

Today’s fast-paced mobile app development services ecosystem makes app reliability crucial. App crashes disrupt user experience, cost money, and get bad reviews. Even with automated testing tools, detecting crashes caused by unexpected user inputs is difficult. Large Language Models (LLMs) can generate many unusual text inputs to stress-test mobile apps.
Mobile apps provide instant access to a wide range of services, information, and communication platforms, making them essential to our daily lives. The growing use of these apps requires high quality and performance to satisfy users and stay competitive in the fast-paced digital world. Mobile apps are ubiquitous, so they need rigorous testing and validation to ensure reliability and resilience to unexpected user inputs.
Text input is essential to mobile app usability and functionality, allowing users to navigate and interact with these digital environments. Text input is essential to many mobile apps, from search queries and form submissions to instant messaging and content creation. The ease of use, efficiency, and satisfaction of users depend on the seamless handling of text input.
The importance of crash detection in mobile apps
Mobile app crashes can harm users and developers. Frequent crashes can cause users to abandon an app, lowering app store ratings. Memory leaks, input validation errors, resource constraints, and unexpected user inputs cause app crashes.
Traditional crash detection ignores edge cases in favor of known issues or typical user behaviors. However, real-world users can enter long text or malformed data, which can cause app crashes or unexpected behavior. Thus, robust apps require the ability to simulate such inputs during development and testing.
Data collection
Rico, one of the largest Android GUI datasets, provides the dataset with many screenshots and view hierarchy files. News, entertainment, medical, and other apps are included. We extract the GUI page for the same app from the view hierarchy file by package name. We extract 7,136 apps with more than 3 GUI pages. First, we randomly select 136 apps with 506 GUI pages and check their view hierarchy file text inputs. We list keywords like EditText, hint-text, AutoCompleteTextView, etc. that indicate apps have text input widgets.
With these keywords, we automatically filter the view hierarchy files from the remaining 7,000 apps to find 5,761 candidate apps with at least one text input widget. Four authors manually check them for text inputs until a consensus is reached. This yields 5,013 (70.2%) apps with at least one text input widget and 3,723 (52.2%) with two or more. It does not overlap with the evaluation dataset.

