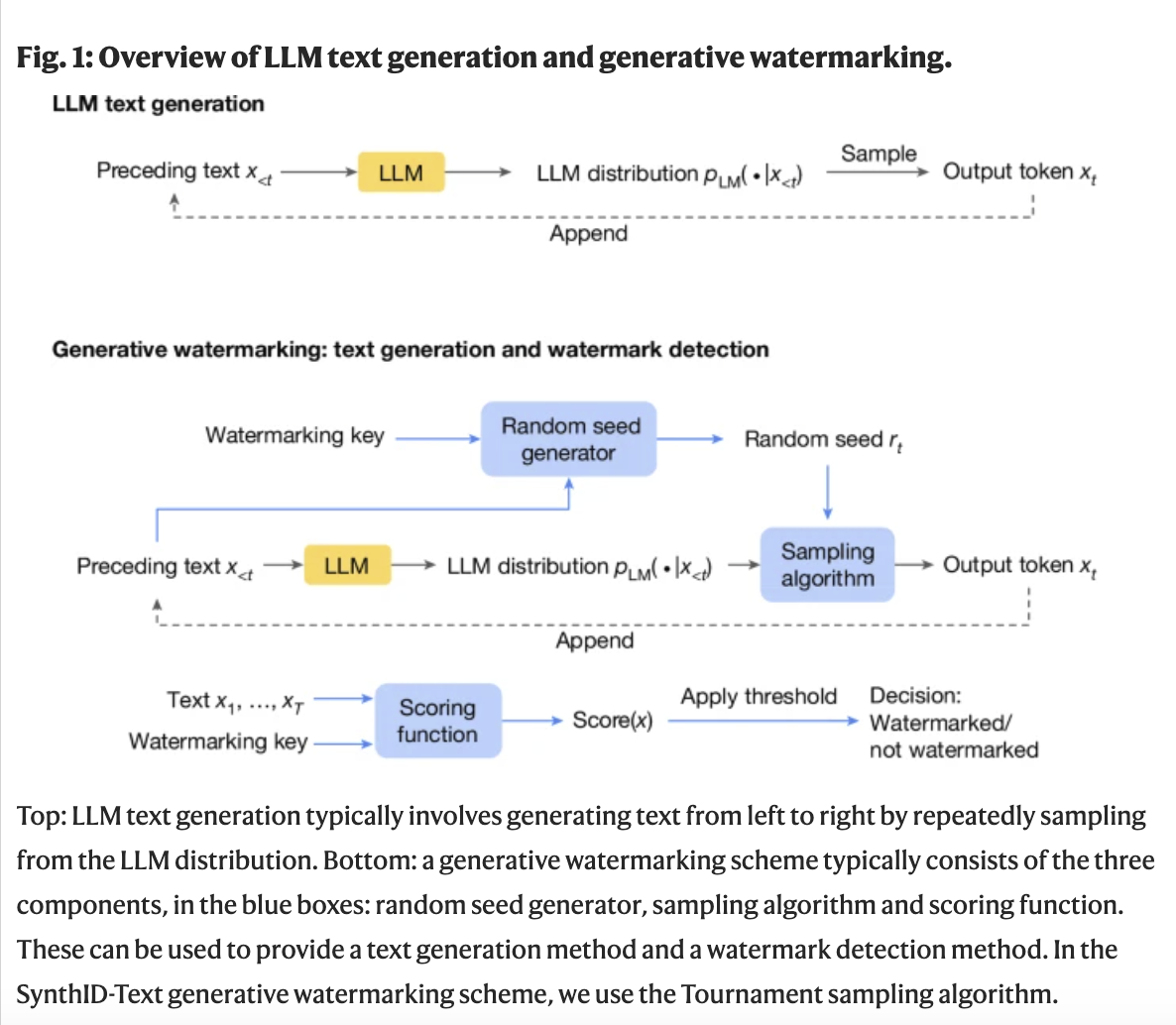
How Does SynthID Work?
According to the research paper, SynthID uses a tournament sampling process where tokens are scored and selected through a series of rounds, with the highest-scoring token chosen. Watermark detection checks if the text scores higher, indicating it is watermarked.