The constraint categories of text inputs
We randomly select 2000 text-input apps and manually categorize them to determine input widget constraints. Two authors individually review the text input’s app name, activity name, input type, and content using the open coding protocol. Then each annotator merges similar codes, and the third experienced researcher will double-check any categorization disagreements.
Finally, we categorize constraints within (intra-widget) and between widgets (inter-widget) and summarize details.
Intra-widget constraint
One text input widget, for example, can only accept a non-negative number for a human’s height. Implicit and explicit subtypes exist. The former accounts for 63% and requires GUI page input display. The latter account for 37%, mostly as feedback when incorrect text input is received, such as when a simple password is entered, reminders that “at least one upper case character (A-Z) is required” are shown.
Role of Large Language Models in mobile app testing
LLMs are a groundbreaking tool for generating human-like text in many languages and contexts. Their diverse, unpredictable, and complex text makes them ideal for generating unusual inputs that reveal app vulnerabilities. LLMs can simulate real-world scenarios and edge cases that traditional testing may miss.
Further, LLMs can quickly generate large amounts of text for automated and large-scale testing. Developers can test rare or unexpected user behaviors by adding LLM-generated text to mobile app testing workflows.
APPROACH
This paper automatically generates unusual text inputs that may crash mobile apps. Since valid input generation and fuzzing deep learning libraries have been studied, LLM may directly produce target inputs. However, each LLM interaction takes a few seconds and uses a lot of energy, making this inefficient for our task. Instead, this paper proposes using LLM to create test generators (code snippets) that can generate a batch of unusual text inputs under the same mutation rule (e.g., insert special characters into a string).
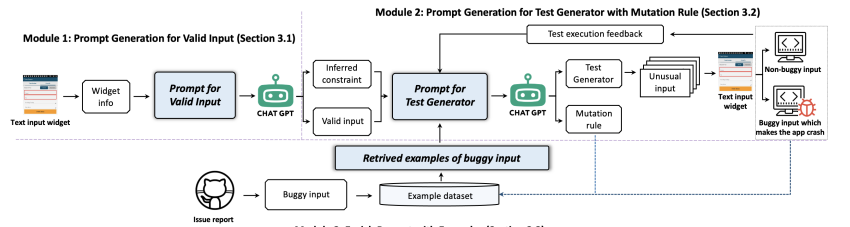
InputBlaster uses LLM to generate test generators and mutation rules as reasoning chains to boost performance. Each test generator automatically generates a batch of unusual text inputs, as shown. Given a GUI page with text input widgets and its view hierarchy file, we use LLM to generate valid text input for the GUI page. We then use LLM to generate a batch of unusual text inputs and the mutation rule, which guides the LLM in making effective mutations from valid inputs. We use the in-context learning schema to provide LLM query examples from online issue reports and historical running records to improve performance.
Prompt generation for valid input
LLM is used to generate valid input for Input Blaster’s mutation target. We input context information about input widgets and their GUI pages into LLM to help determine valid input. We also add dynamic feedback when interacting with input widgets and the constraint categories we summarized to improve performance. In addition to the valid text input, we ask LLM to output its inferred constraints for generating the valid input to aid the mutation rule generation in the next section.
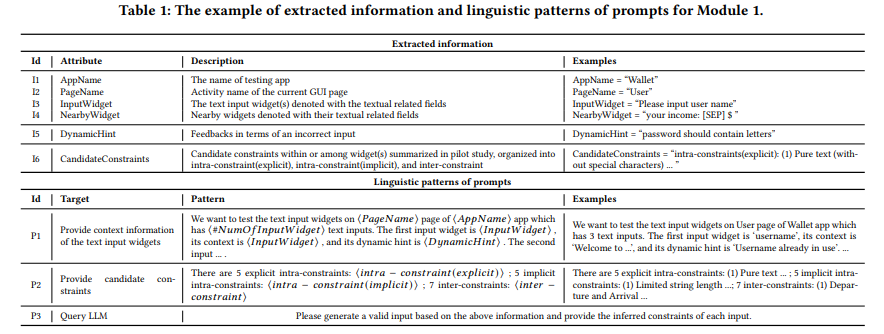
Prompt generation for test generator with mutation rule
InputBlaster uses LLM to generate the test generator and mutation rule from the valid input in the previous section. The mutation rule is the natural language described operation for mutating valid inputs that LLM automatically outputs based on our prompt and serves as the reasoning chain for producing the test generator. Note that LLM outputs this mutation rule.
We will input a batch of automatically generated unusual text inputs into the text widgets to test whether they crash the mobile app after each test generator is generated. This test execution feedback will be included in the LLM query prompt to help it understand the mutation and produce more diverse results. We include the inferred constraints in the previous section in the prompt because the natural language explanation would help the LLM produce effective mutation rules. For example, the LLM would try to insert characters to violate the constraint that the input should be pure text (without special characters).
Enriching prompt with examples
LLM struggles on domain-specific tasks like ours, so the in-context learning schema is often used to improve performance. It helps the LLM understand the task by providing examples of the instruction. Along with the schema and test generator prompt, we give the LLM examples of unusual inputs. We first build a basic dataset of buggy inputs (which truly cause the crash) from open-source mobile app issue reports and continuously add running records during testing. We use the example dataset to design a retrieval-based example selection method to select the best input widget examples for the LLM to learn with relevance.
Bugs detection performance (RQ1)
Bug detection by InputBlaster. With unusual inputs from InputBlaster, the bug detection rate is 0.78 (within 30 minutes), detecting 78% (28/36) of bugs. Bugs can be found in 13.52 attempts and 9.64 minutes, which is acceptable. This shows that our method generates unusual inputs for app testing and helps find input widget bugs.

Future prospects: Enhancing mobile app testing with AI
LLMs’ mobile app testing roles may grow as they evolve. AI models can generate text inputs and predict vulnerabilities based on input patterns, making testing frameworks smarter and more targeted. AI-generated inputs and machine learning-based analytics could automate and improve crash detection.
LLMs can also help mobile app developers generate new inputs as new features are released, ensuring that apps are tested in real-world scenarios before deployment.
Conclusion
In today’s competitive mobile app development services market, app stability and crash prevention are crucial. Large language models generate diverse and unusual text inputs to stress-test apps. LLM integration into testing workflows is difficult, but crash detection and app performance optimization are clear benefits.
Mobile app developers can avoid issues and deliver more reliable, crash-free apps by using LLMs for inputs.