SynthID has two types of watermarking: non-distortionary (maintaining text quality) and distortionary (better detectability but reduced quality). It is efficient, scalable, and can be used in large systems with speculative sampling to balance watermark strength and text quality.
However, there is still work that needs to be done. Ethan Mollick, professor and co-director of the Generative AI Lab at Wharton, commented on the launch of SynthID. “A new watermarking AI paper is causing a stir, but note that watermarking does not solve for identifying AI content in the real world, because it requires cooperation from the AI company and also breaks when people edit the text,” said Mollick.
This means that this watermarking method requires the cooperation of LLM providers to make sure that the text generated by their models is compatible with the watermarking done by SynthID. If others do not implement watermarking, the technique cannot detect text generated by those models.
The watermark may be weakened by certain types of edits, like paraphrasing. This makes it less effective in detecting modified text.
Furthermore, open-source models that are widely distributed and modified are difficult to be enforced by watermarking. Commenting on this and the release of SynthID, associate professor at NUS, Bryan Kian, said that his team has also built a watermarking tool called Waterfall framework that addresses this loophole, thereby detecting plagiarism and unauthorised LLM training.
SynthID can still be vulnerable to “stealing” or “scrubbing” attacks, where adversaries attempt to remove or fake the watermark. This is similar to how people have been removing watermarks from images all this while.
Another study shows that LLM watermarking is susceptible to spoofing and scrubbing attacks. For under $50, attackers can bypass schemes with over 80% success, showing the need for stronger protections.
Interestingly, OpenAI had also created a watermarking tool to detect ChatGPT text with 99.9% accuracy, embedding patterns visible to systems but not to readers. However, they withheld the tool, as an internal study predicted reduced user engagement for ChatGPT by as much as 30%.
OpenAI also anticipated potential circumvention through paraphrasing or translation, which could weaken the tool’s reliability. This is exactly the same criticism that is now being directed towards SynthID.
Is AI Data Really That Bad?
In a recent interview, Reddit CEO Steve Huffman spoke about the company being “the most human place on Earth”, and how its value will only increase in the future. “AI has to come from somewhere,” he said, “the source of artificial intelligence is actual intelligence, and that’s what you find on Reddit.”
Meta chief Mark Zuckerburg also believes that giving proper attribution to AI-generated content will be one of the important trends and applications in the near future. “I think we are going to add a whole new category of content which is AI-generated or AI-summarised content, or existing content pulled together by AI in some way,” he said in a recent earnings call, noting that while he is unsure what is going to work, some things are really promising.
Meta has also announced several tools in this regard, like AudioSeal to detect synthetic audio, and Stable Signature to detect images generated by open-source models.
The quest for detecting AI content has been underway for quite some time. But now, everyone is interested in watermarking text as it seems to be a problem that cannot be solved at all. This has also resulted in people using terms like ‘AI slop’ which refers to a surge of low-quality, machine-generated content online. There are concerns over content that lacks authentic human insight flooding the internet.

The problems with AI-generated content are aplenty, such as students being falsely accused of plagiarism, users unsure if they’re arguing with humans or bots (especially on Reddit), and finally, the blurring of the lines between what’s real and what’s not.
Unfortunately, most AI detectors online, including ZeroGPT and Copyleak, have reportedly been unreliable. Many freelance writers have voiced their frustration on LinkedIn over the inaccurate results from these tools. AIM had earlier reported on how some of these tools claim that even our holy books are AI-generated – saying that the Bible is “97% AI-generated!”
The Coalition for Content Provenance and Authenticity was founded in 2021 with a goal to establish an industry standard for verifying digital content. It developed Content Credentials, which was named one of the best AI inventions by TIME this year.
It is clear that watermarking AI-generated content is the need of the hour when the internet is increasingly getting swarmed with such content. Though Meta, OpenAI, and others have already tried their hands at detecting AI-generated content, Google DeepMind’s SynthID may be able to make a “mark” (pun intended) on the internet, if it is able to partner with other LLM creators.
The post Will Google’s Watermark Tool Save the Internet from AI Slop? appeared first on Analytics India Magazine.